* system call부터 글 작성.
Assignment
Introduction
- 사용자 프로그램 실행을 허용하는 시스템 부분에 대한 작업을 시작하게 된다.
- 현재 기본 코드는 사용자 프로그램을 실행시킬 수 있지만, I/O 혹은 상호작용이 부가능하다.
- 이번 프로젝트에서는 System Call을 통해 OS(핀토스)가 I/O 등, 상호 작용할 수 있게 하겠다.
- 대부분 userprog 폴더에서 작업하게 되지만, 전반적으로 다른 부분도 건드릴 수 있을 것이다.
- Project 1(Threads)를 완료한 상태에서(Advanced Scheduler는 제외) 진행되어야 한다.
System Call 개요
kaist pintos project2 system call 동영상
- 해당 영상은 pintos-kaist가 아닌, 스탠포드에서 제작한 pintos-original이다.
- 즉 카이스트 권영진 교수님이 만든 pintos-kaist 바탕이 아니다.
- pintos-kaist는 64비트 기준이고, pintos-original은 32비트 기준이기 때문에 fork 함수 혹은 context change 방식 등이 수정되었을 수도 있다. 이러한 점 말고도 차이점이 많다.
- 사용자 프로그램이 파일에 접근하거나 파일을 저장, 프로세스 생성 등을 할 수 있게 한다.
- 시스템 콜에서 핵심 포인트는, 시스템 콜을 요청하기 위해 하드웨어 인터럽트가 발생하면서, 실행 모드의 우선순위가 특수 모드로 상승한다는 것이다.

- user area -> kernel area로 이동 시 privilege level이 상승한다.
- 시스템 콜을 구현하기 위해서는 syscall_handler() 함수를 채워야 한다.

Address Validation
system((void *)0);- 위는 사용자 프로그램 안에 포함되어 있는 코드이다. 위와 같이 잘못된 영역을 접근하려고 하면 에러를 띄워줘야 한다.
- 사용자 프로그램은 user space만 참조할 수 있고 kernel space는 참조할 수 없다.
- 이러한 시도가 이루어질 경우 page fault 에러를 띄워줘야 한다. 즉 사용자 프로그램에서 인자로 넘긴 포인터가 커널 공간(OS 영역) 등 잘못된 주소를 가르키고 있으면 page fault 에러를 띄워줘야 한다.
- 사용자 프로그램이 커널 공간 등의 잘못된 주소가 아니라 유효한 주소를 넘겨줬다면(즉 주소 체크가 성공되면), user stack의 arguments를 kernel로 복사한다.
- 시스템 콜이 진행되고 나서, 이 시스템 콜의 반환값을 rax 레지스터에 저장한다.
- 사용자 프로그램은 커널에게 유효한 주소를 제공하면, 커널은 자신(커널)이 실행되는 동안 사용자 프로그램의 공간에 접근하면 안된다.
- 대신에, 사용자 프로그램의 인자들을 복사해온다.(user space -> kernel space)
- 그러면, 커널은 사용자 프로그램 공간에 접근하지 않고 자신, 즉 커널 공간에서 프로그램(사용자 프로그램이 넘긴 인자들을 바탕으로 한 write, read 등의 시스템 콜을 말하는 건가?)을 실행할 수 있게 된다.
- 사용자 프로그램은 유효하지 않은 주소를 가리키는 포인터를 인자로 시스템 콜을 호출할 수도 있다.
- 이러한 잘못된 포인터에는 다음과 같은 경우가 있다.
- 앞 전의 예시에서 봤던 NULL pointer
- 가상 주소와 맵핑되지 않은 포인터
- PHYS_BASE 위의, 즉 커널 공간(kernel virtual memory address space)을 가리키는 포인터
- 이러할 경우 OS는 프로그램을 kill(exit)해줘야 한다.
- 이러한 잘못된 포인터에는 다음과 같은 경우가 있다.
Add system calls
- system call what we have to implement
- halt
- 핀토스를 종료시킨다.
- 사용자 프로그램이 halt를 호출하면 종료되도록 한다.
- exit
- 프로세스에서 나온다.
- thread_exit 함수를 사용한다.
- 다음을 출력시키면서 나온다.

- exec
- 자식 프로세스를 생성하고, 프로그램을 실행시킨다.
- unix의 exec과는 다르다.(unix의 exec는 단순히 exec만 하는 듯)
- 핀토스의 exec는 fork와 exec의 합성이라고 보아야 한다.
- wait (pid_t pid)
- 자식 프로세스(id가 pid인)가 제거될 때까지 기다린다.
- halt
Process Hierarchy
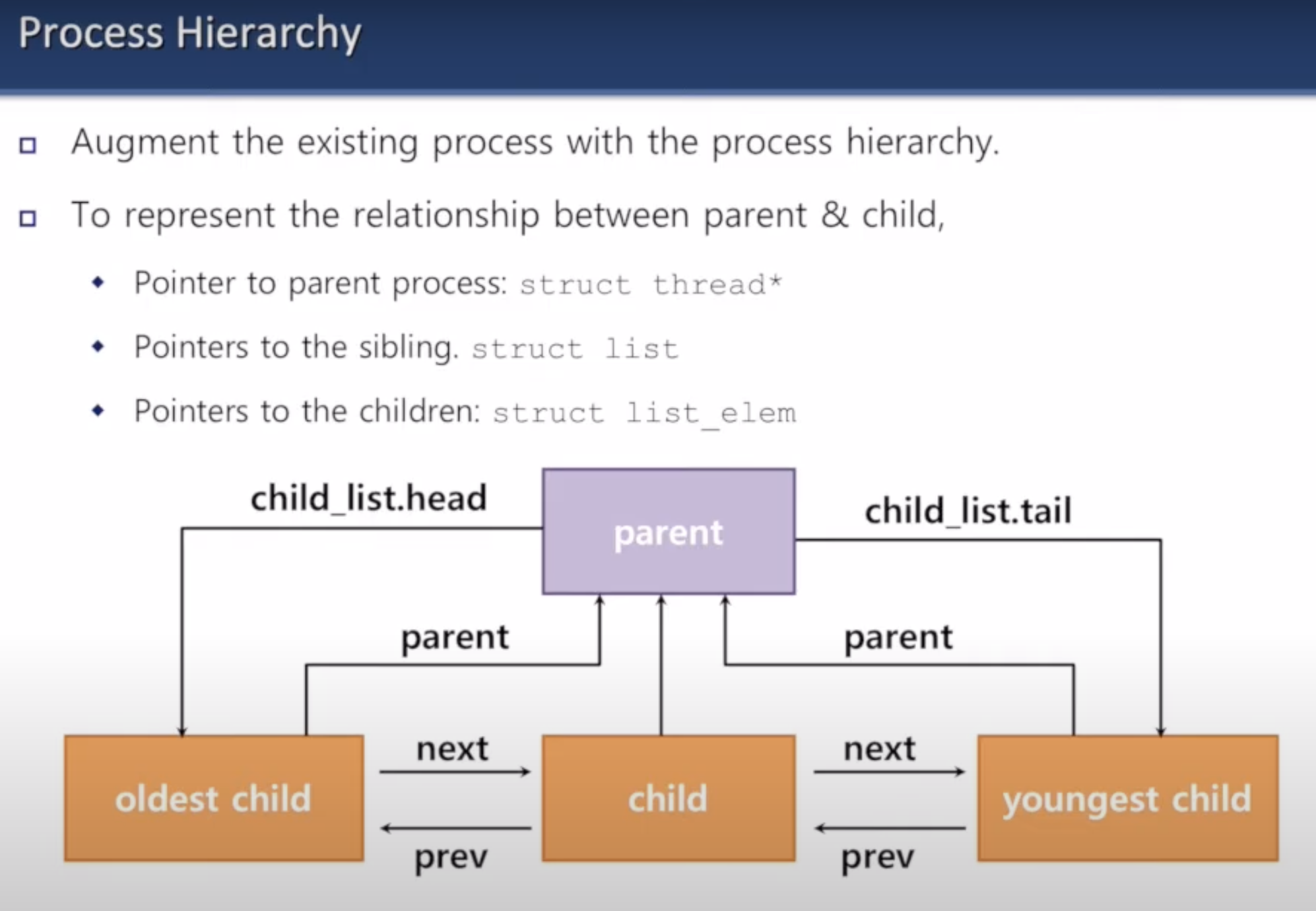
- 이번 프로젝트에서는 프로세스 계층 구조 개념을 도입해야 한다.
- 부모 프로세스와 자식 프로세스를 명시해야 한다.
- 그리고 형제들끼리 가르킬 수 있는 포인터가 필요하다.
- 부모 프로세스를 가르키는 포인터 : struct thread*
- 형제들을 가르키는(형제들을 포함하고 있는 리스트) 포인터 : struct list
- 형제 전부 그 자체들을 가르키는 포인터
- 자식들을 가르키는 포인터 : struct list_elem
- 자식 프로세스 하나 하나를 가르킬 수 있는 포인터
- 모든 프로세스를 가르키는 포인터를 만들 수도 있지만, 이는 낭비가 될 수 있어서 이중 연결 리스트로 프로세스들을 묶는다.
wait() system call
- pid라는 id 값을 가진 자식 프로세스가 종료되길 기다리고, 자식의 종료 상태를 검색한다.
- 자식 프로세스가 계속해서 실행되는 경우, 해당 자식 프로세스가 종료될 때까지 기다린다.
- 자식 프로세스가 exit을 호출 않았으나, kernel에 의해 종료되면 wait 함수는 -1을 반환한다.
- ex. 예외로 인해 종료되는 경우
- 자식 프로세스가 종료된 이후 부모 프로세스는, 그 프로세스의 descriptor 할당을 해제해야 한다.
System Call 구현
check_address
void
check_address (void *addr) {
struct thread *current_thread = thread_current();
if (is_kernel_vaddr(addr) || pml4_get_page(current_thread->pml4, addr) == NULL) {
exit(-1);
}
}- addr(가상 메모리 주소)이 만약 커널 공간을 가르키고 있다면
- 혹은 addr(가상 메모리 주소)이 물리 메모리와 맵핑되어 있지 않다면
- 프로세스를 종료한다.
#define is_kernel_vaddr(vaddr) ((uint64_t)(vaddr) >= KERN_BASE)- vaddr이 KERN_BASE 이상에 있다면, 즉 커널 공간을 가르키고 있다면 true를 반환한다.
- 64비트에서 포인터는 8바이트의 크기를 가진다.(32비트에서는 4바이트이다)
syscall_handler
void
syscall_handler (struct intr_frame *f UNUSED) { // SJ, 시스템 콜이 호출되면 시스템 콜 핸들러가 이 시스템 콜을 어떻게 다뤄야 할지 중재한다.
// TODO: Your implementation goes here.
// int syscall_number = f->R.rax; // SJ, 사용자 프로그램이 어떤 시스템 콜을 요청한 것인지 확인해야 한다.
switch(f->R.rax) {
case SYS_HALT:
halt();
break;
case SYS_EXIT:
exit(f->R.rdi);
break;
case SYS_CREATE:
create(f->R.rdi, f->R.rsi);
break;
case SYS_REMOVE:
remove(f->R.rdi);
break;
case SYS_WRITE:
f->R.rax = write(f->R.rdi, f->R.rsi, f->R.rdx);
break;
case SYS_OPEN:
f->R.rax = open(f->R.rdi);
break;
default:
exit(-1);
break;
}
// printf ("system call!\n");
// thread_exit ();
}default에 exit을 두어야 한다. switch 밖에 두면 안된다. 시스템 콜 한 번에 바로 exit되기 때문이다. 여러 번의 시스템 콜을 처리할 수 없게 된다.
syscall 함수들
void
halt (void) {
power_off(); // SJ, 핀토스 종료
}
void
exit (int status) {
struct thread *current_thread = thread_current();
current_thread->exit_status = status; // SJ, 종료시 상태를 확인, 정상종료면 state = 0
printf("%s: exit(%d)\n", current_thread->name, status); // SJ, 종료 메시지 출력
thread_exit();
}
bool
create (const char *file, unsigned initial_size) {
check_address(file);
return filesys_create(file, initial_size); // SJ, file 생성 성공 시 true를 반환한다.
}
bool
remove (const char *file) {
check_address(file);
return filesys_remove(file); // SJ, file 제거 성공 시 true를 반환한다.
}
int
write (int fd, const void *buffer, unsigned size) {
if (fd == STDOUT_FILENO) {
putbuf(buffer, size); // SJ, console에 대한 lock(console_lock)을 얻고 작업을 마친 후 lock을 해제한다.
return size; // SJ, console에 대한 작업도 겹치면 안되기 때문에 lock을 걸어준다.
}
}
int
open (const char *file) { // SJ, 디렉토리를 열어서? 디스크에서? 해당하는 파일을 찾아서, 그 파일만큼 메모리를 할당받고(filesys_open 안의 file_open에서 calloc) 파일 테이블에서 빈 fd에(add_file_to_fd_table) open한 파일을 배정시킨다.
check_address(file);
struct file *file_object = filesys_open(file);
if (file_object == NULL) {
return -1;
}
int fd = add_file_to_fd_table(file_object); // SJ, 해당 프로세스의 fd_table에서 빈 fd를 찾고 file을 배정시킨다.
if (fd == -1) {
file_close(file_object); // SJ, inode close하고 file이 할당 받은 메모리를 해제한다.
}
return fd; // SJ, 실패했으면 -1을 반환할 것이다.
}file descriptor table 관련 함수들
// SJ, file descriptor table 관련 helper functions
int
add_file_to_fd_table(struct file *file) {
struct thread *current_thread = thread_current();
struct file **fd_table = current_thread->fd_table;
while (current_thread < FDT_COUNT_LIMIT && fd_table[current_thread->fd]) { // SJ, file descriptor table에 담을 수 있는 총 갯수인 3 * 2^9개보다 작을 동안, 그리고 파일 테이블에서 해당 파일 디스크립터가 이미 배정되어있다면 +1하면서 새로 배정할 곳을 찾아야 할 것이다.
current_thread->fd++; // SJ, 만약 2, 3, 4가 배정되어 있었는데 3이 빠진다면, 새로운 파일을 추가할 때 while문의 2번째 조건으로 인해 while문을 빠져나오고 3에 배정할 것이다.
}
if (current_thread->fd >= FDT_COUNT_LIMIT) { // SJ, 테이블이 꽉차 있으면 -1을 반환한다.
return -1;
}
fd_table[current_thread->fd] = file; // SJ, fd_table[current_thread->fd] 이것도 포인터라고 보면 된다.
return current_thread->fd;
}
struct file *get_file_from_fd_table (int fd) {
struct thread *current_thread = thread_current();
struct file **fd_table = current_thread->fd_table;
if (fd < 0 || fd >= FDT_COUNT_LIMIT) { // SJ, 사용자 프로그램이 잘못된 fd를 요청하면 NULL을 반환한다.
return NULL;
} else {
return fd_table[fd]; // SJ, struct file을 가르키는 포인터를 반환한다.
}
}
void close_file_from_fd_table (int fd) { // SJ, 지금 할당을 해제시키는 것이 아니라, process_exit()할 때 모든 파일들을 할당해제 한다.
struct thread *current_thread = thread_current();
struct file **fd_table = current_thread->fd_table;
if (fd < 0 || fd >= FDT_COUNT_LIMIT) {
return;
} else {
fd_table[fd] = NULL;
}
}기타
- 어떤 시스템 콜을 요청했는지 intr_frame의 rax에 담겨져 있다.
- 해당 시스템 콜을 하고 나서 생긴 반환 값을 rax에 넣는다.
- intr_frame : 인터럽트 프레임, 실행 중인 프로세스와 레지스터 정보, 스택포인터(rsp), instruction count를 저장하는 자료구조이다. kernel의 stack에 존재하며, 인터럽트나 시스템 콜 호출 시에 사용된다.
- rsp : 스택 포인터
- 컨텍스트 스위칭이 일어나면, 컨텍스트 스위칭이 일어나는 그 시점에서 실행 중이던 정보들(레지스터 값들)을 담아 놓는다.
- 그러면 컨텍스트 스위칭이 일어나 CPU가 다른 프로세스를 진행하다가 다시 원래 프로세스가 진행되어야 할 때, 그 원래 프로세스의 인터럽트 프레임에 저장된 정보들(레지스터에 있던 값들)을 통해 그 시점부터 다시 진행할 수 있게 된다.
- 프로세스 A가 진행 중이다가 프로세스 B로 컨텍스트 스위칭이 일어나려고 하면
- 현재 CPU의 레지스터 값들을 프로세스 A의 인터럽트 프레임으로 옮긴다.(프로세스 A가 진행 중이었으니)
- 프로세스 B의 인터럽트 프레임의 값(이전에 프로세스 B도 CPU에서 진행된 적이 있다고 가정. 따라서 프로세스 B도 컨텍스트 스위칭에 의해 끊긴 적이 있으니 인터럽트 프레임에 어디를 실행했었는지 저장해뒀을 것이다)을 CPU 레지스터로 옮긴다.
- iretq 인스트럭션을 활용하여 프로세스 B를 진행한다.
- 인터럽트 상태에서 빠져 나오는 것이라고 한다.
- CPU에 프로세스 B를 진행할 정보를 다 담았으니 인터럽트 상태에서 빠져나오는 것으로 생각하자.
- thread : pintos에서 thread는 kernel thread이다. user thread는 user_thread라고 명시되어 있다.
- struct thread(쓰레드 정보로 name, priority, tid, interrupt frame 등을 담고 있다)는 kernel space에 할당되어 있다.
- pintos에서 command line은 128byte로 제한된다.
- kernel stack and user stack
- 프로세스의 user address space는 프로세스마다 각각 다르지만, kernel address space는 모든 프로세스가 동일하게 본다.
- 즉, 프로세스 A와 프로세스 B의 가상 주소들은 서로 다른 물리주소로 맵핑된다.
- 허나 커널 공간 주소는 모든 프로세스에서 동일한 물리 주소로 맵핑된다.
커널, 즉 OS는 당연히 1개가 알아서 OS 일을 하니까 그런 것이고, 프로세스 또한 각기 다른 프로세스들이니까(서로 다르니까) 서로 다른 물리주소로 맵핑되는 것이지 않을까?
- user mode에서 rsp는 0 ~ 3GB, kernel mode에서 rsp는 3GB ~ 4GB 사이의 값으 가지게 된다.
- 현대 시스템의 메모리는 직접적으로 접근되어지지 않는다.
- 물리적인 메모리가 지원하는 가상 주소 공간이 사용된다.
- 개념적으로는, 가상 / 물리 메모리 모두 page라고 불리는 chunk 단위로 쪼개진다. 이 page의 크기는 4096bytes로 대략 4KB이다.
- 일반적으로 프로세스는, user stack과 kernel stack을 각각 하나씩 가지고 있다. user mode에서 kernel mode로의 전환은 시스템 콜이나 인터럽트 발생 시 일어난다.
- 즉, rsp 레지스터는, 프로세스가 user mode이면 user stack의 top을 가르키다가 kernel mode로 전환 되면 kernel stack의 top을 가르키게 된다.
- 참고로 x86에서는 kernel stack의 크기가 8KB(2로 고정되어 있다. 프로세스 생성 때 한번 할당되어 작아지지도, 커지지도 않는다.
- user space에서 user stack은 아래로 성장하는 반면, heap(동적 할당)은 위로 성장한다.
- user stack은 프로세스가 user mode에서 실행되는 동안에만 사용된다.
- kernel stack은 kernel space의 일부이다. 따라서 사용자 프로세스가 직접적으로 접근할 수 없다.
- 사용자 프로세스가 syscall을 사용할 때 마다 cpu 모드는 kernel 모드가 된다. 이 시스템 호출 동안 프로세스의 커널 스택이 사용된다.
- 프로세스의 user address space는 프로세스마다 각각 다르지만, kernel address space는 모든 프로세스가 동일하게 본다.
- rbp를 기반으로 rsp가 -되면서 stack에 데이터를 쌓게 된다.
- pintos의 interrupt frame은 PCB 혹은 TCB라고 할 수 있다.
- 인터럽트가 들어오면, 본인의 데이터를 interrupt frame에 담고, 다시 자기 자신으로 돌아오기 위해
- 쓰레드가 생겨나면 4kB가 생기고 거기에 쓰레드에 대한 정보가 모두 담긴다.
- 여기에 intr_frame이 있다.
- 즉, 쓰레드마다 intr_frame이 1개씩 존재한다.
- 커널 모드에서는 사용자 프로세스 공간까지 모두 침범할 수 있다.
- 이 커널 모드로 넘어가는 순간을 해킹하면, 사용자 프로세스 공간까지 침범이 가능해진다.
- syscall
- 유저 모드에서 커널 모드로
- ex. write() -> define syscall3 -> syscall 함수-> syscall 함수 안의 syscall 어셈블리어 -> syscall.entry-S? -> Ring 0이 되어 커널모드가 됨 -> syscall_handler
- 파악 중
- do_iret
- intr_frame에 저장된 값들을 통해 원래 프로세스로 돌아간다.
- 파악 중
- 파일 테이블에 담긴 것은 파일을 가르키는 포인터들
- 파악 중
- inode는 파일에 대한 메타데이터를 담고 있는 자료구조이다.
- 다음을 통해 테스트 케이스에서 출력이 가능하다.
msg ("#######%d, %d\n", h1, h2);- 터미널에 다음과 같은 입력으로 테스트 케이스 1개씩 수행해볼 수 있다.
- pintos -v -k -T 60 -m 20 --fs-disk=10 -p tests/userprog/no-vm/open-twice:open-twice -- -q -f run open-twice
- pintos -v -k -T 60 -m 20 --fs-disk=10 -p tests/userprog/no-vm/fork-once:fork-once -- -q -f run fork-once
- pintos -v -k -T 60 -m 20 --fs-disk=10 -p tests/userprog/args-single:args-single -- -q -f run 'args-single onearg'
- ASSERT(condition)
- condition이 true이면 지나가고, false이면 PANIC에 빠뜨린다.
- PANIC
- 핀토스를 종료
- 종료되어지는 그 시점의 소스 파일 출력
- 그 파일 어디에서 종료되는지 line number 출력
- 어떤 function 진행 중이었는지 출력
- (어셈블리)call을 하면 iret을 통해 돌아온다.
- fork -> process_fork -> __do_fork에서 thread_current()가 자식 쓰레드인 이유
- fork하면 process_fork로 간다.
- process_fork에서 thread_create, 이 때 __do_fork 함수와 부모 쓰레드를 인자로 넘겨준다.
- 그러면 부모 쓰레드(현재 쓰레드)는 새로운 쓰레드를 생성하여, 새로운 쓰레드의 페이지 할당 및 파일 테이블 초기화 등을 수행한다.
- 이후 이 새로 생긴 쓰레드의 인터럽트 프레임의 rip에는 kernel_thread를, rdi에는 function을(__do_fork), rsi에는 부모 쓰레드를 저장한다.
- 그리고 나서 이 새로운 쓰레드를 ready_list로 보낸다. 이후 자신은 sema_down(&child_thread->fork_sema)되어 자식 프로세스의 fork가 정상적으로 완료될 때까지 대기하게 된다.
- 새로운 쓰레드가 자기 차례가 되면 컨텍스트 스위칭이 일어나 인터럽트 프레임에 저장되어 있는 정보를 바탕으로 CPU 제어권을 얻고 동작하게 될 것이다.
- 이 인터럽트 프레임의 rip에는 kernel_thread가 들어가 있기 때문에, 이 쓰레드는 처음부터(CPU에 올라간 순간) kernel_thread를 수행한다.
- kernel_thread에서 function(aux) 코드를 수행하게 되는데 아까 첫 번째 인자 rdi로 __do_fork를, 두 번째 인자 rsi로 부모 쓰레드를 넘겼다.
- 즉, 자식 쓰레드는 kernel_thread 함수를 실행하면서 kernel_thread 함수에 있는 function(aux)를 실행하게 되는데 이는 __do_fork(부모 쓰레드)와 같다.
- 자식 쓰레드는 __do_fork로 가서 부모의 인터럽트 프레임을 복사 받고, 부모의 파일 테이블을 복사 받는다.(할당 및 초기화는 앞 전에 부모 쓰레드가 수행하는 thread_create에서 완료된다)
- 자식 쓰레드는 fork 수행을 완료했으니 sema_up(&child_thread->fork_sema)을 하여 부모의 대기를 풀어준다. 그러면 부모 쓰레드는 ready_list로 들어갈 때 자신의 일도 수행할 수 있게 된다.
- 자식 쓰레드의 인터럽트 프레임에 부모 인터럽트 프레임을 저장해두었다.(fork 함수를 수행하면서 syscall 되었을 그 당시 수행하던 레지스터 정보들) do_iret을 통해 자식 쓰레드의 인터럽트 프레임의 레지스터 정보들이 CPU로 올라가게 되는데, 이는 부모 인터럽트 프레임과 같다. 따라서 fork된 자식 쓰레드는 부모가 syscall 당했을 때 직후의 일을 수행하게 된다. 그냥 fork가 제대로 되었다는 것이다. syscall 이후 다시 돌아왔을 때 부모랑 똑같은 곳(syscall 당하고 난 후 돌아와서 수행할 직후의 코드)에서 일할 수 있도록.
- ready_list에 있는 쓰레드들이 곧 TCB or PCB이다. (핀토스 기준)
- load 시에 file_deny_write해서 다른 프로세스가 이 파일에 쓸 수 없도록
- file_deny_write를 하면 inode_deny_write가 실행되어 deny_write_cnt를 ++한다.(1이상이면 쓰기 불가능, 0이면 쓰기 가능으로 deny_write_cnt는 0과 1의 값을 가지게 된다)
- file_close 시에 file_allow_write가 실행되서 다른 것들이 쓸 수 있게 한다.
- 어떤 쓰레드가, A라는 파일을 exec할 때 A가 load되는데, 이 쓰레드는 A가 수정되지 않은 채로, 원래 원했던 대로 실행되길 원한다. 따라서 load를 완료할 때 file_deny_write를 해서 다른 쓰레드가 A라는 파일에 write를 할 수 없게 한다. 쓰레드는 A라는 파일이 원래 원했던 대로 실행되길 원하기 때문이다.
- 다른 쓰레드가 write를 하려고 하면 syscall의 write를 사용하게 되는데, 여기 안에는 file_write가 포함되어 있고 file_write 안에는 inode_write_at이 포함되어 있다.
- 이 함수에 이 파일에 쓰기를 할 수 있는지 확인하는 변수인 deny_write_cnt를 확인해서 해당 변수가 1이상이면(불가능) 바로 return 0을 해서 시스템 콜 write의 반환 값을 0으로 하게 한다.(하나도 못읽었다라는 뜻으로)
- file_close가 되면 다시 다른 쓰레드가 write를 할 수 있게 된다.
- 다른 쓰레드가 write를 하려고 하면 syscall의 write를 사용하게 되는데, 여기 안에는 file_write가 포함되어 있고 file_write 안에는 inode_write_at이 포함되어 있다.
process_exec(void *file_name)- 유저(사용자)가 입력한 명령어를 수행할 수 있도록, 프로그램(프로세스)을 메모리에 적재하고 실행하는 함수이다.
thread_create(const char *name, int priority, thread_func *function, void *aux)thread_exit(void)do_iret(struct intr_frame *tf)- process_exec()에서 load()를 호출한다.
- load의 반환 값을 담은 success가 1이라면, 즉 load에 실패하지 않았다면(성공했다면) 새롭게 생성된 thread로 context switching을 진행한다.
- load는 성공 시 true, 실패 시 false를 반환한다.
- 만약 실패 시 process_exec()은 -1을 반환한다.
- load의 반환 값을 담은 success가 1이라면, 즉 load에 실패하지 않았다면(성공했다면) 새롭게 생성된 thread로 context switching을 진행한다.
- gp register(global pointer register) : ALU가 계산을 하고 있는 도중에 데이터가 들어와 잠시 보관해두는 곳
- 레지스터 구성
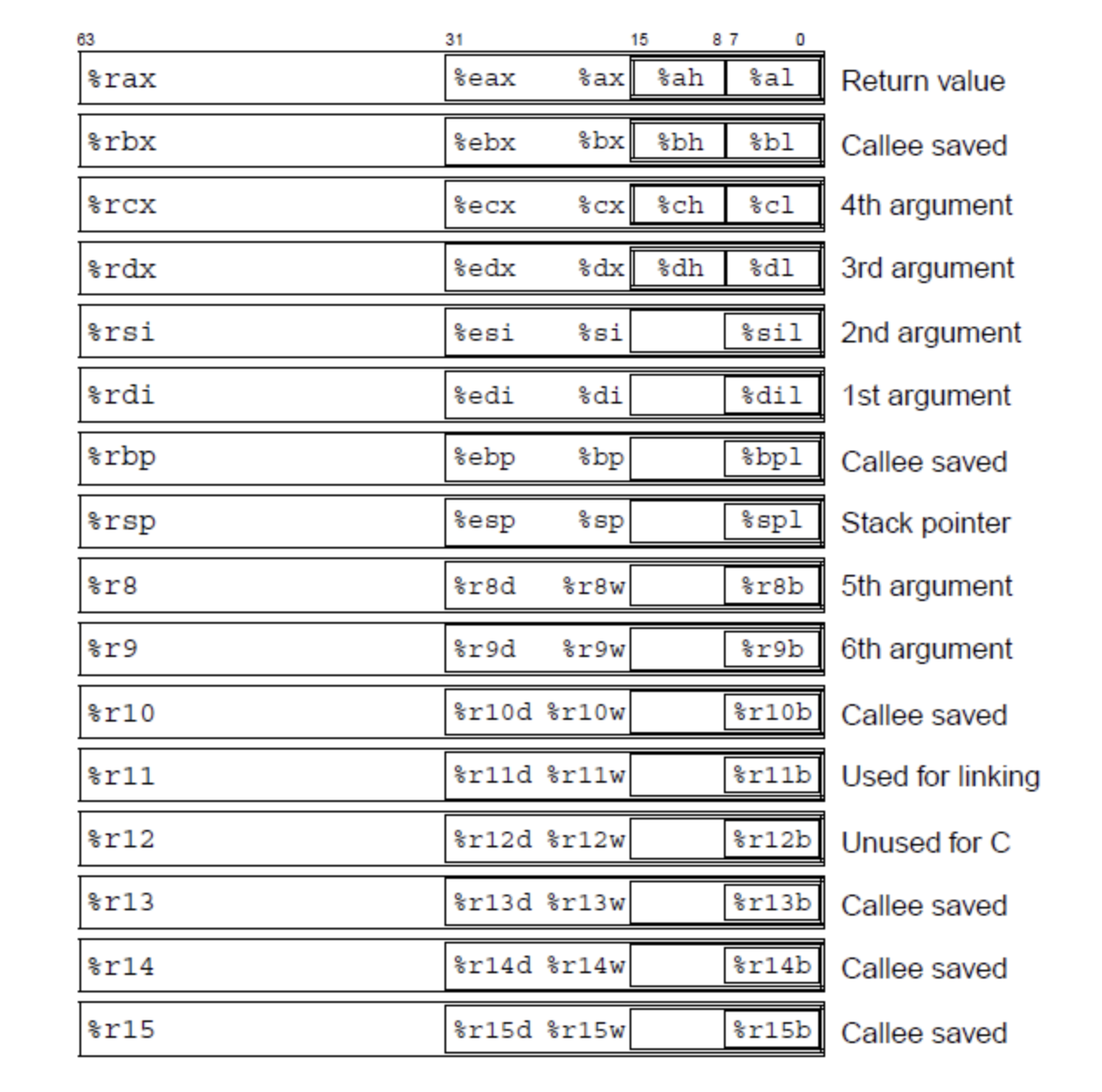
- %rax caller-saved
모든 함수의 return값을 담당한다. retq가 되었을때 반환되는 값들은 전부 rax라고 생각하면 된다.
- %rdi~r9 caller-saved
함수를 호출할때 넘겨주는 매개변수를 담당한다. 만약 매개변수가 6개를 넘는 함수인경우, stack주소를 의미하는 %rsp를 이용하여 stack에 매개변수를 넣어두고 사용한다.
순서는 rdi, rsi, rdx, rcx, r8, r9 순이다. (상단의 이미지에도 나와있다)
- %r10~r11 caller-saved
특별한 용도없음, 주로 함수내에서 아무렇게나 쓰고 버릴 수 있는 지역변수로 사용함. 단 r11은 linking으로도 사용함(우리 level에서는 중요하지 않음)
- %rsp callee-saved
Stack의 top주소를 의미하며, 한 함수내에서 rsp값은 바뀔 수 있어도, 모든 지역변수를 제거하여 rsp가 다시 원상태로 돌아와야 하기 때문에 rsp는 callee-saved이다.
- %rbx, %rbp, %r12~r15 callee-saved
이들은 callee-saved값으로, 다른함수를 갔다와도 바뀌지 않아야하는 값을 이 register에 넣는다, 재귀함수의 탈출조건이 대표적인 예시가 될 수 있겠다. (선언한 함수 내에서 바뀌는 것은 상관없다) (%r12의 경우 C언어 에서는 사용하지 않는다)
- %rip
위 이미지에도 없고 caller, callee로도 구별되지 않지만 중요한 레지스터. 이 레지스터에는 현재 명령이 실행되고있는 명령줄의 주소가 들어가있다. 이게 증가하면서 함수가 진행되고, 이게 jmp되면서 주소가 바뀌면, 다른 함수로 넘어가게 된다.
