
📌 dplyr 라이브러리
 |  |
|---|
data manipulation
- mutate - 새로운 변수 생성
- select - 필요한 변수만 추출
- filter - 조건에 맞는 데이터 필터링
- arrange - 정렬하기
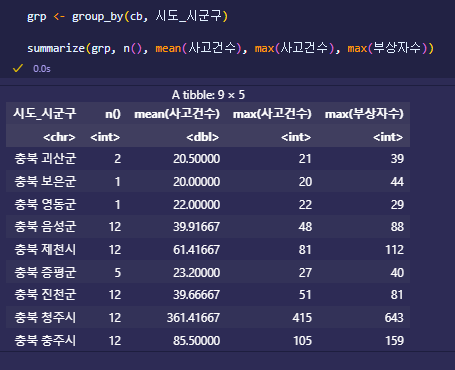
- summarize - 통계량 구하기
- group_by - 그룹 나누기
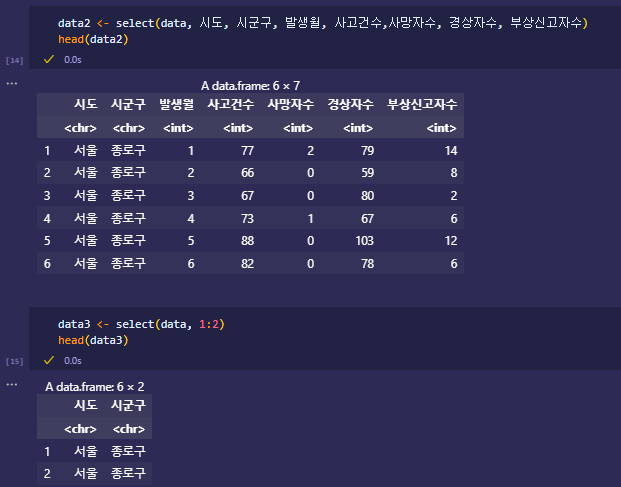
변수 선택 - select
select(df, 변수명,…)
또는 select(df, 번호)
- 예전에 필터링은:
df[c(‘변수명’,…)] 변수 이름으로
df[1:n] 열 번호로
- select(df, -변수명)
- select(df, -c(변수명,…)
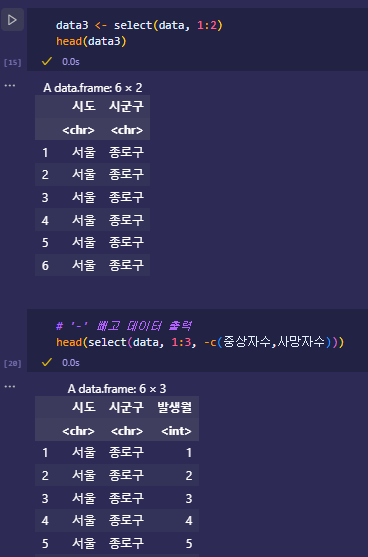
- 변수명 앞에 –가 붙으면 삭제
- 선택과 삭제 동시 사용 가능
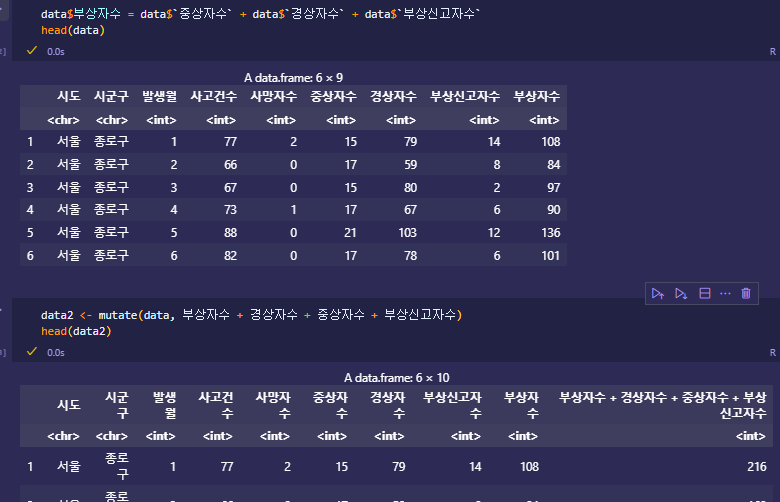
변수 생성 - mutate
-
mutate(df, 변수명=수식)
-
예전에는 df$변수명 = 수식
-
부상자수를 구하여 data2에 저장
-
data2에서 시도와 시군구를 합쳐서 시도_시군구 생성하여 data3에 저장
-
data3에서 사고당부상자수를 구하여 data4에 저장
정렬하기 - arrange
-
arrange(df, 변수명, desc(변수명))
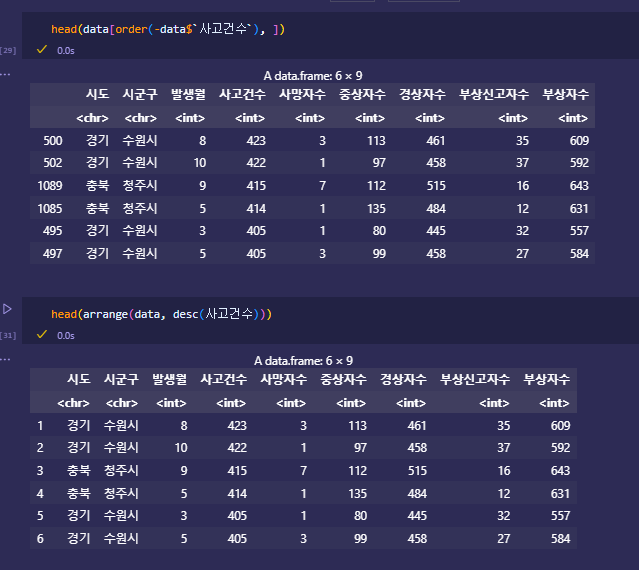
-
desc는 역순으로
-
예전에는 df[order(변수명, -변수명), ]
필터링 - filter, and, or
-
filter(df, 조건)
-
예전에는 df[조건, ] 행에 조건식, 열은 전부
-
%>%: 파이프 위의 결과를 그대로 받아 다음 코드 실행 – 데이터프레임 생략 가능

- filter(df, 조건)
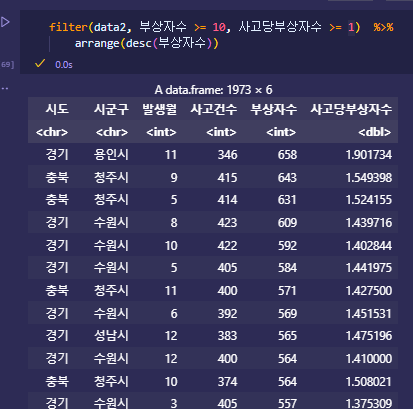 | 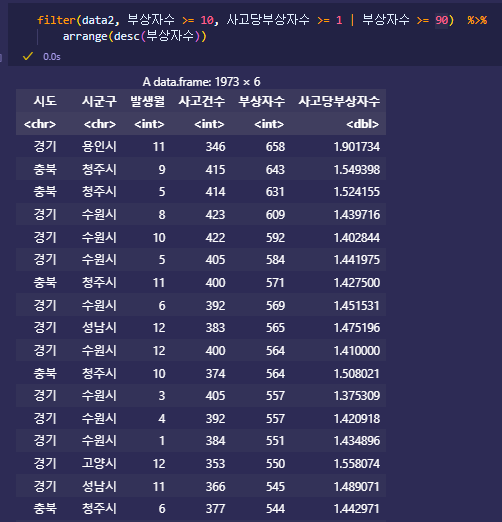 |
|---|
-
,(쉼표)로 연결된 조건은 and
-
&: and
-
|: or 사용 가능
📌 파이프 사용

앞의 결과를 다른 변수에 저장하지 않고 그대로 다음 줄에 넘겨줌
데이터프레임 이름을 명시하지 않아도 됨. (각 문장의 끝에 %>%)
 | 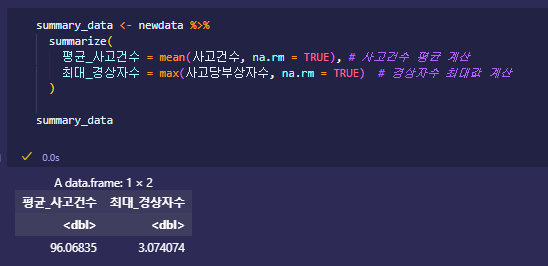 |
|---|
 |  |
|---|

무지(無知)