8-1강, Memory Management 1
Logical vs Physical Address

- Logical address(=virtual address)
- 프로세스마다 독립적으로 가지는 주소 공간
- 각 프로세스마다 0번지부터 시작한다.
- CPU가 보는 주소는 logical address이다.
- 즉 주소 바인딩에 있는 그림에서 20, 30, 30, 40 주소는 가상 주소이다.
- 만약 이것이 진짜 물리적 주소라면, 코드를 짜는 사람은 일일히 빈 물리적 메모리를 찾아야 한다.(다른 프로그램이 해당 메모리를 이미 차지하고 있을 수도 있으니까)
- Physical address
- 메모리에 실제 올라가는 위치
- 가상 메모리도 결국엔 물리적인 메모리에 올라가야 프로그램이 실행될 수 있다.
- 주소 바인딩

- 주소를 결정하는 것.
- 프로세스마다 0번지부터 시작하는 주소 공간이 있지만 결국엔 물리적 메모리에 올라가야 실행이 가능하다. 그렇게 되면 주소가 바뀌게 된다.
- 이러한 것을 주소 변환 혹은 주소 바인딩이라고 한다.
- Symbolic Address
- 우리는 프로그래밍 시 변수 이름을 가지고 값을 저장하고, 함수를 호출할 때에도 함수 이름을 가지고 호출한다. 실제로 0x10208523 등의 주소를 사용해서 값을 저장하거나 함수를 호출하지 않는다.
- 이렇듯 우리는 숫자로 된 주소를 사용하지 않고 이름으로 된 주소를 사용하고 있다. 이를 symbolic address라고 한다.
- 이것이 compile되면 숫자로 된 주소가 된다.
주소 바인딩


- Complie time binding
- 컴파일 시에 주소 변환이 이루어진다.
- 컴파일 시점에 이미 물리적인 메모리 주소가 결정된다.
- 다른 물리적인 메모리 주소가 비어있음에도 불구하고 0번지부터 올리게 된다.
- 현대 컴퓨터에서는 사용하지 않는 방식이다.
- 메모리에 올라가는 메모리 주소를 바꿀려면 컴파일을 다시 해야한다.
- 컴파일 이후 바꿀 수 없기 때문에 절대코드라고 칭한다.
- Load time binding
- 실행이 시작될 때 주소 변환이 이루어진다.
- 프로그램이 시작되어 메모리에 올라갈 때 물리적인 메모리 주소가 결정된다.
- 프로그램 시작할 때 보니 500번지가 비어있어서 500번지부터 해당 프로그램을 올렸다.
- 실행 시 어느 위치든 올라갈 수 있기에 재배치 가능코드라고 칭한다.
- Execution time binding(=Run time binding)
- 프로그램이 시작되고 나서도 물리적인 메모리 주소가 바뀔 수 있는 방법이다.
- 하드웨어인 MMU가 바꿔준다.
- 실행 도중에 프로그램의 메모리 주소가 바뀔 수 있다.
- 현대 컴퓨터에서 사용되는 방식이다.
- 프로그램이 시작되고 나서도 물리적인 메모리 주소가 바뀔 수 있는 방법이다.
Memory-Management Unit(MMU)

- 주소 변환을 위한 하드웨어이다.
- 가상 주소 -> 물리 주소
- 사용자 프로그램과 CPU는 가상 주소만 다루고 있다.
- MMU가 물리적인 메모리로 주소 변환을 해주기 때문에 사용자 프로그램과 CPU는 알 필요가 없다.
Dynamic Relocation
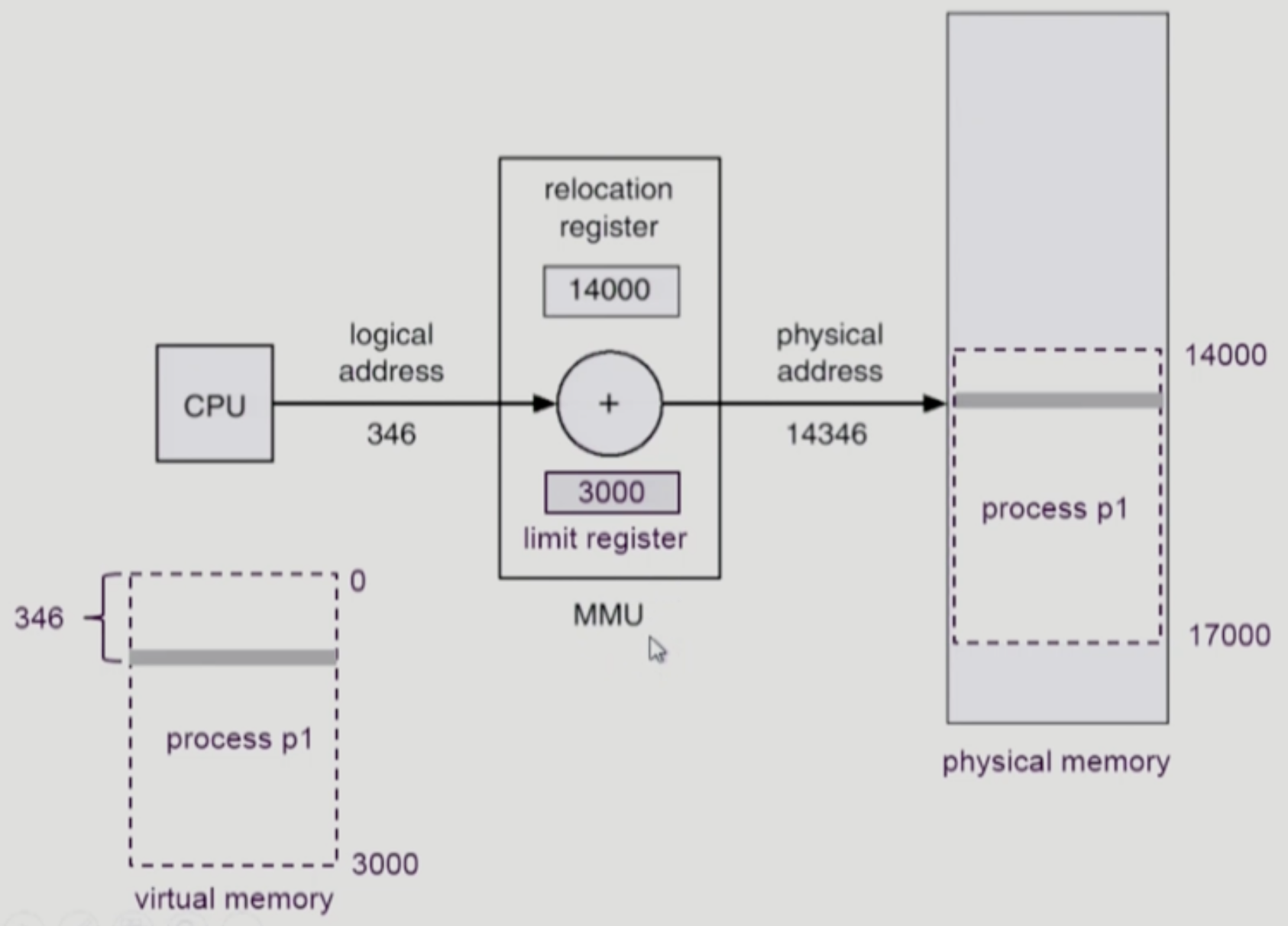
- relocation register(base register)와 limit register를 이용해 주소를 변환한다.
- 레지스터 2개를 이용한 MMU scheme
- CPU가 메모리 346번지(가상 주소)에 있는 내용을 달라고 하면(주소 변환이 필요)
- 가상 주소 0번지부터 346만큼 떨어져 있는 그 내용을 달라고 CPU가 메모리에 요청하는 상황이다.
- p1이 CPU에서 실행 중인 상황이다. 가상 주소 공간을 나타내고 있다.
- 물리적 메모리에서 시작 위치인 14000에 346을 더해서 물리적인 메모리를 읽어낸다.(relocation register는 미리 14000이라는 값을 저장하고 있는다)
- limit register
- p1은 3000만큼의 크기를 가지고 있다.
- 이를 limit register가 저장하고 있는다.
- p1이 악의적인 프로그램이라서 자신한테 없는 4000번지의 데이터를 읽어달라고 할 수 있다.
- 남의 프로그램 메모리를 보려하는 악의적인 시도이다.
- 이를 limit register가 막는 역할을 한다.
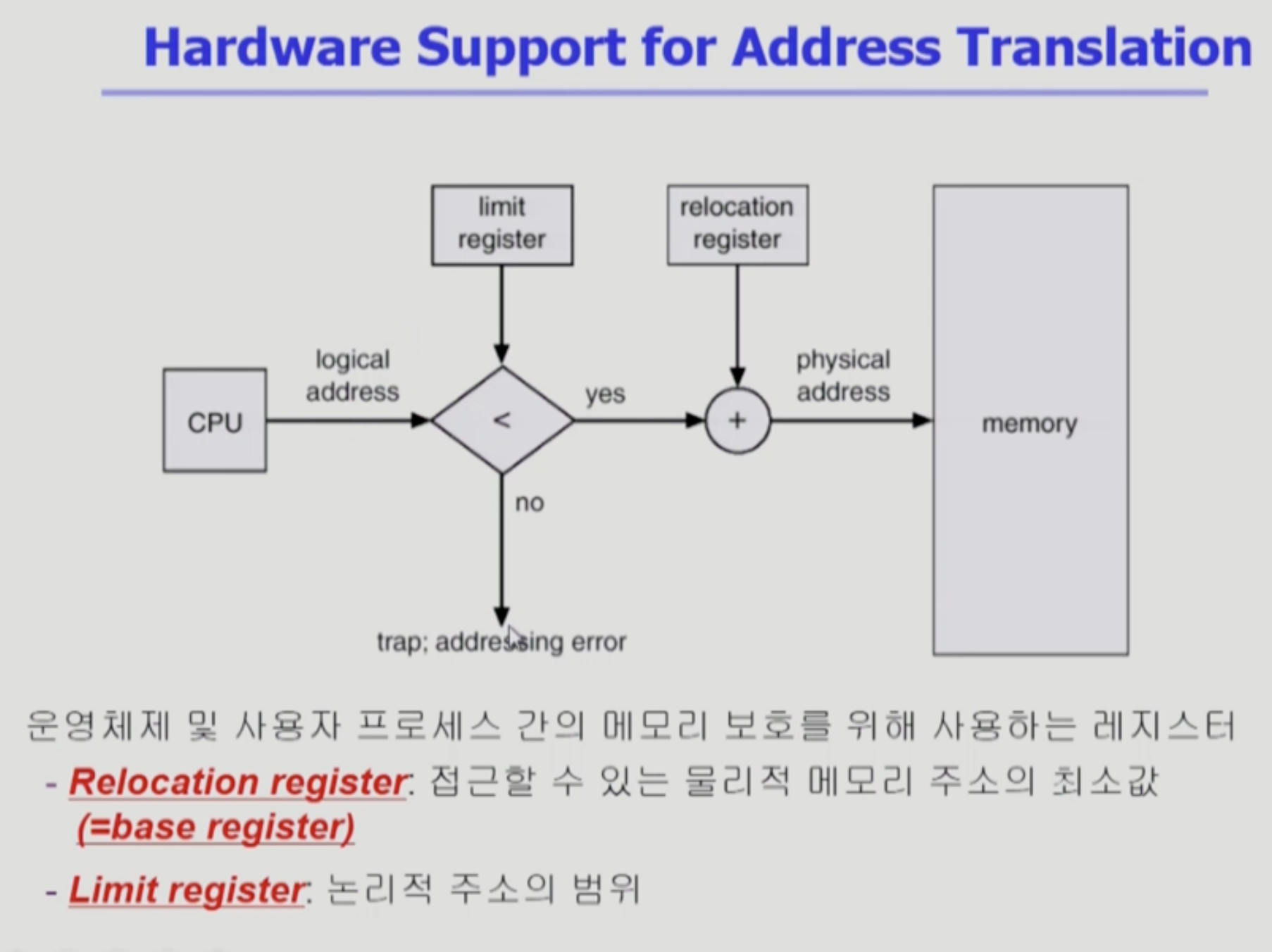
- 프로그램이 악의적인 시도를 하면 trap이 걸려 addressing error를 내어 프로그램을 중단시키거나 한다.
- 아니라면 물리적인 메모리 주소의 내용을 읽어 CPU에 전달한다.
Dynamic Loading
- 프로세스 전체를 메모리에 미리 다 올려놓는 것이 아니라, 해당 루틴이 불려질 때 메모리에 load하는 것.
- 필요할 때마다
- 한 번에 올려놓는 것을 정적(static) 로딩이라고 한다.
- memory utilization이 향상된다.
- 프로그램은 방어적으로 만들어지기 때문에, 상당 부분은 오류를 처리하는 루틴이 많다. 즉 일반적으로 사용이 안되는 루틴이 많이 포함되어 있다. 자주 사용되는 부분은 적게 포함되어 있다.
- 따라서 이렇게 자주 사용되는 부분이 적기 때문에 이 부분만 올리면 효율적이다.
- 오류를 처리하는 루틴까지 다 올리면 낭비가 될 수 있다.
- 이는 운영체제의 특별한 지원 없이, 프로그램 자체에서 구현이 가능하다.
- 프로그래머가 쉽게 dynamic loading할 수 있도록 OS는 라이브러리를 통해 지원한다)
- Loading : 메모리에 올리는 것이다.
Overlays
- 초창기엔 프로그램 한 개를 메모리에 올리는 것도 불가능했다.
- 어떤 부분이 실행되려면 그 부분만 메모리에 올리고, 다른 부분이 실행되려면 또 그 부분만 메모리에 올린다.
- 즉 프로그래머가 수작업으로 코딩을 통해 하게 된다.
- 이에 반해 동적 로딩은 라이브러리를 이용하기 때문에 쉽다.(어떻게 올리고 내리는지 자세히 코딩할 필요가 없다)
Swapping

- 프로세스를 메모리에서 디스크로 쫓아내는 것이다.
- 디스크로 쫓겨나는 것이 swap out, 다시 메모리로 돌아오는 것이 swap in
Dynamic Linking

- Linking을 실행 시간(execution time)까지 미루는 기법이다.
- Static linking
- 라이브러리가 프로그램의 실행 파일 코드에 포함된다.
- 실행 파일의 크기가 커질 수 있다.
- Dynamic linking
- 라이브러리의 함수가 실행될 때 연결된다.
- 라이브러리 호출 부분에 라이브러리 루틴의 위치를 찾기 위한 stub이라는 작은 코드를 둔다.
- 라이브러리가 이미 메모리에 있다면, 그 라이브러리의 함수가 위치한 곳으로 가고, 없으면 디스크에서 읽어온다.
- 운영체제의 도움이 필요한다.
Allocation of Physical Memory

- 물리적인 메모리를 어떻게 관리할 것인가
- 물리적인 메모리 그림이다.
- 낮은 부분에는 OS가 상주하고 있고 높은 부분에는 사용자 프로그램이 상주하고 있다.
- Contiguous allocation
- 프로그램이 올라갈 때 통째로 올라가는 것이 연속 할당
- Noncontiguous allocation
- 일부는 여기에, 일부는 다른 곳에 있는 것이 불연속 할당
- 현대 컴퓨터에서 사용하는 방식이다.
Contiguous allocation


- 고정 분할 방식
- A는 분할 1, 2만큼의 크기를 가지고 있기 때문에 분할 1로 들어갈 수 있다.
- 허나 B는 크기가 분할 1, 2보다 커서 분할 3로 들어가야 한다.

- 외부 조각
- 프로그램이 들어갈 수 있는 공간임에도 불구하고 사용이 안되었다.
- 나중에 새로운 프로그램이 외부 조각을 채울 수 있다.
- 그 때는 새로운 프로그램이 분할 2보다 작아서 내부 조각이 생길 수는 있다.
- 내부 조각
- 프로그램의 크기가 분할 3보다 작다. 그 안에서 남는 메모리 조각이 내부 조각이다.
- 프로그램 B한테 할당된 공간이지만 사용이 되진 않는다.
- 가변 분할 방식
- 프로그램이 실행될 때마다 차곡차곡 순서대로 메모리에 올리는 방법이다.
- 실행되다가 프로그램 B가 끝나면 그 공간은 빈 공간(외부 조각)이 된다.
- 이 공간에 프로그램 D가 들어갈 수는 없다. 따라서 아래 쪽에 들어가게 된다.
- 프로그램마다 크기가 다르기 때문에 외부 조각이 생길 수 있다.
- 내부 조각은 생기지 않을 것이다. 애초에 분할을 받지 않으니까
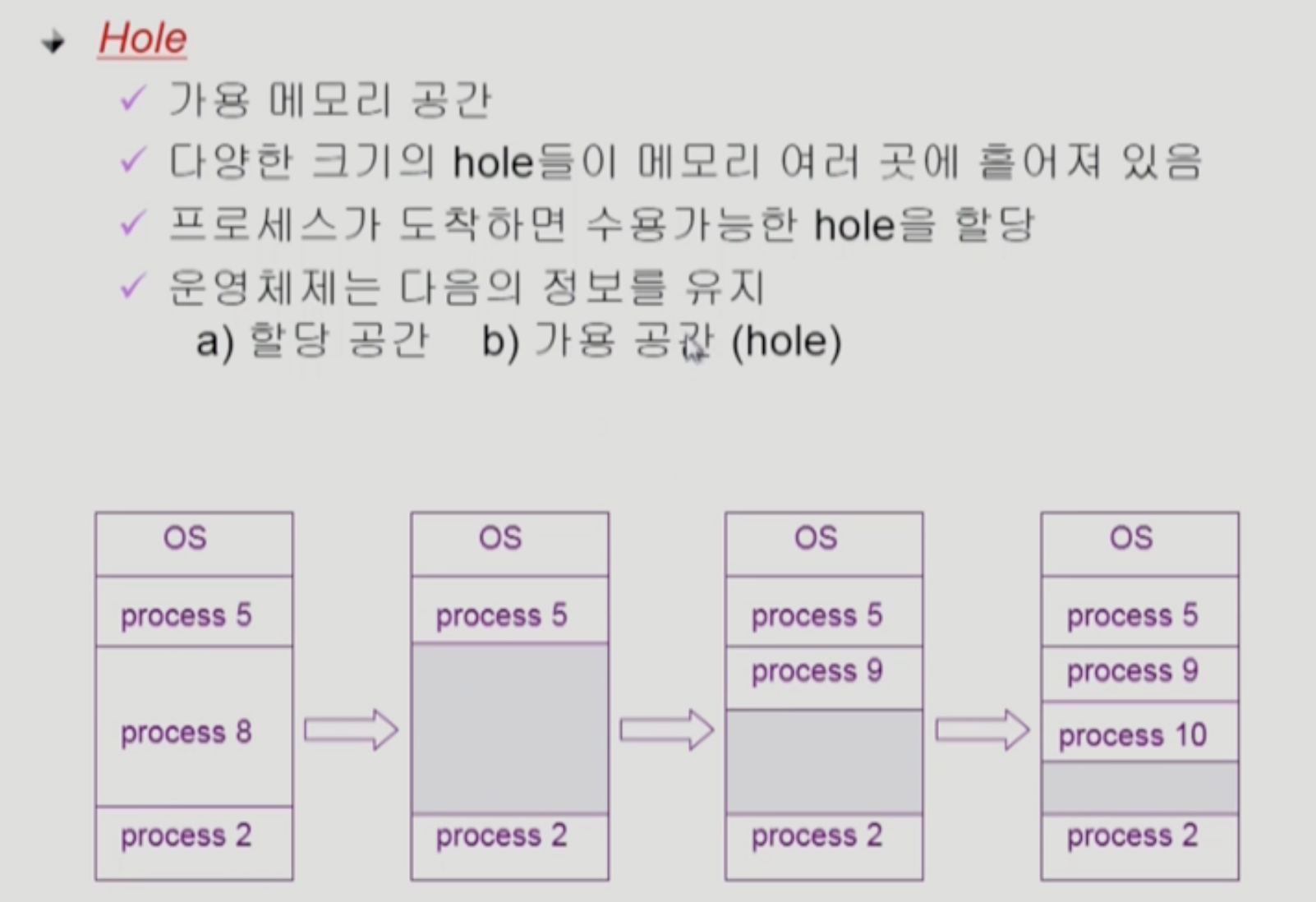
- Hole
- 어느 부분은 프로그램에 의해 사용되고 있고, 어느 부분은 Hole인지 정보를 가지고 있어야 한다.
- 새로운 프로그램이 생성되면 이 정보를 바탕으로 할당시킬 수 있어야 한다.
- 그러면 이 때 어디다가 프로그램을 넣어야 할지 문제가 생긴다.

- Dynamic Storage-Allocation Problem
- 생성된 프로그램을 어느 hole에 넣을 것인가
- First-fit
- hole 중 제일 처음 발견되는 hole에다가 할당하는 것이다.
- hole을 찾는 오버헤드가 적다.
- Best-fit
- hole을 다 살펴보고 hole의 크기와 가장 맞는 것에 할당시킨다.
- hole을 찾는 오버헤드는 크지만, 메모리 오버헤드가 적다.
- Worst-fit
- 가장 큰 hole에 할당시켜 나간다.
- 더 큰 프로그램이 할당될 수 있음에도 불구하고 작은 프로그램이 할당될 수 있다.

- Compaction
- ex. 디스크 조각 모음
- 외부 조각(external fragmentation) 문제를 해결해준다.
- 사용 중인 메모리 영역을 한 군데로 몰고, hole들을 다른 한 곳으로 몰아서 큰 block을 만드는 것이다.
- Run time binding이 지원되어야 한다. 실행 중에 재배치가 이루어지기 때문이다.
Noncontiguous allocation
- contiguous allocation처럼 프로세스를 통째로 올리지 않는다. 단위로 나눠서 메모리에 올린다.
- 페이징 기법을 이용해서 이러한 문제들(hole들이 균일하지 않아 어디다 넣을 것인가, 혹은 한 군데로 밀어넣는 compaction 등의 문제)을 해결할 수 있다.
- 프로그램을 페이지 단위로 짜른다.
- 주소 변환이 복잡해진다. 주소 변환을 페이지 단위로 해야되기 때문이다. 프로그램 전체를 올리는 것이 아니라 페이지 단위로 짜르고 각각을 따로 메모리에 올리기 때문에 주소 변환 횟수가 많아지고 복잡해진다.
- 페이지 단위로 짜르는 페이징 기법이 아닌, 의미 있는 단위(code, data, stack 등)로 짜르는 것이 segmentation이다.
- 한 프로세스의 code, data, stack 등의 segment를 각기 다른 메모리 주소에 할당한다.
- code 자체도 함수 단위로 의미 있는 단위로 segment가 나눠질 수 있다.
- 크기가 일정하지 않아서 dynamic storage-allocation problem이 생길 수 있다.
- 맨 마지막에 가서는, 페이지 단위로 나뉘어진 프로그램의 마지막이 꼭 4kB는 아닐 수 있으니까 짜투리가 남을 수 있다.
8-2강, Memory Management 2
Paging
- 프로그램을 구성하는 주소 공간이, 동일한 공간의 페이지로 나뉘어져서, 각각의 페이지가 필요에 따라 물리적인 메모리에 올라갈 수 있는 방법이다.
- 따라서 각각의 페이지들을 주소 변환해주어야 한다. 이는 limit register, relocation register 2개만으로는 주소 변환이 불가능하다.
Paging Example

- 페이징 기법에서 주소 변환을 위해, 페이지 테이블(배열)이 사용된다.
- 위 그림에서 중간 그림이다.
- 논리적인 페이지가 물리적인 메모리에서 각각의 페이지가 어디에 올라가 있는가.
- page 0은 물리적인 메모리(페이지 프레임)에서 어디에 올라가 있는가(1번 페이지 프레임)를 페이지 테이블이 저장하고 있다.
- 물리적인 메모리에서 페이지가 들어갈 수 있는 공간을 페이지 프레임이라고 한다.
- 위 그림에서 오른쪽 그림이다.
- 프로그램마다 페이지 테이블이 존재한다.
- 이 페이지 테이블은 메모리에 넣는다.
Address Translation Architecture
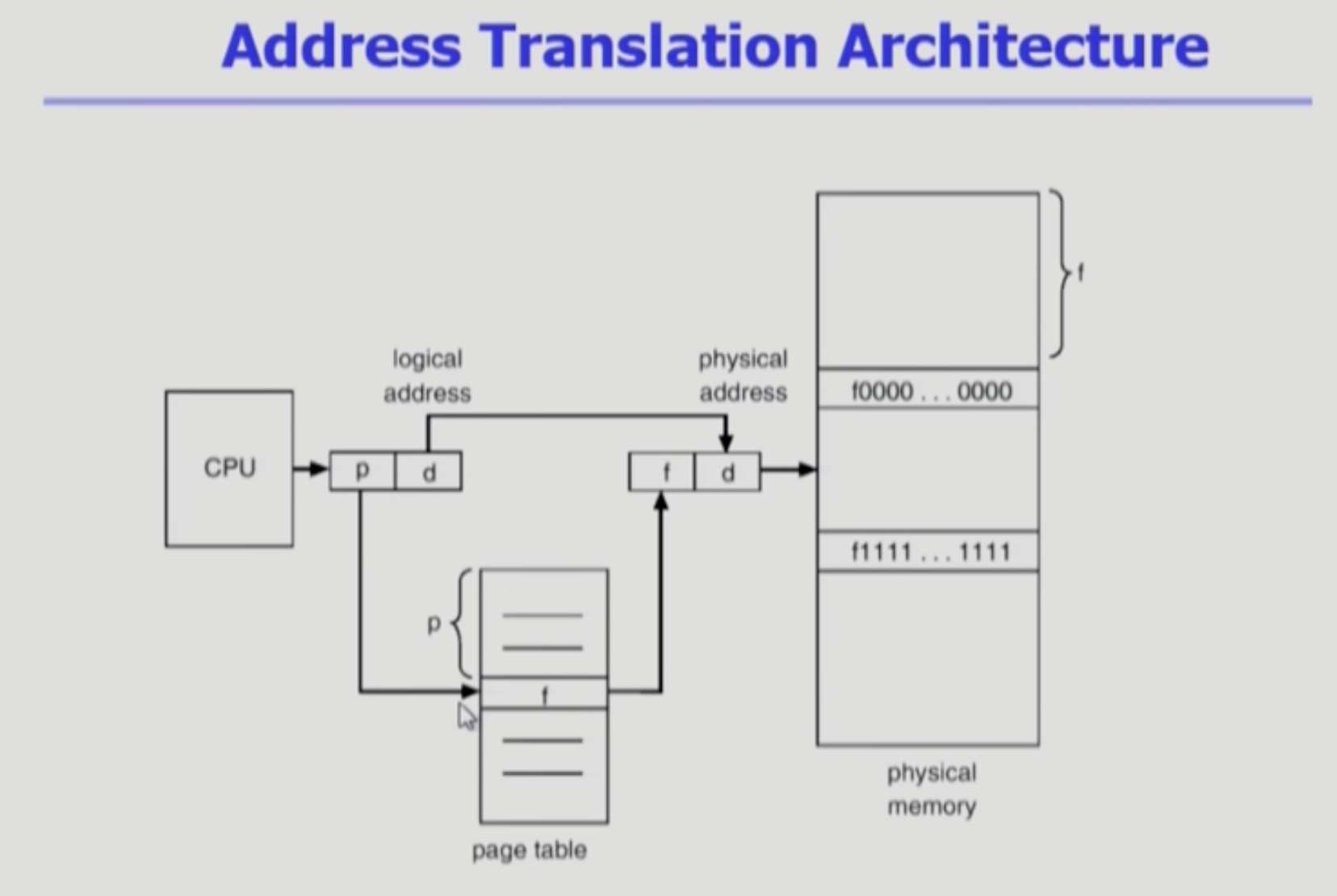
Implementation of Page Table

- 페이지 테이블은 메인 메모리에 상주하고 있다.
- 메모리에 위치한 페이지에 접근하기 위해서는 주소 변환을 한 다음에 접근해야 하는데
- 이 주소 변환을 하려면 페이지 테이블을 접근해야 하고
- 이 페이지 테이블 또한 메모리에 있다.
- 즉 페이지에 접근하려면 주소 변환(메모리 접근)이 2번 필요하다.
- 메모리에 위치한 페이지 테이블에 접근하는 것 1번 + 그 페이지를 통해 메모리에 위치한 실제 data에 접근하는 것 1번
- 메모리 상에 페이지 테이블이 어디 있는지, 그 시작 위치를 Page-table base register (PTBR)이 가리킨다.
- 페이지 테이블이 길이가 있을텐데, 그 길이를 Page-table length register (PTLR)이 보관하고 있는다.
- 앞서 본 relocation(base) register, limit register가 비슷한 개념(페이지 테이블을 이용하지 않을 때 가상 주소를 물리적, 즉 실제 메모리 주소로 변환할 때 쓴 레지스터)으로, 이제 메모리 상의 페이지 테이블이 어디 위치하는지, 그 페이지 테이블의 길이가 얼마인지를 나타내는 데에 사용되는 셈이다.
- 메모리에 2번 접근하다보니 속도가 느려질 수 있다.
- 메인 메모리보다 빠른, 일종의 캐시인 TLB(하드웨어)가 속도를 빠르게 해준다.
- 데이터 저장을 위한 캐시가 아닌 주소 변환을 위한 캐시이다.
- 메모리에 접근하기 전에, TLB를 통해 주소 변환이 가능한지 먼저 살펴본다.
- TLB에 없는 경우 페이지 테이블(프로세스마다 존재)을 이용하게 된다.
- 빈번히 참조되는 entry 몇 개만 가지고 있는다.
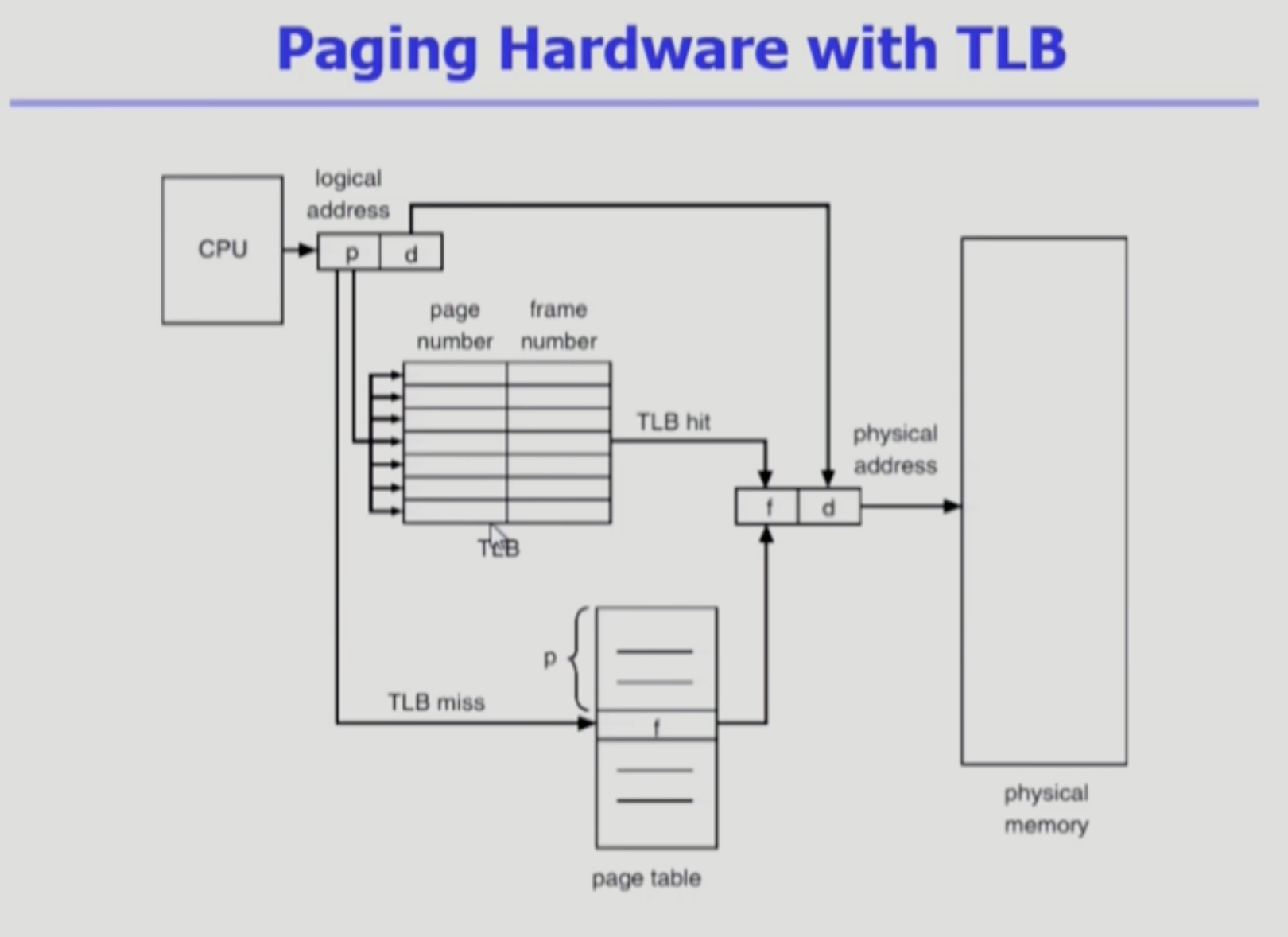
- 논리적인 페이지 번호 p, 그 p가 물리적인 메모리로 주소 변환된 f 이 2가지를 쌍으로 가지고 있어야 한다.
- 빈번히 참조되는 entry 몇 개만 가지고 있는다.
- 해당 p가 있는지 전체를 탐색하게 된다. 그러다가 없으면(TLB 미스(캐시 미스)) 페이지 테이블로 넘어간다.
- 전체를 탐색해서 p가 있는지 확인하기 때문에 시간이 오래 걸릴 수 있다.
- 이를 막기 위해 parallel search(병렬 탐색)이 가능한 Associative register를 사용한다.

- 다른 프로세스로 넘어가면(컨텍스트 스위칭), 프로세스마다 주소 정보가 다르기 때문에(페이지 테이블을 각각 가지고 있기 때문에, 서로의 페이지 테이블, 즉 각각의 페이지 위치가 다르기 때문에) TLB를 비워야 한다.
Effective Access Time

- 실제 메모리에 접근하는 시간을 알아보자
- TLB에 접근하는 시간, Associative register lookup time = e
- 메인 메모리에 접근하는 시간, memory cycle time = 1
- 즉 TLB에 접근하는 시간인 e는 메인 메모리에 접근하는 시간보다 훨씬 작을 것이다.
- TLB로부터 찾아지는 비율 = a
- 그렇다면 실제로 메모리에 접근하는 시간이 어느정도 될 것인가
- a만큼, 즉 TLB를 통해 주소 변환 정보가 찾아지는 만큼은(위 그림에서 hit에 해당)
- TLB에 접근한 시간 + 주소 변환을 안해도 되고 그냥 바로 메모리에 접근해도 되는 시간(한 번)
- (1 + e)a
- TLB에 접근한 시간 + 주소 변환을 안해도 되고 그냥 바로 메모리에 접근해도 되는 시간(한 번)
- 주소 변환 정보가 TLB에 없는 경우, 즉 1 - a인 경우(위 그림에서 miss에 해당)
- TLB에 접근한 시간(확인했으나 없었다) + 페이지 테이블 시간(한 번, 페이지 테이블도 물리적 메모리 상에 있으니 여기에 접근하려면 메인 메모리에 접근하는 시간인 1만큼 걸린다) + 페이지 테이블에서 주소 변환 정보를 찾아 진짜 원하는 주소의 메인 메모리에 접근하는 시간(한 번)
- (2 + e)(1 - a)
- TLB에 접근한 시간(확인했으나 없었다) + 페이지 테이블 시간(한 번, 페이지 테이블도 물리적 메모리 상에 있으니 여기에 접근하려면 메인 메모리에 접근하는 시간인 1만큼 걸린다) + 페이지 테이블에서 주소 변환 정보를 찾아 진짜 원하는 주소의 메인 메모리에 접근하는 시간(한 번)
- 총 2 + e - a
- a가 거의 1에 가깝다고 한다. e는 TLB, 즉 캐시에 접근하는 시간이기 때문에 메인 메모리에 접근하는 시간인 1보다 훨씬 작을 것이다.
- 페이지 테이블만으로 찾을 때는 메인 메모리에 2번 접근하기 때문에 2라는 시간이 걸리는 반면,
- TLB를 이용하면 1 + e 정도 걸리는 셈이고 e 또한 매우 작다고 하니 1 정도 걸리는 셈이다. 즉 2배 정도 빠르게 된다.
- 즉 TLB라는 캐시를 이용하면 원하는 주소의 물리적 메모리 접근이 빨라진다.
- a만큼, 즉 TLB를 통해 주소 변환 정보가 찾아지는 만큼은(위 그림에서 hit에 해당)
Two-Level Page Table


- 페이지 테이블이 2단계로 존재한다.
- 컴퓨터에서 어떤 방식을 적용하는 데에는 2가지 측면이 있다.
- 시간을 줄이거나, 공간 낭비를 줄이거나
- 페이지 테이블을 2번 방문해야하니 시간이 줄어들진 않는다.
- 2단계 페이지 테이블은 공간 낭비를 줄여준다.
- 프로그램이 페이지 단위로 나뉘어서 메모리로 올라오기 때문에, 물리적인 메모리보다, 프로그램의 가상 메모리가 크더라도 실행하는 데에는 문제가 없다.
- 32비트 사용 시 2^32바이트 (4GB)만큼의 주소 공간을 표현할 수 있다.
- 4GB를 4KB로 쪼개면 1MB로, 총 1MB의 페이지 테이블 엔트리 갯수를 가질 수 있다.
- 엔트리 하나의 크기는 4B 정도 된다.(32비트 주소 체계이므로)
- 따라서, 페이지 엔트리 크기가 4바이트이므로 페이지 테이블 용량은 4MB가 된다.
- 그러나 대부분의 프로그램은 페이지 중 일부분만을 사용하게 된다. 따라서 page table 공간 낭비가 심해진다.
- 어느 페이지를 찾으려면 페이지 테이블에서 선형 탐색을 해야한다.
- 중간에 NULL이라고 해도 빼고 만들 수는 없다. 배열이기 때문에
- 따라서 페이지 테이블을 1개만 쓰면 페이지 테이블 전체를 다 만들어야 한다.

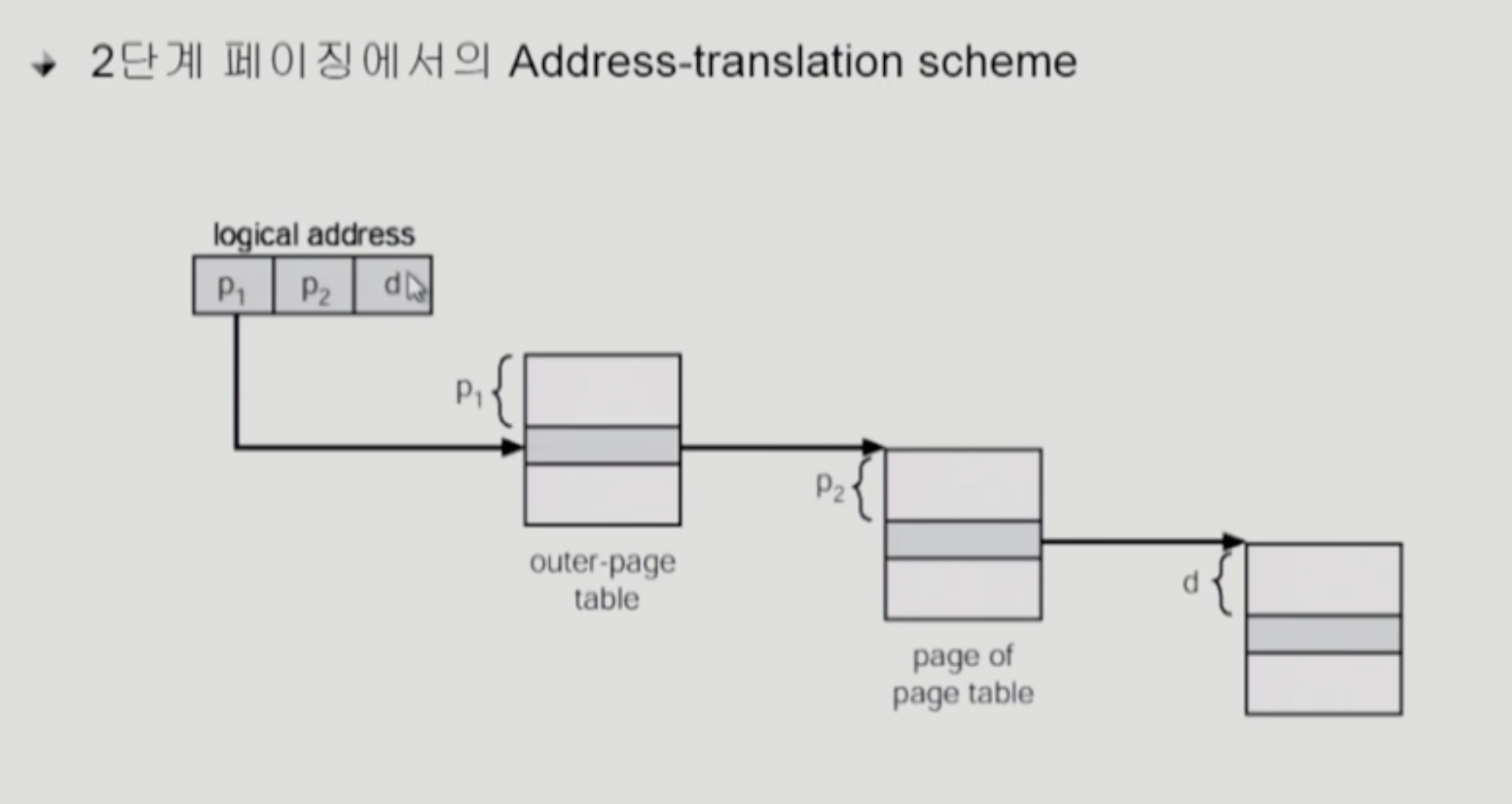
- 페이지 테이블을 쪼개서, 페이지 테이블 자체를 페이지로 구성한다.
- 그 페이지 테이블 크기는 페이지이므로 4KB이고, 엔트리가 4B이므로 총 4K개의 엔트리가 들어갈 수 있다.
(멀티레벨 페이지 테이블이 이해가 되지 않아 일단 생략)
Segmentation

- 의미를 가지는 단위로 쪼개는 것. code, data, stack과 같이 세그먼트로 쪼개는 것.
Segmentation Architecture

- 세그먼트별로 주소 변환을 위해 세그먼트 테이블이 존재
Segmentation Hardware


메타몽 닮음 :) email: alohajune22@gmail.com