Deadline: 24.06.26
오늘 리뷰할 논문은 2021년 Open AI가 발표한 모델 CLIP(Contrastive Language-Image Pre-training)이며, 축약되지 않은 arxiv 버전을 다루려 한다.
논문 출처: https://arxiv.org/pdf/2103.00020
코드 출처: https://github.com/OpenAI/CLIP
Intro, Approach를 위주로 정리하였다.
🔸기존 문제점:
1) CV는 이미 고정된 형태의 object를 분류하도록 훈련됨
2) 새로운 시각적 개념을 학습하려면 라벨링 데이터가 추가적으로 필요
🔸제안 내용: 이미지에 대한 raw text(예: 캡션)을 사용해 학습하는 방법
🔸결과:
1) image-caption을 예측하는 사전 훈련을 통해 시각적 개념을 참조 및 새로운 개념을 설명 가능
2) downstream task에서 zero-shot 달성
(OCR, 비디오에서의 액션 인식, 지리적 위치 확인, 다양한 종류의 세밀한 객체 분류 등 30개 이상의 다른 컴퓨터 비전 데이터셋에서좋은 성능을 보임)
1. Intro
NLP 분야에서는 웹 규모의 raw text를 직접 학습하는 방법이 labeld NLP dataset을 통한 방법을 능가하는 연구 결과가 나왔지만,
Computer Vision에서는 여전히 ImageNet과 같은 데이터셋으로 모델을 pre-train하는 것이 표준이다.
자연어는 일반성을 통해 훨씬 더 넓은 범위의 시각적 개념을 표현하고 감독할 수 있는데
Web text를 직접 학습하는, 확장 가능한 pre-train 방법도 이와 비슷한 결과를 내지 않을까?
따라서 이들은 인터넷에서 4억 쌍의 새로운 (image, text) 데이터셋을 생성 후,
ConVIRT의 단순화된 버전을 처음부터 훈련시킨 CLIP(Contrastive Lanugage-Image Pre-training) 모델을 제안한다.
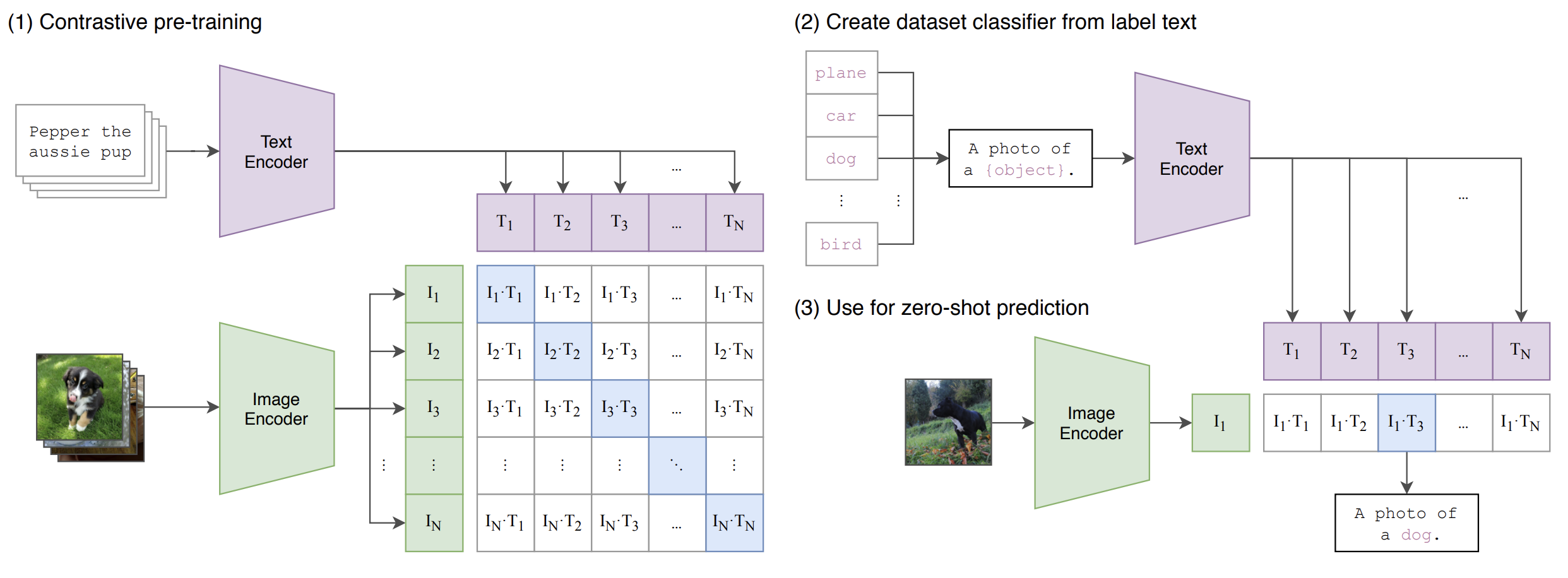
<CLIP의 동작 방식>
일반적으로 이미지 모델은 일부 레이블을 예측하기 위해 image feature extractor와 linear classifier를 joint-training 하지만,
CLIP은 image encoder와 text encoder를 joint-training하여 올바른 (image, text) 쌍을 예측한다.
2. Approach
2.1. Natural Language Supervision
이 논문의 핵심은 자연어에 포함된 supervision의 perception을 학습하는 것이다.
자연어로부터 학습하는 것은 다른 학습 방법에 비해 몇 가지 장점이 있다.
- 정형화된 라벨이 없기에 확장이 쉬움
- 대부분의 Un-Supervised, Self-Supervised 접근법은 단순한 표현을 학습하지만
이와 다르게 표현과 언어를 연결해 Zero-shot transfer가 가능
2.2. Creating a Sufficiently Large Dataset
이들은 인터넷에서 수집한 4억개의 (image, text) 쌍으로 구성된 새로운 데이터셋 WIT(WebImageText)을 구축하였다.
2.3. Selecting an Efficient Pre-Training Method
NLP Supervision을 성공적으로 확장하기 위해선 훈련 효율성이 중요하고,
저자들은 이를 고려해 최종 pre-training 방법을 선정하였다.
사전 학습 방법은 다음과 같다.
초기에는 VirTex와 유사하게 CNN과 텍스트 변환기를 처음부터 공동 훈련하여 이미지의 캡션을 예측하였다. 하지만 이 방법을 효율적으로 확장하는데 어려웠고,
아래 그림의 파란색 그래프 모델은 주황색 그래프(Bag of Words 예측)보다 효율성이 3배 낮았다.
이 두 방법의 공통점은 이미지에 동반된 텍스트의 정확한 단어를 예측하는 것인데,
이는 이미지와 함께 발생하는 다양한 설명, 댓글, 관련 텍스트 때문에 어려운 작업이다.
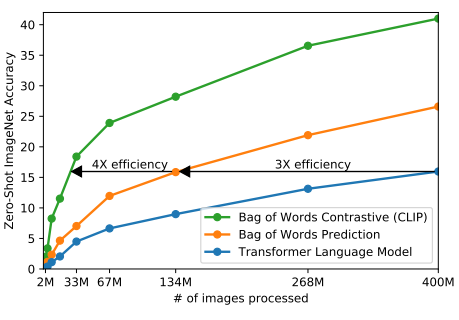
최근 Contrastive representation 학습 연구는 대조적 목표가 동등한 예측 목표보다 더 나은 표현을 학습할 수 있음을 발견했고,
다른 연구에서는 이미지 생성 모델이 고품질의 이미지 표현을 학습할 수 있지만 동일한 성능의 대조 모델보다 10배 이상의 연산을 필요로 한다는 결과가 나왔다.
따라서 저자들은 전체 텍스트가 어떤 이미지와 짝을 이루는지 예측하는, 더 쉬운 대리 작업을 해결할 수 있는 시스템을 구상했다.
즉, 예측 목표(주황색 그래프) ➡️ 대조 목표(초록색 그래프)로 바꿨더니 zero-shot transfer 속도가 4배 빨라졌다.
N개의 (image, text) pair가 주어지면 CLIP은 배치 내의 N*N 가능한 (image, text) 중 실제로 발생한 쌍을 예측하도록 학습했다.
이를 위해 CLIP은 배치의 N 쌍의 image 및 text embedding의 cosine similarity를 최대화하면서 N² - N 쌍의 잘못된 임베딩 유사성을 최소화하도록
image encoder와 text encoder를 joint trainig 하여 multi-modal embedding space을 학습했다.
ImageNet 가중치로 image encoder를 초기화하거나 pre-trained weight로 text encoder를 초기화하지 않고 처음부터 모델을 훈련했다.
representation과 contrastive embedding space 사이의 non-linear projection 사용 대신,
각 인코더의 representation에서 multi-modal embedding space로 매핑하기 위한 linear projection만 하였다.
2.4. Choosing and Scaling a Model
image encoder
1) ResNet-50
2) ViT
위 두개의 아키텍쳐를 약간 수정함
너비, 깊이, 해상도 증가하는 연산 실행
text encoder
1) Transformer
text encoder는 ResNet의 너비 증가에 비례해 모델의 너비만 확장함 (깊이 확장 ❌)
2.5. Training
5개의 ResNet과 3개의 ViT를 훈련했고, ViT-L/14@336px 모델의 성능이 가장 높았다.

Figure의 (1)단계에서 반드시 주대각선 방향으로 결과가 나오는지 알아보기