[논문 리뷰] TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents
.jpg)
TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents
Thomas Wolf, Victor Sanh, Julien Chaumond & Clement Delangue
Main Issue
- Consistent Personality의 부족, 일관성 없는 대답
- Long-term-memory의 문제로 인해 마지막 dialogue 대화 보다, 이전에 했던 대화 들이 고려 되지 못함
- "I don't know"와 같은 기계적인 대답
Imporvement
- 대답(answer)의 타당성
- 사전 정의된 성격(personality)과 대화 이력(history)의 일관성(consistent)
- 유창성과 문법적 정확성
Model
모델은 12 개의 디코더로만 이루어진 transformer 구조를 활용하였다. 여기에는 원래 self-attention 구조(BERT에서 활용되는 구조)와 다른 점이 있는데 i시점에서는 i번째 이후의 토큰에 대해서는 attention이 부가되면 안되므로 이를 방지할 수 있는 masked-self-attention heads구조가 활용되었다. transformer 구조의 decoder와 같으므로 transformer의 구조 혹은 GPT2를 확인하면 더 자세히 알 수 있다.
또한 tokenizer에는 bytepair encoding(BPE tokenizer)을 활용하였다.
Training
Pre-Traing
기존 pre-trained model과는 살짝 다른 점이 있다.
긴 문장과 단락을 이용하기 위해 sentence-level이 아니라 document-level로 pre-training 진행
Fine-tuning
Input의 변형
본 논문에서는 dialogue 사용을 persona를 같이 input으로 사용하였다. 여기서 Persona란, Personality의 집합체라고 생각하면 된다. 본 논문에서의 Persona 데이터는 다음과 같이 정의 되어 있다.

위 그림처럼 input은
(i) 성격의 집합(persona), (ii) PERSON1의 대화(혹은 history) 그리고 (iii) PERSON2의 대화 이렇게 3파트로 구성된다.
그리고 이들을 3가지 타입의 임베딩으로 변환 시켜 모델에 사용한다. 이는 기존 BERT나 GPT2와 같다고 보면 된다. 다만, 문장의 segment를 3부분으로 나눈 것에만 집중하면 된다.
즉, 기존 BERT나 GPT모델과 다른 점은 문장의 타입을 persona(성격의 집합) , person1의 발화, person2의 발화 이렇게 3가지로 나누어 임베딩을 시켰다는 점이다.
Multi-task learning
TransferTransfo에서는 문장 생성뿐 만 아니라 분류에도 집중하였다. 즉, 두 개의 Loss를 사용하였다.
두 가지 Loss 함수는 다음과 같다: (i) a next-utterance classification loss, and (ii) a language modeling loss
다음 발화에 대해 이것이 fake(= distractor) 인지 real인지 분류하는 next utterance classification loss와 language model에 대한 loss 이렇게 두 가지를 설정한다.
1) Language model loss 기본적인 seq2seq 구조를 따르고 이는 올바른 하나의 문장을 형성하는 데에 도움을 준다. 즉, 전 단어와 다음 단어 사이가 어색하지 않게 생성하는 것을 도와주고 문장이 문법적으로 어휘적으로 적절한가에 대해 판단한다.
예를 들어, I am good thank you 라는 문장을 보면, I 다음에 am, thank 다음에 you가 온다. 이는 올바른 문장이다. 그러나 I is good thank they 이라는 문장을 보게 되면, I 다음에 is, thank 다음에 they가 온다. 이는 어색한 문장이다. language model loss는 I is good thank they처럼 어색한 문장이 아닌 I am good thank you처럼 올바른 문장이 되게끔 도와준다. 단어와 단어 사이의 전후 관계를 파악하여 문법적으로 어휘적으로 올바른 문장을 생성한다. 논문에서는 language model loss에 CrossEntrophyLoss를 활용하였다고 한다.
2) Next utterance classification
TransferTransfo에서는 Input에는 두 가지 특징의 데이터가 들어간다. real data와 fake data이다. 그림에서 윗부분을 보면, ‘You have a nice dog’은 ‘How are you today?’ 에 대한 대답으로 알맞지 않다. 이보다는 밑에 부분인, ‘I am good thank you’가 더 적당하다. 이때 위에 부분은 fake data, 아래 부분은 real data이다.
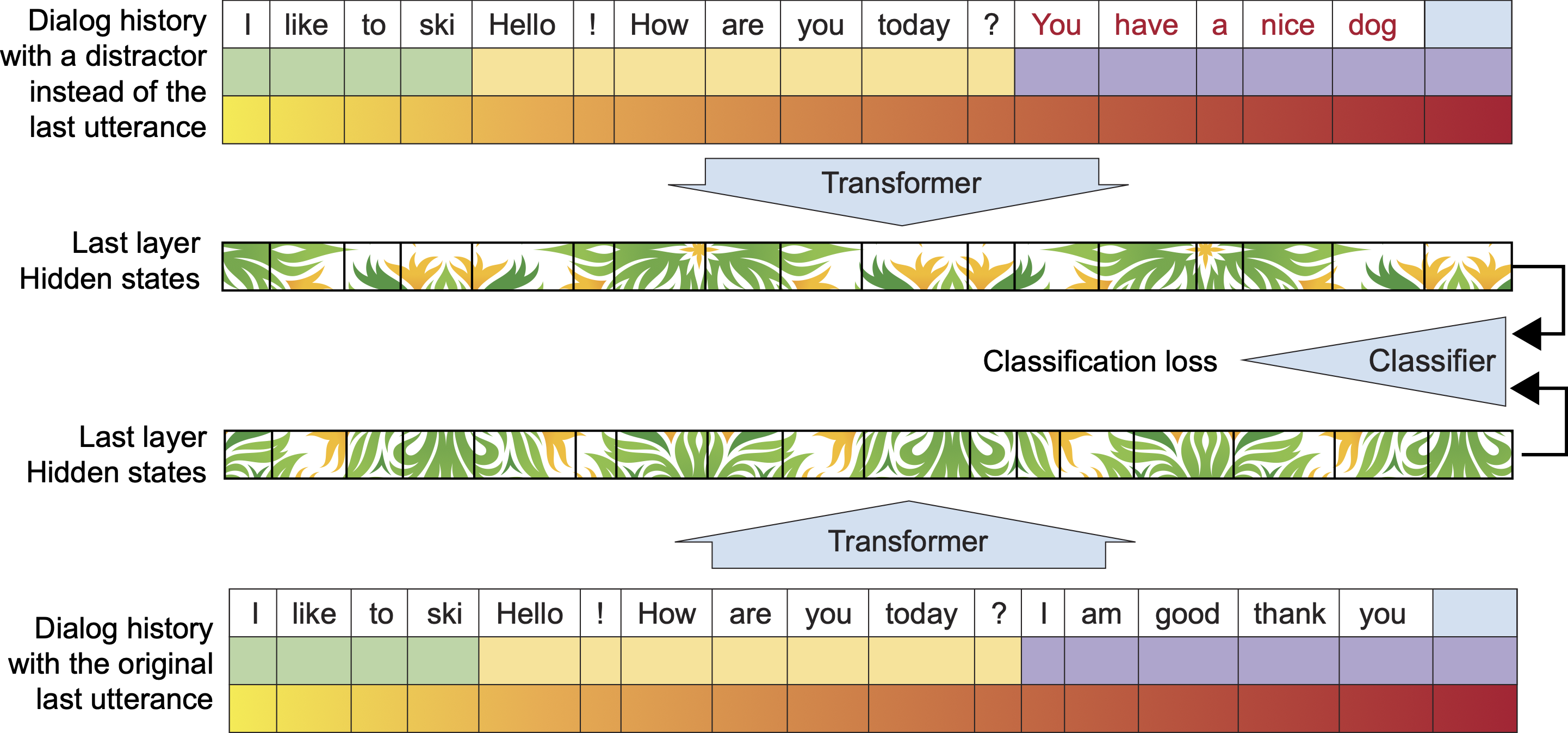
이러한 두 가지 특징의 데이터를 집어넣는 이유는 다음과 같다. Language model은 You다음에 have, have 다음에 a, a 다음에 nice, 그리고 nice 다음에 dog가 나오게 해준다. 그리고 이렇게 생성된 ‘You have a nice dog’은 language model 관점에서는 올바른 문장이다. 그러나 How are you? 다음에 오기에는 어색하다.
next utterance classification은 이러한 어색한 연결구조를 방지하기 위해 필요하다. 전에 있던 대화들과 (history) 이어지지 않는 대화가 생성되면, 이는 챗봇으로는 실격이다. 따라서 a next-utterance classification loss는 같은 history상(문맥상)에서 올바르게 이어질 말(real data)과 말은 되지만 어색하게 이어질 말(fake data = distractor)을 넣어주어 이 둘을 서로 구분하는 것을 도와주게 한다.
이러한 분류 작업을 통해 persona와 그 이전 발화(history)에 대해 일관성 있는 대답이 나오는 것이 가능하게 된다.
