개념
웹 스크래핑은 웹 개발에 필요한 데이터를 실제 서비스 중인 웹에서 정보를 취합하는 것을 말한다.
Python에서 BeautifulSoup 이라는 라이브러리를 활용하여 작성하며, 스크래핑을 원하는 웹에서 올려놓은 글, 이미지, 순위, 줄거리 등의 정보를 가져와 활용할 수 있다.
🚩 BeautifulSoup Documentation
체크리스트
BeautifulSoup을 사용하여 데이터를 정제할 때는 다음과 같은 과정을 필요로 한다.
- BeautifulSoup import
- header
- request
- soup
- 데이터 정제
설계
나는 ‘만개의 레시피’ 라는 웹에서 레시피와 관련한 정보를 스크래핑하기로 했다.
스크래핑할 데이터는 이름/사진/난이도/요리시간/요리순서 를 각각 나눠 변수에 담고, 다시 딕셔너리로 하나로 묶어 총 400개의 레시피를 가져오려고 했다.
-
스크래핑 플로우
스크래핑을 거치는 과정은 하나의 페이지에서 여러 개의 URL을 스크래핑하고, 그걸 페이지 별로 반복하여 굉장히 많은 URL을 수집한다. 또 그 스크래핑한 URL을 가지고 타고 들어가 자료를 가지고 오는 순서로 되어 있다.
-
레시피 가져오기
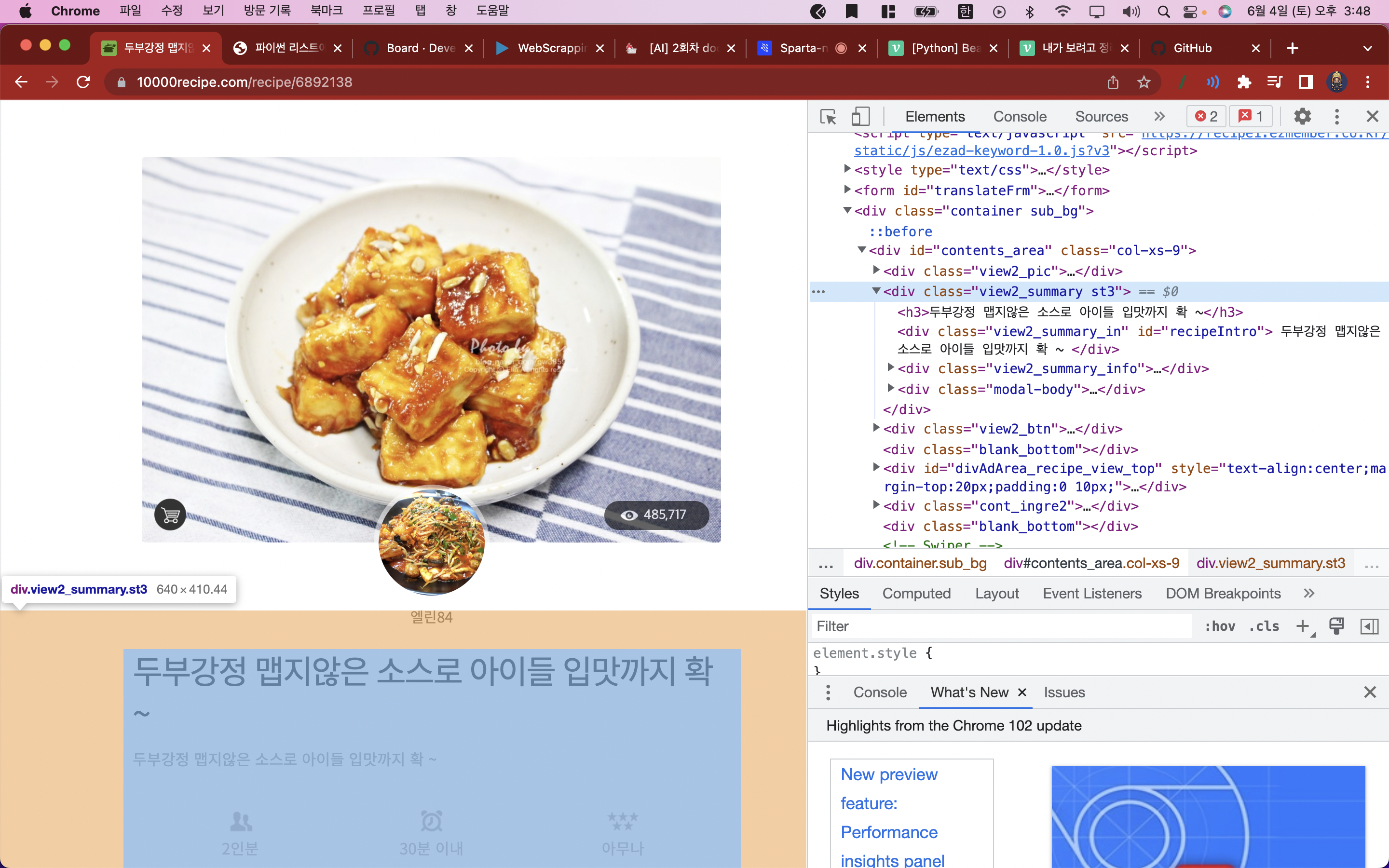
먼저 URL을 가져오기 보다 하나의 URL을 가지고 레시피 전체를 수집해오는 것을 먼저 수행하기로 했다.
하나의 레시피 상세 페이지에서 가져올 데이터는
1. 레시피 제목
2. 요리 시간
3. 요리 난이도
4. 요리 재료
5. 요리 순서
로 총 다섯 개의 필드로 묶어 가져올 것이다.
URL을 변수에 담아 넣고, 가짜 요청하기 위한 헤더를 만들고 리퀘스트를 진행한다. 가져온 HTML 페이지 전체를 데이터를 가져오기 위해 파싱(Parsing)을 진행한다.
파싱한 데이터를 가지고 정제할 데이터 필드에 해당하는 클래스 이름이나 셀렉터를 선택하고 해당 데이터의 밸류나 텍스트 split, strip메서드를 사용하여 값만 쏙 빼낸다
꺼낸 데이터를 변수에 담고, 다시 딕셔너리로 한데 묶어 리턴한다. 리턴하려면 함수로 묶어서 URL을 인자로 받으면 된다!- URL 가져오기
URL을 여러 개로 가져오기 위해서는 다시 페이지 URL이 여러 개 존재하는 페이지를 탐색한다. 리스트페이지에 해당하는 페이지를 찾아 개발자 도구로 어떤 부분이 링크를 받아 넘기는 지 확인한다.
만개의 레시피에서는 리스트에서 이미지를 클릭하면 레시피 상세 페이지로 이동하게 하므로 썸네일 이미지가 잔뜩있는 리스트페이지에서 이미지 부분을 가져오면 URL을 한 번에 여러개 수집할 수 있다.
레시피 데이터를 가져온 것 처럼 리스트페이지 URL을 변수에 담아 넣고, 가짜 요청 헤더와 리퀘스트를 진행, HTML을 파싱한다.
파싱한 데이터에서 href가 들어있는 클래스를 선택하면 클래스에 해당하는 복수의 데이터가 골라지므로, 반복문으로 슬라이싱하여 URL_LIST에 Append를 진행한다.
이 전 과정을 함수로 묶어 URL_LIST를 리턴한다.
- 페이지 넘어가기

URL리스트를 리턴하는 함수에 원하는 만큼의 페이지번호를 인수로 받는다.
페이지 번호에 대해 반복문을 만들고, URL을 Fstring으로 페이지 번호가 루프를 돌 때마다 바뀌도록 세팅해주면, 한페이지만 받는 것이 아닌 한페이지의 모든 URL을 다 수집하면 페이지 번호를 넘겨가면서 다른 페이지의 모든 URL을 수집하는 루프가 적용되므로, 10을 넣으면 10페이지까지 데이터가 있다면 100개든 1000개든 가져올 수 있는 것이다!
코드
⌨️ KAGGLE Notebook - 만개의 레시피 크롤링
💽 웹 크롤링 특강 셀프 코드리뷰
