단일 단계 인덱스
인덱스
- 순차 화일의 빠른 검색을 위해 <탐색 키, 레코드 포인터>로 관리
- 인덱스는 데이터 화일과는 별도의 화일에 저장
- 인덱스 화일은 데이터 화일의 크기에 비해 훨씬 작음
- 하나의 데이터 화일에 여러 인덱스들을 정의 가능
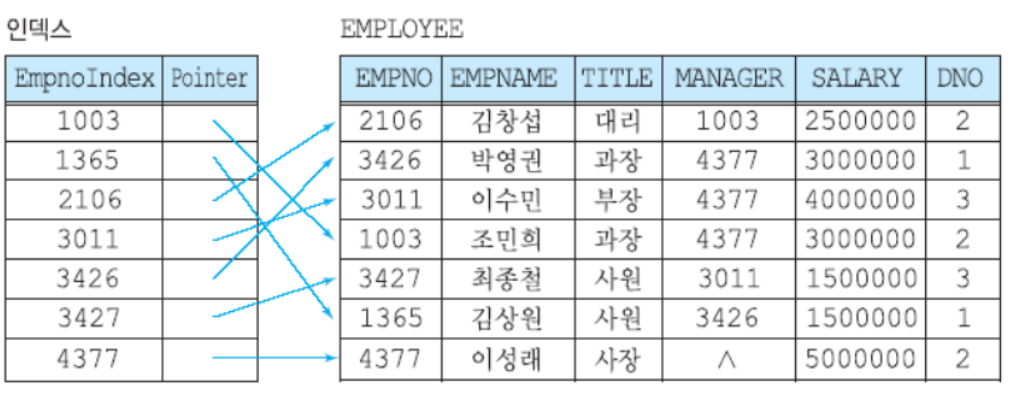
- 인덱스가 정의된 필드(애트리뷰트)를 탐색 키라고 부름
- 탐색 키는 릴레이션의 기본 키와는 다른 개념이라 값이 중복되도 됨
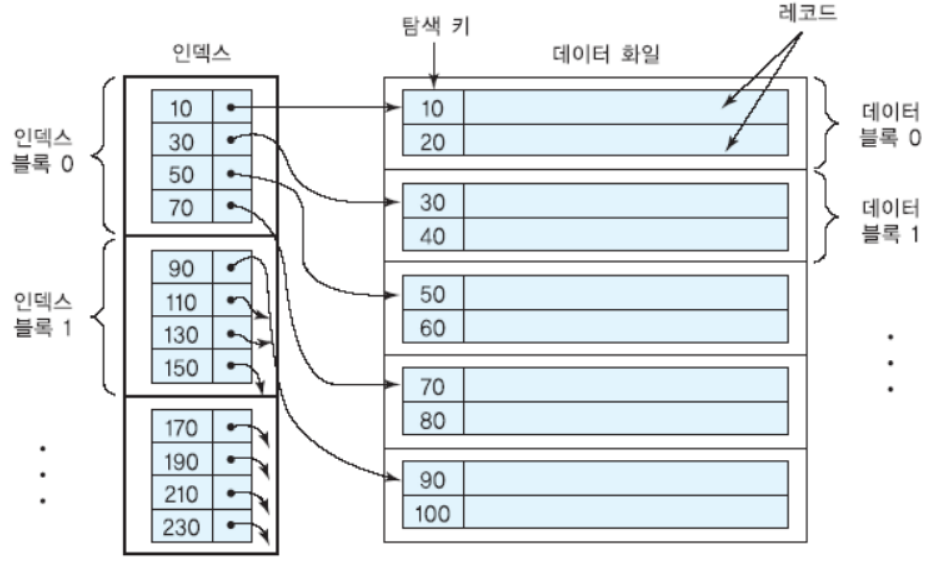
기본 인덱스
- 탐색 키가 릴레이션의 기본 키인 인덱스
- 그래서 인덱스 또한 순서되로 정의되며 중복이 없음
- 희소 인덱스로 유지됨
- 각 릴레이션마다 최대한 한 개의 기본 인덱스를 가질 수 있음
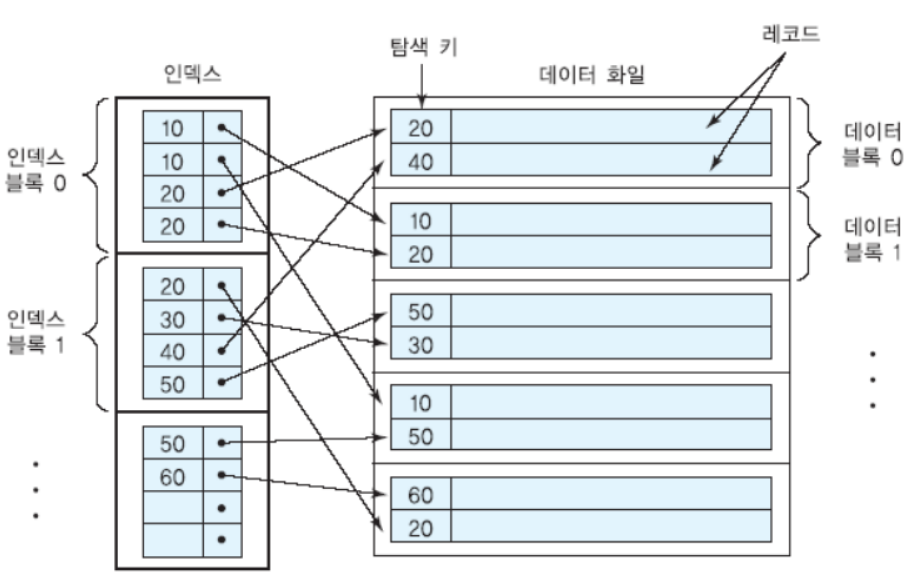
보조 인덱스
- 탐색 키가 릴레이션의 기본 키가 아닌 인덱스
- 그래서 인덱스는 비순차적이며 중복이 발생할 수 있음
- 밀집 인덱스로 유지됨
클러스터링 인덱스
- 기본 인덱스처럼 탐색 키 값에 따라 정렬된 데이터 화일에 대해 정의
- 본 인덱스와는 다르게 탐색 키 값이 데이터 화일 내에 중복 존재 가능
- 범위 질의에 유용
희소 인덱스 vs 밀집 인덱스
- 희소 인덱스가 모든 갱신과 대부분의 질의에 대해 더 효율적
- COUNT 질의 같은 애트리뷰트만 검색하는 질의의 경우 데이터 화일을 접근할 필요 없이 인덱스만 접근하기에 밀집 인덱스가 유리
- 한 화일은 1개의 희소 인덱스와 다수의 밀집 인덱스를 가질 수 있음
클러스터링 인덱스 vs 보조 인덱스
- 클러스터링 인덱스는 희소 인덱스일 경우가 많고 범위 질의에 좋음
- 보조 인덱스는 밀집 엔딕스이므로 위의 설명처럼 특정 COUNT 질의엔 유리
