
0. 들어가며..
사실 첫 언어가 파이썬이다보니 프런트엔드 개발자임에도 불구하고 자바스크립트가 아닌 파이썬으로 코테 준비를 강행했는데 최근에 서류 넣은 회사에서 받은 충격적인 이메일.

프런트엔드 직무에는 자바스크립트만 보는 회사가 있다는 것은 얼핏 들었지만 한귀로 듣고 한귀로 흘러버렸다. 그래도 어떻게든 풀어보고 싶어서 기초문제부터 코드트리에서 연습했지만 하루 아랍어 공부한다고 바로 아랍어로 너구리는 최고의 동물임을 피력할 수 없는 것처럼 IT 회사의 코딩테스트를 통과하는 것은 불가능한 일이었다.
어떻게 프런트엔드 개발자를 지원하면서 자바스크립트를 이렇게까지 등한시했을까 싶은 마음에 시험을 보는 내내 정말 큰 반성을 하게 되었고.. 먼저 매맞는게 감사한 이 상반기에 큰 전환점이 된 것 같다.
그래도 나에게 익숙했던 파이썬으로 미리 코테 찍먹했던 것을 자바스크립트에 비교하면서 공부에 써먹는 방식으로 소화시켜보고 싶어졌다. 현재 파이썬에서 자바스크립트로 코테 언어를 바꾸는 과정에서 코테의 근본인 배열부터 두 언어가 많이 다르다는 생각이 들었다.
정확히 어떤 것이 다른지 사용 빈도가 높은 배열에 대해 자료구조의 배열, 파이썬의 배열, 자바스크립트의 배열의 비교를 통해서 알아보자.
1. 자료구조의 배열 (Array)
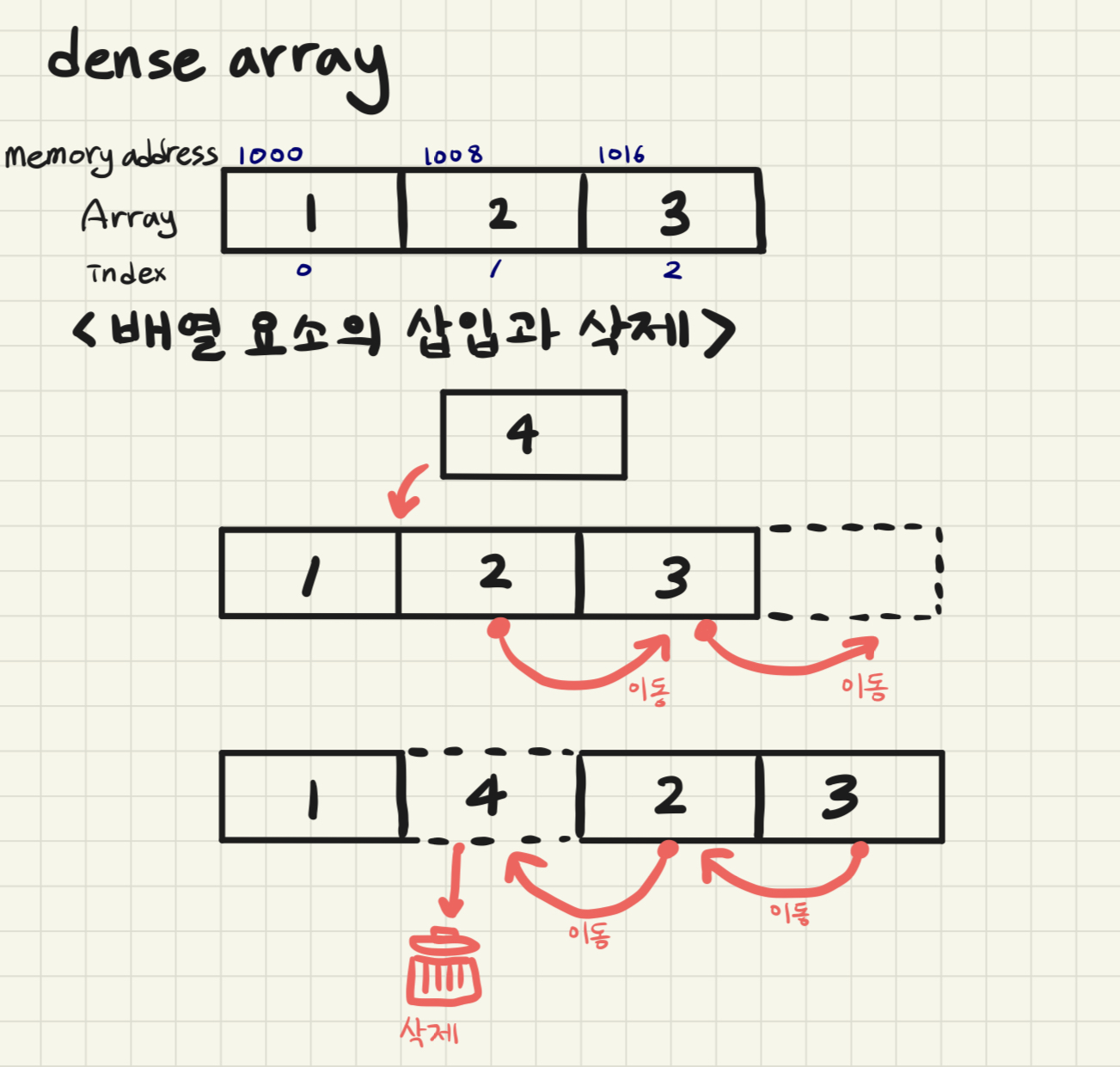
배열 Array : 연관된 data를 메모리 상에 연속적이며 순차적으로(연속적으로) 미리 할당된 크기만큼 저장된 자료 구조. compile 단계에서 memory allocation이 일어난다. 여기서 핵심은 고정된 저장 공간과 순차적인 데이터 저장이다.
이러한 배열을 밀집 배열(dense array)이라 한다.
장점 )
- lookup과 append가 빠르다. → 조회를 자주해야하는 작업에 유리함
단점 )
- fixed-size 특성상 선언 시에 Array의 크기를 미리 정해야 함. → 메모리 낭비나 추가적인 overhead 발생,
- 요소를 추가하거나 삭제할 때 배열의 요소를 연속적으로 유지하기 위해 요소를 이동시킴. → 시간 복잡도 증가
그렇다면 미리 예상한 것보다 더 많은 수의 data가 들어오게 되어 Array의 size를 넘어서게 되는 경우 어떻게 해결할 수 있을까?
답은 바로 동적으로 배열의 크기를 조절하는 Dynamic Array와 데이터가 추가될 때마다 메모리 공간을 할당받는 Linked list에 있다. 파이썬의 배열 구현 방식과 함께 살펴보자.
2. 파이썬으로 배열 구현하기
Dynamic Array
파이썬에서는 리스트(list) 타입이 배열 기능을 제공하며 기본적으로 동적 배열 (Dynamic Array) 로 구현되어 있다.
Dynamic Array란?
dynamic_array = []
# 요소 추가
dynamic_array.append(1)
dynamic_array.append(2)
dynamic_array.append(3)
# 요소 삭제
dynamic_array.pop()동적 배열은 complie time에 크기가 정해지는 static array와 달리, 배열의 크기를 run-time에 조정할 수 있는 배열이다. static array는 선언 시에 size를 선언하여 설정된 size보다 많은 갯수의 data를 추가할 수 없다. 이에 반해, 동적 배열은 저장 공간이 가득 차게 되면 유동적으로 size를 조절하여 data를 저장하는 자료구조이다. 파이썬에서는 사용자가 리스트의 크기를 신경 쓸 필요없이 요소를 append하거나 delete를 할 수 있다는 장점이 있다.
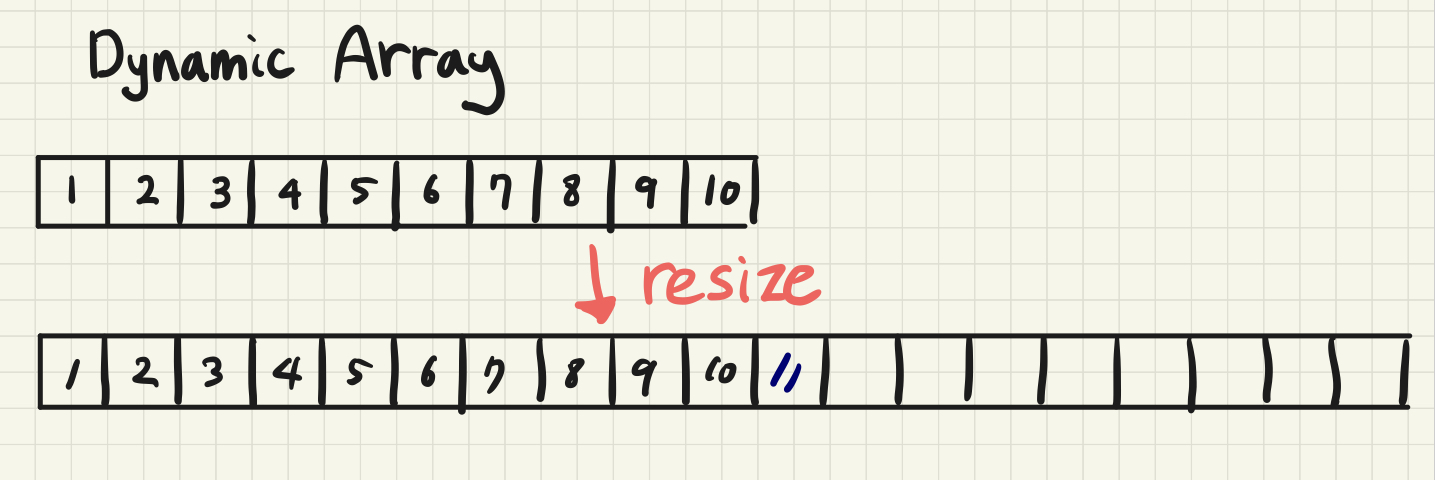
static Array의 한계점을 보안하고자 만들어진 동적 배열은 data가 기존에 할당된 memory를 초과하게 되면, size를 늘린 배열을 선언하고 그곳으로 모든 데이터를 옮김으로써 늘어난 크기의 size를 가진 배열이 된다. 이를 resize라고 일컫는다. resize의 대표적인 방법으로는 doubling이 있다.
- Doubling O(1)의 시간복잡도로 데이터를 추가하다가 메모리를 초과하게 되면 기존 배열의 size보다 2배 큰 배열을 선언하고 n개의 데이터를 일일이 O(n)의 시간 복잡도로 옮기는 방법이다.
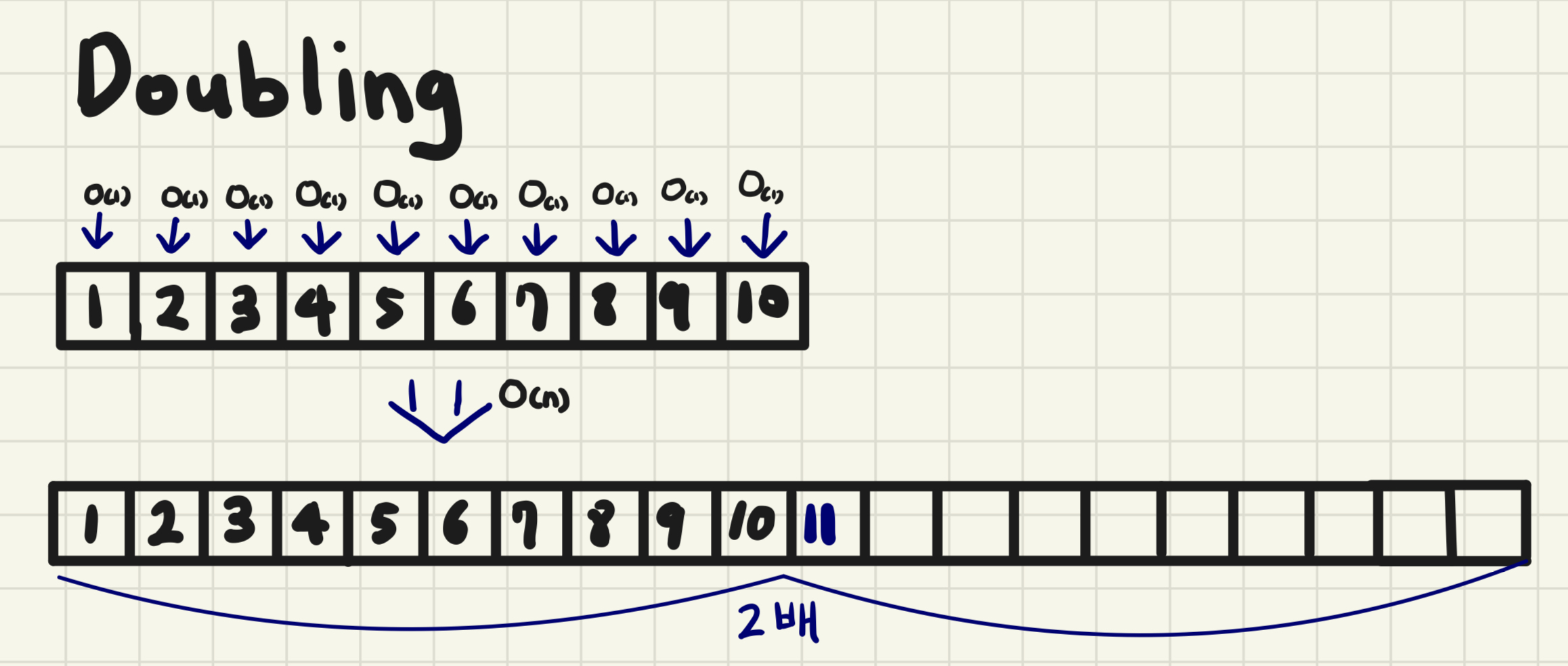
- Amortized time complexity 분할상환 시간복잡도 : append의 전체적인 시간복잡도는? 일반적으로 Dynamic array에 데이터를 추가할때마다 O(1)의 시간이 걸리게 되지만 resize를 하는 과정에서는 일일이 데이터를 모두 옮겨야 하기 때문에 이때 O(n)의 시간 복잡도를 가지게 된다. (resize O(n)) 이때 append의 전체적인 시간 복잡도는 O(1)이고, 더 정확히 말하자면 amortized O(1)이다. 이따금씩 발생하는 resizing하는 시간을 (O(n)), 통상적으로 발생하는 O(1)의 작업들이 분담해서 나눠가짐으로써 전체적으로 O(1)의 시간이 걸린다.
장점 )
- 데이터 접근과 할당이 O(1)로 빠른 속도를 가짐. 특히 Dynamic Array의 맨 뒤에 데이터를 추가하거나 삭제하는 것이 상대적으로 빠르다
단점 )
- 맨 끝이 아닌 data를 삽입하거나 삭제할 때는 느리다(O(n)). 메모리 상에서 데이터들이 연속적으로 저장되어 있기 때문에 data들을 모두 한칸씩 shift 해야 하기 때문.
- resizing 과정에서 예상치 못하게 낮은 performance 발생.
- 필요한 것 이상의 memory 공간을 할당받기 때문에 낭비되는 메모리 공간 발생.
그렇다면 또다른 배열 구현 방법인 Linked List란 무엇일까?
Linked List : 데이터 값과 다음 Node의 address를 저장한 Node라는 구조체로 이루어진 자료구조.
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
else:
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def display(self):
elements = []
current = self.head
while current:
elements.append(current.data)
current = current.next
print(elements)
Linked list는 메모리상에서는 비연속적으로 저장이 되지만 (논리적 불연속성) Node가 next Node의 주소를 가리킴으로서(포인터) 논리적인 연속성을 가진 자료구조이다.
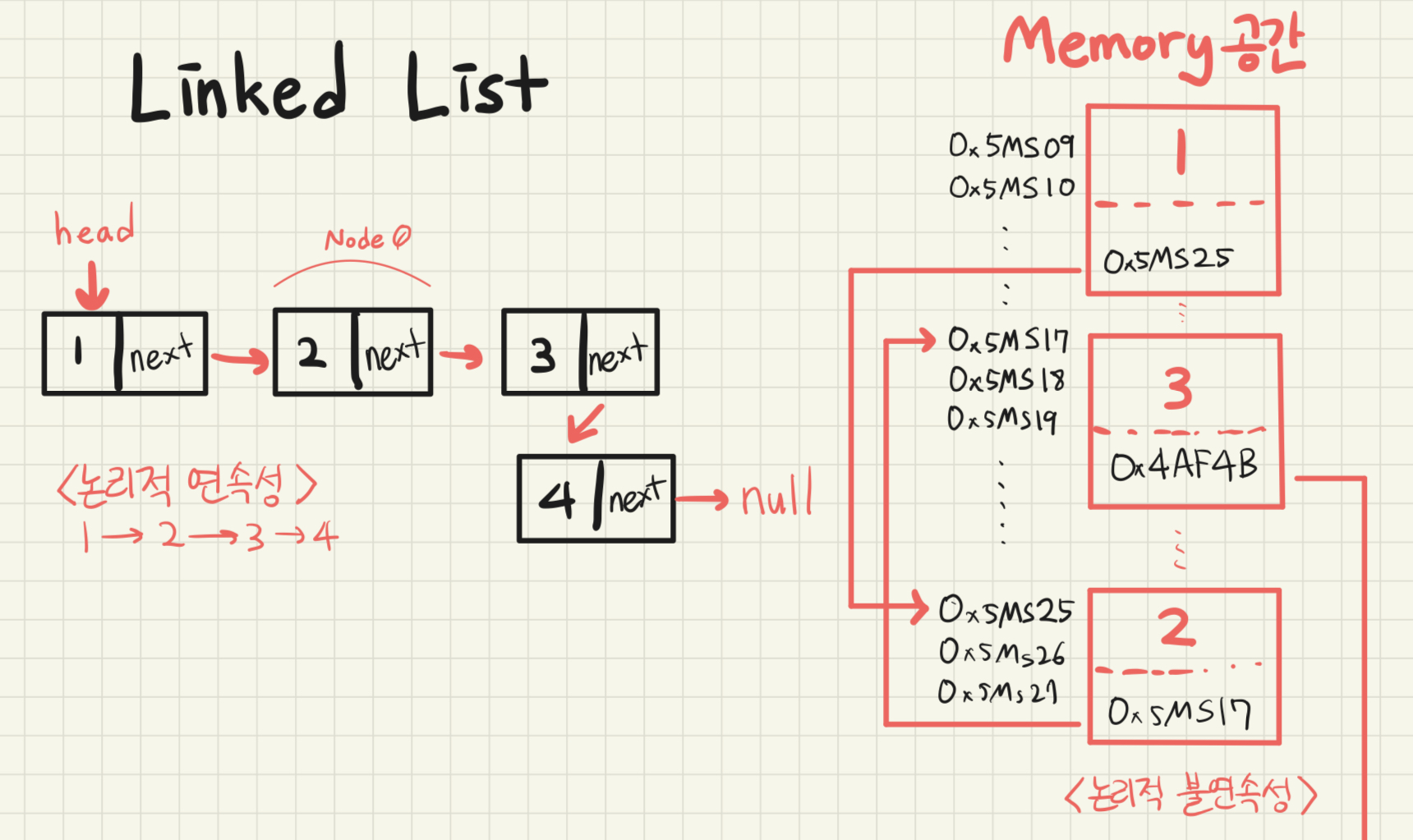
compile 단계에서 memory allocation이 일어나는 array와 달리 Linked list는 run-time 단계에 memory allocation이 일어난다. 따라서 런타임 단계에서 새로운 node가 추가될 때마다 memory allocation이 일어난다.
Linked List의 대표적인 특징으로는 Array보다 삽입/삭제가 빠른 속도로 가능하다는 것이다. Array의 경우 중간에 데이터를 삽입하거나 삭제하려고 할 경우 해당 인덱스의 뒤에 있는 모든 원소들을 shift를 하며 O(n)의 시간 복잡도를 갖게 된다. 하지만 Linked list의 경우에는 next address가 가리키는 주소값만 변경하면 되기 때문에 O(1)의 시간 복잡도로 삽입이나 삭제가 가능하다.
즉, 저장할 데이터 개수가 불확실하고 삽입, 삭제가 잦은 경우, 조회 작업을 별로 하지 않을 때에 Linked list, 파이썬의 deque을 이용하는 것이 유리하다.
deque와 연결 리스트의 유사성:
from collections import deque
# deque 생성
linked_list = deque()
# 요소 추가 - 리스트의 끝에 추가
linked_list.append(1)
linked_list.append(2)
linked_list.append(3)
# 요소 추가 - 리스트의 시작에 추가
linked_list.appendleft(0)
# 요소 삭제 - 리스트의 끝 요소 삭제
linked_list.pop()
# 요소 삭제 - 리스트의 시작 요소 삭제
linked_list.popleft()
# 리스트 출력
print(list(linked_list))- 양방향 액세스:
deque는 양쪽 끝에서 요소를 추가하거나 제거할 수 있다. 이는 연결 리스트에서 노드를 양쪽 끝에 추가하거나 제거하는 것과 유사하다. - 동적 크기 조정: 둘 다 필요에 따라 크기가 조정된다. 연결 리스트는 노드가 추가되거나 제거될 때 마다 자연스럽게 크기가 조절되며,
deque역시 유사한 방식으로 작동한다. - 메모리 사용: 연결 리스트와 마찬가지로,
deque는 사용되지 않는 메모리를 최소화하며, 요소들이 메모리상에서 연속적이지 않을 수 있다.
장점 )
- 메모리 할당이 런타임 중에 일어나기 때문에 런타임 중에도 사이즈를 늘리고 줄일 수 있음
- 필요한 만큼만 memory allocation을 하여 메모리 낭비가 없다.
단점 )
- 포인터 사용으로 인한 배열 요소 저장 공간의 증대
- 특정 index 조회에 시간이 많이 듦
3. 자바스크립트의 배열
자바스크립트의 배열은 매우 유연하고 강력한 내장 데이터 타입으로, 다양한 메서드를 통해 쉽게 배열을 조작할 수 있다.
// 배열 생성
let array = [1, 2, 3, 4, 5];
// 배열에 요소 추가
array.push(6); // 배열의 끝에 추가
array.unshift(0); // 배열의 시작에 추가
console.log(array); // [0, 1, 2, 3, 4, 5, 6]
// 배열에서 요소 제거
array.pop(); // 배열의 끝에서 제거
array.shift(); // 배열의 시작에서 제거
console.log(array); // [1, 2, 3, 4, 5]
// 배열 요소 접근
console.log(array[2]); // 3
// 배열 길이
console.log(array.length); // 5
// 배열 순회
array.forEach((element, index) => {
console.log(`Element at index ${index}: ${element}`);
});
// 배열 슬라이싱
let slicedArray = array.slice(1, 3);
console.log(slicedArray); // [2, 10]
// 배열 내 요소 수정
array[2] = 10;
console.log(array); // [1, 2, 10, 4, 5]
자바스크립트의 배열은 자료구조의 배열과 같은가?
결론부터 말하자면 자바스크립트의 배열은 자료구조에서 말하는 배열과 다르다.
앞서 언급했듯이 자료구조에서 일컫는 배열은 동일한 크기의 메모리 공간이 빈틈없이 연속적으로 나열된 자료구조를 의미한다. 이러한 배열은 밀집 배열(dense array)로 배열의 요소는 하나의 데이터 타입으로 통일되어 있으며 서로 연속적으로 인접해 있다.
그러나 자바스크립트의 배열은 배열의 요소를 위한 각각의 메모리 공간이 동일한 크기를 갖지 않을 수 있으며, 연속적으로 이어져 있지 않아도 된다. 이처럼 배열의 요소가 연속적으로 이어져 있지 않는 배열을 희소 배열(sparse array)이라 한다.
즉, 자바스크립트의 배열인 희소배열은 일반적인 의미의 배열이 아니며 자료구조의 배열을 흉내 낸 특수한 객체이다.
console.log(Object.getOwnPropertyDescriptors([1,2,3]));
/*
{
'0' : {value: 1, writable: true, enumerable: true, configurable: true}
'1' : {value: 2, writable: true, enumerable: true, configurable: true}
'2' : {value: 3, writable: true, enumerable: true, configurable: true}
length : {value: 3, writable: true, enumerable: false, configurable: false}
}
*/이처럼 자바스크립트 배열은 인덱스를 나타내는 문자열을 (’0’ , ‘1’ , ’2’ ) 프로퍼티 키로 가지며, length프로퍼티를 갖는 특수한 객체다. 자바스크립트의 배열의 요소도 일반적인 배열의 요소와 달리 사실 프로퍼티 값이다.
자바스크립트에서 사용할 수 있는 모든 값은 객체의 프로퍼티 값이 될 수 있다. 다시 말해 어떤 값이라도 자바스크립트의 배열의 요소가 될 수 있다. (문자열, 숫자, 불리언, undefined, NaN, function(){} 등)
const arr = [
'string',
10,
true,
null,
undefined,
NaN,
Infinity,
[ ],
{ },
function() {}
];장점 )
- 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠른 성능을 기대할 수 있다.
- 다양한 데이터 타입의 요소를 포함할 수 있다.
- 동적으로 크기 조정이 가능하여, 런타임 중에 배열의 크기를 변경할 수 있다.
단점 )
- 자바스크립트의 배열은 구조상 밀집 배열보다 인덱스로 요소에 접근하는 데에 더 많은 시간이 걸린다.
4. 정리하면..
따라서 자바스크립트의 배열은 정적 배열, 동적 배열, 연결 리스트 중 그 어떤 것도 아닌 특수한 형태의 객체이다.
배열의 각 요소는 키-값 쌍의 형태로 저장되며, 이 키는 배열의 인덱스를 나타낸다. 이는 배열이 내부적으로 해시 테이블과 유사한 방식으로 구현될 수 있음을 의미한다..고 모던 자바스크립트에 나와있지만 아직 해시 테이블에 관한 개념 정립도 제대로 되지 않아서 다음 글에서 제대로 다뤄보고 싶다.
또한 직접 사용해보니 자바스크립트는 정말 높은 유연성을 가지고 있어, 기능 구현 자체는 파이썬보다 쉽다고 느껴지지만 확실히 속도적인 부분에서 더 느리거나 컴파일 에러가 발생하지 않아서 디버깅이 어렵다는 단점도 존재했다. 그 이유를 자료구조의 분석과 비교를 통해서 알 수 있어서 유익한 시간이었다.
📚Bibliography
- 모던 자바스크립트 modern javascript(https://ko.javascript.info/)
- 파이썬 공식 문서 (https://docs.python.org/ko/3/library/collections.html#collections.deque)
- 10분 테코톡🐻 중간곰의 선형 자료구조 (https://www.youtube.com/watch?v=xnURecIJk4g)
- 기출로 대비하는 CS 전공면접 (https://www.inflearn.com/course/%EA%B0%9C%EB%B0%9C%EC%9E%90-%EC%A0%84%EA%B3%B5%EB%A9%B4%EC%A0%91-cs-%EC%99%84%EC%A0%84%EC%A0%95%EB%B3%B5/dashboard)

8개의 댓글

희소 배열에 관해서는 처음 들어보는데 너무 흥미로워요!! 자바스크립트에서 객체의 개념은 아직도 신기하네요..
요즘 파이썬의 자료구조를 공부 중이었는데 자바스크립트와 비교하며 더 깊이 있게 이해할 수 있는 시간이었어요 ㅎㅎ

희소배열에 대해 새로 알게 되었어요 감사합니다! 인덱스로 접근하는데 오래걸리는 이유는 주소연산을 통해 해당 요소를 찾는게 아니라 연결리스트처럼 해당 인덱스까지 데이터 하나 하나씩 접근해서 찾아가는 방식인건가요?



너무 유익해요! 다음 글도 기대돼요ㅎㅎㅎ