CS224W 4강 - Graph as Matrix: PageRank, Random Walks and Embeddings
- Node Importance
-
Link Analysis를 통해 구함
- PageRank: Teleport to any node
관점에 따라 PageRank는 서로 다른 세 방식으로 해석될 수 있음- Flow model: 벡터형, 행렬형 수식으로 표현 가능
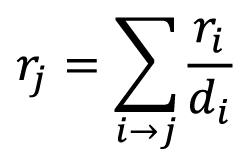

- Stationary distribution for the random walk
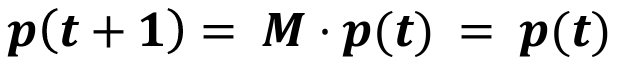
- "Rank matrix r" = Principal eigenvector of stochastic adjacency matrix with eigenvalue=1
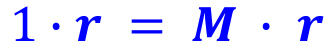
- Simple & scalable한 "Power Iteration"을 통해 r을 구할 수 있음!
- Power Iteration이란 그냥 간단하게 Rank matrix r을 초기화한 후, 에 따라 수렴에 이르기까지 r을 반복적으로 업데이트하는 방법
- "Dead ends" & "Spider traps"의 문제를 해결하기 위해 랜덤 텔레포트를 도입함 (Google matrix) r can be efficiently computed by power iteration of the stochastic adjacency matrix (G; 랜덤 텔레포트 도입한 Google matrix)
- Flow model: 벡터형, 행렬형 수식으로 표현 가능
이제 Node Importance 개념을 확장시켜서 추천 문제에 적용해봄. 추천 문제는 기본적으로 User-Item bipartite graph 데이터가 근간인데, 적절한 추천을 위해서는 Node Proximity를 구하는 것이 필수적임. PageRank가 랜덤 텔레포트를 통해 전체적인 맥락에서 Node Importance를 따졌다면, PPR이나 Random Walk with Restarts는 텔레포트할 노드를 제한함으로써(query nodes), query nodes에 대한 node importance, 다시 말해 query node에 대한 node proximity를 구할 수 있게 됨.- Personalized PageRank(PPR): Teleport to a subset of nodes
- Random Walk with Restarts: Teleport to a single query node
- PageRank: Teleport to any node
-
- Node/Graph Embedding
지금까지 다뤘던 Similarity based embedding은 모두 Matrix Factorization이랑 동치이다.
Shallow encoding은 Node similarity를 정의하는 방법에 따라 다음과 같이 나뉘는데,- 그냥 두 노드가 엣지로 연결되어 있다면 similar이라 간주
Embedding = "Adjacency matrix의 MF"
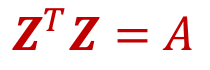
- DeepWalk
Embedding = "More complex transformed Adjacency matrix의 MF"
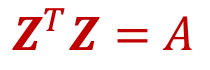
- Node2Vec (too, but 더 복잡)
하지만, shallow encoding의 한계로 인해 오늘날은 embedding을 학습을 통해 구하는 deep encoding 방법론으로 발전됨 (feature info + structural info)
Deep Representation Learning and Graph Neural Networks - 그냥 두 노드가 엣지로 연결되어 있다면 similar이라 간주
