-
Imbalanced 데이터셋: Precision, Recall, F1 score 추천 (PR curve)
- 일반적인 AD test 환경은 imbalanced
- Precision = 옳게 예측된 양성 수/예측 양성 수 = TP/(TP+FP)
클수록, 1에 가까울수록 좋음!
Recall = 옳게 예측된 양성 수/실제 양성 수 = TPR = TP/(TP+FN)
클수록, 1에 가까울수록 좋음!
★★★ Recall = TPR ★★★
F1 score = 2PR/(P+R) = P와 R의 조화평균 ('조화평균을 이용하면 산술평균을 이용하는 것보다, 큰 비중이 끼치는 bias가 줄어든다고 볼 수 있음')
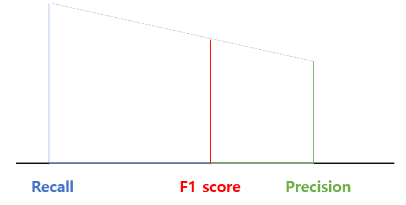
'P와 R 두 지표가 어느 한쪽도 치우치지 않는 수치를 나타낼 때 상대적으로 높은 값을 가진다'. - score =
F1 score이 P와 R에 동일한 가중치를 부여하는 데 반해, score은 값에 따라 P 또는 R에 더 많은 가중치를 부여할 수 있음.- < 1 : Precision에 더 많은 가중치
- > 1 : Recall에 더 많은 가중치
-
Balanced 데이터셋: AUC
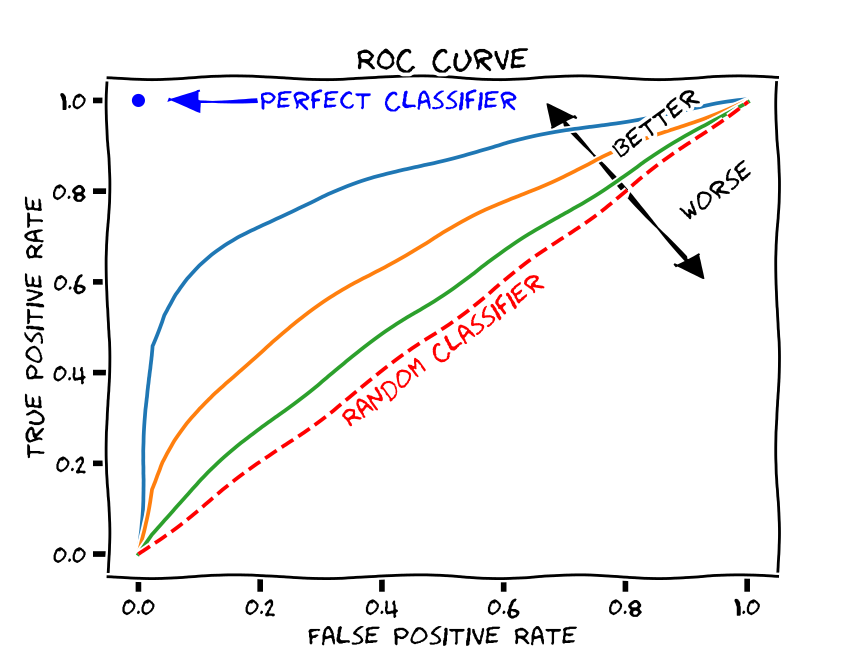
- AUC(a.k.a AUROC; Area under the ROC curve)
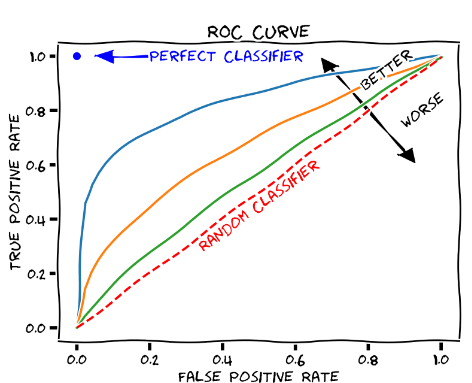
- x축: FPR = 잘못 예측된 음성 수/실제 음성 수 = FP/(FP+TN)
작을수록, 0에 가까울수록 좋음! - y축: TPR = 옳게 예측된 양성 수/실제 양성 수 = Recall = TP/(TP+FN)
클수록, 1에 가까울수록 좋음!
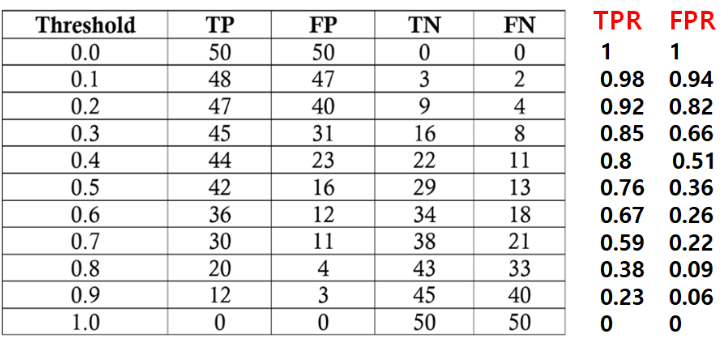
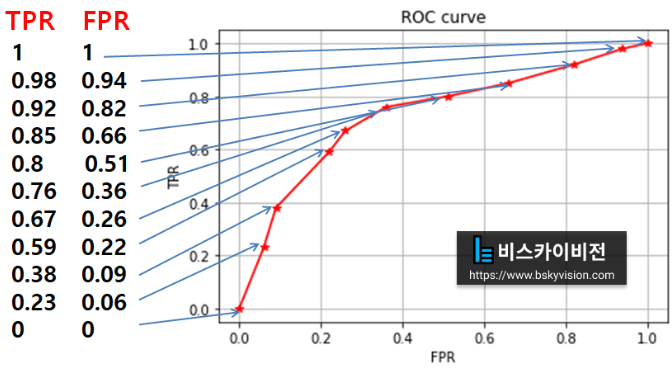
★★★ TPR = Recall ★★★ - ROC curve: 이진 분류 decision threshold에 따라 찍히는 (FPR,TPR) 점을 찍어가며 그린 그래프
ROC curve의 왼쪽 아래 Threshold가 최대인 경우 (모두 음성으로 예측)
ROC curve의 오른쪽 위 Threshold가 최소인 경우 (모두 양성으로 예측)
- AUC에서 성능이 좋다는 것은?
가운데야 어쨌건 threshold의 minimum으로 가면 (1,1)이 되고, threshold의 maximum으로 가면 (0,0)로 가게 된다. 우리는 이진 분류기가 작은 FPR과 큰 TPR을 갖길 원하므로, 이를 만족시키기 위해 그래프가 왼쪽 위로 치우친 형태이길 원한다. 다시 말해 'FPR의 값이 작아질 때 TPR이 천천히 작아진다면 좋은 성능을 가진 이진 분류기라고 볼 수 있다'.
AUC가 클수록, 1에 가까울수록 좋음!
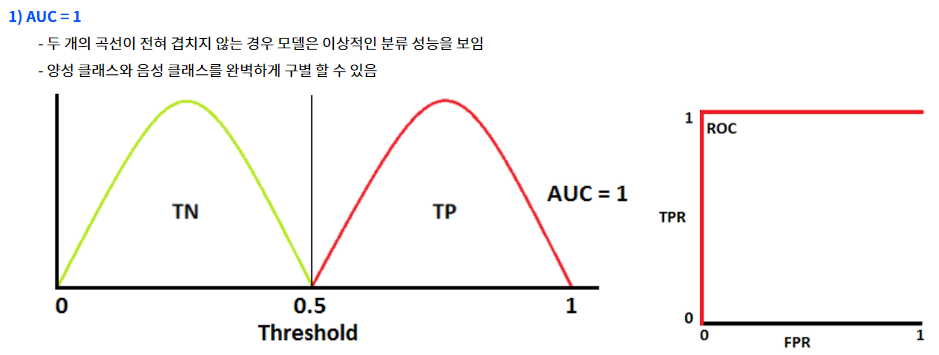
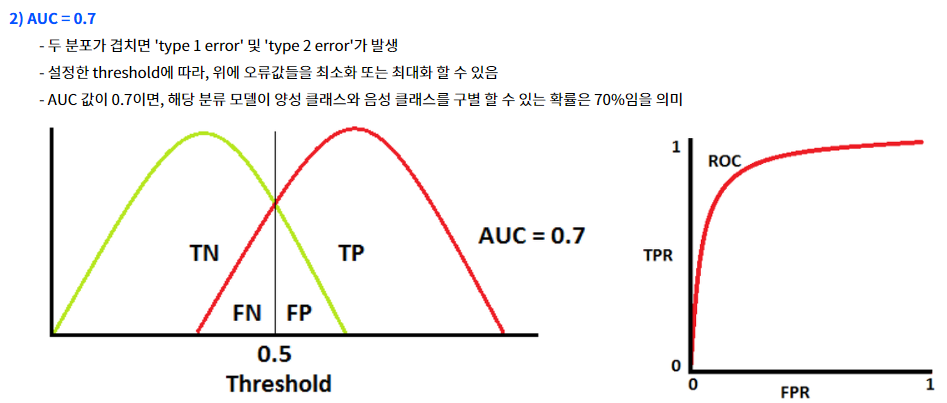
- AUC의 기준
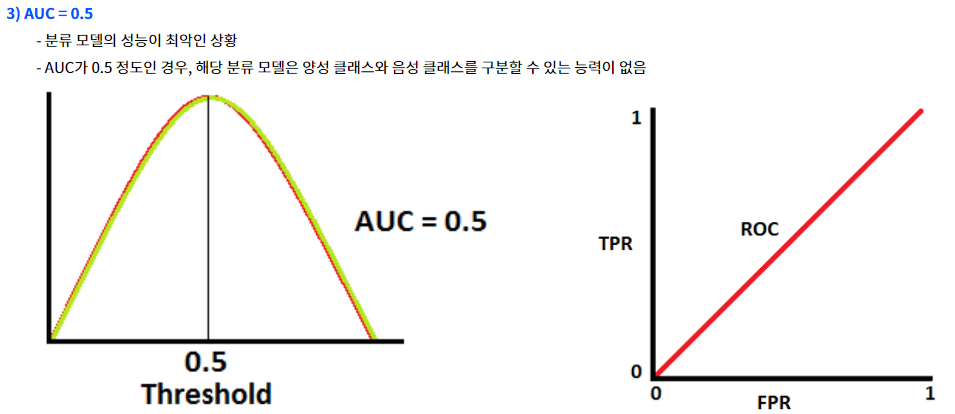
AUC의 최솟값이자 baseline=0.5 : 모델의 클래스 분리 능력이 전혀 없음
- x축: FPR = 잘못 예측된 음성 수/실제 음성 수 = FP/(FP+TN)
- 왜 Imbalanced 데이터에서 F1 score 보다 AUC가 더 나은 metric인가?
- 문제 관점의 변경: Balanced (모델이 두 클래스를 얼마나 잘 구분하는가) Imbalanced (소수 클래스를 얼마나 탐지해낼 수 있는가)
- ROC curve와 F1 score에서 Recall을 동일하게 사용하므로, 유일한 차이는 FPR을 사용하는가 or Precision을 사용하는가의 차이임. '식에서도 볼 수 있듯 FPR은 Total Negatives 가 분모로 존재하기 때문에 총 Negative Class의 수가 FPR값에 큰 영향을 미친다. 즉 Imblanaced Dataset에서는 Negative 클래스인 0 클래스 수가 1클래스 수에 비해 워낙 많은 상황이기 때문에 False Positive의 수가 개선되더라도 FPR 값이 줄기 쉽지 않다. 반면 Precision은 전체 negative class 수에 전혀 영향을 받지 않게 된다. 따라서 FPR을 활용하는 AUC스코어보다는 F1 Score를 활용하여 학습한 뒤 PR Curve를 통해 모델의 성능을 검증하는 것이 좋다'.
- Precision: 클래스 1에 대해 정확하게 탐지할 수 있는 확률
- FPR, TPR: 클래스를 분간하는 능력을 지표화
- AUC(a.k.a AUROC; Area under the ROC curve)
- 이진분류기 성능 평가방법 AUC(area under the ROC curve)의 이해 https://bskyvision.com/entry/AUROC-%EC%84%B1%EB%8A%A5%EC%A7%80%ED%91%9C%EB%9E%80
- AUC-ROD 커브
https://bioinformaticsandme.tistory.com/328- 불균형(imbalanced) 데이터 모델링은 ROC curve를 사용을...
https://julie-tech.tistory.com/121- 분류 성능 평가 지표: 불균형 데이터에는 어떤 평가 지표가 좋을까? - 오차행렬 완벽 정리
https://eatchu.tistory.com/12- 분류성능평가지표 - Precision(정밀도), Recall(재현율) and Accuracy(정확도)
https://sumniya.tistory.com/26

위의 글에서는 Imbalanced 데이터 셋에서 f1 score를 추천한다고 적으신 것 같은데,
아래는 또 이렇게 나와 있네요.
'왜 Imbalanced 데이터에서 F1 score 보다 AUC가 더 나은 metric인가?'