Principle of locality
The principle of locality assumes that programs tend to access memory in regular patterns. To illustrate, imagine you are a typical Korean student—your daily routine revolves around just a few places: the classroom, the cafeteria, and your home.
Now, if someone were to guess where they could find you with the highest probability, they'd likely choose one of these three places. Similarly, in programs, the locality principle means the next memory access will often be near or related to a recently accessed location.
Temporal locality
When a piece of memory is referenced frequently over a short period of time, it's called temporal locality. This concept refers to accessing the same data repeatedly within a short time span. Temporal locality is cache-friendly because, as long as the data remains in the cache, there's no need to repeatedly search through memory, improving performance.
Spatial locality
When a program references a piece of memory, it often references nearby or adjacent memory as well—this is known as spatial locality. To put it into perspective, it's like a student choosing to visit a park near their school for a change of scenery—they go there simply because it's close by. Similarly, spatial locality is cache-friendly, as the proximity of memory references improves performance by utilizing the cache more efficiently.
Cache-friendly program - practical example.
Memory pooling
When a system requires high performance, using malloc (a heap memory allocator) can result in data being scattered across different areas of memory, creating a cache-unfriendly environment and degrading performance.
Memory pooling solves this by allocating a block of memory in advance and reusing it, eliminating the need for repeated calls to malloc.
Look at the diagram below:
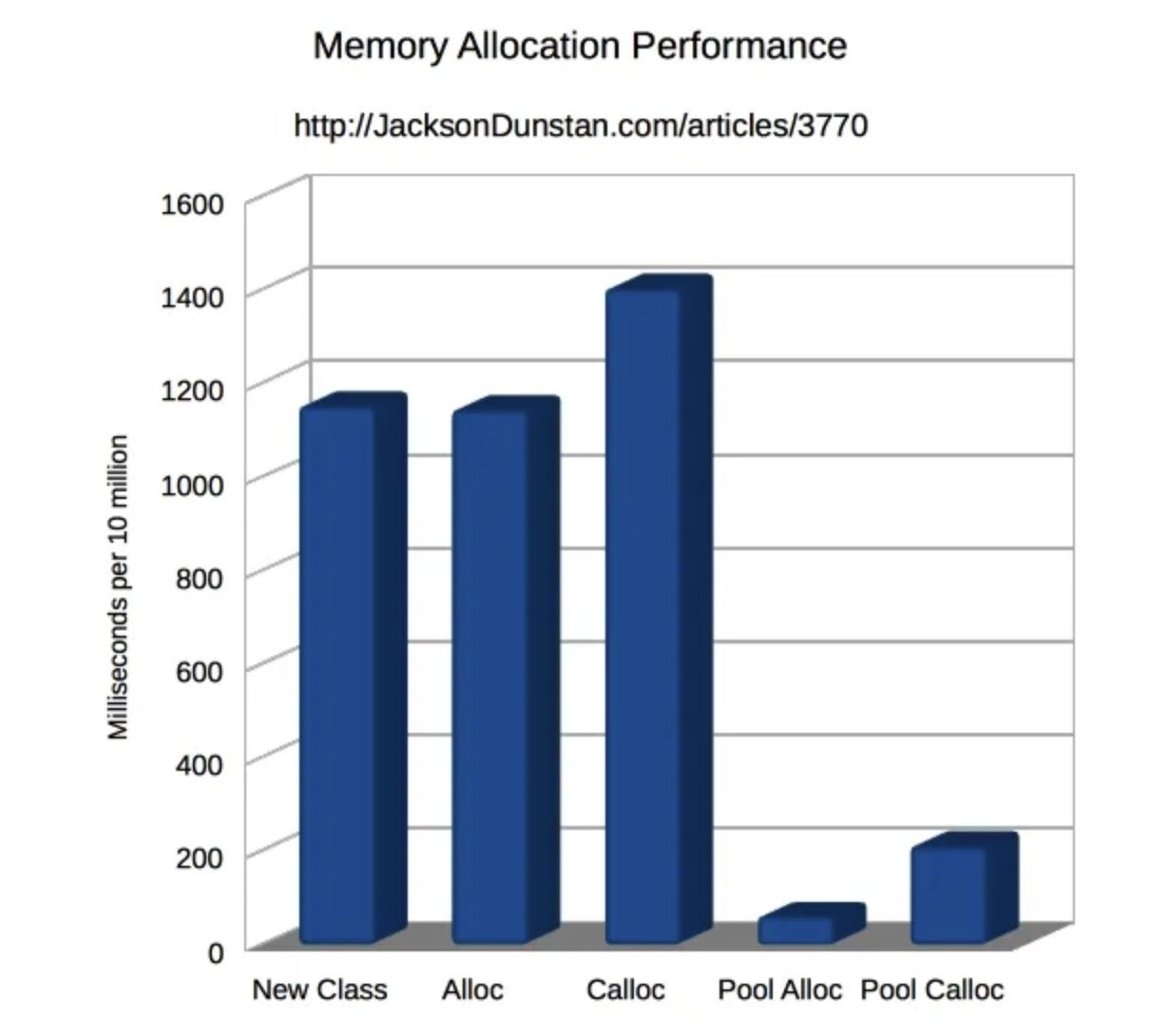
As you can see, the performance improvement from using a memory pool can range from 5 to 20 times.
However, memory pooling is typically suited for specific system requirements and isn't a versatile abstraction. The focus is more on the concrete implementation rather than being a general-purpose solution.
Struct realignment
When you write a program that checks if a linked list has a certain node, you may implement that like:
const SIZE: usize = 100000;
#[repr(C)]
struct List {
next: Option<Box<Node>>,
arr: [i32; SIZE],
value: i32,
}With this, you go on to write search algorithm like this"
impl List {
fn find(&self, target: i32) -> bool {
let mut current_node = Some(self);
while let Some(node) = current_node {
if node.value == target {
return true; // Target found
}
current_node = node.next.as_deref();
}
false
}
}
The code above simply iterates List and the data frequenly referenced are next and value, and arr is NEVER used. With the current implementation, as next and value is located physically away from each other bacause of the size of arr, it leads to a bad spatial locality. So, the better positioning will be:
#[repr(C)]
struct List {
next: Option<Box<Node>>,
value: i32,
arr: [i32; SIZE],
}Here I used #[repr(C)] for C-like memory layout on purpose. Without this, Rust aligns data in memory to take up the least amount of space, which may not optimize access speed. The fastest memory layout can only be achieved by developers who understand the access patterns of their data.
Cold-hot data separation
If you want to further optimize the codes above, consider introducing lifetimes to the Arr struct, allowing caches to store more nodes. As a result, you can improve cache efficiently and overall performance.
const SIZE: usize = 100000;
struct Arr {
data: [i32; SIZE], // Fixed-size array
}
#[repr(C)]
struct List<'a> {
next: Option<Box<List<'a>>>,
value: i32,
arr: &'a Arr,
}
impl<'a> List<'a> {
fn find(&self, target: i32) -> bool {
let mut current_node = Some(self);
// Iterate through the list
while let Some(node) = current_node {
if node.value == target {
return true;
}
current_node = node.next.as_deref();
}
false // Target not found
}
}
Do I need all these techniques?
Most of the time, you don't. However, it’s essential to distinguish between "you cannot" and "you do not."
Cache optimization is primarily about enhancing performance, which involves using analysis tools and scrutinize system throttles and bottlenecks. If the system doesn't have these requirements, feel free to experiment with these techniques, but don't take them too seriously.
