💻데이터 전처리 - codeacademy
DATA CLEANING IN R
A huge part of data science involves acquiring raw data and getting it into a form ready for analysis. Some have estimated that data scientists spend 80% of their time cleaning and manipulating data, and only 20% of their time actually analyzing it or building models from it.
When we receive raw data, we have to do a number of things before we’re ready to analyze it, possibly including:
diagnosing the “tidiness” of the data — how much data cleaning we will have to do
reshaping the data — getting the right rows and columns for effective analysis
combining multiple files
changing the types of values — how we fix a column where numerical values are stored as strings, for example
dropping or filling missing values - how we deal with data that is incomplete or missing
manipulating strings to represent the data better
📌데이터 전처리의 중요성
- R로 데이터 정리하기
- -데이터 과학의 큰 부분은 원시 데이터를 수집하여 분석할 준비가 된 형태로 만드는 것입니다.
- 일부에서는 데이터 과학자가 데이터를 정리하고 조작하는 데 시간의 80%를 소비하고
- 실제로 데이터를 분석하거나 데이터에서 모델을 구축하는 데 시간의 20%만 소비한다고 추정했습니다.
📌데이터 전처리 내용(Data cleaning)
-
데이터의 잘 정리되어 있는지 진단
-
데이터 재구성
-
여러 파일 결합
-
값 유형 변경
-
누락된 값 삭제 또는 채우기
-
데이터를 더 잘 나타내기 위해 문자열 조작
📌프로그래밍 언어의 구성 - 변수 및 연산자
- 상수
정수형, 실수형, 문자열 - 변수 타입
수치형, 문자형, 벡터, 리스트, 행렬, 데이터프레임 - 산술연산자
사칙연산(+, -, *, /)
거듭제곱(^, **)
몫(%/%)
나머지(%%) - 비교연산자
==, >, <, >=, <=, != - 논리연산자
& (and), | (or), ! (not)
📌 제어문
- 조건문
if, if-else, if-else if-else, switch- 반복문
for, while- 함수 및 클래스
Base에 기본으로 내장된 함수 및 클래스 사용
패지키(라이브러리)에 포함된 함수- Note
R 언어에서는 반복문과 함수를 사용할 일이 많지 않음
📌 표준입축력 및 파일 입출력
- 표준출력
- csv 파일 읽기/쓰기
read.csv, write.csv- 엑셀 파일 읽기/쓰기
read_xlsx, write.xlsx
상수
- 정수형
1, 8412, -5- 실수형
1.2, -2.9, 1.23E5- 문자열
“a”, “My name is Hasik.”- Boolean
T, TRUE, F, FALSE- 내장 상수
(누락치 또는 아직 정해지지 않은 수)
NA, NULL
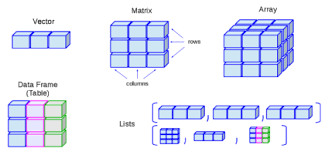
📌R에서 사용되는 NEW 데이터타입
- 벡터 –
c(값, 값, 값, …) - 행렬 –
matrix(벡터, 행의 수, 열의 수) - 리스트 –
list(키=값, 키=벡터, 키=행렬, …) - 데이터프레임 – data.frame(키=벡터, 키=벡터, …)
🔥 - 데이터 타입_벡터(vector)
-
일차원 배열
-
같은 타입의 변수들의 모임
-
c로 시작
c(값, 값, …)
v <- c(1,2,3)
n <- 1:10
x <- c(“a”, ”b”, ”c”)
names <- c(“kim”, “lee”, “park”, “choi”)
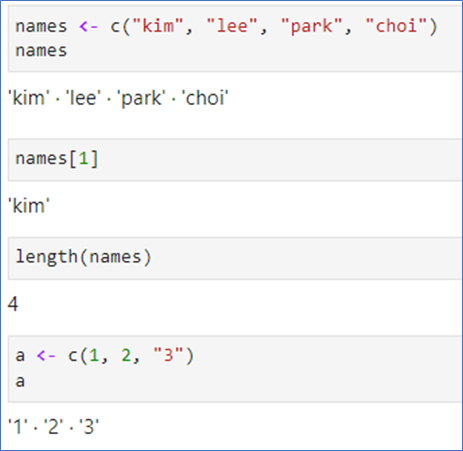
📌벡터에서의 indexing
- index는 1부터 시작
- 지정한 번호의 원소만 추출 가능
- m:n은 m부터 n까지 1씩 증가, 이때 c는 안써도 됨
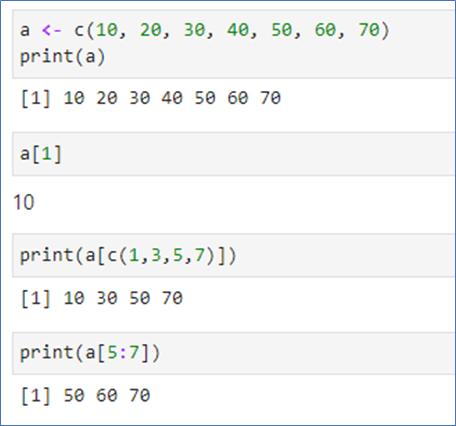
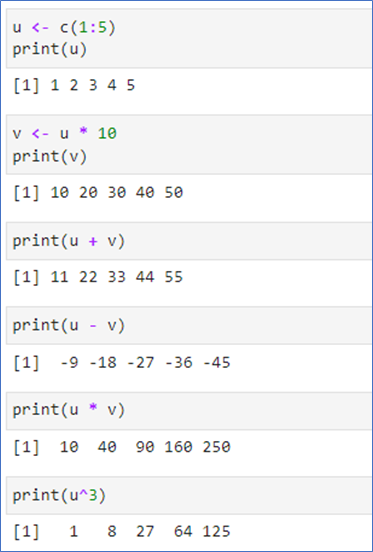
📌벡터에서의 연산
- 벡터에서의 연산은 각 원소끼리의 연산 -> 그 결과는 벡터
- R 언어의 장점은 for loop을 사용할 필요가 거의 없음: 벡터 베이스 계산
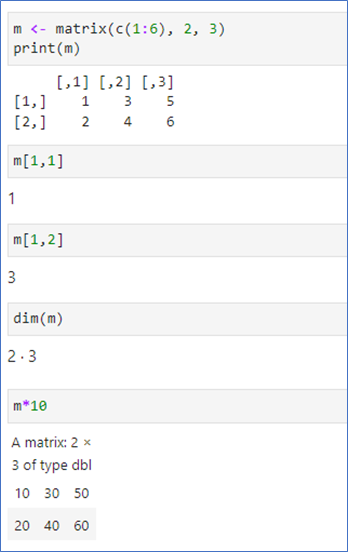
🔥데이터 타입 – 행렬(matrix)
- 이차원 배열
- 같은 타입의 변수들의 모임
matrix(벡터, 행의 수, 열의 수)
m <- matrix(c(1,2,3,4,5,6), 2, 3)
m <- matrix(1:6, 3, 2)
🎯행렬_예시
-
index는 1부터 시작
-
대괄호로 index 지정
-
[행번호, 열번호] 순
-
dim() 함수는 행렬의 크기 구하기
📌행렬에서의 indexing
-
ncol 또는 nrow로 열의 수 또는 행의 수 지정
-
[행번호, ]는 그 행 전체를 추출
-
[ , 열번호]는 그 열 전체를 추출

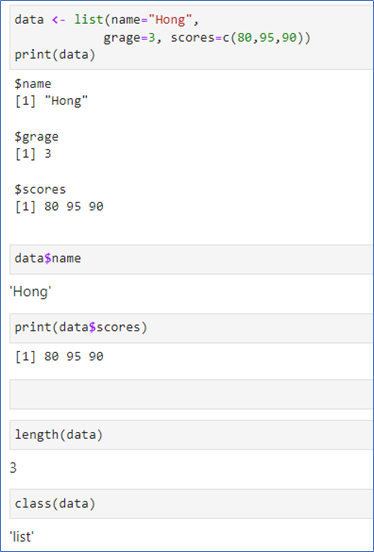
🔥데이터 타입 – 리스트(list)
-
일차원 배열
-
다른 타입의 변수들의 배열 가능
-
리스트의 원소로는 무엇이든 가능
list(키=값, 키=값,…)
data <- list(name=“Hong”, grade=3,
scores=c(80,90,100))
🎯리스트_사용예시
-
“변수명$키이름”으로 사용
-
class()는 데이터 타입 알아보기
-
length()는 리스트의 길이 구하기
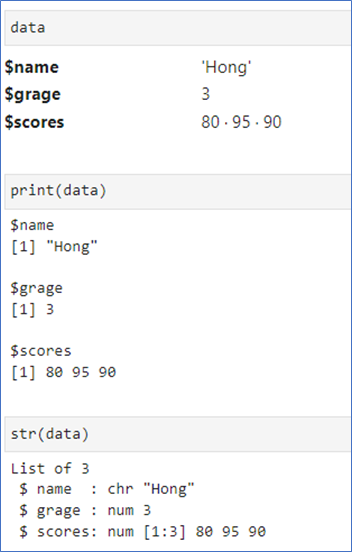
📌리스트 구조 확인 – str()
- structure의 약자 str()
- str이 string을 의미하는 것이 아님.
🔥데이터 타입 – 데이터프레임(data frame)
-
이차원 배열
-
다른 타입의 벡터 가능
-
리스트와 비슷하나 모든 벡터의 길이가 같아야 함
-
엑셀의 sheet 하나가 변수 1개에 저장
-
데이터베이스의 table 하나가 변수 1개에 저장
data.frame(키=값, 키=값, …)
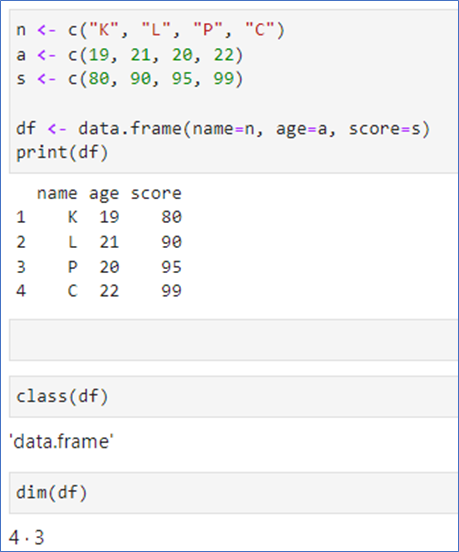
df <- data.frame(name = n, age=a, score=s)
🎯데이터 프레임 사용 예
-
class()는 데이터 타입 알아보기
-
dim()는 데이터 프레임의 사이즈 구하기
-
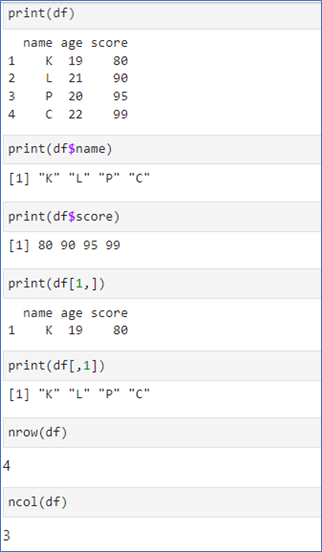
“변수명$키이름”으로 사용
-
df[1, ]은 1행
-
df[ ,1]은 1열
-
nrow()는 행의 수
-
ncol()은 열의 수
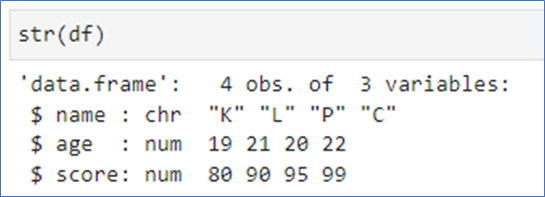
📌데이터 프레임 구조 확인 – str()
- structure의 약자 str()
- str이 string을 의미하는 것이 아님.