CS224W 3강 - Node Embeddings
-
Traditional ML Pipeline에서 hand-crafted하게 만든 feature vector 말고, automatic하게 feature을 학습하는 방법이 없을까? Graph Representation Learning
-
"Similarity of embeddings between nodes indicates their similarirty in the network" Similarity Preserving
-
Embedding Nodes
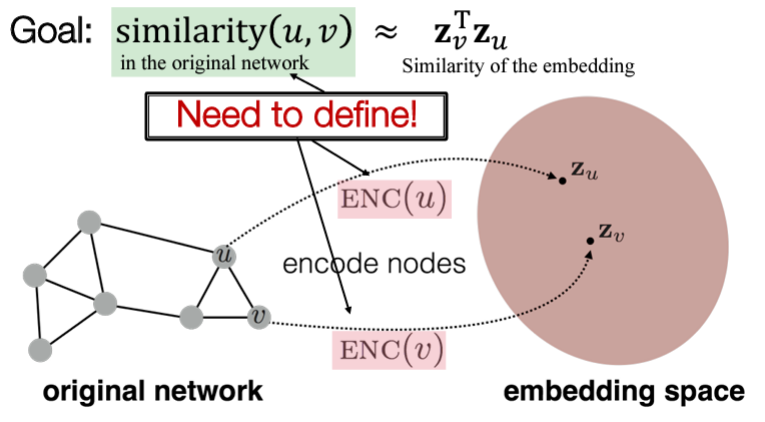
- For simplicity, 인접행렬 등 그래프의 구조 정보 이외의 추가적인 attributes는 무시함
- 임베딩 공간에서의 similarity는 주로 dot product (angle btw two vectors) 로 계산됨 Decoder
- Task-Independent feature vectors
- Unsupervised / Self-supervised methods node label, node feature 사용 안함!
정의 해야하는 것...- Encoder
1-1. Shallow Encoding: 간단한 lookup 테이블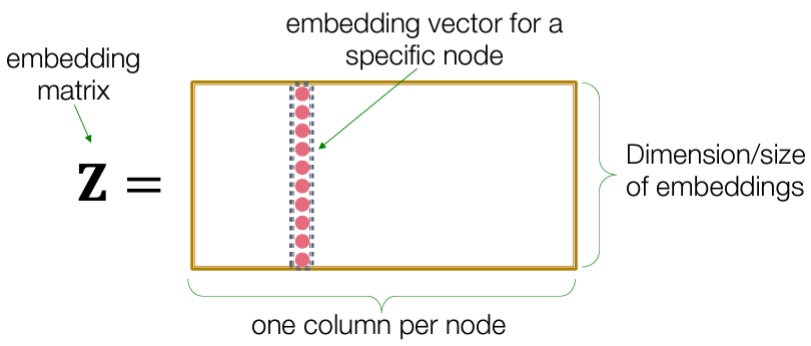 ex) DeepWalk, node2vec
ex) DeepWalk, node2vec
1-2. Deep Encoding: GNNs (Lecture 6)
- Encoder
-
Original graph에서의 node similarity measure
Random Walk (with some random walk starategy R (e.g., DeepWalk, node2vec)) 근본적으로, 왜 직접적인 이웃 노드로 임베딩을 학습하지 않고 random walk를 하는지에 대한 이유는 다음과 같다.
근본적으로, 왜 직접적인 이웃 노드로 임베딩을 학습하지 않고 random walk를 하는지에 대한 이유는 다음과 같다.
- Node degree 의 경우에는 계산량이 너무 많기 때문에
- 인접 n-hop neighbor까지만 본다면, graph search의 관점에서 제한적이기 때문에
Q) Slide 24에서 random walk의 효율성이 높은 이유를 random walk 상에서 동시에 방문되는 노드 쌍만 고려하면 된다고 적혀있는데, 결국 softmax를 구하기 위해서는 모든 노드 쌍을 고려해야하는 것 아닌가? 진짜로 효율성이 좋다고 할 수 있나?

 Random walk strategy R로 얻은 node u의 neighborhood nodes가 u로부터의 임의의 random walk에서 visit될 확률을 최대화하는 node u의 feature vector을 학습함.
Random walk strategy R로 얻은 node u의 neighborhood nodes가 u로부터의 임의의 random walk에서 visit될 확률을 최대화하는 node u의 feature vector을 학습함.
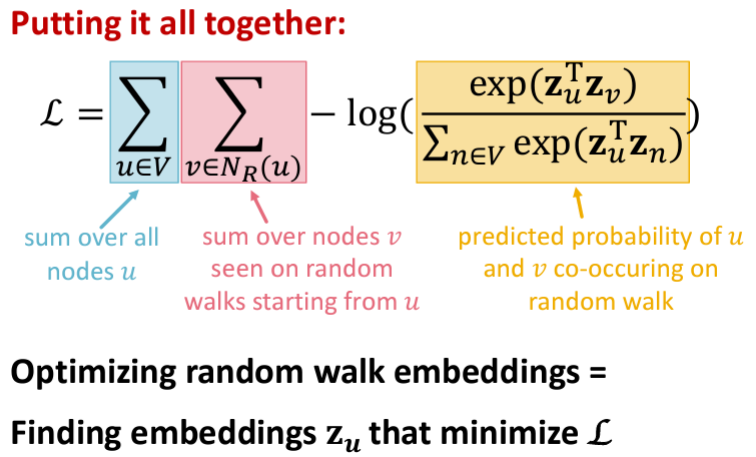 하지만 이중 for문의 time complexity & softmax 분모에서 모든 노드 쌍에 대한 정규화 부분 때문에 too expensive
하지만 이중 for문의 time complexity & softmax 분모에서 모든 노드 쌍에 대한 정규화 부분 때문에 too expensive
softmax에 negative samplingNegative Sampling 이란?
Softmax에서 전체 노드에 대해 normalization을 하는 것은 complexity가 크므로, 전체 노드 말고 subset에 대해서만 normalization을 하자는 아이디어이다. 그렇다면 어떤 subset을 선택해서 사용해야할 지에 대한 논의가 되어야 하는데, NLP에서는 보통 타겟 단어와 연관성이 없을 것이라고 추정되는 단어를 뽑는다. 직관적으로도 말이 되는게, 당연히 전체 노드 집합을 대체할 하위 집합을 구하는거면, 전체 노드를 가장 잘 represent 할 수 있는 하위 집합을 구하는게 당연하다. 일반적으로 흔한 단어일수록 현재 타겟 단어와의 연관성이 낮다고 판단하여 전체 corpus에서 가장 빈번하게 등장하는 단어들로 negative sample의 subset을 구성한다. 그래프에서는 node degree가 높은 노드들로 subset을 구성한다.
그래프에서는 node degree가 높은 노드들로 subset을 구성한다.
Nearby nodes 를 결정하는 random walk strategy R에 따라 다음과 같이 분류할 수 있다.
2-1. DeepWalk : Fixed-length, unbiased random walks starting from each node
2-2. Node2Vec : Fixed-length, biased 2nd order random walk starting from each node
local view (BFS) + global view (DFS)
2nd order: remembering where the walk came from (return parameter이 있으니까..)
biased: 다음 traverse할 노드를 선택하는 확률이 모두 같지 않고, p와 q 두 파라미터에 의해 차등적으로 이동하게 됨파라미터 설명 Return parameter p 이전 노드로 돌아가는 정도 In-out parameter q
(Walk away parameter)BFS(inwards)와 DFS(outwards)의 비율 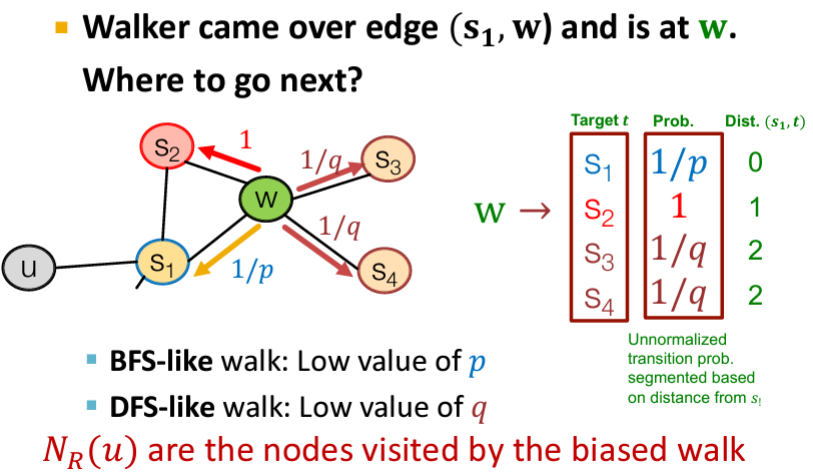 Q) Slide 46에 Linear-time complexity: 모든 노드마다 fixed set of random walk가 있기 때문에, 그래프 사이즈에 linear한 시간복잡도를 가짐
Q) Slide 46에 Linear-time complexity: 모든 노드마다 fixed set of random walk가 있기 때문에, 그래프 사이즈에 linear한 시간복잡도를 가짐
-
Embedding Graphs
-
Sum/Avg over node embeddings
-
그래프상 모든 노드와 연결되어 있는 virtual super node를 만들고 그 node에 대한 embedding을 graph embedding으로 여기는 것
-
Anonymous walk embedding
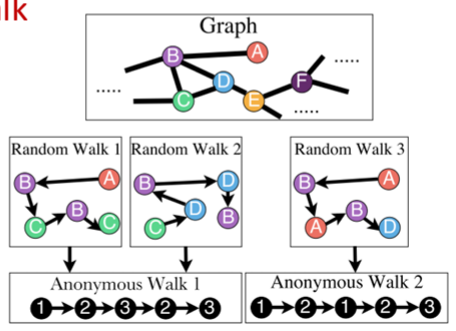 Anonymous walk: 각 random walk에서 지나온 노드 각각 말고, 지나온 순서만을 고려함
Anonymous walk: 각 random walk에서 지나온 노드 각각 말고, 지나온 순서만을 고려함3-1. Fixed embedding: 2강의 Graphlet feature과 유사한 아이디어로, represent the graph as a probability distribution over the sampled anonymous walks
3-2. Learnable embedding: Learn a graph embedding together with all the anonymous walk embeddings
Embed walks s.t. the next walk can be predicted

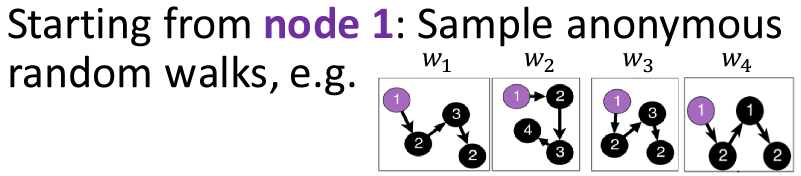
Q) window 내에서 oc-occur 되는 anonymous walk를 예측하도록 임베딩을 학습하는데, 위 그림에서 보다시피 샘플링된 랜덤 워크들은 저마다의 관계가 없는 독립적인 개체이고, window를 두고 그 내에 있는지 예측하는게 무슨 의미인지 모르겠음..
Q) Slide 63에 "Embed anonymous walks, concatenate their embeddings to get a graph embedding" 이라고 되어 있는데 위에 슬라이드 수식과 상충됨?
-
-
학습된 embedding을 활용하는 downstream tasks
- Link prediction시에는 양 노드의 node embedding을 함께 활용하여 모델의 입력으로 사용
- Concatenate
- Hadamard product
- Sum/Avg
- Distance (L2)
- Link prediction시에는 양 노드의 node embedding을 함께 활용하여 모델의 입력으로 사용
