붓꽃의 꽃받침 길이와 너비, 꽃잎의 길이와 너비, 그리고 종을 담은 데이터 셋이 있다.
종을 모른다고 가정하고 K-means clustering을 이용해서 군집을 지어보겠다. K-means clustering으로 묶은 군집이 실제 종과 얼마나 일치하는 지를 비교해 볼 것이다.
import pandas as pd
df = pd.read_csv("./data/iris.csv")판다스를 임포트하여 CSV 파일을 데이터 프레임으로 만든다.
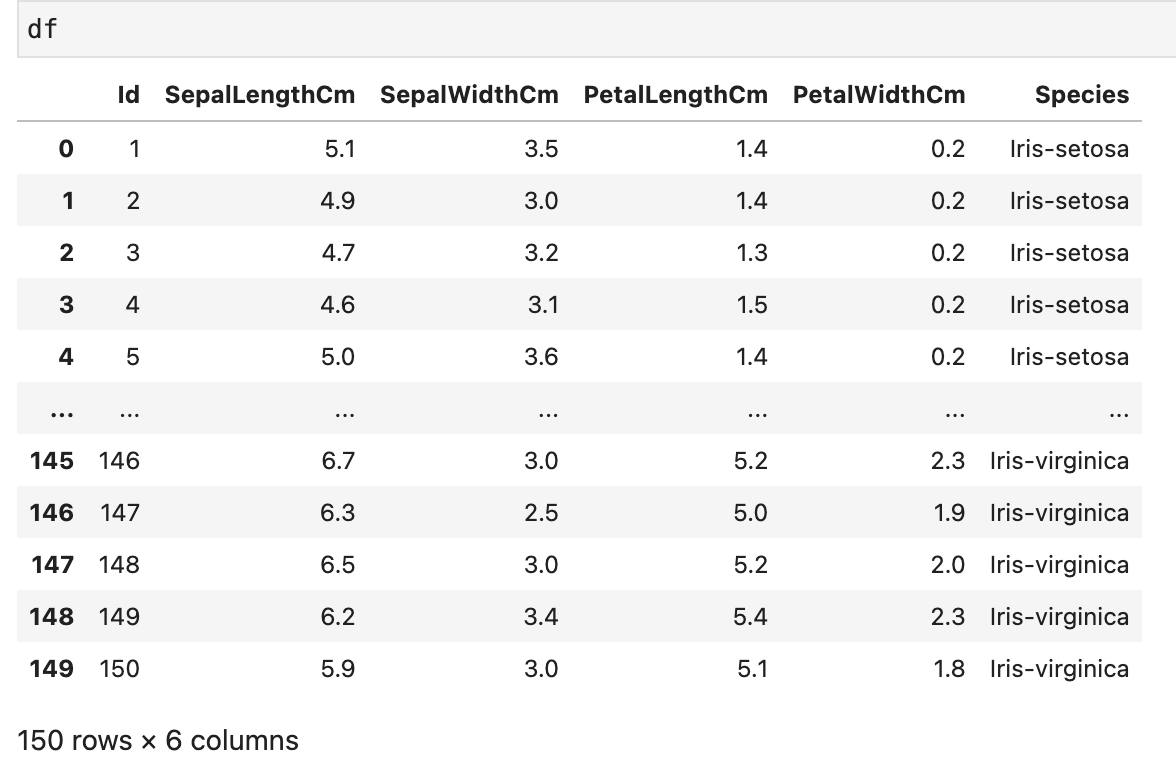
df를 확인해 보면 아래와 같다.
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
df["color"] = label_encoder.fit_transform(df["Species"])sklearn.preprocessing 모듈에서 LabelEncoder 클래스를 사용하여 "Species" 컬럼의 값을 숫자로 인코딩한다.
cur_df = df[["PetalLengthCm", "SepalLengthCm", "color"]]
data = cur_df.drop(["color"], axis=1).values세개의 컬럼을 cur_df에 할당한다.
그리고 data에는 color 컬럼을 제외한 후, 넘파이 배열 형태로 할당한다.
from sklearn.cluster import KMeans
model = KMeans(
n_init=10,
n_clusters=3,
)
model.fit(data)sklearn.cluster 모듈에서 KMeans 클래스를 사용하여 k-평균 군집화(K-means clustering) 모델을 생성한다.
n_init=10으로 설정하여 초기 중심점 설정을 10번 시도하고, n_clusters=3으로 설정하여 3개의 클러스터를 생성한다.
그리고 data를 학습시킨다.
def inference(model, data):
h = 0.02
x_min, x_max = data[:, 0].min() - 1, data[:, 0].max() + 1
y_min, y_max = data[:, 1].min() - 1, data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
return xx, yy, Zk-평균 군집화 모델과 데이터를 받아들이고, 군집화 결과를 시각화하기 위한 그리드 데이터를 생성하는 역할을 수행하는 함수를 정의한다.
시각화할 그리드의 간격을 0.02로 주고,
그리드 범위를 설정하고,
xx, yy 변수에 x_min부터 x_max까지, y_min부터 y_max까지의 범위에서 h 간격으로 그리드 데이터를 생성한다.
생성된 그리드 데이터 xx, yy를 펼쳐서 1차원으로 만든 후, k-평균 군집화 모델 model을 사용하여 군집 레이블 Z를 예측한다.
import numpy as np
from matplotlib import pyplot as plt
def plot_kmeans_cluster(xx, yy, Z, model, data, columns, species):
labels = model.labels_
centroids = model.cluster_centers_
plt.clf()
Z = Z.reshape(xx.shape)
plt.scatter(data[:, 0], data[:, 1], c=labels, s=10)
plt.xlabel(columns[0])
plt.ylabel(columns[1])
plt.show()
plt.scatter(data[:, 0], data[:, 1], c=species, s=10)
plt.xlabel(columns[0])
plt.ylabel(columns[1])
plt.show()labels = model.labels_: 군집화 모델 model에서 예측된 레이블 labels를 가져온다. 각 데이터 포인트가 속한 군집의 레이블이 저장된다.
centroids = model.clustercenters: 군집화 모델 model에서 예측된 클러스터 중심점들을 가져온다.
plt.clf(): 그래프를 초기화한다.
Z = Z.reshape(xx.shape): 군집화 결과인 Z를 xx의 shape에 맞게 재구성한다.
plt.scatter(data[:, 0], data[:, 1], c=labels, s=10): 데이터 포인트들을 산점도로 시각화한다. 각 데이터 포인트의 x와 y 좌표가 data[:, 0]과 data[:, 1]에 저장되어 있고, 각 데이터 포인트의 군집 레이블이 labels로 지정된다.
plt.xlabel(columns[0]), plt.ylabel(columns[1]): x축과 y축의 라벨을 columns에 지정된 컬럼 이름으로 설정한다.
plt.show(): 시각화된 그래프를 화면에 출력한다.
그리고 데이터 포인트들을 종(species) 정보를 이용하여 다시 산점도로 시각화한다.
columns = cur_df.columns
xx, yy, Z = inference(model, data)
plot_kmeans_cluster(xx, yy, Z, model, data, columns, cur_df["color"])plot_kmeans_cluster로 전달할 파라미터들을 정의하고, plot_kmeans_cluster를 호출하여 시각화한다.
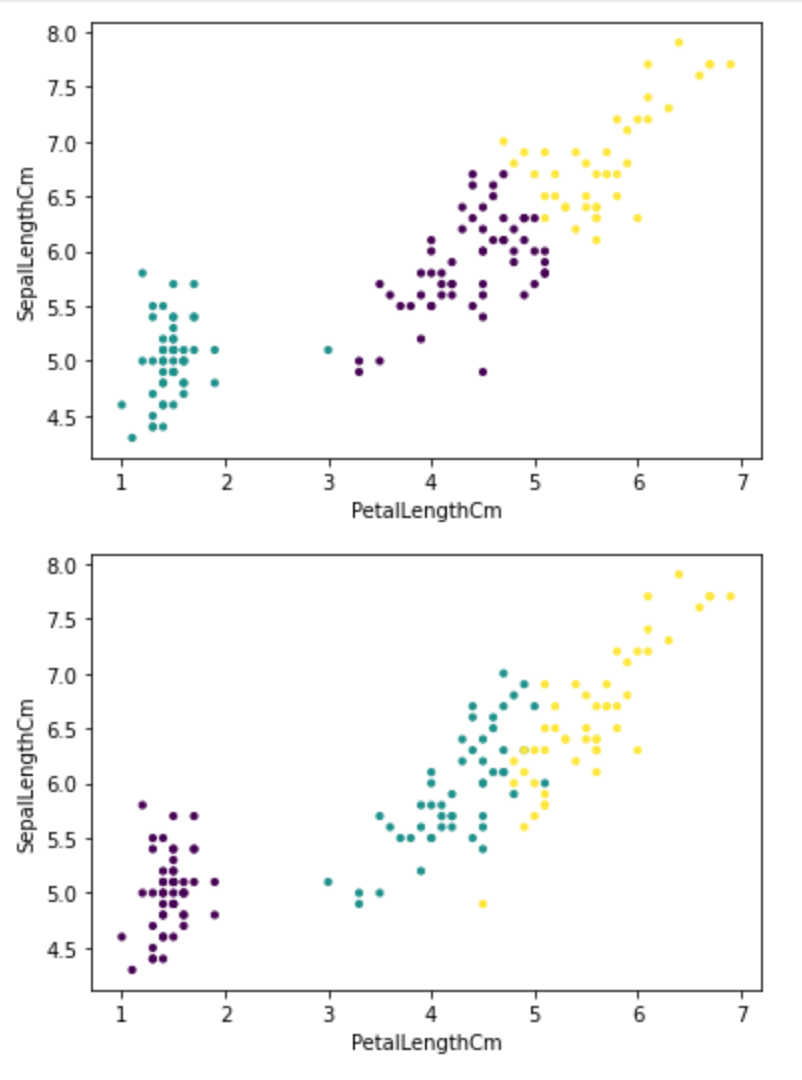
새로운 데이터가 들어왔을 때 어떤 클러스터에 속하는지 분류를 쉽게 할 수 있다면 인간들의 업무에 큰 도움이 될 것이다.
더 정확하고 세밀한 모델을 만들 수 있도록 공부를 더 해야겠다.
