
📌 AI 이미지 생성(AI Image Generaion)이란?
인공지능의 한 분야로, 컴퓨터 알고리즘이 이미지를 자동으로 생성 또는 수정하는 기술. 주로 생성적 적대 신경망(GAN), 확산 모델(Diffusion Model), 변환기(Transformer) 등의 딥러닝 모델이 사용됨
핵심 딥러닝 모델
- GAN : 생성자(Generator)와 판별자(Discriminator)라는 두 신경망이 서로 경쟁하며 학습하는 모델
- Diffusion Model : 이미지를 점차적으로 노이즈화하고, 다시 노이즈를 제거해가며 깨끗한 이미지를 복원하는 모델
- Transformer : 주의(attention) 메커니즘을 통해 텍스트 설명을 바탕으로 인관성 있는 이미지를 생성하는 모델
기본 딥러닝 모델
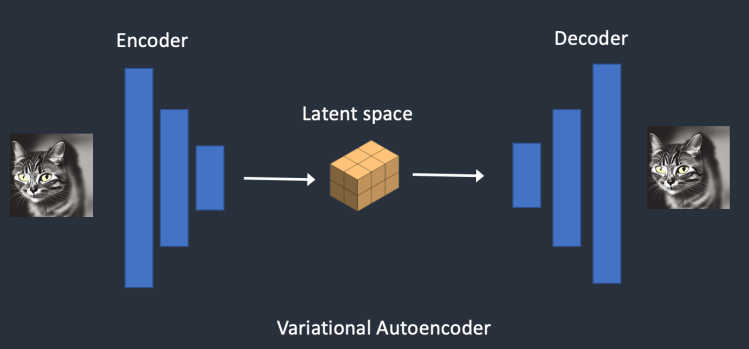
- Autoencoder : 입력 데이터를 압축하고 복원하면서 주요 특징을 학습하는 모델
- VAE(variational Autoencoder) : 데이터의 분포를 학습하여 무작위 샘플로 다양한 이미지를 생성하는 모델
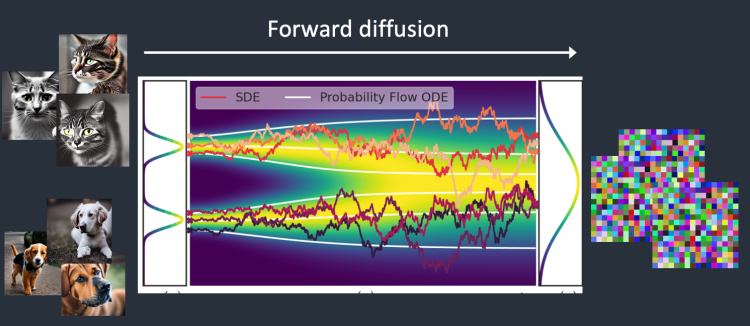
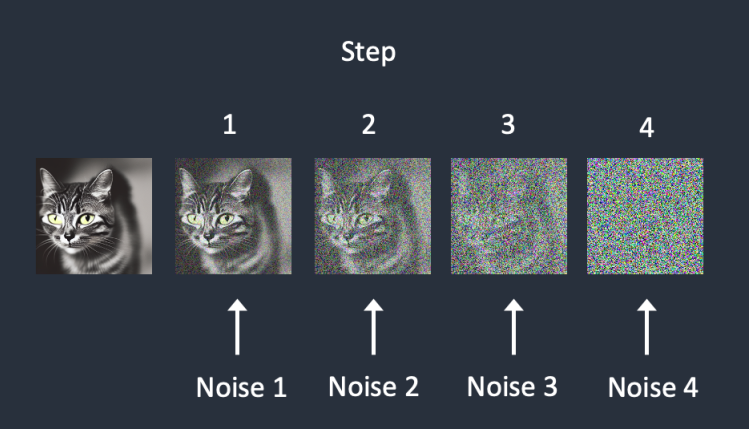
📌 Diffusion 모델의 원리(1)
- Forward diffusion(순방향 확산)
물리학에서의 ‘확’과 유사한 방식으로 AI 모델을 학습시키는 방식,해당 프로세스에서는 학습용 이미지에 점차적으로 잡음(NOISE)을 추가하여, 점점 아무런 특징이 없는 노이즈로 바꿔 버림.
마치 물컵에 잉크를 한방울 떨어뜨리는 것과 유사하며, 잉크가 컵에 든 물속에서 확산되어 얼마 후면 잉크가 처음에 어디에 떨어졌는지 전혀 알 수 없게 되는 것과 비슷함사전혀 알 수 없게 되는 것과 비슷함전혀 알 수 없게 되는 것과 비슷함사전혀 알 수 없게 되는 것과 비슷함.
 |  |
|---|
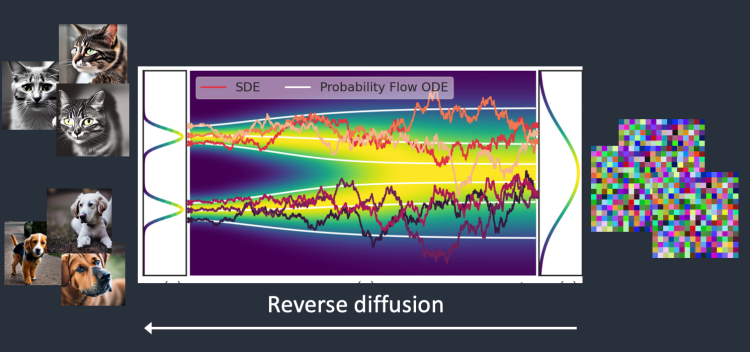
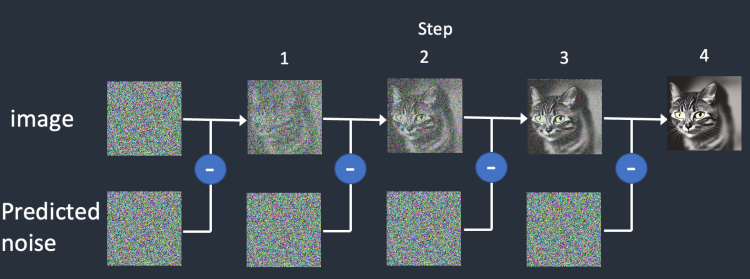
📌 Diffusion 모델의 원리(2)
- Reverse diffusion(역방향 확산)
이러한 확산 과정을 거꾸로 돌리는 방식으로, 실제 물컵에 떨어진 잉크를 다시 되돌릴 수 는 없지만, 컴퓨터 상에서는 가능함.
Ex) 비디오 역재생
해당 프로세스는 ‘노이즈’, 즉 잡음 상태에서 시작해서
이미지를 복구하는 방식임 하지만, 이미지 공간은 매우 고차원이기 때문에 해당 방식을 이미지 공간 내에서 진행하는 것은 굉장히 느리거나, 작동이 어려움.
Ex) 3개의 색채널이 있는 512x512 픽셀 이미지의
경우 5125123 = 786,432 차원 수를 가짐.
 |  |
|---|
📌 Latent Diffusion 모델(LDMs)
-
이러한 문제를 해결g기 위해 LDMs 가 등장했으며, 더 이상 이미지 공간에서 직접 작업을 수행g는 것이 아니라 잠재적인 공간(Latent Space)에서 이미지를 압축한 뒤 연산을 시행한는 방식
-> 잠재 공간은 이미지 공간에 비해 48배나 작아 -
연산 속도가 훨씬 빠르고 경제적임.
LDMs에 해당g는 대표적인 인공지능 소프트웨어에는미드저니와 스테이블 디퓨전 등이 있으며, 두가지 모두 텍스트를 입력받아 이미지를 생성해주는(Text-to-Image) 모델임. (두 모델 이외에도 여러 소프트웨어가 있음.)
📌 AI 파운데이션 모델

📌 AI 이미지 생성 기술 발전 연표
| 연도 | 주요 사건 및 발전 |
|---|---|
| 2014년 | - GAN (Generative Adversarial Network) 등장 (Ian Goodfellow) - 얼굴 합성, 예술적 스타일 변환 등에서 큰 주목을 받음 |
| 2017~2018년 | - Transformer 모델 등장 (Vaswani et al., 2017) - NLP 분야에서 큰 성과를 보이며 텍스트-이미지 생성 모델의 기반 제공 - BigGAN과 StyleGAN의 등장으로 고해상도 이미지와 스타일 조절 가능성 향상 |
| 2020년 | - Diffusion Model 등장 - 점진적으로 노이즈를 제거하여 자연스럽고 고해상도의 이미지를 생성 - Imagen, Stable Diffusion 등 최신 모델들이 이 구조를 기반으로 발전 |
| 2021년 | - LDM (Latent Diffusion Model) 등장 - 연산 비용을 줄이기 위해 잠재 공간에서 노이즈 제거 방식 채택 - OpenAI의 DALL-E 공개, GPT-3 기반 이미지 생성 모델로 대중적 주목 |
| 2022~2023년 | - AI 이미지 생성 기술의 대중화 및 상용화 - Stable Diffusion의 오픈소스 제공으로 누구나 AI 이미지 생성 가능 - MidJourney, DALL-E 2, Stable Diffusion 등의 경쟁으로 산업 전반에 활용 |
| 2024년 | - 주요 AI 이미지 생성 툴: IDEOGRAM, MidJourney 6.1, Stable Diffusion 3.5, Flux, imagefx 등 - 사실적이고 고품질의 이미지 생성, 실제 사진과의 구별 어려움 - 개인화된 콘텐츠 제작, 디지털 아트, 광고, 패션, AI 가상 피팅, 버추얼 휴먼 등 다양한 산업으로의 확대 |
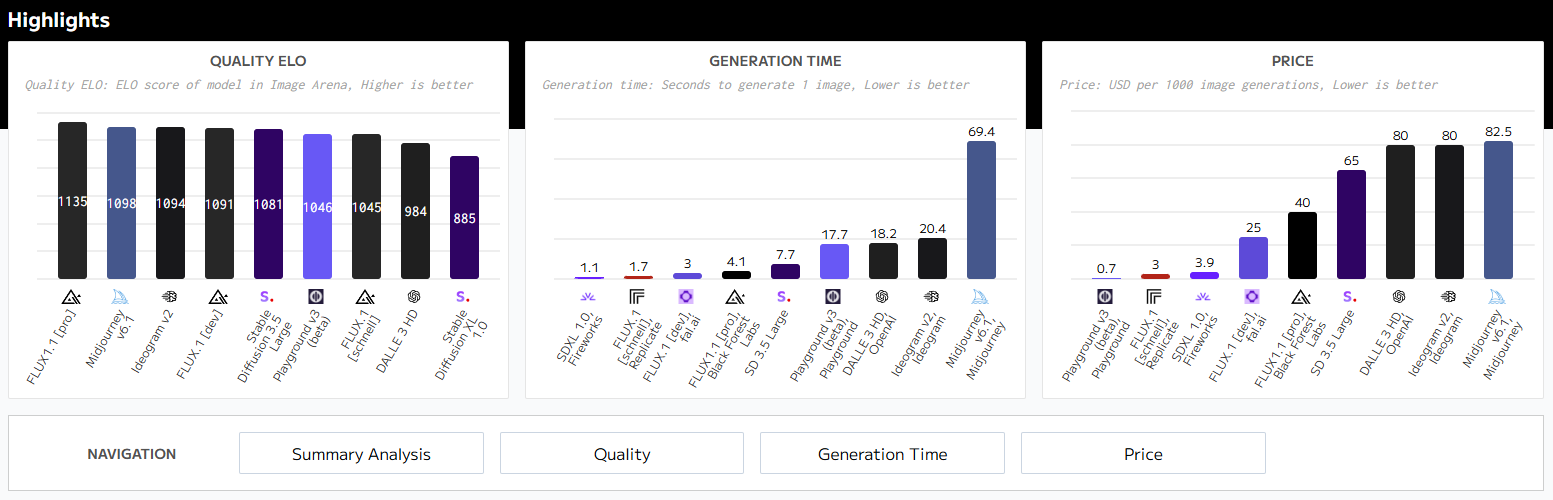
🎯 artificialanalysis.ai
- ELO SCORE (체스 레이팅 방식)기반으로 ai 모델 간 상대적 평가 진행
- 24.11 기준, 상위 AI 모델은 FLUX(pro), Midjourney(6.1v), adeogram(v2) 등이 차지하고 있음
- 사용자. 부터 직접 상대적 비교평가 방식으로. 평가 됨
-> eloscore를 보고 품질, 생성 시간, 제작 비용(클로즈 소스인 경우) 등을 고려하여 결정
📌 스테이블디퓨전(SD)

: 스테이블 디퓨전의 특징
- 내 PC만 있으면 무료로 이미지 생성이 가능함. (오픈소스)
- WEBUI, COMFYUI 등의 작업환경을 제공함.
- 자유도가 굉장히 높지만, 설정할 수 있는 변수(파라미터)가 굉장히 다양하고, 호환성이 높음.
- PC의 성능에 따라 이미지 생성 속도가 결정됨.
- 다양한 버전 및 확장 프로그램, API를 지원함.
- 스테이블 디퓨전 프롬프트작성을 위한 문법이 존재함.
기본 패키지 다운
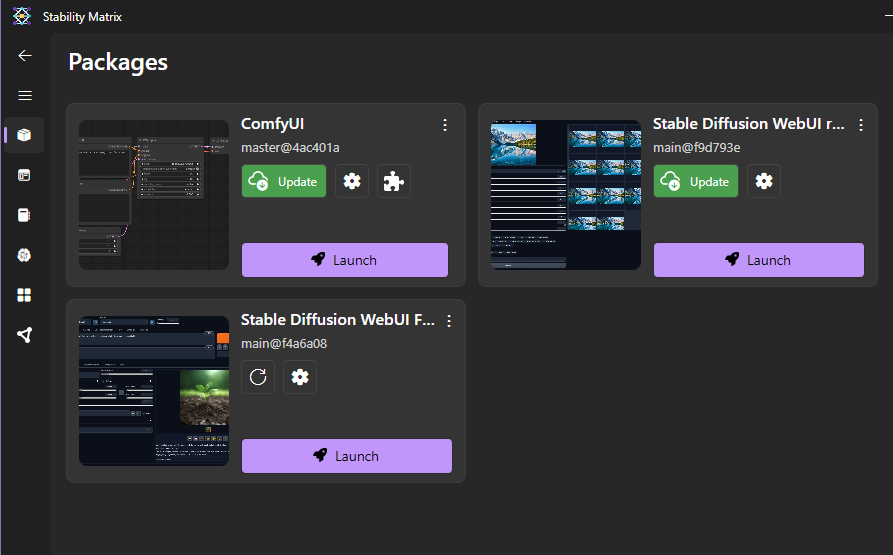
📌 Stable Diffusion 필수 용어
| 용어 | 설명 | 예시 및 권장사항 |
|---|---|---|
| Checkpoint | 이미지의 전체적인 형태를 결정하는 베이스 모델. 종류에 따라 실사, 3D, 2D 등으로 특화됨. | Ex) majicmix-realistic, DreamShaper. 적용 경로: Stability Matrix > Model Browser |
| VAE | Variational Autoencoder의 약자로, 이미지를 보정하는 기능 제공. | Ex) 실사: vae-ft-mse-840000-ema-pruned.ckpt 3D/2D: kl-f8-anime2.ckpt |
| LoRA | Low-Rank Adaptation의 약어. LDM 모델을 파인튜닝하여 품질 향상. | Ex) AI 버추얼 모델 외형 유지를 위한 LoRA 파일 생성 및 적용 |
| Sampling Method | 이미지 생성 과정에서 알고리즘 선택. 이미지의 질과 다양성 조정. | Sampling Steps: 샘플링 횟수로 권장 수치는 상황에 따라 다름. |
| Hires. Fix | 생성된 이미지를 고해상도로 보정하는 기능. | 권장: 고해상도로 이미지 후보정 작업 필요 시 활성화. |
| Upscaler | 이미지를 업스케일링하는 알고리즘 선택. | Ex) 실사 특화: R-ESRGAN 4x+ 사용. 적용 경로: Stability Matrix > models > Upscaler |
| Denoising Strength | 생성된 이미지에서 원본 이미지 변형 정도를 조절. | 권장 수치: 0.3~0.5 (text-to-image). |
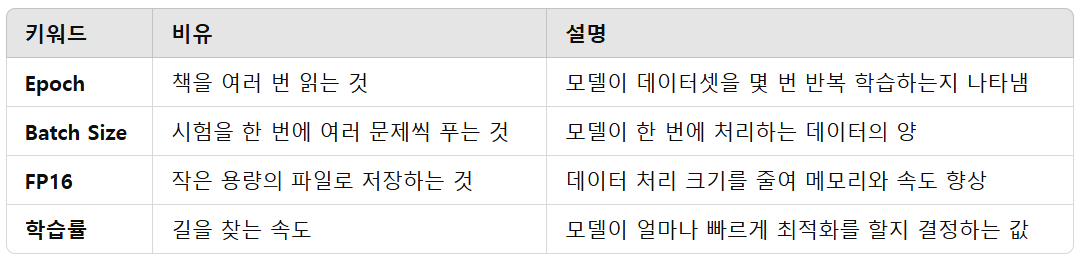
| Batch Count | 프롬프트와 파라미터로 이미지를 몇 번 생성할지 설정. | 권장: 필요한 횟수에 맞춰 설정. |
| Batch Size | 한 번의 작업에서 생성할 이미지 개수. | 권장: 일반적으로 Batch Count 조절 권장. |
| CFG Scale | 입력 프롬프트를 얼마나 따를지 결정하는 수치. | 권장 수치: 7~11 (높을수록 프롬프트 충실). |
| Seed | 이미지 생성의 랜덤성을 제어하는 값. 같은 Seed를 사용하면 동일한 이미지 생성 가능. | 권장: 재현성을 위해 고정값 설정. |
📌 UI 설정, 업스케일러 설정, 필수 확장 프로그램 정리
(1) UI 설정
| 설정 단계 | 설명 |
|---|---|
| Quicksettings list 수정 | - 상단 탭 우측 Settings > User Interface 선택. - Quicksettings list에 sd_model_checkpoint, sd_vae, CLIP_stop_at_last_layers 추가. |
| 설정 적용 | - Apply settings 버튼 클릭. - Reload UI 버튼 클릭. |
| 효과 | Checkpoint, VAE, Clip skip 설정을 메인 화면에서 쉽게 조정 가능. |
(2) 업스케일러 설정
| 업스케일러 이름 | 설명 | 권장 사용 사례 |
|---|---|---|
| R-ESRGAN 4x | AI 기술이 적용된 업스케일러로, 실사 이미지 업스케일링에 특화. | 실사형 인플루언서 이미지 제작. |
| R-ESRGAN 4x+ Anime6B | AI 기술이 적용된 업스케일러로, 애니메이션 이미지 업스케일링에 특화. | 애니메이션 이미지 제작. |
(3) 필수 확장 프로그램
| 확장 프로그램 이름 | 설명 | 설치 방법 |
|---|---|---|
| ControlNet | 자세 설정, 원근감, 빛 표현 등 수십 가지 커스터마이징 작업을 가능하게 하는 핵심 기능. | Extensions > Install from URL에서 URL: https://github.com/Mikubill/sd-webui-controlnet 입력 후 설치. |
| open pose editor | 피사체의 자세를 탐지하거나 직접 지정하여 원하는 자세를 쉽게 생성 가능. | 동일한 방식으로 설치. URL: 별도 URL 필요 시 제공. |
| Adetailer | After+detailer로 특정 부위(손, 얼굴 등)를 후보정하여 완성도 향상. | Extensions > Install from URL에서 URL: https://github.com/Bing-su/adetailer 입력 후 설치. |
추가 팁: 확장 프로그램 관리
- 다양한 확장 프로그램 확인:
- Extensions > Available > Load from 클릭 시 설치 가능한 확장 프로그램 목록 확인 가능.
- 인기 확장 프로그램 무료 설치 가능.
- 확장 프로그램 업데이트:
- Installed 탭 이동 > check for updates 클릭.
- Apply and restart UI 버튼 클릭 시 WebUI 재시작과 함께 업데이트 적용.
📌 미드저니(Midjourney)
-
미드저니의 특징
-
복잡한 설치 과정 없고, 사용방법이 어렵지 않다.
-
다양한 스타일의 고퀄리티 이미지를 쉽게 생성할 수 있음.
-
월 구독료를 지불해야하는 유료 S/W.
-
디스코{ OR 웹에서 즉시 빠른 이미지 생성이 가능함.
-
커뮤니티 활성도가 높고, 업데이트가 지속적임.
-
프롬프트 작성 시 지켜야할 미{저니 문법이 존재하며, 프롬프트 당 4장의 기본 이미지가 생성됨.
-
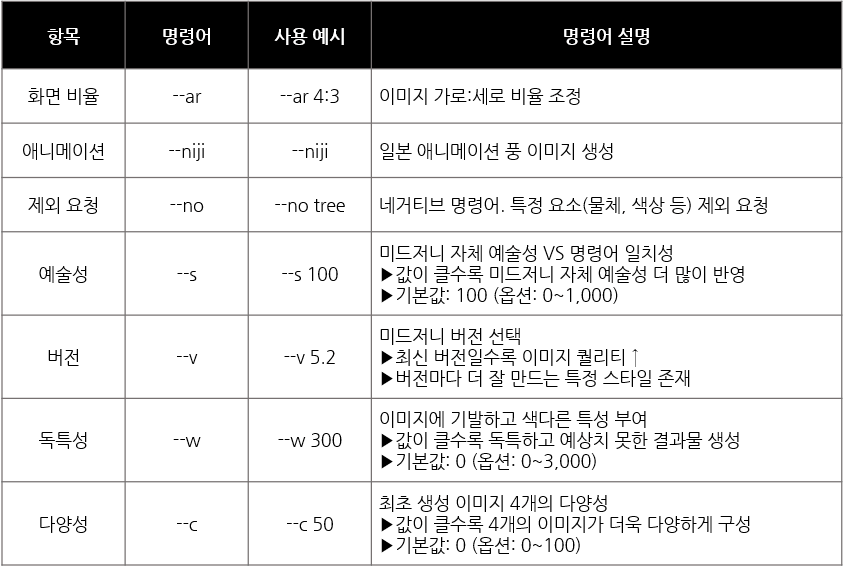
📌 미드저니 시작하기 (3) 스타일 프롬프트, 기본 문법 사용하기
미드저니 기본 문법을 통해 생성할 이미지의 비율, 형태, 스타일 등을 조정할 수 있으며, 스타일, 구도, 카메라, 조명 등을 표현하는 프롬프트가 추가된다면 더 쉽고 빠르게 원하는 이미지 생성이 가능함.
- Ex) 3D Animation(스타일), wide angle(구도),
Canon EOS-1D X MARK II (카메라),
Cinematic Lighting(조명)
*niji는 미드저니의 애니메이션 만화 그림체 특화모델
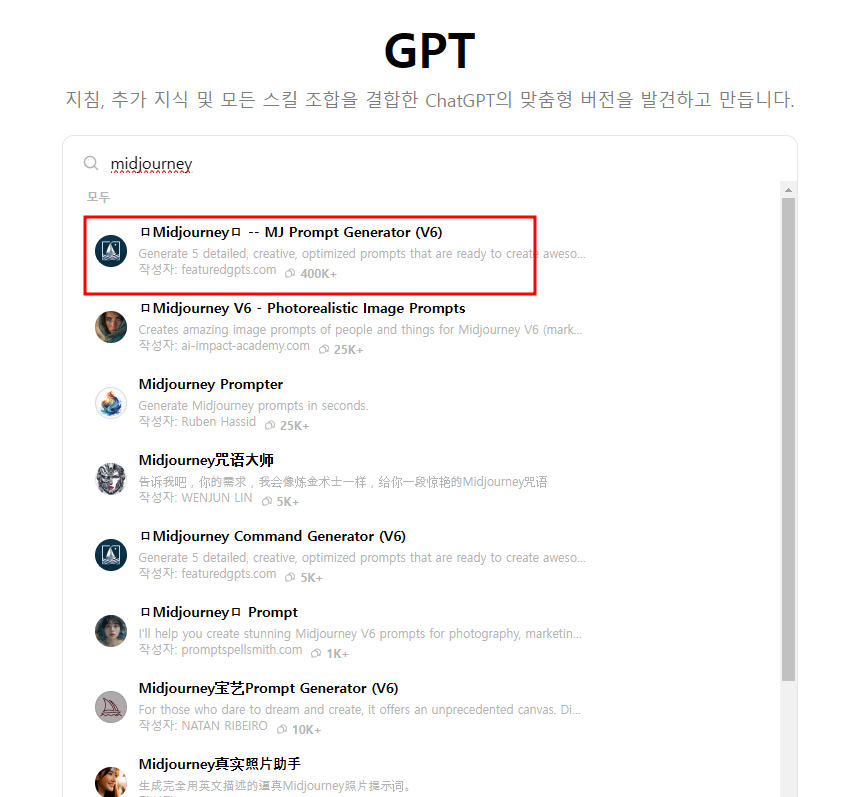
Chat-gpt 활용하기
미드저니 프롬프트 자동화 생성을 위한 GPTs를 자체 제작도 가능하지만, GPTs를 제작하기 위해서는 유료 구독이 필요하기 때문에, 기존 생성되어있는 미드저니 GPTs를 활용하는 것을 추천.
GPT메인 > GPT탐색 > midjourney 검색
최상단 GPTs 및 채팅 시작
- Ex) 9:16비율로 3d 스타일의 흰색 고양이를 만들기 위한 프롬프트를 작성해줘 → 프롬프트 5개 작성 복잡하고 창의적인 프롬프트 작성 과정을 GPT를 통해 효율적으로 단축시키고 해당 프롬프트를 기반 으로 수정하여 더 고품질의 결과물을 얻는 것이 가능
📌 LoRA
- (Low-Rank Adaptation): AI 모델을 나만의 스타일로 커스터마이징하기
LoRA의 개념
- LoRA는 대형 AI 모델을 더 작은 데이터셋으로 빠르게 적응시킬 수 있는 효율적인 파인튜닝 기법.
- 일반적인 파인튜닝은 모델의 모든 파라미터를 변경하는데 비해, LoRA는 적은 수의 파라미터만을 조정하여 모델의 성능을 효율적으로 개선할 수 있음
- AI 파운데이션 모델 별로 LoRA를 지원하는 방식과 형태가 다르고, 지원을 하지 않는 경우도 있음
kohya_ss
- 주요 기능: Stable Diffusion 등의 모델 파인튜닝적은 리소스로도 맞춤형 모델을 생성이 가능함
- 적용 분야: 특정 아트 스타일, 캐릭터, 인물, 배경, 제품 등
- 특징: 로컬 또는 가상 환경에서 구동(GPU 성능에 영향)
Replicate
-
- 주요 기능: Flux-dev (상업적 이용이 제한된 오픈소스)기반의 파인튜닝 기능을 제공
-
- 적용 분야: 특정 아트 스타일, 캐릭터, 인물, 배경, 제품 등
-
- 특징: 클라우드 GPU를 사용하는 방식으로, 가장 최신 모델인 Flux 모델의 LoRA를 적은 비용으로도 제작 가능
🚀 추가 - LoRA 모델 사용해보기
- Web UI(Forge) / 난이도 上
- 무료 제작이 가{함.
- 버전 관리 및 기{ 통합 용이
- PC 성{에 영향을 많이 받음- Replicate(api / 유료) / 난이도 下
- 저비용 고품질 결과물 제작 가능
- 버전 관리 및 기{ 통합이 어려움
- PC 성{에 영향을 받지 않음
