내가 만들려고 하는 작품에 대해 YOLO란 무엇인가에 대해 다시 좀더 공부를 해보려고 한다. 들어가기전 개념을 알고가자.
📌1. Object Detection (객체 탐지)

- 이미지 내의 객체를 배경과 구분해 식별하는 것(Classification)뿐만 아니라, 이미지 내 해당 객체의 위치까지 표시하는 알고리즘
- 해당 Object라고 판단되는 곳에 bounding box가 그려진다.
1_1. bounding box란?
- 특정 사물을 탐지하여 모델을 효율적으로 학습 할 수 있도록 도움을 주는 방법.
- 객체 탐지 모델에서 바운딩 박스는 타겟 위치를 특정하기 위해 사용된다.
- 타겟 위치를 X와 Y축을 이용하여 사각형으로 표현한다. 예를 들어, 바운딩 박스 값은 (X 최소값, Y 최소값, X 최대값, Y 최대값)으로 표현이 됩니다.

1_2 모델
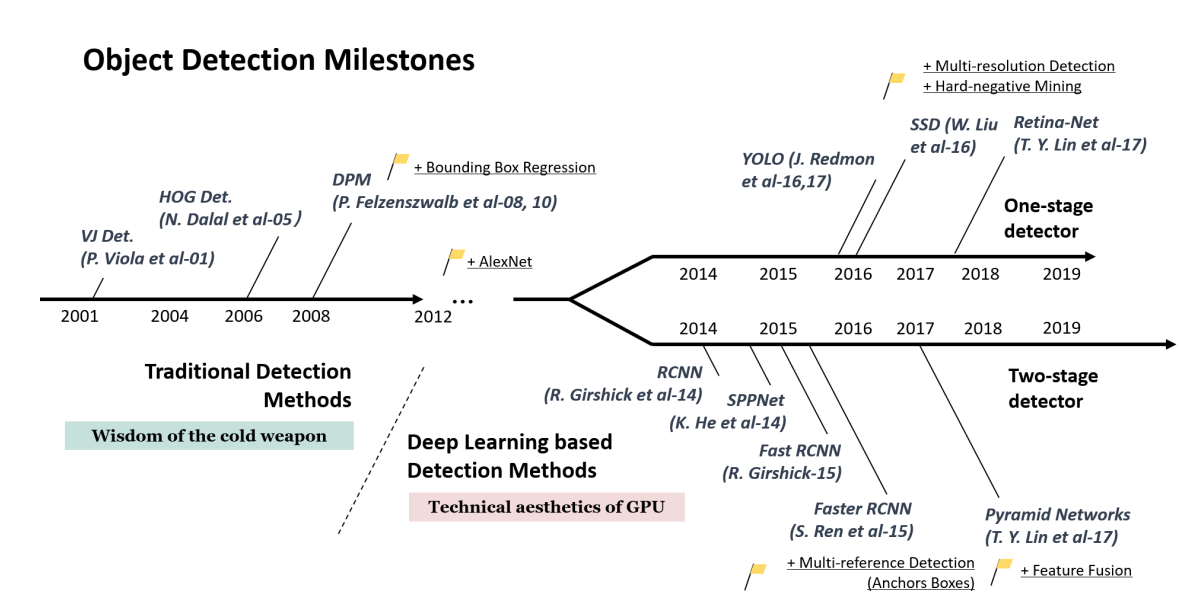
- One-Stage Detector
-> 특정 물체에 대해 어떤 물체인지 분류 - Two-Stage Detector
-> 물체가 있을만한 영역을 빠르게 찾아내는 알고리즘Two-Stage Detector은 객체를 검출하는 정확도 측면에서는 좋은 성능을 냈지만, 예측 속도가 느려 실시간 탐지에는 제한됐습니다. 이러한 속도 문제를 해결하기 위해 Classification과 Region Propsal을 동시에 하는 One-Stage Detector가 제안
- One-Stage Detector는 비교적 빠르지만 정확도가 낮고, Two-Stage Detector는 비교적 느리지만 정확도가 높다.
모델의 종류
- Two-Stage Detector
R-CNN, Fast R-CNN, Faster R-CNN - One-Stage Detector
YOLO, SSD, RetinaNet
이중에서 나는 저번 전공수업때 사용해본 YOLO를 사용려고 한다.
📌2. YOLO란
YOLO는 아래와 같은 특징들이 있다.
- 이미지 전체를 한번만 본다
- region proposal, feature extraction, classification, bbox regression
=> one-stage detection로 통합하여 빠르다 - 주변 정보까지 학습하여 이미지 전체를 처리하기 때문에
background error가 적다 - 훈련 단계에서 보지 못한 새로운 이미지에 대해서도 검출 정확도가 높다
이해하자
- 원본이지미를 R-CNN계열의 방식처럼 여러 장 분할해 분석하는 일을 하지 않고 원본 이미지 그대로 CNN에 통과시킨다.
- YOLO모델의 라이브러리 많고 통합된 모델을 사용해 별도에 작업이 필요없다. 또한 이전 모델들에 비해 상대적으로 속도가 빠르다.
- 훈련단계에서 보지 못한 새로운 이미지에 대해서도 검출이 높다.
2_1 동작과정
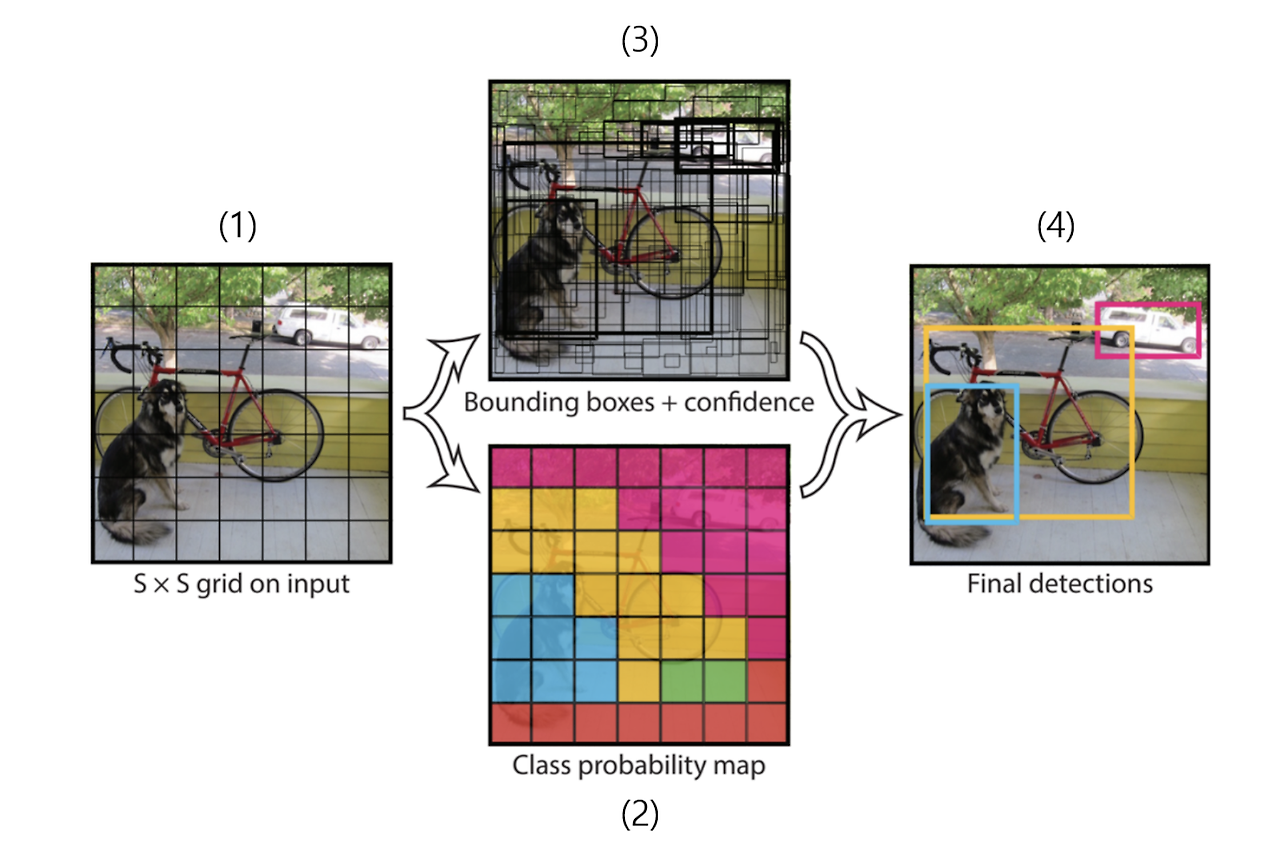
- 사진이 입력되면 가로 세로를 동일한 그리드 영역으로 나눈다.
-
그 후 각 그리드 영역에 대해서 어디에 사물이 존재하는지 바운딩박스와 박스에 대한 신뢰도 점수를 예측합니다. 신뢰도가 높을수록 굵게 박스를 그려 준다. 이와 동시에 (2)에서와 같이 어떤 사물인지에 대한 classification작업이 동시에 진행된다.
-
그러면 굵은 박스들만 남기고 얇은 것들 즉, 사물이 있을 확률이 낮은 것들은 지워 준다.
-
최종 경계박스들을 NMS(Non- Maximum Suppression) 알고리즘을 이용해 선별하면 (4) 이미지처럼 3개만 남게 됩니다.
-
더 깊게 알고 싶다면 참고 사이트를 확인해보자
https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.g137784ab86_4_484 -
논문 링크 : https://arxiv.org/abs/1506.02640
나는 YOLOV5버전을 사용해본적이 있기에 깃허브 주소를 남긴다.
참고 : Github
📌YOLOV8

YOLOv8은 YOLOv5의 후속 모델로, 여러 가지 개선사항을 포함하고 있다.
- YOLOv8의 주요 개선사항:
- 아키텍처 개선: backbone과 neck 부분의 설계가 개선되어 더 효율적인 특징 추출이 가능해졌다.
- 앵커 프리(Anchor-free) 디자인: 기존의 앵커 기반 방식에서 벗어나 객체 검출의 정확도와 속도를 향상시켰다.
- 세그멘테이션 기능 추가: 객체 검출뿐만 아니라 인스턴스 세그멘테이션도 수행할 수 있게 되었다.
- 다중 작업 학습: 분류, 검출, 세그멘테이션을 동시에 학습할 수 있는 구조를 채택했다.
- 개선된 학습 전략: 더 효과적인 학습 방법과 데이터 증강 기법을 도입했다.
-
다른 모델과의 비교:
YOLOv8은 최신 객체 검출 모델들과 비교했을 때 장점 -
속도와 정확도의 균형: 실시간 처리가 가능한 빠른 속도를 유지하면서도 높은 정확도를 제공한다.
-
유연성: 다양한 크기의 모델(nano, small, medium, large, xlarge)을 제공하여 다양한 환경에 적용 가능하다.
-
다기능성: 객체 검출, 인스턴스 세그멘테이션, 이미지 분류 등 여러 작업을 하나의 모델로 수행할 수 있다.
-
사용 편의성: Ultralytics 프레임워크를 통해 쉽게 사용하고 fine-tuning할 수 있다.
- 성능 분석:
COCO 데이터셋에서의 성능 비교 (객체 검출 task 기준):
YOLOv8x: 53.9 mAP, 26.2 ms (Tesla V100 GPU)
YOLOv5x: 50.7 mAP, 23.0 ms (Tesla V100 GPU)
Faster R-CNN: 37.0 mAP, 65.0 ms (Tesla V100 GPU)
RetinaNet: 40.0 mAP, 54.0 ms (Tesla V100 GPU)
YOLOv8은 YOLOv5에 비해 mAP(mean Average Precision)가 약 3.2 포인트 향상되었으며, 처리 시간도 비슷한 수준을 유지하고 있습니다. 그렇기에 나는 YOLOV8버전을 활용해서 공모전에 준비를 시작하게 되었다. 다시 문서를 읽어보고 적합한 모델을 골라 좋은 경험을 챙겨가면 좋겠다.
깃허브 : YOLOV8
참고 Document : https://docs.ultralytics.com/usage/cfg/
