
📌 데이터타입 중급
시험범위에는 행렬과 리스트는 생략한다
🎯벡터(vector)
- 1.1 벡터의 성분에 이름 부여
- 1.2 벡터 자동 생성
- 1.3 데이터 추출
- 인덱스로 추출
- 조건으로 추출(filtering)
- which: 조건을 만족하는 인덱스
- ifelse
- 1.4 데이터 삽입/삭제
- 1.5 sort
- 1.6 벡터의 계산
-
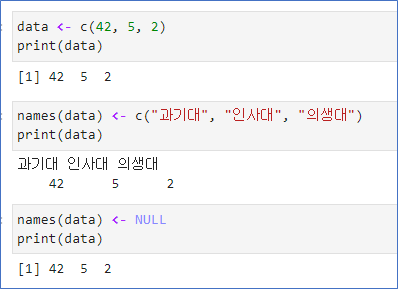
벡터는 값만으로 이루어진 일차원 배열
-
벡터의 각 원소에 이름(names) 부여 가능
-
벡터의 이름 출력names(벡터)
-
벡터의 이름 삭제-names(벡터)<-NULL
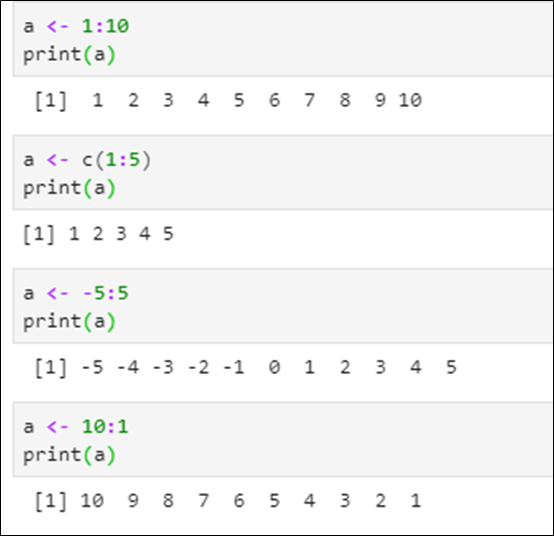
📌 m:n – m부터 n까지 1씩 자동 증가
벡터 생성시 c가 없어도 됨
n이 더 작으면 1씩 감소
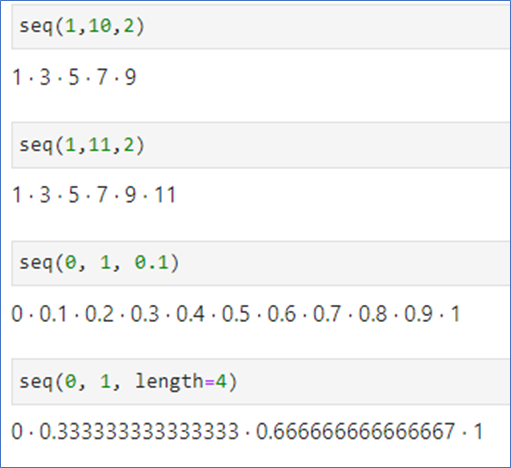
📌seq(from, to, by)
seq(from, to, length=)
by: by 만큼씩 증가
length: 개수 지정
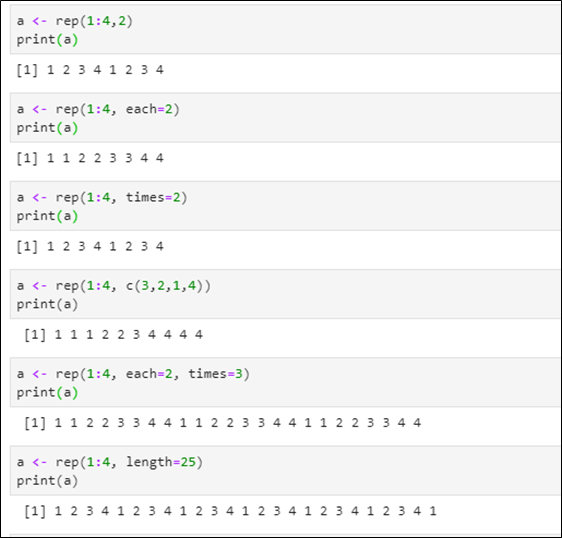
rep() - 반복 생성
rnorm(개수, 평균, 표준편차) - 정규 난수 생성
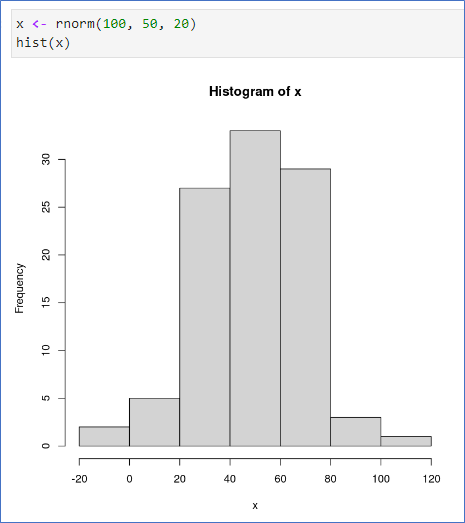
runif(1000) - 0 ~ 1 사이 난수 1,000 개
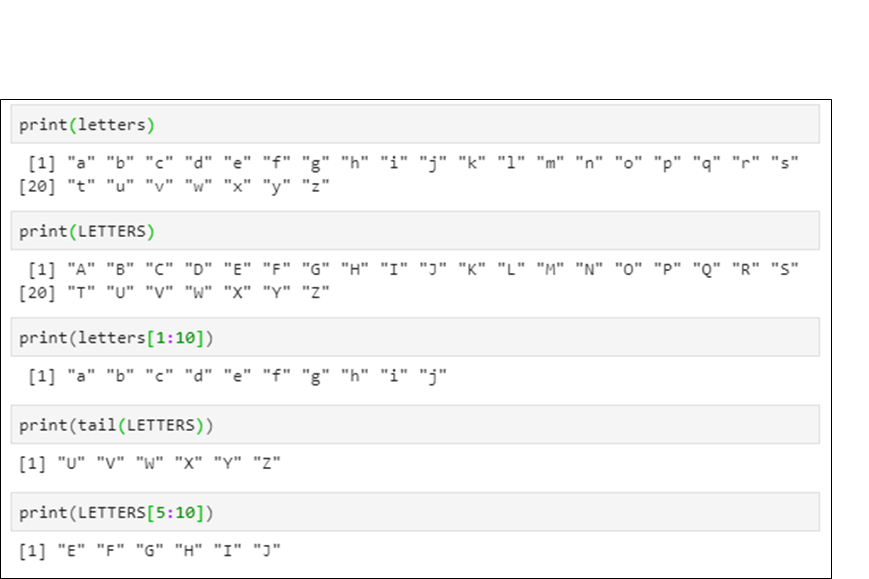
📌알파벳 벡터 – letters[ ], LETTERS[ ]
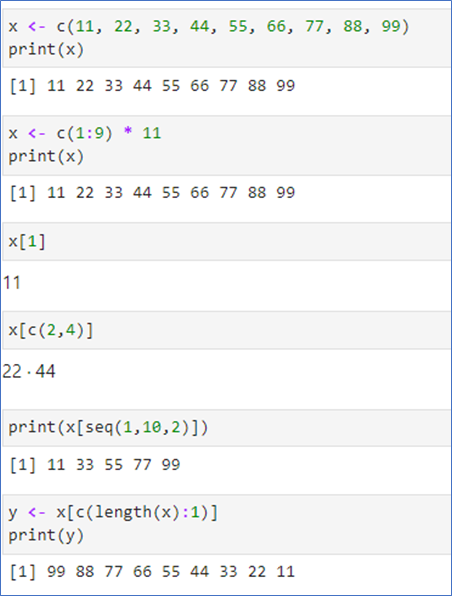
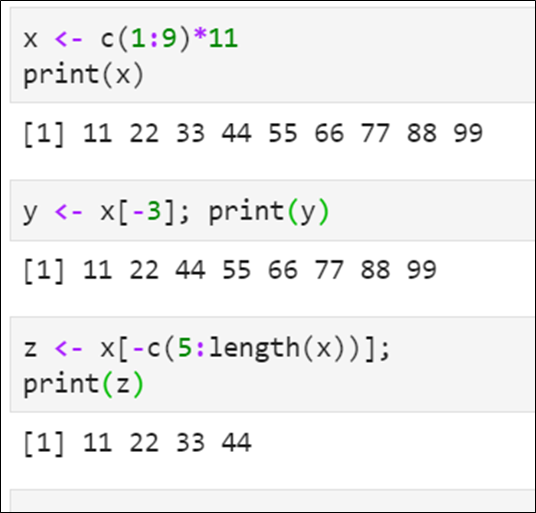
📌 데이터 추출 - 인덱스로
-
인덱스는 1부터
-
추출하고자 하는 성분의 인덱스 지정
-
인덱스를 벡터로 지정 가능
-
seq() 함수 사용 가능
📌 데이터 삽입 / 삭제
-
append(벡터, 삽입할 값, after=인덱스): 지정된 인덱스 뒤에 삽입
-
예제는 하나의 값이지만 벡터도 삽입 가능
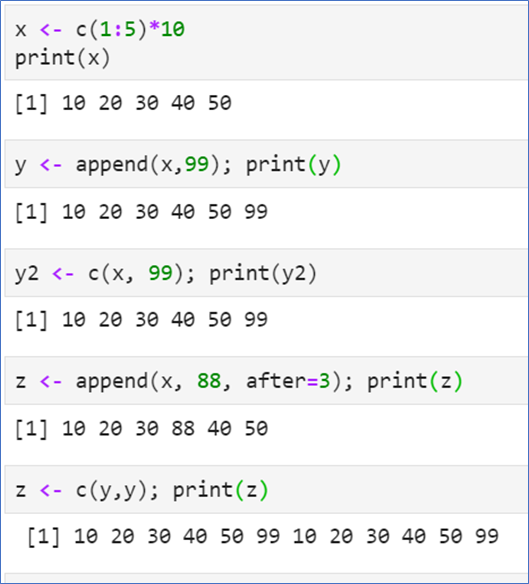
- 인덱스 앞에 '-'를 붙이면 지정된 성분 삭제
📌 정렬하기 - sort()
-
sort(벡터): 오름차순으로 정렬
-
sort(벡터, decreasing=T): 내림차순으로 정렬
-
sort(x)의 결과를 저장하지 않으면 x는 원래 그대로

📌 데이터 추출 - 필터링
-
[ ]안에 조건으로 필터링
-
which(조건): 조건을 만족하는 인덱스 반환
-
&: 두 조건 and
-
|: 두 조건 or
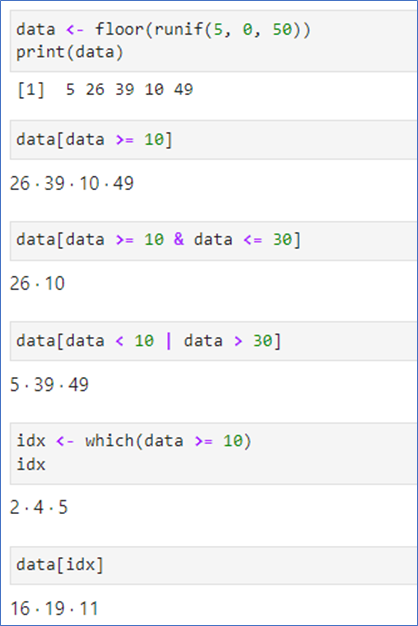
-
order(x): i번째로 큰 수가 있는 인덱스
-
ifelse(조건, 참값, 거짓값): 조건이 참인 성분에는 ‘참값‘을, 거짓인 성분에는 ‘거짓값’으로
-
엑셀의 if 함수와 동일
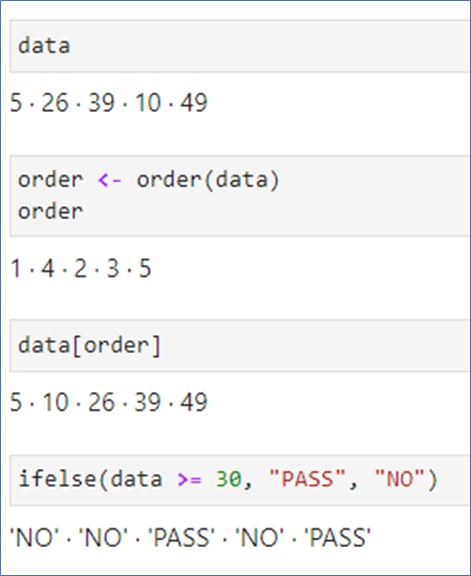
📌 벡터의 계산
-
성분마다 같은 계산 결과 저장
-
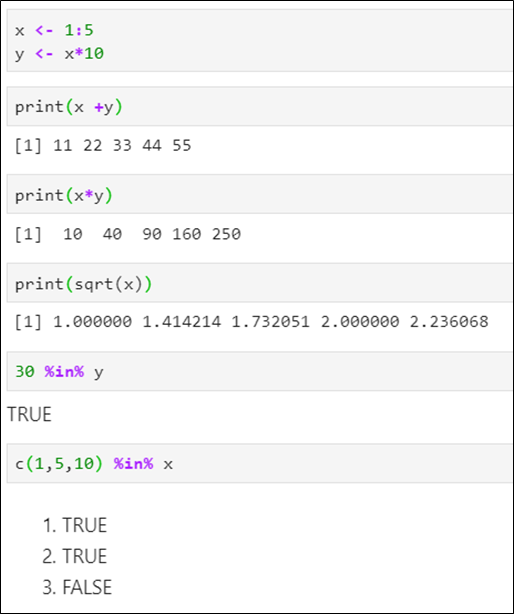
+, -, *, /는 각 성분끼리
-
성분 %in% 벡터:-벡터가 성분을 포함하는지를 조사하는 연산자
🚀 기타 벡터 관련 함수
unique(): 중복 제거 1개씩만
sample(): 표본 추출
sample( , , replace=T): 중복 추출 가능
🎯데이터프레임
- 행렬과 데이터프레임은 둘 다 테이블 형식(직사각형) - 데이터프레임은 데이터베이스의 한 테이블과 흡사
- 데이터프레임에는 행렬과 달리 다양한 형태의 변수 저장 가능
 |  |
|---|
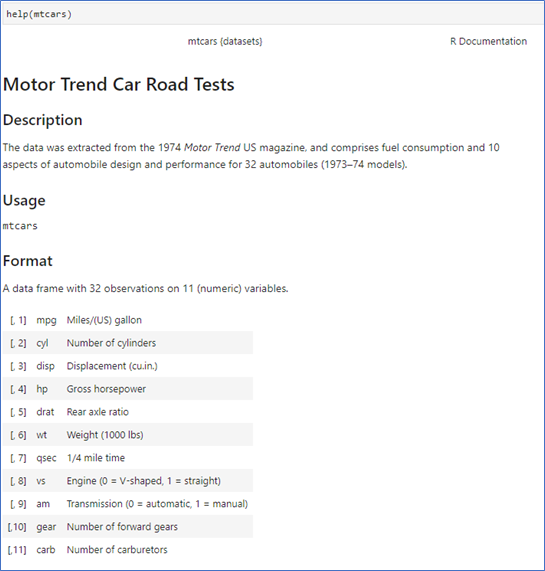
- help(mtcars)
- R Sutudio의 Help창에서 데이터의 이름으로 확인
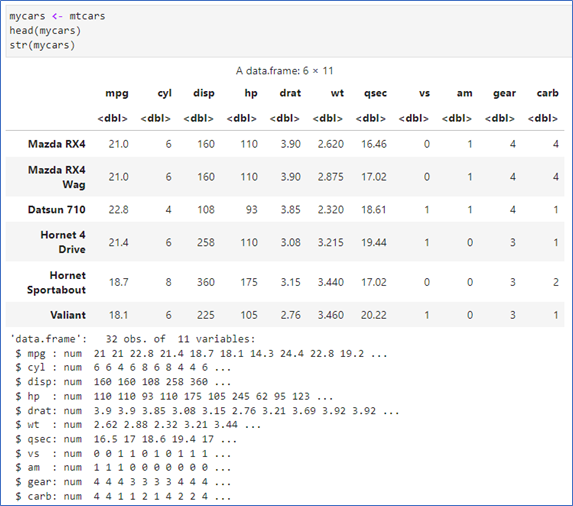
자동차 연비에 대한 데이터 - head(): 처음 6개 보기
- head(df,3): 3개 보기
- tail(): 마지막 6개
- str(): 구조 보기
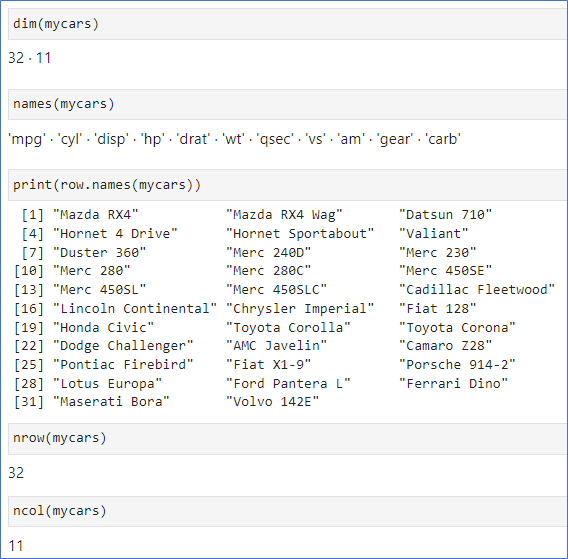
- nrow(): 행의 개수
- ncol(): 열의 개수, 변수의 개수
- dim(): 행과 열의 개수
- names(): 변수 이름- 변경도 가능
- row.names(): 행 번호
📌 인덱싱 - key & index
- 키 값으로 추출
mycarscyl - 인덱스로 추출
mycars[ , c(1,3,5)]: 지정된 열만
mycars[1:10, ]: 지정된 행만
mycars[1:10, 1:3]: 1-3변수의 데이터를 1행부터 10행까지 - head(), tail()
처음(끝)의 6행만
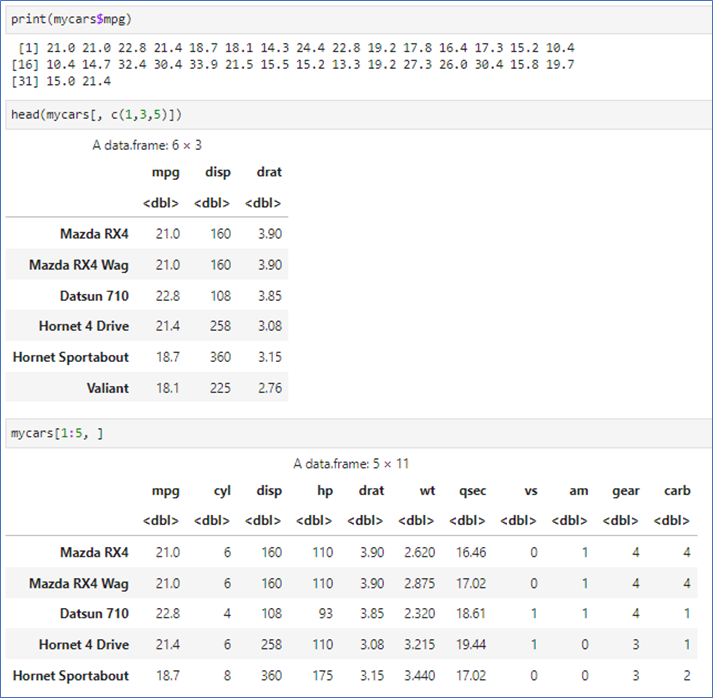
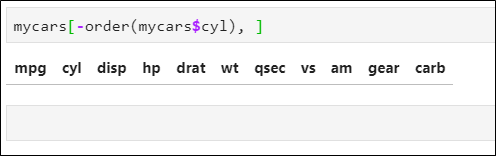
📌 데이터 프레임 정렬하기
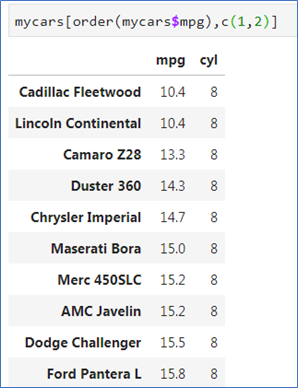
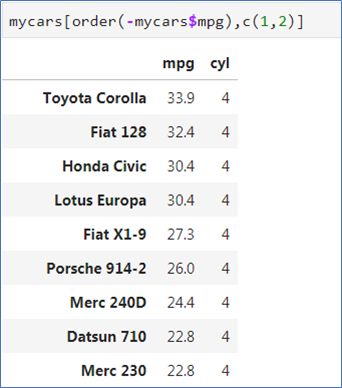
- 기준 변수 지정
order()로 기준 변수 지정 - df[order(df$키), ]
올림차순으로 정렬 - df[order(-df$키), ]
내림차순으로 정렬
🚀 변수 앞에 -를 붙이면 내림차순으로
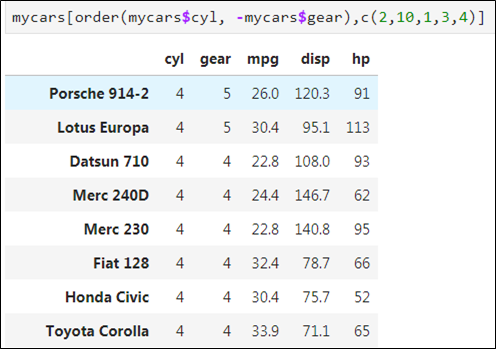
📌 기존 변수가 2개 이상 일 떄
-
cyl 변수는 오름차순으로
-
gear 변수는 내림차순으로
-
주의: df[-order(), ]
 |  |
|---|
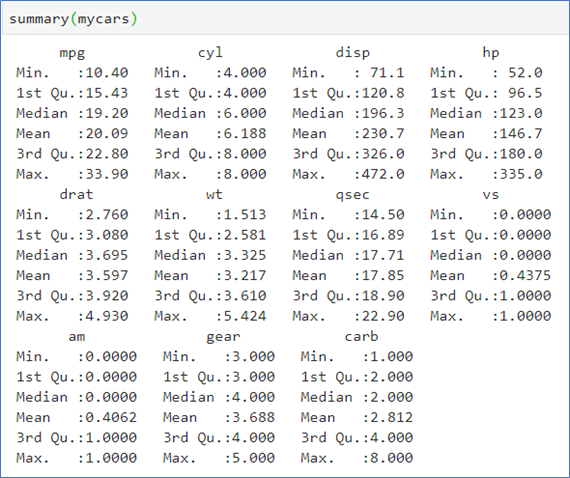
📌요약통계량 구하기
summary(df)는 데이터프레임 df의 모든 변수의 요약통계량을 구해준다
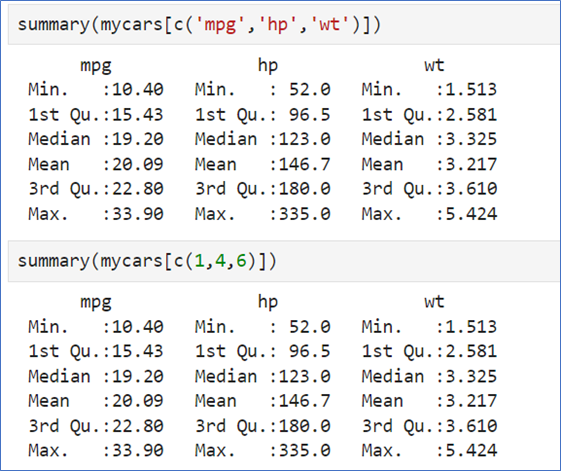
🚀 벡터 이용하기
- 벡터를 이용하여 요약통계량을 구하는 변수를 선택할 수 있다.
- 변수이름으로 또는 인덱스로

무지(無知)