Overview
모델 분류의 평가에 대해 알아보자. 해당 시간의 주요 목적은 다음과 같다.
어려운 이야기를 제외하고, 분류 평가에 대한 설명 및 매번 혼동되는 평가 지표에 대해 이야기 해보자
분류의 중요성
현재 하나투어에서 서비스하고 있는 여행정보AI는 사용자의 질의에 따라 다양한 형태의 답변을 주고 있다.
분류를 통해 사용자가 어떤 의도로 질문을 했는지에 대한 파악이 필요하다.
- 2024년 8월 14일부터 18일까지 베트남 여행을 계획 중입니다. 부모님이 가시는 거라 노쇼핑, 노옵션이어야 하고, 하롱베이는 꼭 가고 싶어 하십니다. 인솔자가 계속 있어야 하고, 3박 5일 말고 4박 5일 일정이면 좋겠습니다.
애매하다는 정의는 여러 사람이 똑같은 분류로 지정하지 않고 서로 다른 분류를 지정하였을 경우다.
해당 질의는 일정 추천으로 되어 있지만 상품 추천에 대한 상품 조건일 수도 있다.

여행정보AI처럼 하나의 입력창에 여러 타입의 답변이 나올 수 있는 경우 분류를 통해서 각각의 프로세스가 실행이 될 수 있도록 해야 한다.
즉, 사용자가 질의한 내용의 의미를 분석하여 어떤 분류인지를 찾아 사용자가 원하는 답변을 도출할 수 있도록한다.
분류 평가(Classification Evaluation)란?
생성된 분류 모델이 얼마나 잘 분류를 수행하는지 판단하기 위한 프로세스.
- 모델의 성능을 측정하고, 모델이 실제 환경에서 기대하는 대로 작동할 것인지를 예측
- 세부적인 평가 지표들을 통해 모델의 성능이 부족한 부분을 진단
사용자가 모델에게 질문을 던질 때, 얼마나 내 마음을 잘 이해하였는가?
학습 / 테스트 데이터 셋 (Train / Test data set)
학습 데이터와 테스트 데이터를 수동으로 분류하지 않는다. 모델 학습시 학습 데이터를 기준으로 일정 비율만큼의 데이터를 테스트 데이터로 지정한다.
테스트 데이터 선정은 랜덤이며 10 ~ 15% 사이의 비율로 구성이 된다.
여행정보AI의 분류값은 현재 기준 12개로 구성되어 있으며 각 분류별 질의의 개수가 다르다. 이는 만들어지는 분류별 테스트 데이터 개수도 다르게 설정되는데, 테스트 데이터가 너무 많으면 훈련 데이터가 부족하여 모델 성능이 저하될 수 있고, 반대로 테스트 데이터가 너무 적으면 모델의 일반화 능력을 정확히 평가하기 어렵다
혼동 행렬 (Confusion matrix)
학습된 AI 모델의 성능을 평가하기 위해 가장 기본이 되는 표. 가로, 세로 중 한 쪽에는 정답 데이터(Ground Truth)에 해당하는 클래스를, 다른 한쪽에는 모델의 예측에 해당하는 클래스를 표시한다.
해당 지표는 정보 검색 평가에서도 사용한다

- 예상: 사람이 예상한 결과
- 예측: 모델이 예상한 결과
실제, True등 문서마다 조금씩 다르고 헷갈리게 정의되어 있다. 우리는 예상(Expect)과 예측(Predic)이라는 용어로 고정해서 사용한다
- True Positive(TP, 참 양성): 실제 True인 정답을 True라고 예측 (정답)
- True Negative(TN, 참 음성): 실제 False인 정답을 False라고 예측 (정답)
- False Positive(FP, 거짓 양성): 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN, 거짓 음성): 실제 True인 정답을 False라고 예측 (오답)
해당 내용은 하루만 지나도 다시 까먹고 헷갈리게 되는 지표
이해하기
쉽게 이해하기 위해서는 먼저 표를 그릴 수 있어야 한다. 다음을 기억 하자
- 행은 사람
- 열은 모델
- 모델의 결과가 중요
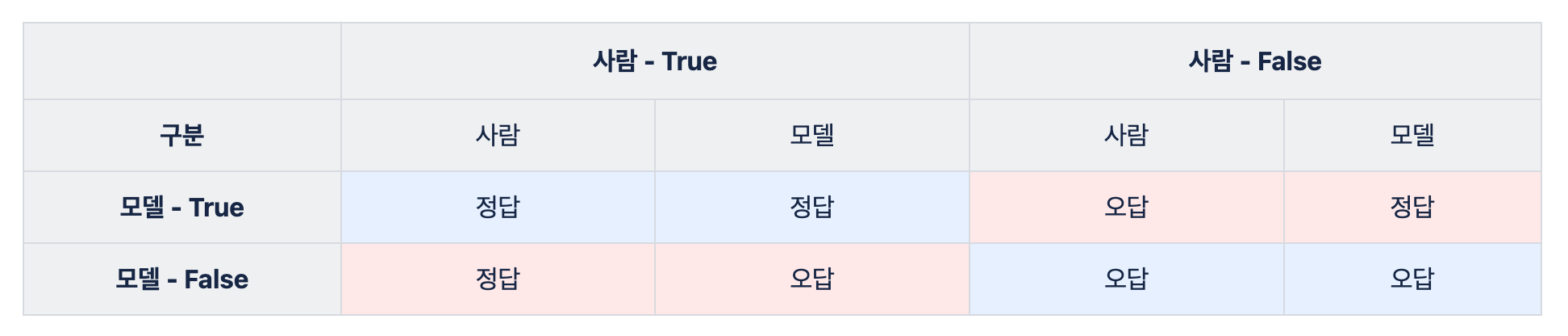
True / False 는 예상과 예측이 맞았는가? Positive / Negative 는 모델의 예측이 맞았는가?
- TP: 예상 예측이 맞으니까 True, 너의 예측이 정답이라고 하니 Positive
- FP: 예상 예측이 틀리니까 False, 너의 예측이 정답이라고 하니 Positive
- FN: 예상 예측이 틀리니까 False, 너의 예측이 오답이라고 하니 Negative
- TN: 예상 예측이 맞으니까 True, 너의 예측이 오답이라고 하니 Negative
성능 지표 분석
조화평균(F1-Score), 특이도(Specificity), 정확도(Accuracy)는 대상에서 제외
정확도의 경우, 계산시 TP + TN / TP + FP + FN + TN 의 공식을 가지는데,
다중 클래스 분류에서의 TN은 전체 문서의 모든 대상이 TN값이 되므로 전체 문서의 개수를 구할때 제외된다.
즉, 공식의 결과가 잘못 나오게 되므로 대상에서 제외 한다
Precision (정밀도)
양성(Positive)으로 식별된 사례 중 실제로 양성(Positive)이었던 사례의 비율
- 검색: 제대로 검색한 문서의 비율
- 모델: 모델이 정답이라고 예측한 비율
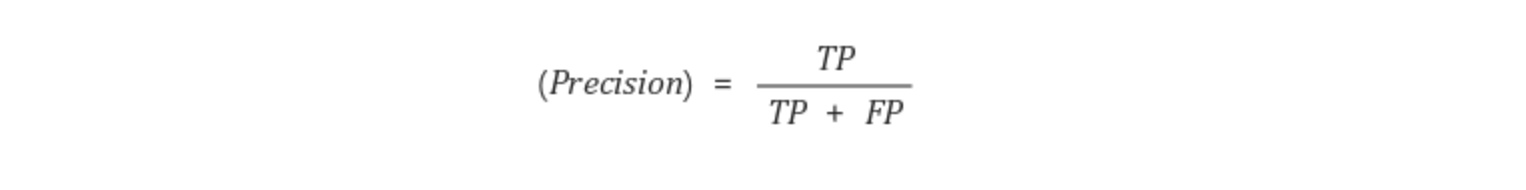
FP: 예상(사람)이 틀린것
TP + FP → 모델이 특정 분류로 예측한 전체 개수 ( 예측이 맞은거 + 예측이 틀린거 )
모델이 전체 데이터 중, A 라벨을 20개로 지정하였는데 실제 사람과 모델이 같은 A라벨로 지정한 지정한 비율
분모가 모델이 되면 ‘모델이 정답이라고 예측한 비율’이 된다
Recall (재현율)
양성(Positive) 중 정확히 양성(Positive)이라고 식별된 사례의 비율
- 검색: 실제 관련 있는 문서 중 검색 시스템이 검색해낸 문서의 비율
- 모델: 분류개수에 대해서 실제 모델이 제대로 예측한 비율

FN: 예측(모델)이 틀린것
TP + FN → 사람이 특정 분류로 예측한 전체 개수 | 예상한 해당 분류의 전체 개수
사람이 전체 데이터 중, A 라벨을 20개로 지정하였는데 실제 사람과 모델이 같은 A라벨로 지정한 지정한 비율
분모가 사람이 되면 ‘사람이 예상한 개수에 대한 모델이 정답이라고 예측한 비율’이 된다
분석 이후
목적
- 정밀도를 증가시키기 위해서는 FP의 값이 줄어들어야 한다
- 재현율을 증가시키기 위해서는 FN의 값이 줄어들어야 한다
정밀도, 재현율 증가시키기
어떻게 하면 FN과 FP에 대해서 값을 조절할 수 있을까? 해당 방법에 대해서는 명확하게 나와있지 않지만 다음과 같은 프로세스라면 점차 줄어들 것이라 생각된다.
- 테스트 셋의 FN, FP 수치만 확인하지 말고 직접 어떠한 질문이 어떻게 값이 설정되어서 다른지를 확인 할 수 있어야 한다
- 테스트 셋의 분류값을 변경한다
- 테스트 셋과 학습셋을 다시 하나의 데이터 셋으로 뭉쳐서 전체 학습 프로세스를 진행한다
- 랜덤으로 학습셋과 테스트셋을 분리 하므로 동일데이터가 테스트이 될 확률이 있거나 없거나 이다
- 평가 결과의 FN, FP 수치를 확인하면서 프로세스를 반복한다

정답 셋에 대해서는 분석의 필요가 없다. 나의 예상과, 모델의 예측이 틀렸을 경우 어떤 질의가 어떻게 서로 틀리게 분류를 지정했는지에 대한 분석만이 필요하다. 즉, FN과 FP에 대해서 질의 내용을 확인한다
평가시 테스트셋의 데이터는 변경하지 않는다. 이는 “오염”이 되었다고 표현한다고 한다.
기존의 평가와 비교를 할 수 없으므로 하나의 평가지표만을 봐야 한다.
이전의 평가와 비교를 하기 위해선 같은 테스트셋으로 진행이 필요하다.
단, 위의 프로세스는 이전데이터와의 비교가 아닌, 지속적으로 루프하며 정밀도를 올리는 방식으로 정밀도가 1에 가깝게, FP와 FN이 0에 가깝게 하기 위함이다.
