
✏️ 실전 머신러닝 기초 공부자료
👀 딥러닝
👓 딥러닝(Deep Learning)이란?
비선형 데이터를 예측하는데 선형 회귀는 정확한 예측값을 가져다 주지 못함
선형회귀를 여러 번 반복하는 시도를 하게 됨 -> 실패
선형회귀 사이에 비선형의 레이어를 겹겹이 넣어 모델을 만듦 -> 성공!
💡 딥러닝은 선형회귀 사이에 비선형 레이어 층을 깊게 쌓는 모델
💡 Deep Neural Networks 구성 방법
👓 레이어 쌓기
딥러닝 네트워크는 인풋 노드 / 히든 노드 / 아웃풋 노드 세 가지로 구성
노드들의 모음을 레이어라고 함
하나의 레이어가 선형회귀로 이루어져 있으며 연결되어 있음(Multi Layer Perceptron
뉴럴 네트워크는 입력과 출력이 적고 은닉층이 많은 마름모꼴
은닉층 뒤에 활성함수를 집어넣음
- 인풋 레이어 - 기계에게 학습시킬 X값
- 히든 레이어 - 은닉층, 입력층과 출력층을 제외한 중간층
- 아웃풋 레이어 - 기계가 예측할 Y값
👓 네트워크 너비와 깊이
모델을 예측하기 위해서 여러가지 실험(튜닝)을 진행하는 방법 중 너비와 깊이를 조정해서 활용함
-
네트워크 은닉층의 노드 개수를 늘리는 방법(너비)
- 은닉층 1의 노드 : 8개 -> 16개
-
네트워크 은닉층 개수를 늘리는 방법(깊이)
- 새로운 은닉층 3 추가
👀 딥러닝의 주요 개념과 기법
📌 배치 사이즈와 에폭
배치 사이즈(Batch Size)
- 천만개의 데이터 셋을 한꺼번에 학습시키기에는 메모리가 너무나도 많이 필요하고, 현실적으로 많은 비용 발생
- 따라서 데이터셋을 작은 단위로 쪼개서 학습시키려는데 그 단위를 배치(Batch)라고 함
- 1000만개의 데이터셋을 1000개 씩 쪼개어 10000번 반복
- 이 과정을 Iterataion이라고 함
- Batch = 1000, Iteration = 10000
에폭(Epoch) - 똑같은 크기의 데이터셋을 가지고 반복 학습을 하는데 몇 번 반복할까를 정의하는 것이 에폭이다
- 데이터셋 1000의 데이터- 배치 사이즈는 100, 이터레이션은 10
- 1000의 데이터를 한번 훑어 학습하면 1 에폭
📌 활성화 함수
활성화 함수라고도 하고 Activation이라고 함
신호의 임계치(Threshold)를 넘어야만 전달 -> 이를 비슷하게 만든 것이 활성화 함수
활성화 함수는 비선형 함수(대표적으로 Sigmoid) 이어야 한다
1. Sigmoid
2. tanh
3. ReLU : 간단하고 많이 사용함
4. Leaky ReLU
5. Maxout
6. ELU
📌 과적합과 과소적합
딥러닝 모델을 학습시키는 과정에서 Training Loss는 낮아지는데 Validation Loss가 높아지는 시점을 Overfitting 이라고 하며 여러 스
킬을 사용해서 극복해야 하는 경우가 발생함
📌 데이터 증강
오버피팅을 해결하는 좋은 방법 중에 하나는 데이터의 개수를 늘리는 것
실제로는 데이터가 부족한 경우가 많기 때문에 조정을 해가면서 여러가지 데이터로 늘림
데이터 증강은 이미지 처리 분야에서 주로 사용됨
사진을 회전, 블러, 크롭 등등 하나의 사진으로 여러 시도를 수행함
아이는 자신의 손가락이라고 인식하지 못하고 여러 사람의 손가락을 보고서 손가락이라고 인지하게 됨 -> 일반화
📌 드랍아웃
연결된 노드 일부 연결선을 랜덤으로 끊어버려 출력을 0으로 만듦
모든 아이디어가 좋은 판단 요소가 아니기 때문에 끊어서 산으로 가지 않게 만듦
📌 앙상블
여러 개의 네트워크를 사용해서 여러 값들 중 모델에서 나온 출력을 기반으로 투표를 함
평균값, 최고값 등 출력값은 설계하기 나름
컴퓨팅 파워가 충분하다면 모델의 성능이 2% 상승할 수 있음
📌 학습률 조정
추세의 예측값을 항상 Global Minimum으로 도달하기는 어렵다.
Learning Rate Decay는 Local Minimum으로 빠르게 도달하는 방법
처음에는 큰 폭으로 접근하다가 조금씩 러닝 레이트가 줄어들면서 Local Minimum의 값으로 다가간다.
러닝 레이트 디케이는 모델의 오버슈팅을 막아주는데 효율적이다
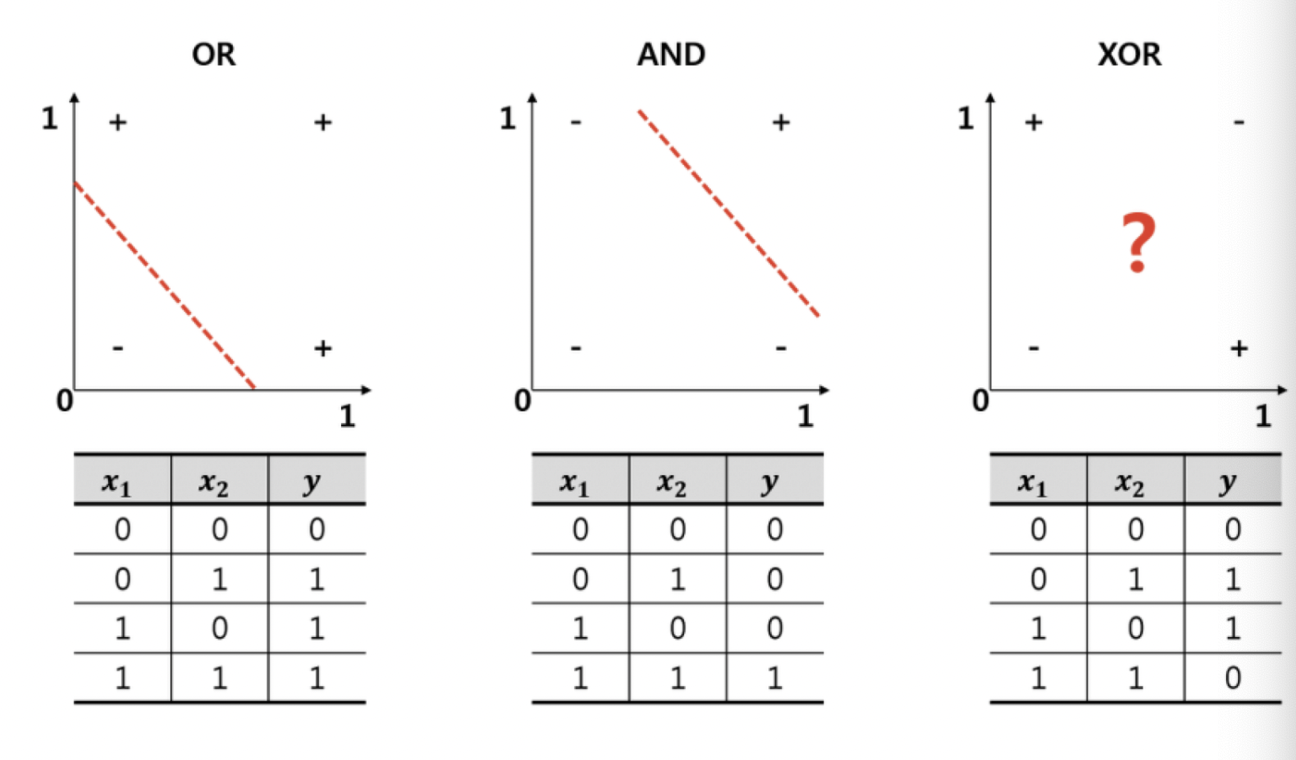
🎯 XOR 실습
🥊 XOR?
논리게이트 XOR은 일치하지 않으면 1을 리턴한다.
OR과 AND와 다르게 0과 1을 선형으로 구분할 수가 없다
따라서 선형논리회귀를 사용해서는 문제를 풀 수 없다
👣 선형논리회귀를 사용해 풀어보기
input 값인 x1, x2를 np.array로 선언한다
output 값인 y도 마찬가지
x_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32)
y_data = np.array([[0], [1], [1], [0]], dtype=np.float32)이진 논리 회귀를 사용해 0과 1사이의 값을 출력하는 sigmoid함수와 이진 크로스엔트로피를 사용해 모델을 컴파일한다. 그리고 출력해보면 0.5에 수렴하는 값들이 나오는데 0과 1이 나오지 않기 때문에 잘못된 예측이라고 할 수 있다
🚀 Multi Layer Perceptron을 사용하여 풀어보기
딥러닝에서는 여러개의 인풋/히든/출력 레이어 네트워크를 가지고 있고, 레이어 마다 노드 갯수가 있다.
모델을 만들어줄 때, 출력 값과 노드 갯수를 고려하여 선언한다. 히든 레이어는 relu, 출력 레이어는 sigmoid activation을 사용한다
fitting을 할 때, verbose 값을 1로 만들면 출력하고 0으로 만들면 출력하지 않는다. 일일히 확인하지 않고 빠르게 작업해볼 수도 있다.
model = Sequential([
Dense(8, activation='relu'),
Dense(1, activation='sigmoid'),
])
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=1000, verbose=0)💡 Keras Functional API
지금까지는 Keras Sequential 클래스를 사용하여 모델을 설계했다. 이는 단순한 모델 설계는 편리하지만 복잡한 모델을 만들기에는 한계가 있어 실무에서 주로 사용하는 Functional API를 활용한다
📌 라이브러리 임포트
모델에는 Model, 레이어는 Input 라는 라이브러리를 케라스에서 추가로 임포팅한다
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Input📌 모델 구조 설계 및 Summary
Functional API를 사용하면 네트워크의 구조를 서머리로 파악할 수 있게 된다.
각각 인풋/히든/출력 레이어의 출력 모양과 학습에 사용하는 파라미터의 갯수를 알 수 있다.
Output Shape의 None은 Batch Size로 변경이 가능한 값이다
input = Input(shape=(2,))
hidden = Dense(8, activation='relu')(input)
output = Dense(1, activation='sigmoid')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.summary()📌 값 예측
모델을 피팅한 뒤 출력 값에 X데이터를 넣어 예측할 수 있다
model.fit(x_data, y_data, epochs=1000, verbose=0)
y_pred = model.predict(x_data)
print(y_pred)