
Cloud Dataflow 란?
- 서버리스 환경, 직접 클러스터를 관리할 필요 X
- 서비스를 위한 프로그래밍에 전념할 수 있음
- 간접 운영 비용이 줄어듬
- 다른 GCP 리소스들을 이용할 수 있음
지원하는 프로그래밍 언어
- Java
- Python
- Go
Dataflow vs. Dataproc
| Dataflow | Dataproc |
|---|---|
| Apache Beam기반 | Apache Hadoop/Spark 기반 |
| Severless | DevOps |
| 기존에 레거시 없이 새로 접근할 때 적합 | Apache 빅데이터 생태계에 적합 |
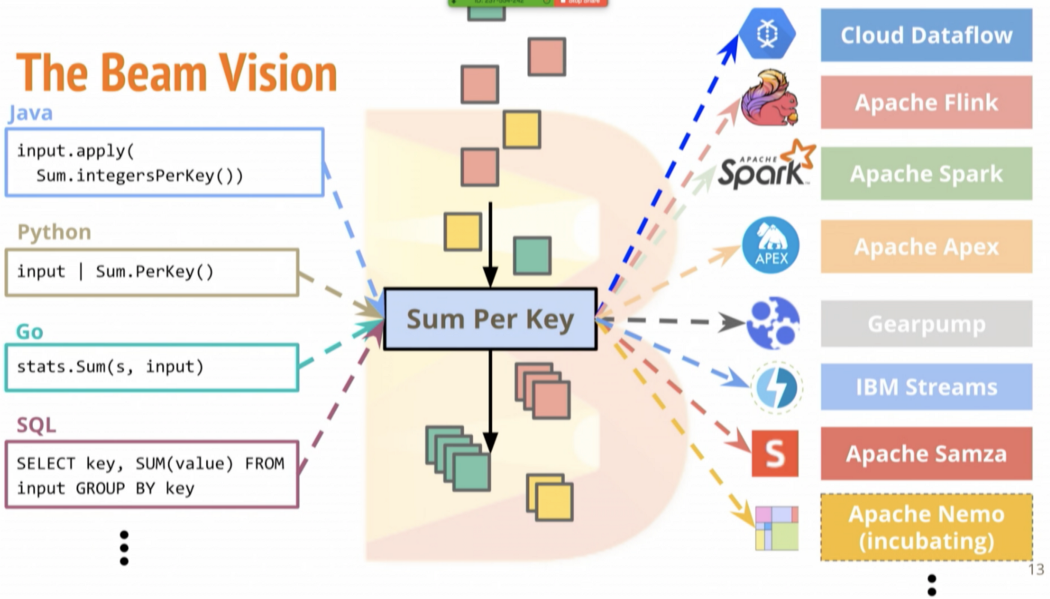
Apache Beam은 무엇인가?
Apache Beam은 구글에서 개발하여 2016년에 오픈소스로 공개한, ETL, batch, streaming 파이프라인을 처리하기 위한 unified programming model이다.
다양한 언어와 다양한 runner를 지원합니다.
Runner ?
분산처리 백앤드: Apache Flink, Apache Samza, Apache Spark, Google Cloud Dataflow

Dataflow 흐름 및 구성요소
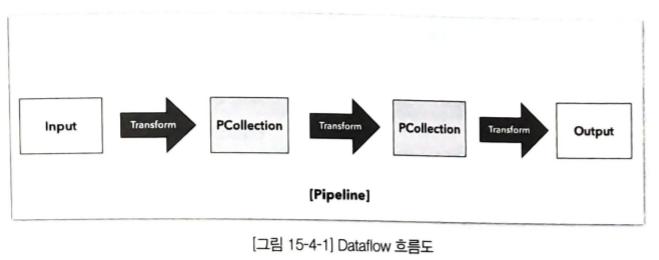
- PCollection: 데이터 저장을 위한 데이터 타입
PCollection
Dataflow Pipeline 내에서 데이터를 저장하는 개념으로 한 번 생성되면 그 데이터는 수정이 불가능합니다.
데이터를 변경하거나 수정하기 위해서는 PCollection을 새로 새성해야합니다.
특징
- 요소 유형: 모두 동일한 유형
- 불변성 : 변경 불가능
- 무작위 접근 : 개별요소에 대한 무작위 액세스 지원 X
- 크기와 경계 : 크기와 제한을 정할 수 있음, 무제한 가능
- 요소 타임 스ㅌ매프: 각 요소에 고유한 타임 스탬프가 존재
Unbounded Data 처리
스트리밍 데이터 처리
- 데이터가 끊이지 않고 들어오기 때문에 결과를 내보내야 하는 타이밍을 잡기 애매
- 시간을 기준으로 작업을 끊어서 처리하는데 이를 윈도윙이라고 합니다.
Window 개념
- Fixed Window
고정된 크기의 시간을 가지는 윈도우 - Slicling Window
다른 윈도우들과 중첩이 되는 윈도우 - Session Window
데이터가 들어오면 윈도우가 시작되고 세션 종료 시간까지 데이터가 들어오지 않으면 윈도우를 종료
지연 데이터와 Water Mark
실제 데이터들이 발생한 시간과 서버에 도착하는 시간의 차이를 어느 시점까지 대기하다가 처리를 할 수 있도록 예측하는 개념
- Watermark를 기반으로 윈도우의 시스템상의 시작 시간과 종료 시간을 예측
Trigger
처리 중인 데이터를 언제 다음 단계로 넘길지를 결정하는 개념
- Time trigger
특정 이벤트 시간에 작동 - Element count trigger
데이터의 개수를 기반으로 작동 - punctuations trigger
특정 데이터가 들어오는 순간에 작동 - Composite trigger
여러가지 trigger를 조합한 형태

함바라기