식당 예약 & 웨이팅 관리 TroubleShooting
1.@Transactional은 클래스에 붙이지 말자

Service 계층의 public 메서드라고 무조건 Repository 계층을 활용하는 것은 아님 → @Transactional을 클래스에 붙이면 트랜잭션 사용을 원치 않는 public 메서드까지 전부 트랜잭션을 사용하게 된다.따라서 @Transactional은 메서드
2.lock 관련 정리 사항들
Redisson에서는 lock 취득 실패 스레드들은 Redis pub/sub과 spin lock이 혼합된 방식으로 lock을 얻을 수 있을 때 까지 대기한다.따라서 Lettuce를 사용할 때와 달리 아래와 같은 lock 대기 코드를 구현하지 않아도 된다.try-fina
3.AOP self-invoation 정리
Spring AOP를 활용해 Lock AOP를 구현하던 중, AOP가 제대로 적용되고 있지 않다는 사실을 알게 되었다.saveReservationWithLock()은 외부에서 save() 호출 시 같이 호출이 되는 구조이다.여기서 자기 자신의 메서드를 호출하는 것이 문
4.Spring Webflux는 과연 현재 프로젝트에 어울릴까
spring에서 반응형 프로그래밍 지원을 위한 비동기 논블로킹 웹 프레임워크reactive 스트림 사양을 기반으로 동작한다.이벤트들을 비동기적으로 처리하며 이를 Publisher-Subscriber 패턴(Reactive Stream)으로 구현하며한 스레드 내에서 요청에
5.꼬리를 놓을 줄 모르는 직렬화/역직렬화 트러블슈팅 - 1
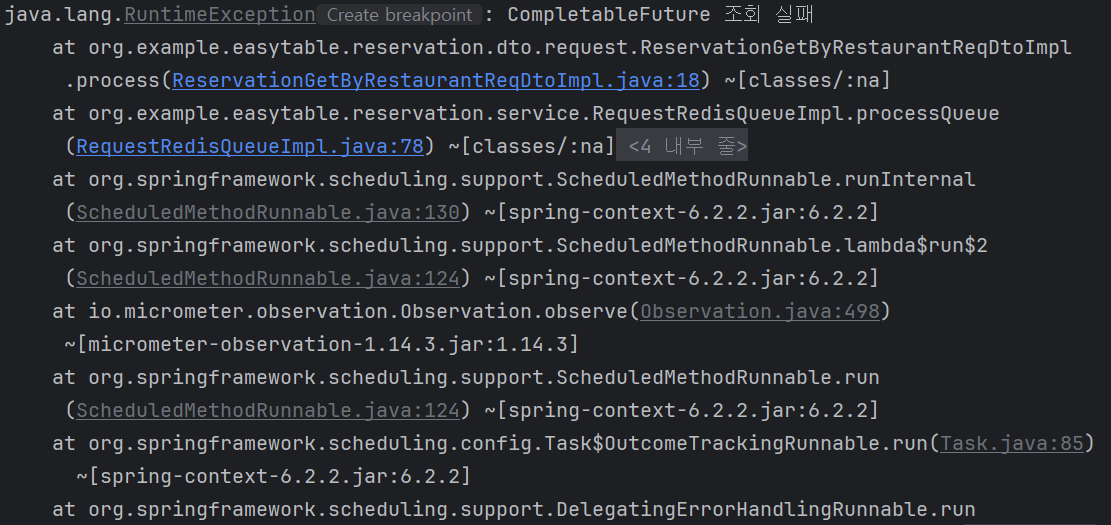
processQueue() 수행 시 아래와 같은 에러 발생Jackson이 cancelled 필드에 대해 역직렬화를 실패했다는 내용인데, 기억 상으로는 역직렬화 대상인 ReservationReqDto의 구현체들 중에서는 해당 필드를 사용하는 곳이 없었다.이상하다고 생각해
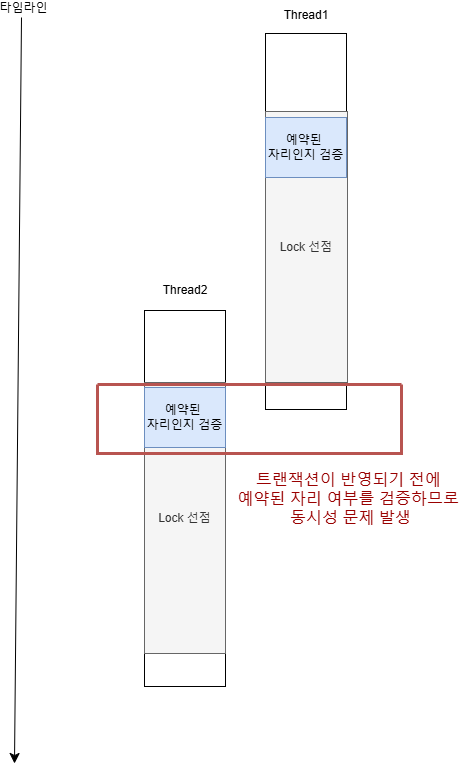
6.Redis Queue 동시성 문제 체크포인트
ZSet 대신 Set을 도입해 역직렬화 문제를 해결했지만, 그 결과 요청 큐와 Completable 저장공간의 동기화 문제가 발생했다.따라서 아래와 같이 두 공간에 대한 데이터 저장 작업의 원자성을 보장하기 위해 아래와 같이 synchroized를 적용하였다.이후 Re
7.대기열 구현 아이디어 V2
Controller 측에서는 Service 계층의 메서드를 호출한 후 비동기 방식을 통해 결과를 기다림Service 측에서는 들어온 요청 검증 후 유효하다면 Waiting Queue에 저장Waiting Queue가 꽉 찼다면 요청 폐기(backpressure 매커니즘)
8.Redis 분산 lock 세션
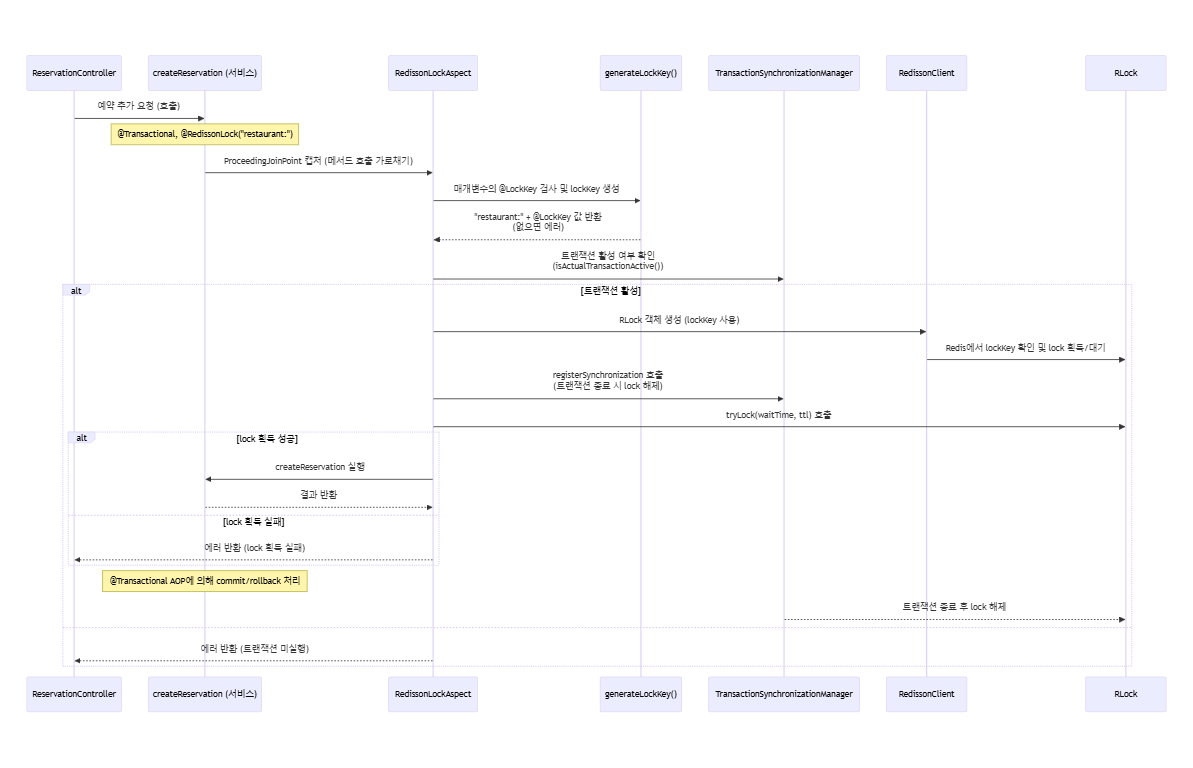
ReservationController.javaReservationService.javaRedissonLock.javaLockKey.javaRedissonLockAspect.javaRedissonConfig.javaReservationController에서 예약 추가를
9.Redis + Spring Webflux 기반 대기열 큐 세션 자료
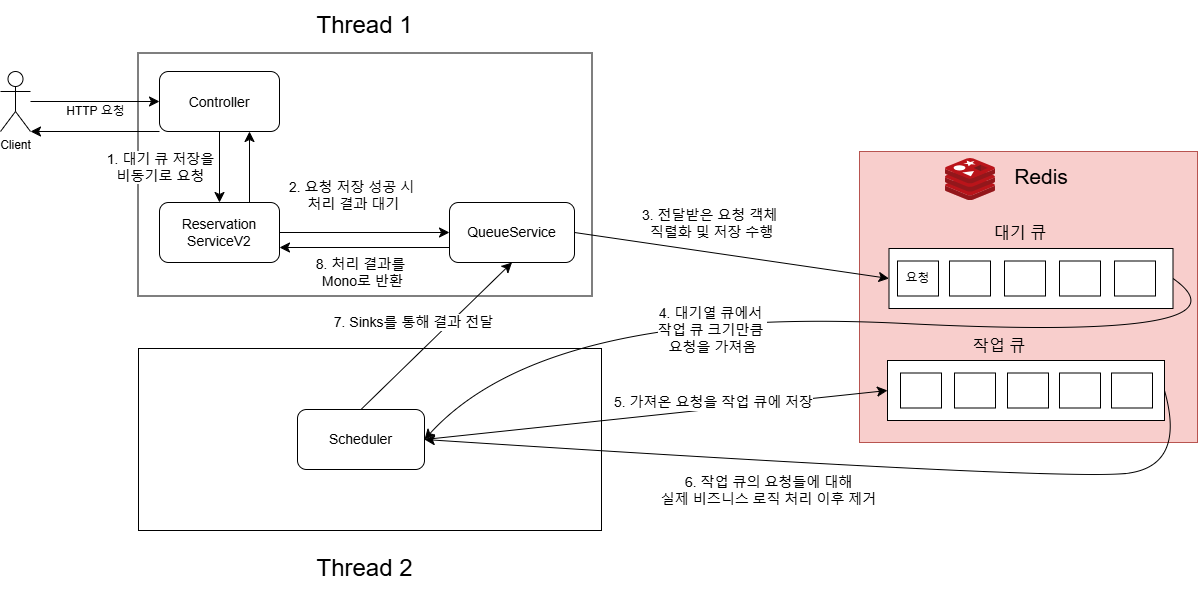
얼핏 보면 3 ~ 6번 과정은 하나의 큐만 사용하는 방식이 오버헤드가 더 적으므로 큐를 굳이 분리해야 한다고 느끼지 못할 수 있다. 하지만 큐를 나눠 관리하게 되면 다음과 같은 이점들이 생긴다.원자성 및 동시성 제어 가능단일 큐로 요청을 처리할 경우 요구사항에 따라 요
10.대기열 구현 아이디어 V3
결론적으로는 구현된 대기열의 여러 가지 사항(큐를 나눈 이유, 작업 큐를 비우는 방식을 스케줄러로 구현한 이유) 등에 대해 why?를 제대로 설명할 수 없다는 문제가 있음큐를 나눈 이유 부족Reactor core & Redis 혼용스케줄러로 작업 큐에서 요청을 꺼내는
11.Spring Data Redis Streams 정리
Redis 5.0에서 도입된 Message Broker 역할의 자료구조저장되는 데이터들을 시간 순서대로 관리하며(FIFO), 소비자 그룹을 통해 여러 클라이언트가 동일한 스트림을 소비할 수 있도록 한다.또한 새로운 데이터 항목이 추가될 때 까지 대기하는 blocking
12.기초적인 Consumer group 생성 문제 해결법

grafana로 성능 테스트를 수행하기 위해 기존 로컬에 설치되어 있던 Redis 등의 의존성을 Docker로 변경하였다.하지만 의존성을 수정하니 아래와 같은 문제들이 발생했다.Redis Cloud에서는 자체적으로 stream 키를 포함한 여러 데이터들을 미리 준비해
13.성능이 나아졌나요? 아니요 제자리걸음이에요

로그인 → 예약 요청의 순서로 진행되며 각 작업들의 응답 속도를 별개로 측정할 수 있도록 구성하였다.(마지막 예약 저장 시간) - (첫 예약 저장 시간) = 24.215745(초)평균 예약 저장 시간: 24.239(밀리초)(마지막 예약 저장 시간) - (첫 예약 저장
14.제자리걸음이었던 이유는 병목현상 때문

분산 lock으로 인해 성능이 저하되던 부분을 원자적 쿼리로 대체하고, 불필요한 쿼리들도 일부 제거했지만 JMeter 테스트 상으로는 오히려 더 느리게 나오는 문제가 발생했다.개선 전개선 후또한 같은 테스트를 수행할 경우에도 평균 응답 시간의 편차가 꽤 있었기에, 이에
15.단 1%의 충돌도 허용할 수 없을 때

대기열 상에 성능 테스트 시 특정 구간에서 처리가 지연되는 것을 확인했다.혹시나 싶어 Redis 모니터링을 해 보니 엄청난 속도로 XREADGROUP들이 실행되고 있었다.이는 Redis Streams를 아래와 같은 방식으로 구독할 때 생기는 현상일 뿐이었다.따라서 해당
16.Spring + Kafka 사용법
의존성 추가Kafka + Zookeeper Docker ComposeProducerConsumerProducer 측면Kafka에서는 add 시 maxlen을 신경쓰지 않아도 되는가?Kafka에서는 add 시 maxlen을 지정하지 않는다.전체 로그 크기, 보존 기간 등
17.partitioning을 정해진 수의 Stream들에 적용해 보았다
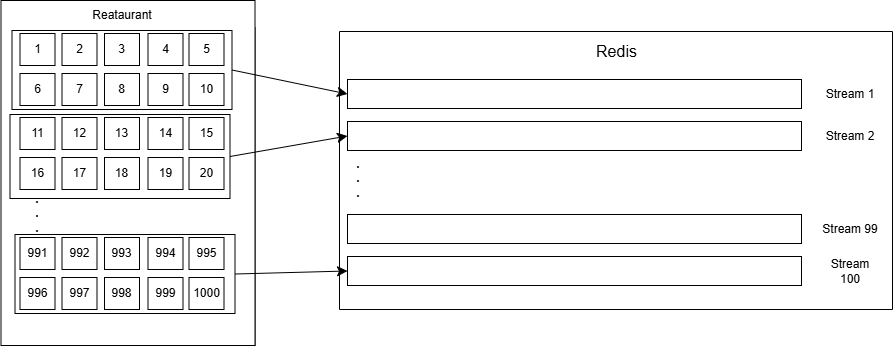
Restaurant 테이블의 row 수와 Stream 수를 1:1로 만들려 했다.각 Restaurant 예약에 대한 경합을 완전히 분리하기 위함예) 완전히 분리 시 1변 Restaurant에 요청이 몰릴 경우에도 2, 3, 4, 5번 Restaurant에 대한 예약은