적대적 공격의 정의
딥러닝 모델의 내부적 취약점을 이용하여 만든 노이즈(perturbation)값을 활용하여 의도적으로 오분류를 이끌어내는 입력값(적대적 예제; adversarial example)을 만들어 내는 공격
여기서 추가되는 노이즈는 인간의 눈으로는 인지할 수 없을 만큼 작게끔 제약이 걸림

적대적 공격의 분류
- White-box attack
공격자가 target 모델에 대해 아키텍쳐, 입력, 출력, 가중치를 포함한 모든 것을 알고 있고, 접근할 수 있음 - Black-box attack
공격자가 target 모델의 입력과 출력에 대해서만 접근 가능하며, 모델의 가중치와 아키텍쳐에 관한 정보는 모름
적대적 공격 방법 소개
- FGSM(Fast Gradient Sign Method)
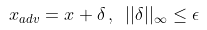
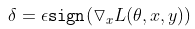
- 학습이 완료된 모델에 test 데이터()가 입력되었을때 오분류를 이끌어내기 위해서 에 노이즈 를 element-wise로 더한 적대적 예제 를 생성
- 이 때 노이즈가 사람 눈에 imperceptible 하도록 제한하기 위해 제한을 걺. 제한이란, 생성된 노이즈의 분포 중 각 픽셀들의 절댓값이 정해진 크기보다 클 수 없음을 의미함. 예를 들어, 이 4인 경우 생성된 노이즈의 분포는 -4 4에서만 값을 가질 수 있음
- 노이즈 수식을 뜯어보면, 의 ground truth class label 에 대한 loss 함수의 기울기와 동일 방향으로(; 일반적인 gradient descent의 반대, 즉 gradient ascent라고 이해할 수 있다), 크기 제한을 걸어서 만들어 졌다는 것을 확인 가능
- Test input에 대해서 loss 함수 gradient를 직접 구해야하기 때문에 White-box attack의 범주에 들어감
- Surrogate 모델을 써서 target 모델을 시뮬레이션 한다면 현실적인 공격 시나리오에서 활용 가능
class FGSM(Attacker):
def __init__(self, model, config, target=None):
super(FGSM, self).__init__(model, config)
self.target = target # 오분류할 target class가 정해진 경우
def forward(self, x, y): # x: test input, y: test input의 ground truth class label
x_adv = x.detach().clone()
if self.config['random_init']: # Random start flag
x_adv = self._random_init(x_adv)
x_adv.requires_grad = True
self.model.zero_grad()
logit = self.model(x_adv) # Projection
if self.target is None: # target class가 정해지지 않은 경우 ground truth class에 반대되는 gradient ascent를 수행
cost = -F.cross_entropy(logit, y)
else: # target class가 정해진 경우 target class로 gradient descent를 수행
cost = F.cross_entropy(logit, self.target)
if x_adv.grad is not None:
x_adv.grad.data.fill_(0)
cost.backward()
x_adv.grad.sign_() # Applying sign function
x_adv = x_adv - self.config['eps] * x_adv.grad # x_adv = x + delta
x_adv = torch.clamp(x_adv, *self.clamp) # Clamping the example
return x_adv- PGD(Projected Gradient Descent)
- FGSM 방법을 조금 응용한 것으로, n번의 step만큼 공격을 반복하고 최종 변형된 에 제약을 걸어 clamping 해줌. 멀티 step을 도입한 것 이외에도, 각 step마다 이전 FGSM과 다르게 learning rate 개념을 도입하여 말고 learning_rate만큼 인풋 데이터 의 변형이 일어나도록 함
- 모델의 오분류를 유도하기 위한 local maxima를 찾는 최적회를 구하기 위해 first-order만을 사용한 공격 중에서 PGD를 이용하는 것이 가장 효과적임. 현재까지 universal first-order adversary로 알려져 있음
- Test input에 대해서 loss 함수 gradient를 직접 구해야하기 때문에 White-box attack의 범주에 들어감
class PGD(Attacker):
def __init__(self, model, config, target=None):
super(PGD, self).__init__(model, config)
self.target = target # 오분류할 target class가 정해진 경우
def forward(self, x, y): # x: test input, y: test input의 ground truth class label
x_adv = x.detach().clone()
if self.config['random_init']: # Random start flag
x_adv = self._random_init(x_adv)
for step in range(self.config['attack_steps']):
x_adv.requires_grad = True
self.model.zero_grad()
logit = self.model(x_adv) # Projection
if self.target is None: # gradient ascent
loss = F.cross_entropy(logit, y, reduction='sum')
loss.backward()
grad = x_adv.grad.detach()
grad = grad.sign()
x_adv = x_adv + self.config['attack_lr'] * grad
else: # gradient descent
assert self.target.size() == y.size()
loss = F.cross_entropy(logit, self.target)
loss.backward()
grad = x_adv.grad.detach()
grad = grad.sign()
x_adv = x_adv - self.config['attack_lr'] * grad
# Projection
x_adv = x + torch.clamp(x_adv-x, min=-self.config['eps'], max=self.config['eps'])
x_adv = x_adv.detach()
x_adv = torch.clamp(x_adv, *self.clamp)
return x_advTest시 적대적 공격을 할 때 test data에 대한 ground truth label이 필요한 점에 대하여
- 일반적인 CV 모델 test시에는 test data에 대한 label을 모른다는 가정하에 진행되지만, 적대적 공격 실험 세팅에서는 test data에 대한 label을 알고, 그 label에서 최대한 멀어지게끔 만든다. 즉 살짝 다른 실험 세팅이라고 생각하면 됨
- White-box 공격에서는 test data에 대한 ground truth label을 알고, grey-box / black-box 공격에서는 test data에 대한 label을 몰라서 한번 forwarding을 거쳐 나온 pseudo-label을 ground truth label 마냥 활용하기도 함
적대적 공격에 대한 방어 방법
- Adversarial training (GAN에서의 adversarial training과 좀 다른 개념)
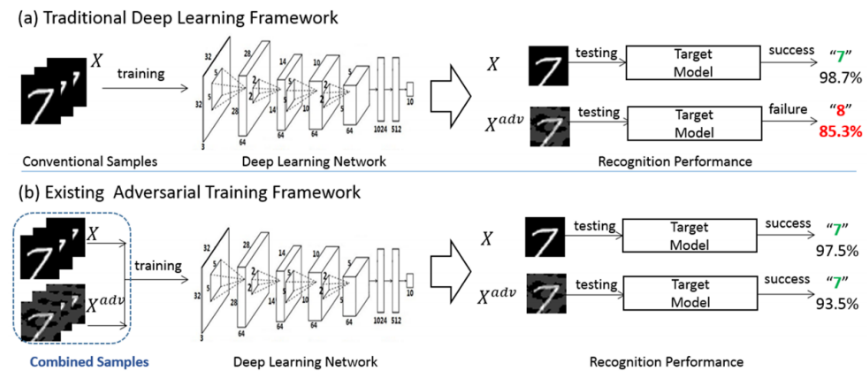
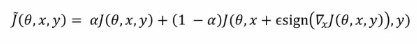
- 적대적 예제도(generated by FGSM, PGD etc) 모델 학습에 함께 사용하는 것
- 적대적 예제의 특징을 학습한 모델은 적대적 예제에 대한 강건성을 보장받고 입력값에 대해 민감도를 줄이는 방향으로 학습이 될 수 있음
- 적대적 예제 = worst case input으로 생각할 수 있음
본 포스트는 본인의 이해를 돕기 위해 여러 참고 자료를 정리하여 쓰여졌음
https://www.youtube.com/watch?v=TfDO2guk0ug
https://rain-bow.tistory.com/entry/%EC%A0%81%EB%8C%80%EC%A0%81-%EA%B3%B5%EA%B2%A9Adversarial-Attack-FGSMPGD
