
0. 들어가며..
최근 취업을 하게 되면서 '업무 자동화'라는 용어를 더 자주 접하게 되었다. 요 몇년 간 프로그래밍을 공부하고, 업무 자동화에 대해 얼핏 들어는 보았지만 실제로 이를 어떻게 적용해야 하는지는 전혀 감을 잡고 있지 못했다.
그러던 중, 긴 설 연휴를 이용하여 codeit의 '웹 자동화 시작하기' 토픽을 수강하며 웹에서 데이터를 자동으로 수집하고, 엑셀로 변환하는 등의 작업을 간단한 코드 몇 줄로 자동화하는 방법을 배우게 되었다!
1. 웹 스크래이핑의 기초
웹 스크래이핑(Web Scraping)이란, 웹사이트에서 자동으로 데이터를 추출하는 기술을 의미한다. 이는 웹 페이지의 HTML 코드나 DOM(Document Object Model) 구조를 분석하여 필요한 정보를 수집하는 과정으로, 주로 파이썬과 같은 프로그래밍 언어와 BeautifulSoup, Selenium, Scrapy 같은 라이브러리나 도구를 사용하여 수행된다. 이번에는 BeautifulSoup 을 이용해서 웹 스크래이핑을 해보겠다!
requests
requests 라이브러리는 Python에서 HTTP 요청을 보내는 데 사용된다. 이 스크립트에서는 GET 요청을 사용하여 웹 페이지의 HTML 콘텐츠를 가져온다.
import requests
response = requests.get('http://quotes.toscrape.com/')
html_content = response.text여기서 response.text는 서버의 응답을 텍스트 형식으로 반환한다.
BeautifulSoup
Beautiful Soup 라이브러리는 웹 페이지로부터 데이터를 추출하기 위해 사용되는 파이썬 라이브러리이다. 웹 스크래핑을 수행할 때, HTML과 XML 파일에서 데이터를 쉽게 검색하고 구조적으로 접근할 수 있게 해준다.
라이브러리 가져오기 및 객체 초기화
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
여기서 BeautifulSoup는 bs4 패키지 내부에 정의되어 있다. bs4는 Beautiful Soup 버전 4를 가리키며, 이는 현재 사용 가능한 가장 최신 버전이다. BeautifulSoup 클래스를 사용해 HTML 문서를 파싱하고 조작한다.
html.parser는 HTML 내용을 분석하고 구조화하는 데 사용되는 내장 파이썬 라이브러리로, 파서(parser)는 문서의 구조를 해석하고 필요한 데이터를 추출하는데 도움을 준다..
태그 선택 및 추출 (select)
Beautiful Soup는 .select()와 .select_one() 메소드를 사용하여 CSS 선택자를 활용한 태그 선택이 가능하다.
- select() 메소드
elements = soup.select("div.some-class") # 모든 일치하는 태그를 리스트로 반환
.select()는 주어진 CSS 선택자와 일치하는 모든 요소를 리스트 형태로 반환한다. 이때, 요소가 없으면 빈 리스트를 반환한다.
- select_one() 메소드
element = soup.select_one("#unique-id") # 첫 번째 일치하는 태그 반환.select_one()은 CSS 선택자와 일치하는 첫 번째 요소만 반환한다. 일치하는 요소가 없으면 None을 반환한다.
태그에서 텍스트 추출하기
태그의 텍스트 콘텐츠를 추출하는 방법은 다음과 같다.
- .get_text()
text = element.get_text(separator=' ', strip=True).get_text() 메소드는 모든 자식 텍스트를 하나의 문자열로 결합하여 반환한다. separator 인자를 사용하면 텍스트 항목 사이에 특정 문자를 삽입할 수 있으며, strip=True는 문자열 양쪽의 공백을 제거한다.
- .strings와 .stripped_strings
texts = list(element.strings) # 모든 텍스트 조각을 리스트로 반환
cleaned_texts = list(element.stripped_strings) # 공백 제거 후 텍스트 조각 반환
.strings 속성은 태그 내의 모든 텍스트 조각을 생성기로 반환한다. .stripped_strings는 각 텍스트 조각의 양쪽 공백을 제거한 값을 반환한다. 개인적으로 정말 유용하게 썼던 .stripped_strings
속성 추출
태그의 속성을 가져오는 방법은 다음과 같다.
- 속성 접근하기
attribute_value = element['href'] # 'href' 속성의 값을 가져옴
속성 값은 딕셔너리처럼 접근하여 추출할 수 있다.
- 모든 속성 보기
attributes = element.attrs # 태그의 모든 속성을 딕셔너리로 반환
.attrs 속성은 해당 태그의 모든 속성을 딕셔너리 형태로 반환한다, 이를 통해 속성 이름과 값을 쉽게 조회할 수 있다.
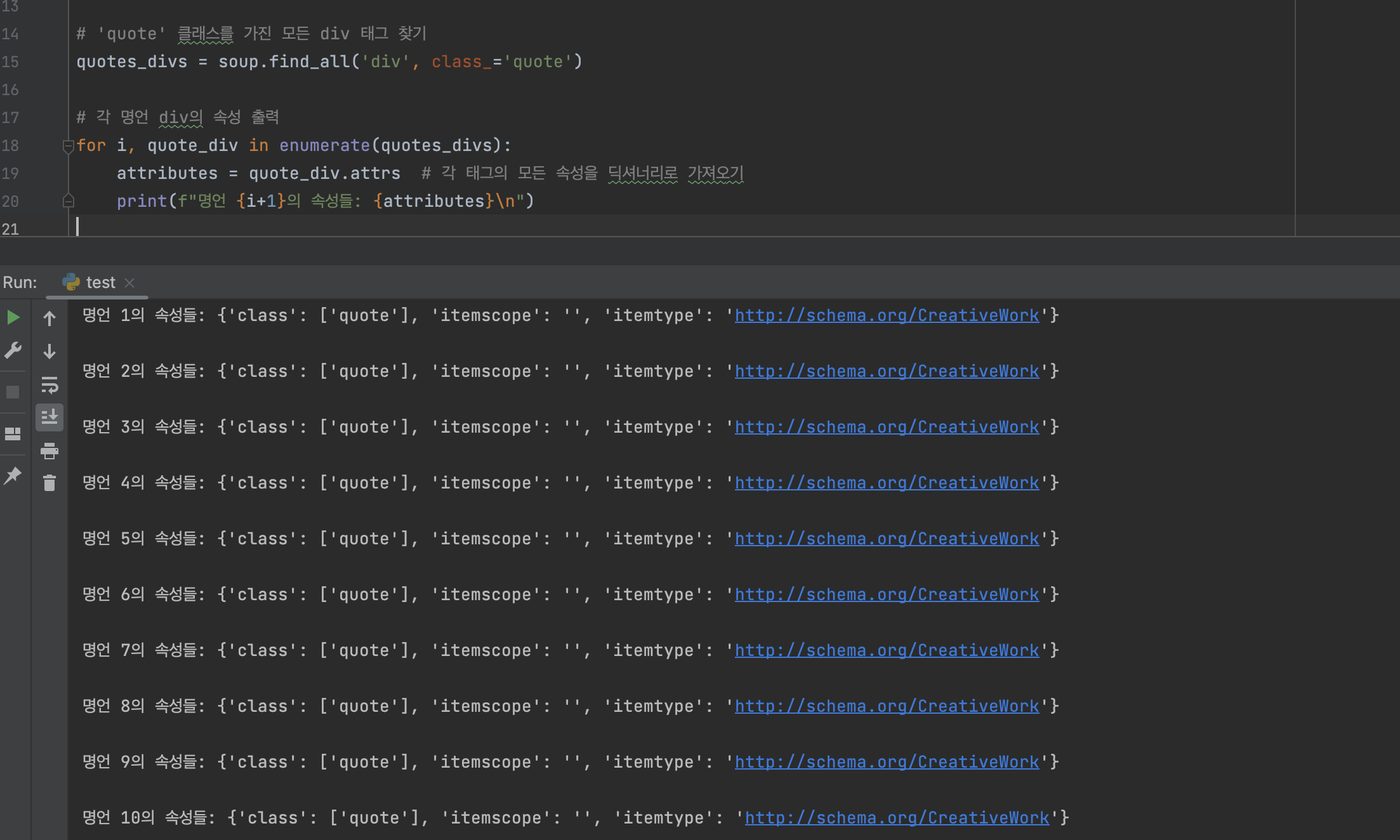
위는 실제 .attrs 속성을 이용하여 해당 태그의 모든 속성을 딕셔너리 형태로 추출해보았다. 이 방식을 통해, HTML 요소의 전체 속성을 파악할 때 매우 좋다. 또한, 딕셔너리 형태로 속성을 추출함으로써, 사용자는 필요한 정보만을 선별적으로 활용할 수 있고, 데이터의 처리 및 분석이 용이해진다.
2. 활용해보기 (유치원 구인구직 사이트 만들기)
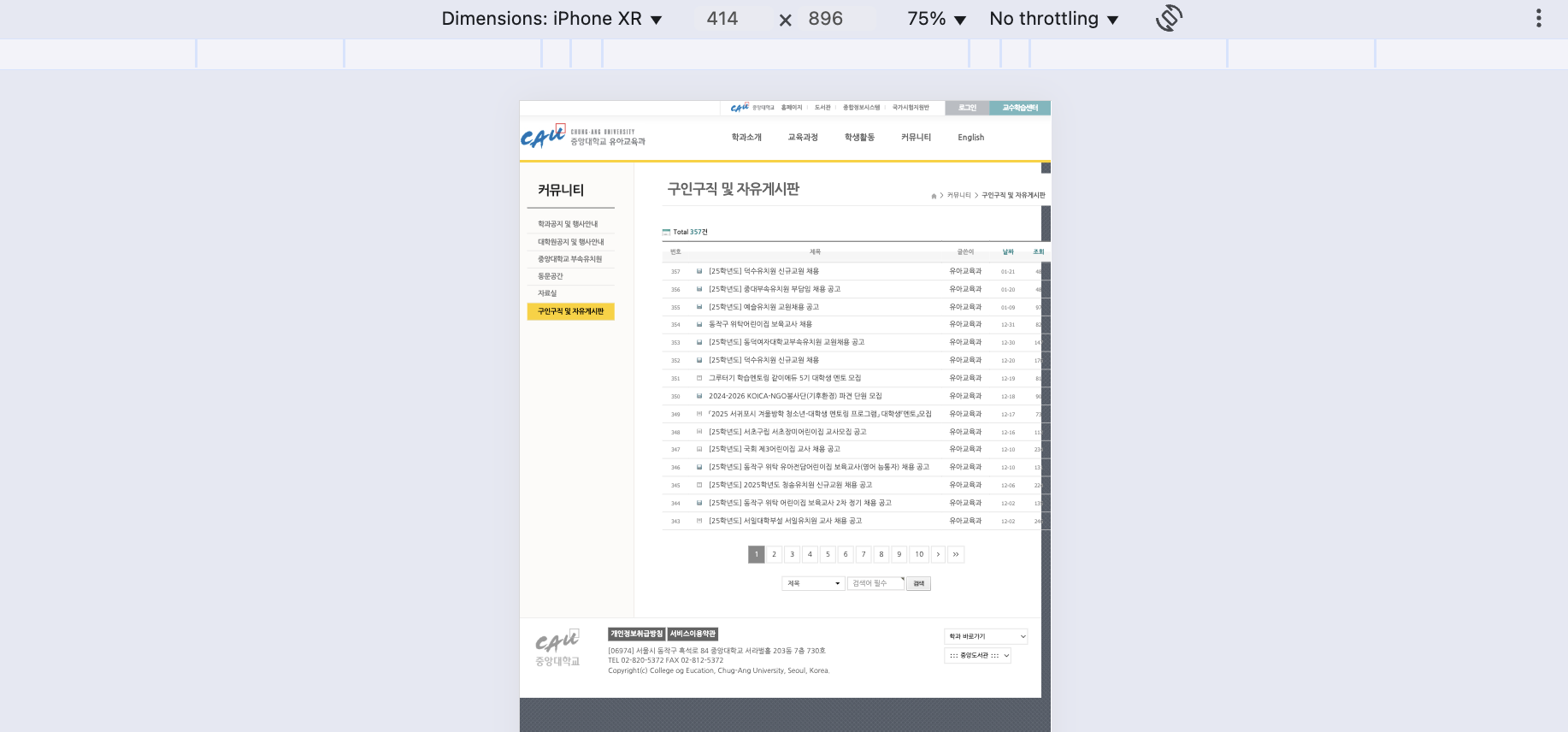
이제 이러한 웹스크래이핑 기술을 이용해서 모바일 지원이 안되는 이 사이트에서 데이터만 가져와서 더 가독성 있는 사이트로 바꿔보겠다.
from bs4 import BeautifulSoup
import requests
# URL 설정
url = "https://cauece.cau.ac.kr/bbs/board.php?bo_table=s0405"
# URL로부터 HTML 페이지 가져오기
response = requests.get(url)
response.encoding = 'utf-8' # 인코딩 설정 (필요한 경우)
# HTML 페이지를 BeautifulSoup 객체로 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 채용공고와 날짜 데이터 추출
job_postings = []
# 'tr' 태그를 순회하며 각 게시글의 제목과 날짜 추출
for row in soup.find_all('tr'):
title_cell = row.find('td', class_='fz_subject')
date_cell = next((td for td in row.find_all('td', class_='td_num') if '-' in td.text), None)
if title_cell and date_cell:
title = title_cell.text.strip().replace("파일첨부", "").replace("텍스트", "")
date = date_cell.text.strip()
job_postings.append({'title': title, 'date': date})
# 추출된 채용공고와 날짜 출력
for job in job_postings:
print(f"Title: {job['title']} - Date: {job['date']}")
내부 코드를 까보니 class로 명확하게 date에 대한 정보를 분리해놓고 있지 않아서 그냥 -를 포함시키면 date로 인식하게 구현했다. 또한 제목에 불필요한 [파일첨부]나 [텍스트] 와 같은 워딩은 제외시키도록 replace 메서드를 사용하였다.
해당 파일을 실행시키면 아래와 같은 결과가 나온다.
Title:
[25학년도] 덕수유치원 신규교원 채용 - Date: 01-21
Title:
[25학년도] 중대부속유치원 부담임 채용 공고 - Date: 01-20
Title:
[25학년도] 예슬유치원 교원채용 공고 - Date: 01-09
Title:
동작구 위탁어린이집 보육교사 채용 - Date: 12-31
Title:
[25학년도] 동덕여자대학교부속유치원 교원채용 공고 - Date: 12-30
Title:
[25학년도] 덕수유치원 신규교원 채용 - Date: 12-20
Title:
그루터기 학습멘토링 같이에듀 5기 대학생 멘토 모집 - Date: 12-19
Title:
2024-2026 KOICA-NGO봉사단(기후환경) 파견 단원 모집 - Date: 12-18
Title:
「2025 서귀포시 겨울방학 청소년-대학생 멘토링 프로그램」 대학생『멘토』모집 - Date: 12-17
Title:
[25학년도] 서초구립 서초장미어린이집 교사모집 공고 - Date: 12-16
Title:
[25학년도] 국회 제3어린이집 교사 채용 공고 - Date: 12-10이런 결과를 firestore에 저장하여 리액트 코드에 적용하면
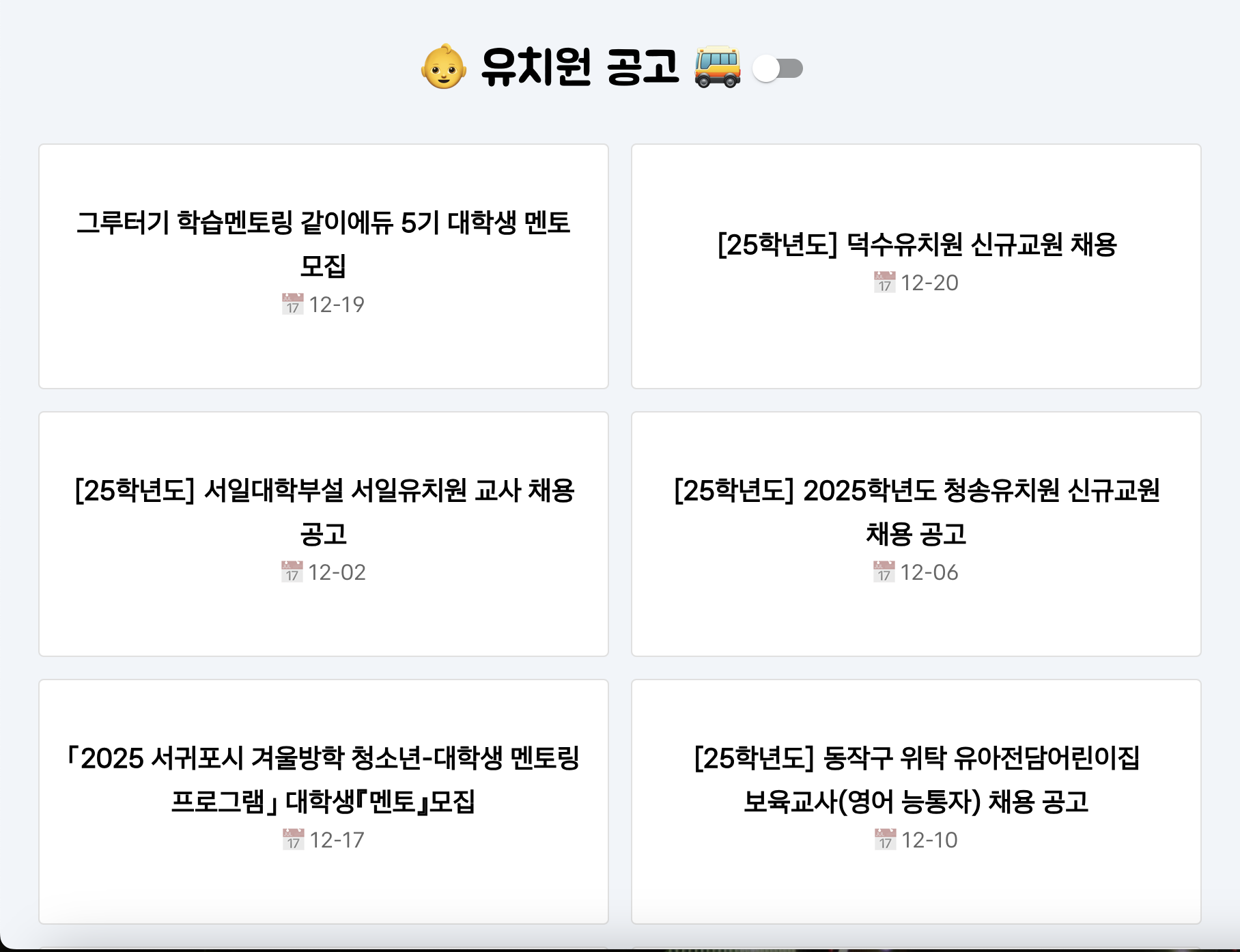
다음과 같은 화면을 얻을 수 있다.
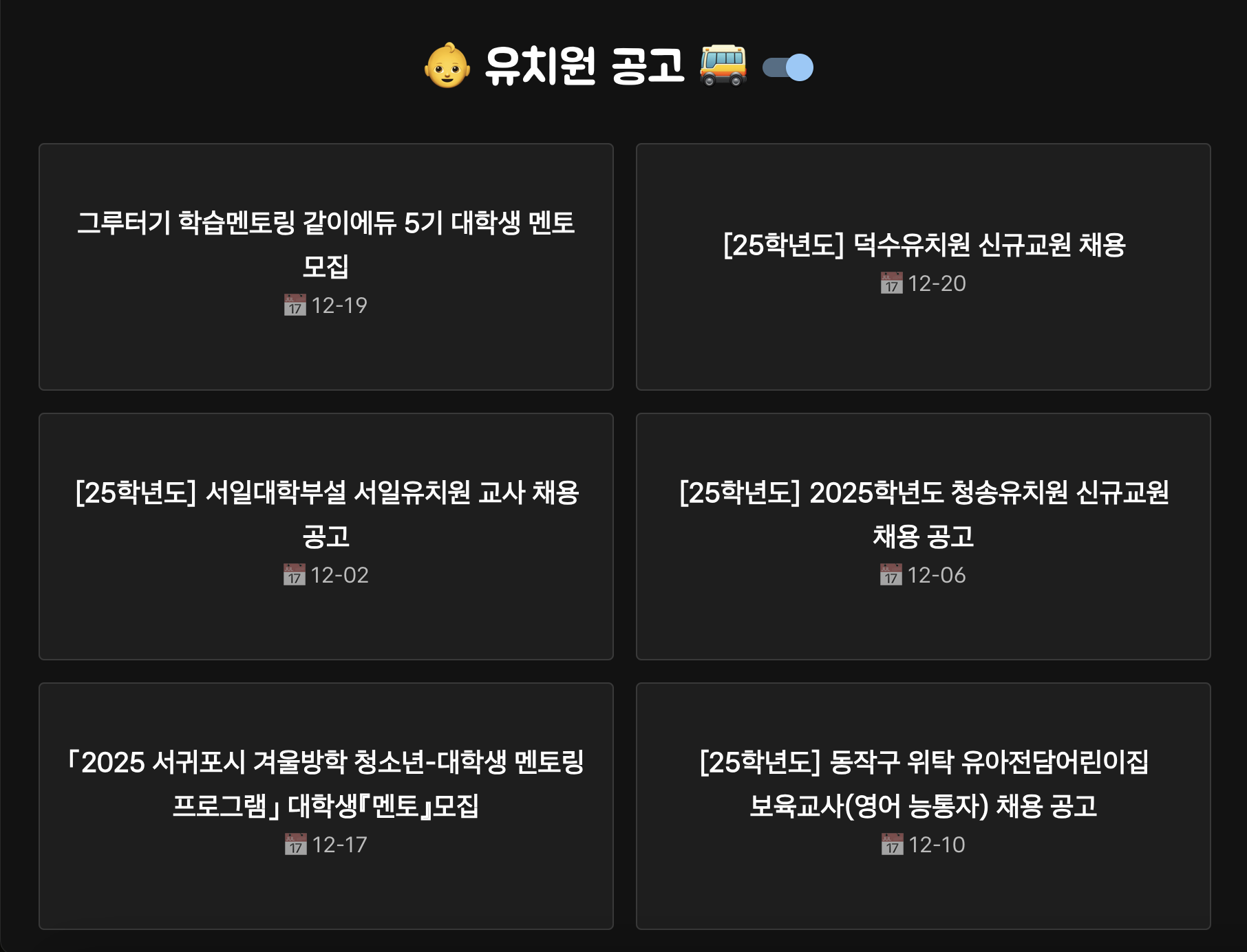
MUI를 쓰면 다크모드도 뚝딱이다 🔨
학과에서는 지원 안해주는 모바일도 적용했다 🫡
나의 최애 조합 (Vite + firebase)로도 배포 완료!
사이트 가기 👉 https://kinderplanet-e2b15.web.app/
3. 마무리
이번 글을 통해 웹 자동화 시작하기 강의를 듣고 beautifulSoup를 이용하여 학과의 공고 정보를 중심으로 웹 스크래이핑을 구현했다. 하지만 그저 한가지 사이트에서 정보를 가져오는 것은 beautifulSoup를 이용하는 의미가 없다고 생각해 앞으로는 다른 학교들의 공고 정보도 끌어와서 서비스의 범위를 확장할 계획이다. 또한, Python을 이용해 최신화된 정보를 자동으로 업데이트할 수 있도록 궁리해봐야겠다.
또한, 각 학교마다 공고 형식이 다를 수 있기 때문에, 학교별로 알맞은 공고 정보를 추출할 수 있도록 코드를 작성해야 될 것 같다. 이렇게 다양한 형식의 공고 정보를 처리한 후, 실제 예비 유아교사들이 유용하게 사용할 수 있는 사이트로 발전시킬 계획이다. 그렇다, 사이드프로젝트 병이 또 도진 것이다. 다음 글부터는 이러한 프로젝트 과정을 세세하게 담아야지 😋

그래도 업무 자동화란 무엇인지 감도 못잡고 있다가 갑자기 프로젝트로까지 확장하게 되다니.. 오랜만에 웹 개발 기초와 파이썬을 복습하고 이 지식들을 융합하여 더 고차원적인, 새로운 프로덕트를 만들어낼 수 있는 시간이었다!
4. Bibliography
