ES의 클러스터를 설계하기 위해 적정한 샤드의 개수와 노드의 개수를 선정하는 방법에 대해 정리한다.
해당 방식은 당근페이 개발자 이신 - 강진우님의 블로거를 보고 그대로 정리한다
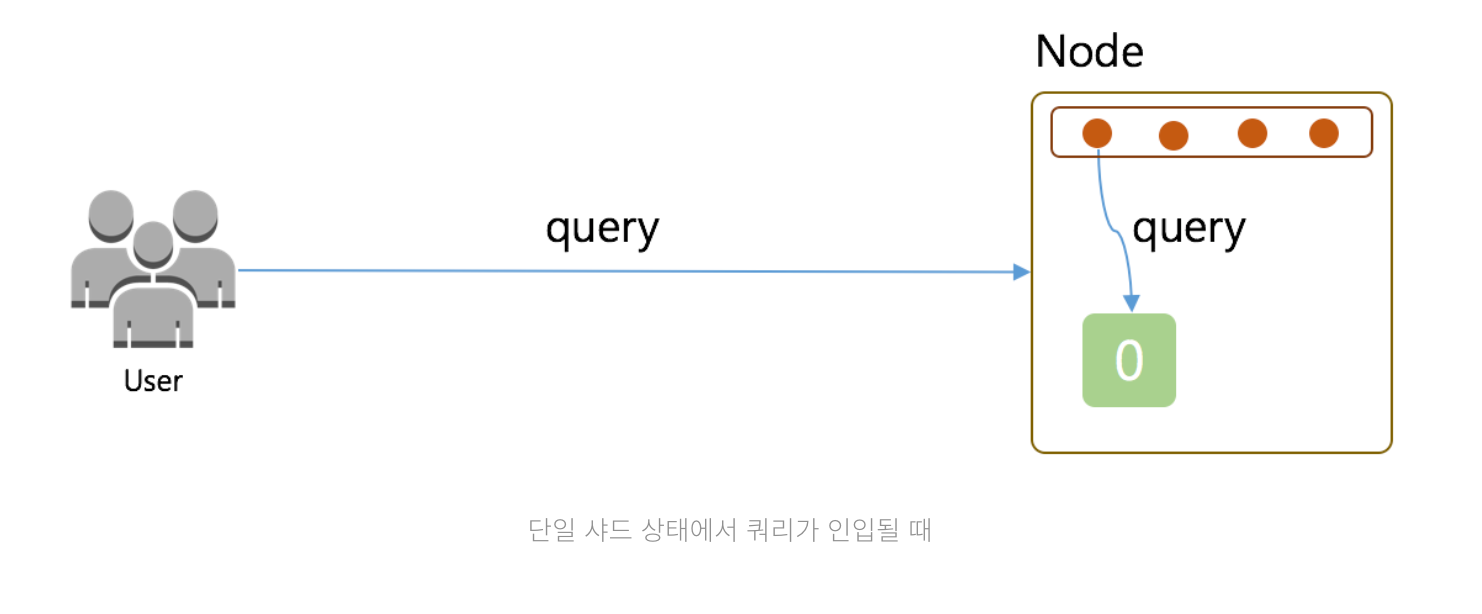
검색이 일어나는 과정
Elasticsearch의 검색은 1 쿼리(Query) 1 샤드(Shard) 1 쓰레드(Thread)를 바탕으로 발생한다. 상황별 케이스를 보자
블로그의 사진을 그대로 인용했다. 잘만들어 보려고 해도 결국 같은 모양의 그림..;;
1개의 쿼리가 각 노드로 인입되어 쓰레드를 사용하게 되는 경우
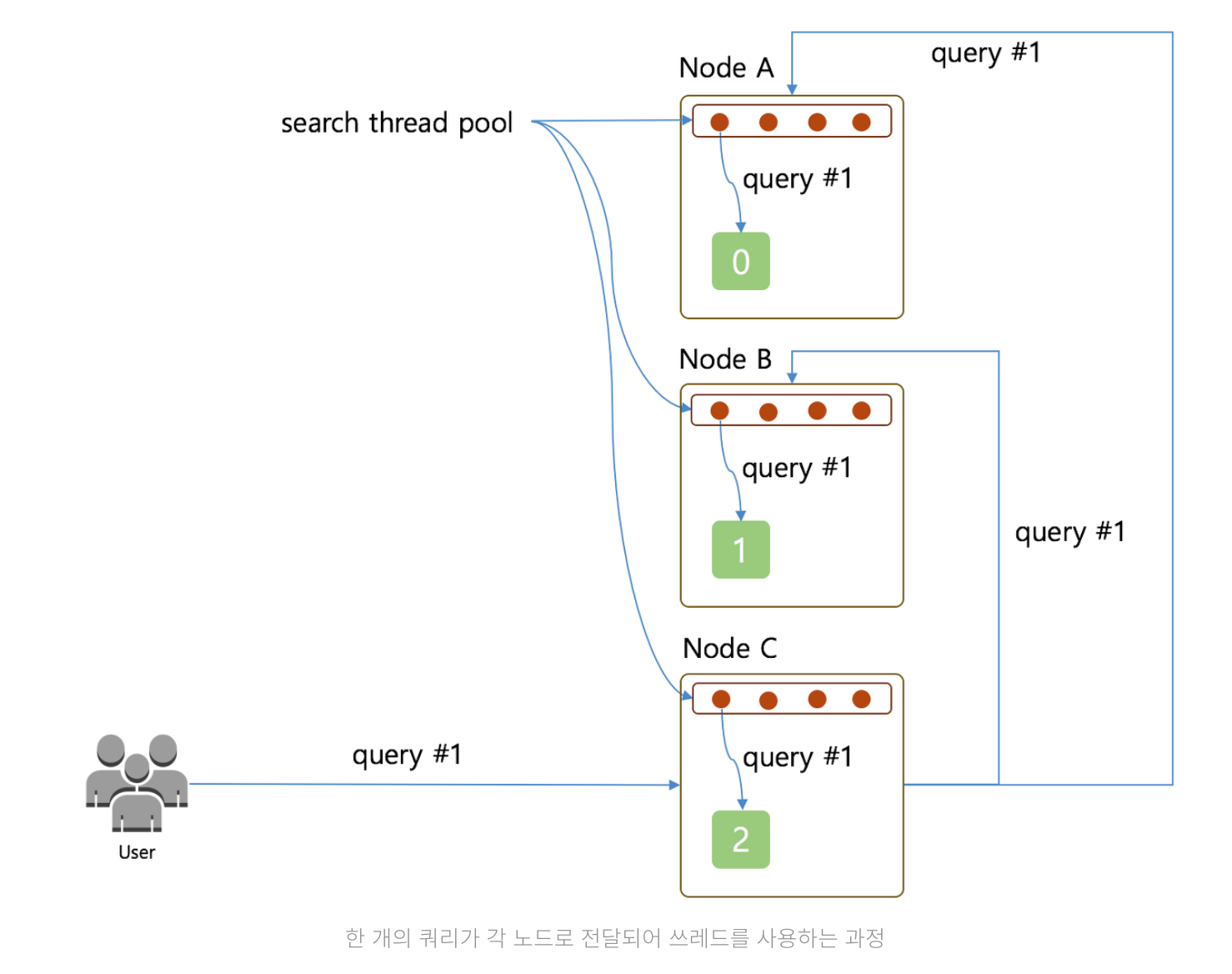
Query #1을Node C로 전달 ( 이때Node C는Coordinate Node)Node C는Node A와Node B에게Query #1을 전달하며 검색을 요청- 각각의 노드는 자신이 가지고 있는 샤드들(설정은 1)을 조회하게 되고, 이때 검색해야 할 샤드의 수가 1개이기 때문에 4개의 쓰레드 풀에서 1개의 쓰레드를 꺼내서 검색
단일 쿼리를 기준으로 각각의 노드는 샤드가 하나씩 이기 때문에 쓰레드를 하나만 사용하고 나머지 3개의 쓰레드는 대기하는 비효율적인 상황이 발생한다.
4개의 쿼리가 각 노드로 동시 인입되어 쓰레드를 사용하게 되는 경우
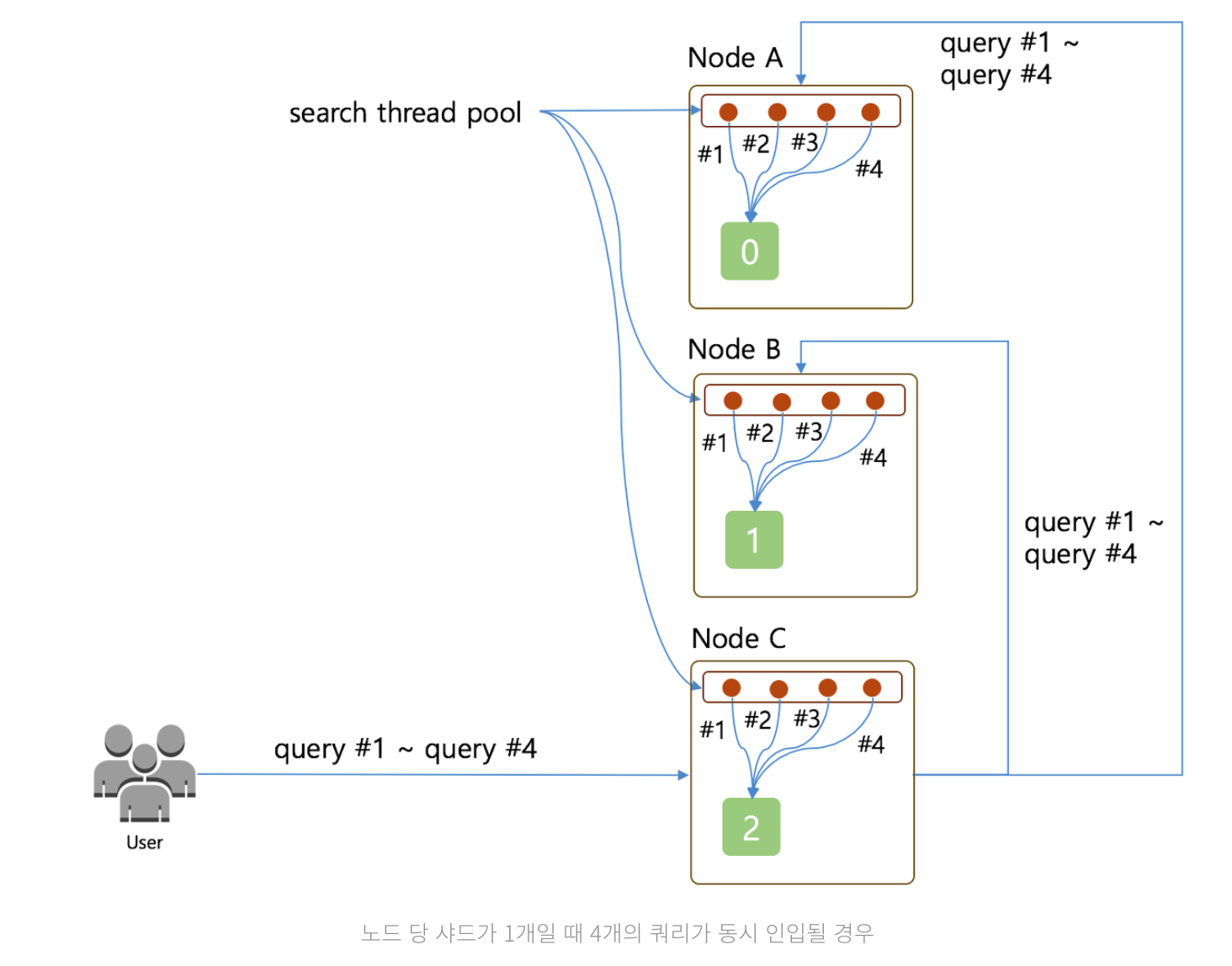
Query #1 ~ Query #4는Node C로 전달Node C는Node A와Node B에게Query #1 ~ Query #4를 전달하며 검색을 요청- 각 노드의 샤드는 1개이기 때문에 쿼리 하나당 쓰레드를 하나씩 나눠서 실행하게 되므로 4개의 쿼리가 동시에 종료
4개의 쓰레드에 4개의 요청이 와서 동시에 쿼리가 종료
4개의 쿼리가 각 노드로 동시 인입되어 쓰레드를 사용하게 되는 경우 ( 샤드 4개 )
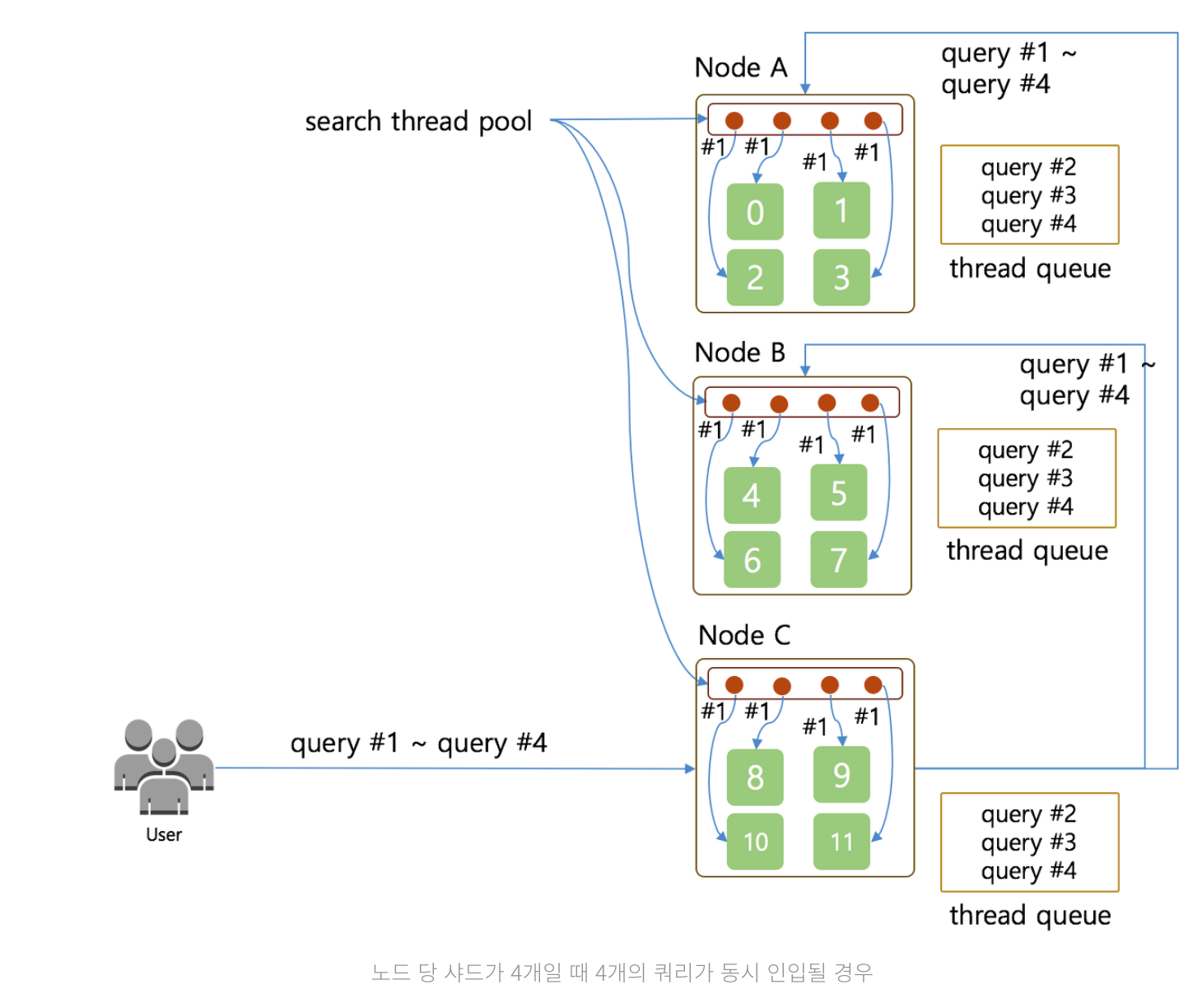
위와 같은 상황에서 샤드만 4개가 되었을 경우,
- 노드별로 검색을 해야할 샤드가 4개이므로,
Query #1에 대한 결과를 조회하기 위해 4개의 쓰레드 풀에서 4개의 쓰레드를 모두 사용해서 각각의 샤드 별로 검색 요청 - 모든 쓰레드 풀이 사용중이므로
Query #2 ~ Query #4는 순차적으로 실행이 된다
Query #1이 종료되기 전까지 쓰레드 큐에 쌓여 대기하게 되므로 동시에 종료되지 못하고 시간차이가 발생
너무 많은 양의 쿼리가 인입될 경우, 큐가 꽉차서 rejected 현상이 발생할 수 있다. reject에 관련된 글도 작성했는데 확인해보니 이것도 강진우 님의 글이였다..
적정한 클러스터 설계 하기
클러스터가 저장해야 할 전체 문서의 데이터 크기
로그성 데이터들이 저장되는 클러스터라면, 일 별 및 GB, 유지 기간등 예측해야 하며, 데이터를 검색하기 위한 검색 엔진이라면 초기 데이터의 크기가 어느 정도이고 주기적으로 어떤 형태로 데이터의 갱신이 일어나는지 예측해야한다.
로그 클러스터의 경우, ILM을 통한 Rolling 정책을 활용하도록 하자
예상하는 최대 동시 인입 쿼리 수
서비스에 노출되고 사용자에게 직접적으로 검색 결과를 돌려주어야 한다면, 최대 몇 개의 쿼리가 동시에 인입되는지 확인해야한다.
목표로 하는 검색 응답 시간
빠르면 빠를수록 좋다는 두리뭉실한 목표보다는 최소한 몇 ms 안에 응답을 줄 수 있게 해야한다 같은 명확한 목표가 필요하다.
40ms ~100ms의 속도가 적당하다고 배웠다. 아무리 빨라도 Front에서 다른 작업을 처리하느라 화면을 제때그리지 못하면 의미가 없다
서비스에 실제 사용할 수 있는 하드웨어의 스펙 결정
테스트하는 장비와 실제 운영되는 장비가 같은 스펙으로 진행이 되어야 한다.
로그 클러스터라면 Hot-Warm 아키텍처로 인한 SDD, HDD로 분류
테스트
강진우님께서 진행하신 테스트 내용이다.
| 항목 | 내용 |
|---|---|
| 클러스터의 데이터 크기 | 전체 3TB (일 별 최대 100GB, 최대 30일 보관 |
| 초당 최대 인입 쿼리 수 | 10개 |
| 목표 검색 쿼리 응답 시간 | 100ms |
| 사용 가능한 하드웨어 스펙 | 24 Core / 32GB Memory |
테스트 시나리오
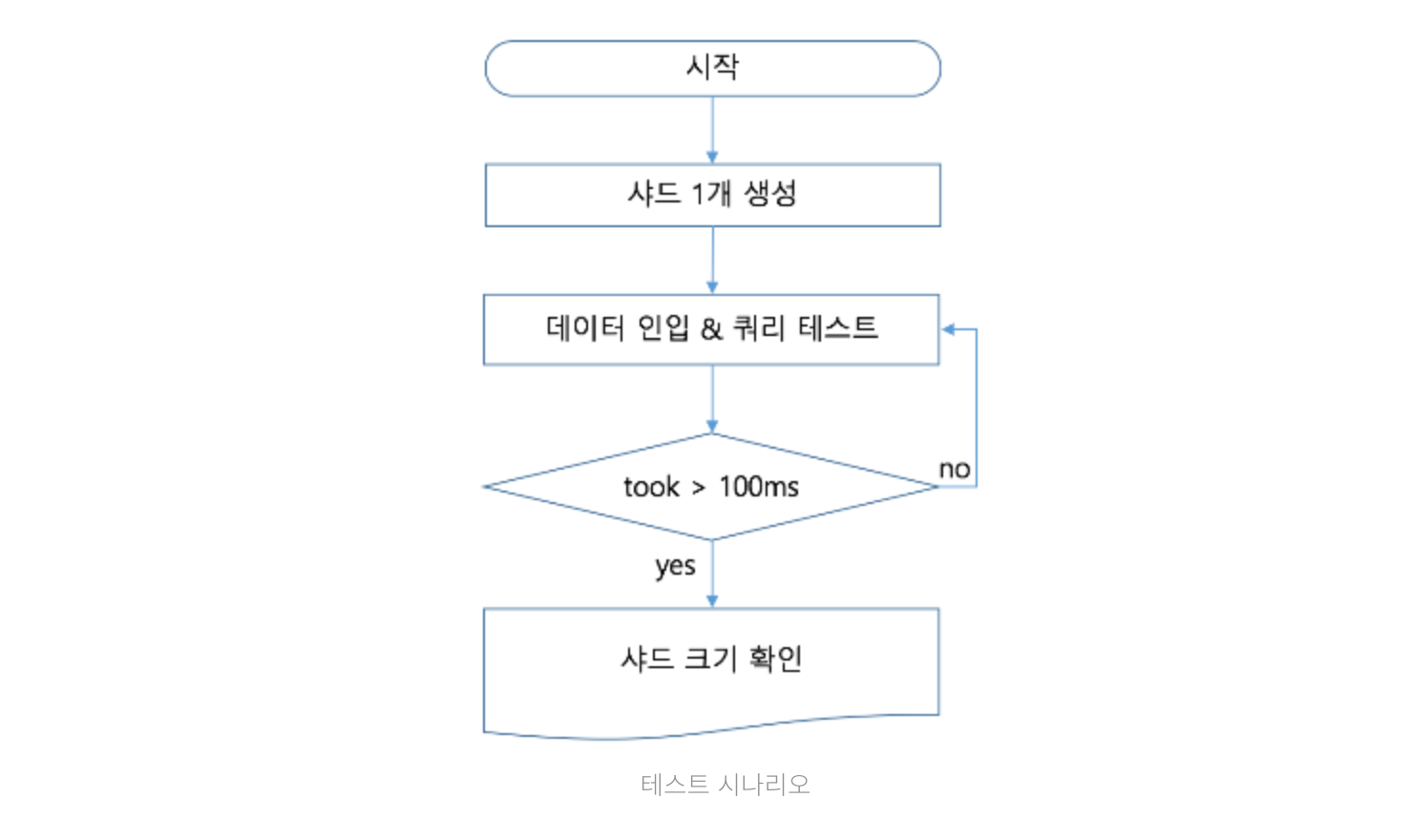
샤드를 1개만 생성하는 이유
검색 요청은 1 쿼리(Query) 1 샤드(Shard) 1 쓰레드(Thread)인데 아래 그림과 같이 하나의 쓰레드가 하나의 샤드에 검색을 날리게 될 때, 이 상태에서 샤드의 크기를 점점 늘려가면서 쿼리를 요청하게 되면 샤드가 담고 있는 데이터의 크기가 점점 커짐에 따라서 검색 쓰레드의 검색 결과가 점점 늘어나는 것을 볼 수 있으며,
최종적으로 하나의 쓰레드가 하나의 샤드를 검색하는 데 걸리는 시간을 알게 된다.
테스트 결과 분석
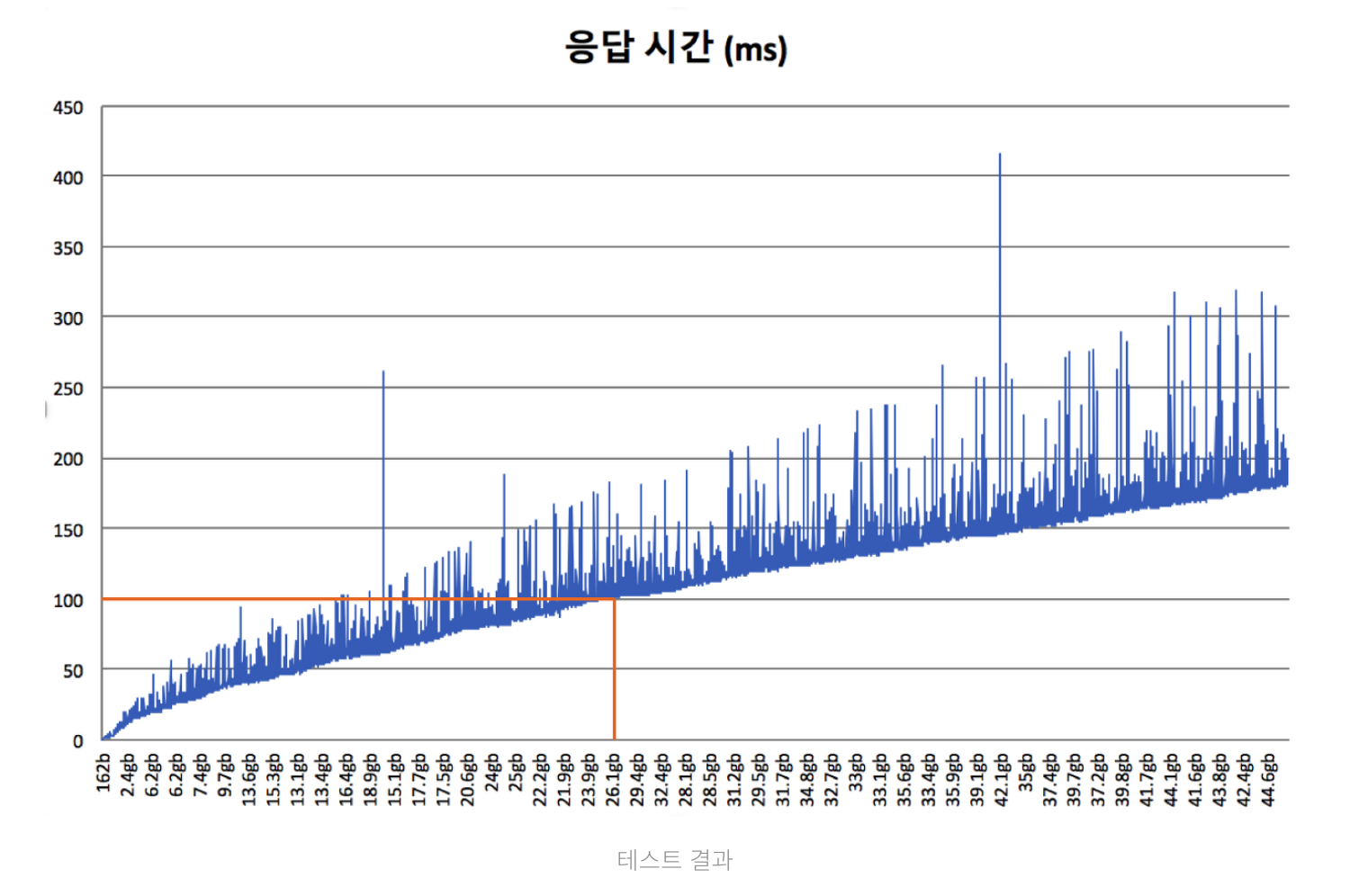
Y축은 쿼리 응답에 대한 took (ms), X축은 문서의 수와 샤드의 크기. 전체적으로 문서의 수와 샤드의 데이터 크기가 늘어나는 만큼 검색에 소요되는 시간도 선형적으로 증가됨
검색 성능 100ms를 달성하기 위해서는 샤드의 크기가 약 26GB 정도 되어야 함을 알 수 있음. 오차 범위를 포함해서 20GB 정도로 샤드의 크기를 맞추게 된다면 약 70ms ~ 80ms의 검색 성능을 기대할 수 있다.
Elasticsearch 공홈에서도 명확한 방식이 제시되지 않고 있다. 그 이유는 사이트마다 데이터의 크기나 구조가 다르기 때문이며 이러한 이유 때문에 직접적으로 사이트의 데이터를 가지고 직접 테스트 해야한다.
샤드의 개수 결정하기
테스트 결과에서 샤드 하나의 크기를 20GB 정도로 설정하면 된다는 것을 확인했다. 하루에 쌓이는 데이터의 양이 최대 100GB기 때문에 하루치 인덱스의 샤드 개수는 5개로 설정하면 된다는 것을 알 수 있다. 또한 초당 인입되는 쿼리 수를 통해서 샤드 5개를 몇 개의 노드에 어떻게 배치하는지 알 수 있다.
인덱스 별 샤드의 개수는 5개이고, 한 번에 처리되어야 하는 쿼리 수는 10개 이므로 클러스터에 필요한 검색 쓰레드의 전체 개수는 50개이다. 즉 클러스터의 데이터 노드들의 검색 쓰레드들의 모든 합이 50개가 된다면, 10개의 쿼리를 동시에 처리할 수 있게 된다. 데이터 노드 하나의 코어 수가 24개 이므로 최소 3대가 필요하고, replica를 1로 두고자 한다면 replica 샤드의 배치를 고려하여 최종적으로 6대의 데이터 노드가 필요하다.
추후 색인에 대한 고려도 필요할 것이다. 데이터의 증분이 얼마나 빈번하게 발생 될 것인지, 현재 구성한 테스트 결과 이후 더 많은 서비스들이 연결되고 요청이 이루어지게 될지는 모르기 때문에 항상 해당 부분을 고려하여 넉넉한 자원을 확보하여 설계를 해야한다.
