
구글이나 네이버 등에 포털사이트에서 내가 만든 사이트가 검색이 잘되기위해서는 SEO가 중요합니다. SEO는 Search Engine Optimization의 약자인데 한국말로하면 검색엔진최적화입니다.
웹사이트를 구축한 후에 필수적으로 하는 일인데요 처음에 용어도 낯설고 왜 해야되는지 궁금해서 상사님께 문의를 해보니 robot.txt를 넣으면 웹로봇이 웹사이트를 돌아다니면서 정보를 찾아서 포털사이트에 뿌려주는 거라고 배웠습니다. 그렇게만 알고 그에 대한 용어라든지 어떻게 돌아가는지에 대한 작동원리를 알지못한 거 같아 이번 기회에 정리하고자 글을 작성합니다.
SEO 동작 원리
웹크롤러라는 자동화된 프로그램을 사용하여 웹사이트에 있는 텍스트, 이미지, 동영상 등을 데이터를 긁어모아서 포털사이트에 검색했을 때 노출되게해주는 거라고 생각하면 됩니다.
SEO 주요 단어 설명
웹 크롤러(Crawler) : '크롤러'('로봇' 또는 '스파이더'라고도 함)는 한 웹페이지에서 다른 웹페이지로 연결되는 링크를 따라가며 웹사이트를 자동으로 검색하는 데 사용되는 프로그램을 가리키는 일반적인 용어입니다. Google 검색에 사용되는 Google의 기본 크롤러를 Googlebot이라고 합니다.
크롤러(Crawler): 사전적 의미로는 '기어다니는 것'이라는 뜻이며, 파충류라는 뜻도 있다.
크롤링(Crawling) : 개인 혹은 단체에서 필요한 데이터가 있는 웹(Web)페이지의 구조를 분석하고 파악하여 긁어옵니다. 여기서 긁어온다는 의미는 모두 그대로 가져오는 것을 말합니다.
색인생성(indexing) : 웹페이지에 텍스트, 이미지, 동영상 등의 데이터를 저장하는 것입니다.
색인
Google 검색은 웹 크롤러라는 소프트웨어를 사용하는 완전히 자동화된 검색엔진입니다. 웹 크롤러는 정기적으로 웹을 탐색하여 Google 색인에 추가할 페이지를 찾습니다. -구글
🖥️Meta Tag 설정
태그는 웹페이지에 대한 정보를 제공하는 기능을 가지고 있습니다. 그러한 정보를 '메타데이터'라고 부르는데 메타데이터는 웹페이지에 나타나지않고, 검색엔진이나 웹크롤러를 통해 수집됩니다.🔸keywords : 검색엔진에 의해 검색되는 단어을 지정합니다.
(10개 이하의 핵심키워드 지정합니다.)
🔸description : 검색결과에 표시되는 문자지정합니다.
(200~300자로 요약해서 적으며이때 키워드를 3회가량 반복하면 좋습니다)
🔸robots : 검색로봇제어
🔸author : 페이지 작성 제작자이름
🔸location: 위치
🔸copyright : 저작권
🖥️OG(Open Graph) 태그
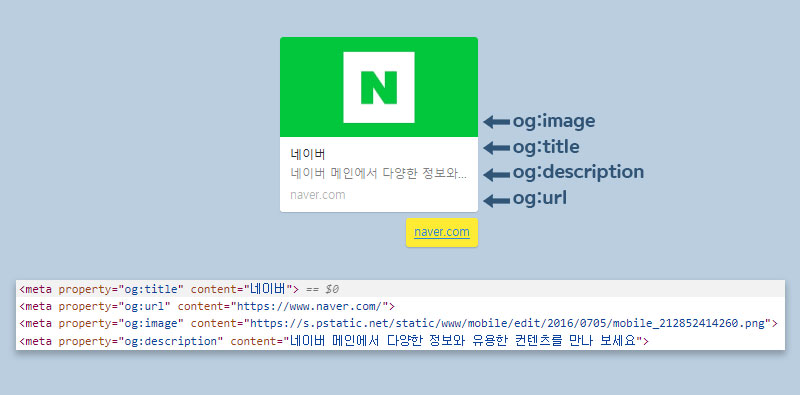
카카오톡에 사이트를 공유하게 되면 미리보기로 어떠한 사이트인지 미리보기할 수 있는게 og입니다.
만약 웹사이트가 오픈 그래프 프로토콜을 지원한다면, 웹사이트에 들어가기도 전에 뭐하는 사이트인지 알 수 있다. (나무위키)
🤖Robots.txt
META Tag 설정하기에 앞서서 웹로봇검색(검색봇)으로 인해 사이트 돌출, 컨텐츠 돌출 등 웹사이트 내의 컨텐츠가 돌출이 용이하게 하고 싶거나 돌출을 제한하는 방식으로 robots.txt를 우선 인식하도록 하고 있으며 메타태그로도 설정이 가능하지만 메타태그의 경우 그 제한사항이 있어 검색봇은 robots.txt을 우선하여 조건에 맞는 웹사이트 컨텐츠 돌출을 진행합니다.
이렇게 이야기를 하면 어려우니까 쉽게 이야기한다면요
서두에서 말한대로 웹로봇이 크롤링을 하면 웹사이트를 돌아다니면서 정보를 얻는거라고 했는데요
막 돌아다니는게 아닌 robots.txt가 가이드 역할을 해줘서 URL 어느부분에 엑세스를 해야하는지 알려주는거라고 생각하면됩니다.

⌨️수정 방법
🔸모든 문서접근을 허가
User-agent: *
Allow: /
🔸모든 문서접근을 거부
User-agent: *
Disallow: /
🔸MSNBot이라는 로봇에 admin, tmp 디렉터리 접근을 차단
User-agent: MSNBot
Disallow: /admin/
Disallow: /tmp/
웹사이트에 웹 크롤러같은 로봇들의 접근을 제어하기 위한 규약이다. 아직 권고안이라 꼭 지킬 의무는 없다. - 나무위키
🔸user-agent : 크롤러를 지정하는 것입니다. (구글인지 네이버인지)
🔸allow : 크롤러를 허용할 경로입니다.
🔸disallow : 크롤러를 제한할 경로입니다.
🔸sitemap : 사이트맵이 위치한 경로의 전체 URL
⌨️검색봇 종류
🔸구글 로봇 : Googlebot
🔸구글 이미지 : googlebot-image
🔸구글 모바일 : googlebot-mobile
🔸야후 로봇 : Slurp, yahoo-slurp
🔸야후 이미지 : Yahoo-MMCrawler
🔸야후 블로그 : yahoo-blog
🔸MSN : MSNBot
🔸MSN 이미지 : psbot
🔸네이버 : cowbot, naverbot, yeti
🔸다음 : daumos
🖥️ Sitemap
사이트맵이란 웹사이트에서 중요한 페이지 정보를 제공해주고 크롤링에게 가이드를 해주는 역할이라고 생각하면 됩니다. xml파일로 구성되어있으며 웹크롤러가 xml파일을 읽어 페이지를 가져올 수있습니다.
필요한 이유
큰규모의 사이트
대부분에 웹사이트는 크롤러가 찾을 수 있습니다 하지만 규모가 큰 사이트는 페이지가 많아 하나 이상의 다른 페이지에 연결되도록 하기 어려워 크롤러가 발견하지 못하는 경우가 있어 사이트맵이 필요합니다.
Reference
크롤러
https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers?hl=ko
사이트맵
https://developers.google.com/search/docs/crawling-indexing/sitemaps/overview?hl=ko
robots.txt
https://namu.wiki/w/robots.txt
https://seo.tbwakorea.com/blog/robots-txt-complete-guide/
https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=ko
