현재 다니고 있는 회사에서 NextJS를 사용하고 있었기에 온보딩 기간동안 NextJS로 프로젝트를 진행하게 됐습니다.
여기서는 NextJS를 사용하면서 느낀 어려움과 헷갈렸던 점 그리고 프로젝트를 진행하면서 배운 점을 적어보려고 합니다.
1. Pre-Rendering
NextJS의 공식문서를 보면 Next는 모든 페이지를 pre-render 한다고 합니다.
이게 무슨 말인지 알아보려면 CSR과 SSR에 대해서 알아야 합니다.
CSR은 초기 페이지에 진입 시 모든 HTML, CSS, Javascript 코드를 번들링한 파일을 불러와서 Client에서 동적으로 화면을 render 시켜줍니다.
이러한 방식의 장점은 크게 아래와 같습니다.
- 새로운 페이지를 불러올 때 화면이 깜빡거리는 현상이 없기 때문에 UX에 강점을 가진 애플리케이션이 될 수 있습니다.
- 페이지를 불러올 때 초기에 한 번만 요청하면 되기 때문에 서버의 부하가 줄어듭니다.
하지만 단점 또한 존재합니다.
- 애플리케이션의 크기가 커질수록 초기 페이지를 불러오는 데 필요한 시간이 증가합니다.
❗️ 이 문제를 해결하기 위해 CSR에서는 코드 스플리팅과 같은 방식으로 각 페이지에 필요한 번들 파일만 불러오는 방식을 적용할 수 있습니다.
- 초기 페이지를 불러올 때 HTML 파일을 살펴보게 되면
<div id="root" ><div>만 나오기 때문에 검색 엔진이 크롤링할 정보가 부족하여 SEO에 불리합니다.
Next는 바로 이러한 문제를 해결하기 위해 나온 React의 Framework입니다.
✔️ How?
그렇다면 어떤 방식으로 이러한 문제들을 해결하는 것일까?
여기서 Next는 앞서 서술했던 pre-render를 통해 이 문제들을 해결합니다.
Next에서 pre-render를 하는 방식은 두 가지 형태로 나눌 수 있습니다.
2. SSG, SSR, CSR
1) SSG - getStaticProps, getStaticPaths
SSG(Static-Site-Generation)은 Build Time(yarn build)에 모든 페이지를 생성하고 생성된 HTML 파일을 CDN에 캐싱하여 요청이 있다면 해당하는 페이지를 가져와 보여주는 방식입니다.
SSG는 Build Time에 모든 페이지를 미리 생성해놓기 때문에 당연히 초기 렌더링 속도가 SSR, CSR보다 빠릅니다.
그리고 Build Time에 생성되기 때문에 공식 문서에서는 데이터가 변하지 않는 Static한 페이지에서 사용하는 것을 권장하고 있습니다.
그렇기 때문에 데이터가 동적으로 자주 바뀌게 되는 페이지는 SSR 방식으로 구현하는 것이 더 적합한 방법이 될 것입니다.
예를 들어, 게시글 목록을 보여주는 페이지가 SSG 방식으로 구현이 됐다고 가정해보겠습니다.
누군가가 새로운 게시글을 작성했다고 한다면 내가 게시글 목록을 바라볼 때는 새로운 게시글이 포함된 게시글 목록이 나타나야 합니다.
하지만 SSG로 구현된 페이지는 Build Time에 모든 HTML을 만들어 놓기 때문에 새로운 게시글이 유저에 의해 동적으로 추가가 되어도 Build Time에 생성된 페이지가 아니기 때문에 접근을 시도하면 404페이지로 이동하게 될 것입니다.
하지만 동적으로 HTML 파일을 생성하는 방법이 존재합니다.
바로 fallback 옵션을 true 로 설정하는 것입니다.
fallback: true 로 설정하게 되면 해당하는 페이지가 없다면 요청을 보내 새로운 HTML 파일을 생성하여 보여줍니다.
fallback: false: 해당하는 페이지가 없다면 404페이지로 이동fallback: true: 해당하는 페이지가 없다면 요청을 통해 새로운 HTML 파일 생성
❗️기존에는 CSR 방식으로 컴포넌트 레벨에서 데이터를 불러와서 사용했던 페이지를 SSG 방식으로 변경하니 렌더링 속도가 눈에 띄게 빨라진 것을 확인할 수 있었습니다.
CSR

SSG
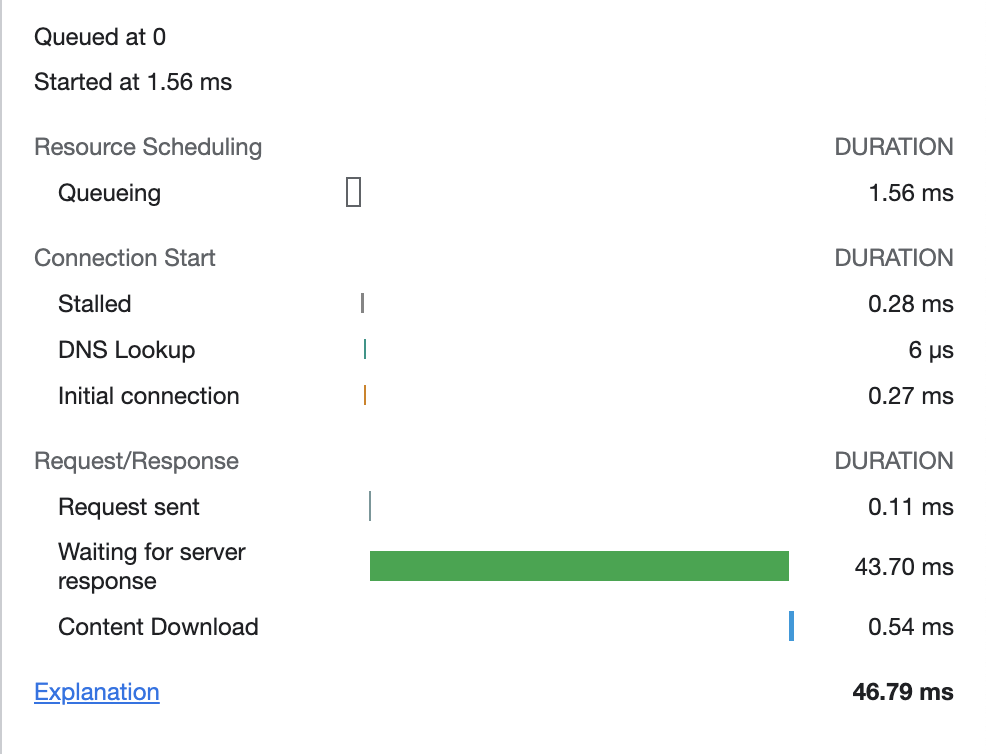

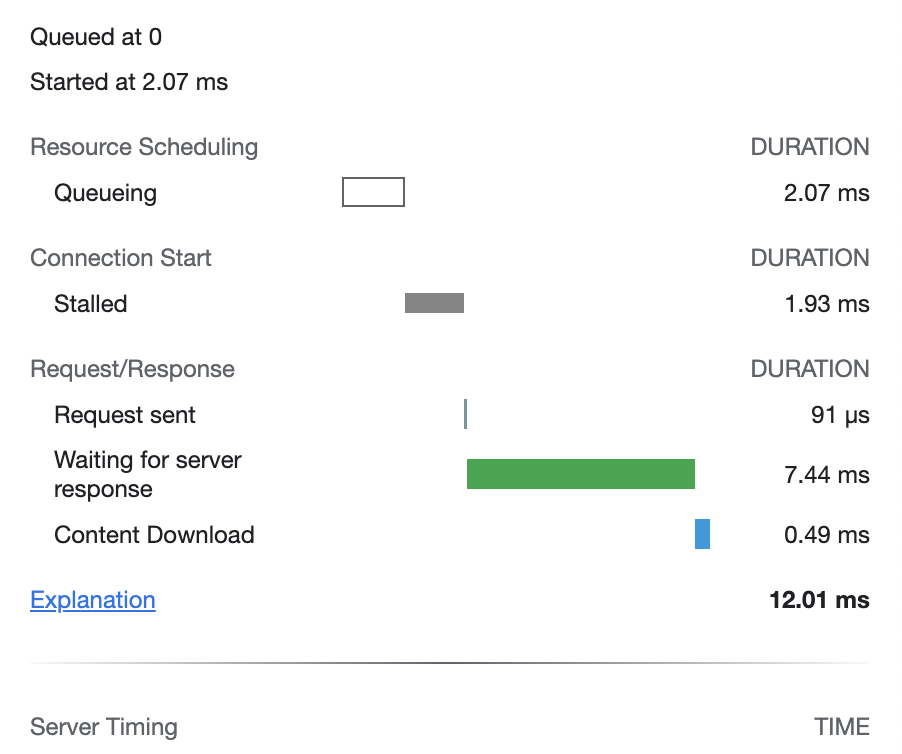
2) SSR - getServerSideProps
SSR(Server-Side-Rendering)은 각각의 요청마다 HTML 파일을 생성하는 방식입니다.
SSR을 사용하기 위해서는 Next가 제공하는 getServerSideProps 함수를 사용해야 합니다. 그리고 이 함수는 Next 서버에 의해서 매 요청마다 서버에서 실행이 됩니다.
위와 같이 매 요청마다 실행이 되기 때문에 내부 데이터가 빈번하게 변경되는 페이지에 주로 getServerSideProps 함수를 사용하게 됩니다.
getStaticProps와 비슷한 역할을 하는 것처럼 보이지만 차이점은 명확합니다.
getServerSideProps는 매 요청마다 실행이 되고 getStaticProps는 Build Time에 실행이 됩니다.
위에서 예시로 들었던 게시글 목록을 바라볼 때,
만약 getStaticProps가 아닌 getServerSideProps로 구현했다면 정상적으로 나는 다른 유저가 추가한 게시글을 바라볼 수 있게 됩니다.
3) CSR
위 두 개의 방식과 더불어 Next에서도 여전히 CSR 방식으로 페이지를 구성할 수 있습니다.
공식 문서에서 CSR 방식은 SEO가 중요하지 않거나 데이터를 pre-render할 필요가 없거나 데이터가 빈번하게 변화할 때 사용하는 것을 권장하고 있습니다.
4) 우리가 정의한 규칙
내가 NextJS를 공부하고 적용하면서 명확한 정답은 없다고 느꼈습니다.
그렇기 때문에 아래의 예와 같이 각 방식의 컨셉에 대한 이해를 바탕으로 프로젝트에 알맞은 방식을 합의하여 사용하는 것이 중요할 것 같다고 생각하게 됐습니다.
예를 들어, 아래와 같은 경우가 가능합니다.
- 랜딩 페이지는 자주 변하지 않는 페이지가 될테니까 SSG로 만들자.
- 게시글 목록 페이지는 유저에 의해 동적으로 데이터의 변화가 일어날 수 있는 페이지니까 SSR로 만들자.
- Header와 Footer는 변하지 않을테니까 SSG로 만들자.
- 마이 페이지는 SEO가 중요하지 않을테니까 CSR로 만들자.
이 프로젝트에서는 각 페이지에 사용할 방식을 아래와 같은 규칙으로 정의하여 사용하게 됐습니다.
-
SSG 방식은 모든 사용자가 같은 화면을 보고 있고 데이터의 변화(By User Interaction)이 없는 페이지(Ex. Home Page, 단순 정보 제공 페이지 등)에서 사용
-
SSR 방식은 모든 사용자가 같은 화면을 보고 있고 데이터의 변화(By User Interaction)가 빈번하게 일어나는 페이지(Ex. 게시글 상세 페이지 등)에서 사용
-
CSR 방식은 주로 모든 사용자가 같은 내용을 바라볼 필요가 없고(Ex.마이페이지, 등록 페이지 등) 데이터의 변화가 자주 일어나는 페이지에서 사용
3. Search
그동안 진행했던 프로젝트에서 검색을 구현할 때 유저가 모든 검색어를 입력하고 Enter를 누르면 검색 결과 페이지가 나오는 식으로 주로 구현을 했었습니다.
이번에는 조금 더 유저 친화적인 방법으로 구현해보고 싶다는 생각이 들어 우리가 생각하는 일반적인 검색 엔진에서 검색하는 것처럼 검색어가 입력될 때 하단의 검색어 자동 완성 기능을 제공하면 어떨까 하는 생각을 했고 구현해보고자 했습니다.
총 세개의 게시판이 있었고 react-query를 사용하고 있었기 때문에 게시판 category에 따라 queryFn 내부에서 분기 처리하여 Data Fetching을 진행했습니다.
먼저 useDebounce Hook을 만들어 검색어 입력에 대한 DOM 이벤트 최적화를 진행했습니다. 그리고 이렇게 완성된 검색어를 react-query의 queryKey로 설정하고 캐싱을 해줘 같은 결과에 대해서 불필요한 API 요청을 하지 않도록 했다. 그리고 검색어를 전역으로 관리하여 하위 컴포넌트에서 사용하게끔 했습니다.
❗️ 초기에는 page에서 state로 관리해서 하위 컴포넌트의 props로 넘겨주는 방식으로 구현했는데 컴포넌트가 많아지면서 props drilling이 발생하여 검색어 쿼리를 전역으로 관리하는 방식으로 바꿨습니다.
검색어를 입력을 하면 검색어를 query로 하는 GET 요청을 보내고 받아온 결과를 slice하여 검색창 하단에 보여줍니다. 그리고 검색 결과는 키보드로 이동이 가능하게끔 만들었습니다.
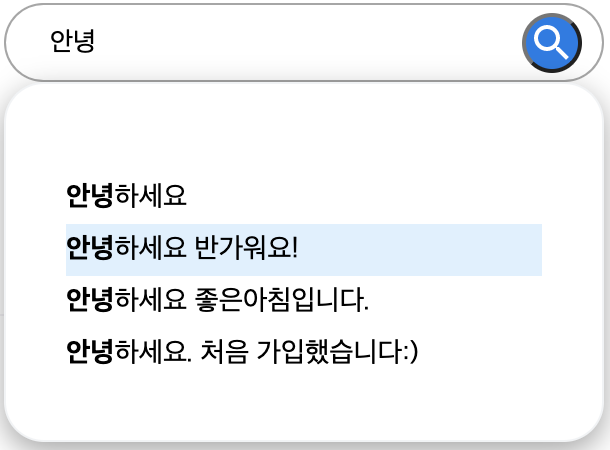
🛠 개선사항
목표했던 기능을 얼추 완성하기는 했지만 크게 세 가지의 개선사항이 존재합니다.
첫번째, 마지막 검색어에서 아래로 혹은 처음 검색어에서 위로 키보드 이동을 하면 하이라이팅이 사라집니다. 이 문제는 검색 결과의 길이를 가지고 예외 처리를 해주면 될 것 같다고 생각하고 있습니다.
두번째, ESC를 눌렀을 때 검색어와 검색결과가 사라지지 않습니다.
e.key가 Escape일 때 전역으로 관리(Recoil)하는 검색어를 초기화 하기 위해 useResetRecoilState()를 사용해봤는데 원하는대로 동작하지 않아 다시 살펴보고 개선해야되는 부분입니다.
❗️ 예상하기로는 react-query의
queryKey를 잘못 관리하고 있는게 아닐까라고 생각하고 있습니다.
세번째, 검색어를 입력하고 나온 추천 검색어 목록에서 키보드 이동을 통해 선택한 검색어에서 Enter로 누르면 선택한 검색어에 대한 결과를 보여주는 것이 아닌 전체 검색 결과를 보여줍니다.
4. Pagination, Filter
React를 사용할 때는 react-router-dom의 useSearchParams Hook을 유용하게 사용해서 페이지네이션을 구현했었는데 Next에서는 useRouter Hook을 통해 페이지네이션과 필터링을 구현했습니다.
Pagination, Filter 함수 모두 단순히 URL을 바꿔주는 역할만 했고 이에 맞는 데이터는 URL의 정보를 가지고 호출하는 방식으로 구현했습니다.
이런 방식으로 구현하게 되면 Client에서 page, perPage, sortBy 같은 관리해야 하는 상태가 줄어들기 때문에 개인적으로는 조금 더 나은 방법이 아닌가 하는 생각을 가지고 있습니다.
5. React Query
이번에도 역시나 React-Query + Recoil을 이용해서 상태 관리를 진행했습니다.
이 조합을 처음 알고 사용했을 때 만족도가 너무 높았기에 이후에 진행했던 프로젝트에서 대부분 사용하게 돼 버렸습니다.
이번에 React Query를 사용하면서 배운 점은 queryKey 관리의 중요성을 여실히 깨달았다는 점입니다.
다뤄야하는 데이터가 많고 사용하는 API가 많다보니까 queryKey를 useQuery Hook 안에 직접 넣어주는 방식으로는 점차 관리하기가 어려워졌습니다.
또한 unique한 queryKey를 만들었다고 생각했는데 어딘가에서 이미 사용하고 있던 queryKey여서 원하는대로 동작하지 않는 경우가 있었습니다.
그래서 같이 일하던 동료가 react-query maintainer인 TkDodo가 소개한 queryKey 관리 방법에 대한 글을 보여줬고 이를 적용해봤습니다.
이 글의 핵심은 데이터를 대표하는 queryKey는 const로 설정하고 이 외에 동적으로 변하는 값은 함수를 통해 넣어줘서 queryKey를 생성해주는 일종의 팩토리 함수를 만드는 것입니다.
const todoKeys = {
all: ['todos'] as const,
lists: () => [...todoKeys.all, 'list'] as const,
list: (filters: string) => [...todoKeys.lists(), { filters }] as const,
details: () => [...todoKeys.all, 'detail'] as const,
detail: (id: number) => [...todoKeys.details(), id] as const,
}이 방식을 적용하고 나니 queyrKey를 한 곳에서 관리하게 되서 유지, 보수도 쉽게 할 수 있었고 코드 가독성 또한 훨씬 좋아진걸 느낄 수 있었습니다.
또한 useQuery, useMutation, useInfiniteQuery와 같은 Hook을 Custom Hook으로 빼서 분리해야 하는가에 대한 고민이 있었습니다.
Custom Hook으로 분리하는 가장 큰 이유가 재사용성이라고 생각을 했는데 한 번만 사용되는 useQuery를 굳이 Custom Hook으로 분리하는게 좋을까를 고민했었습니다.
이번 프로젝트에서는 모든 부분을 Custom Hook으로 분리하지는 않고 일부분만 분리하였지만 Custom Hook으로 분리하게 되면 같은 관심사(?)를 가지는 데이터(Ex. 댓글 수정, 삭제, 등록을 다루는 useMutation Custom Hook)에 대한 로직을 한 곳에서 관리할 수 있는 장점이 있을거 같아서 조금 더 고민을 해봐야 될 것 같습니다.
6. Sentry
프로젝트를 빌드하기 전에는 Typescript가 코드 레벨에서 발생하는 오류를 잡는데 도움을 줄 수 있다. 그리고 데이터에 대한 오류, UI에서 발생하는 오류는 개발을 하면서 충분히 조심하고 방어할 수 있고 최종 사용자들은 이러한 오류들이 없는 서비스를 이용하게 만들 수 있습니다.
하지만 이 외의 예상치 못한 오류, 예를 들어 예상치 못한 네트워크 이슈로 인한 오류, 유저의 브라우저 버전에 따른 오류, 원인을 알기 어려운 오류 등 우리가 미리 예측하고 대응하기 어려운 오류들이 존재합니다.
이번 프로젝트를 진행하면서 이런 예측 불가능한 오류를 추적하고 대응할 수 있는 시스템을 적용해보고자 했고 그동안 생각만 해두었던 Sentry를 적용해보고자 공부를 했습니다.
물론 지금 진행한 프로젝트는 사용자가 많지도 않고 간단한 팀 프로젝트지만 실제 우리 회사의 프로젝트에서는 프론트엔드의 오류를 따로 추적하고 대응하는 시스템이 존재하지 않았기 때문에 프로젝트에 적용해볼 수도 있지 않을까하는 생각이 들었습니다.
Sentry 공식 문서가 잘 나와있어 초기 설정은 어렵지 않게 설정할 수 있었습니다.
공식 문서에는 sentry wizard를 사용하여 설정하는 방식과 manual하게 설정하는 방식 모두 있었는데 나는 wizard를 이용하지 않고 manual하게 설정해줬습니다.
❗️ 만약 manual하게 설정한 후 wizard를 통해 다시 한 번 설정하게 되면 conflict를 해결해줘야 합니다.
🛠 초기 설정 파일 생성
먼저 프로젝트의 최상위에서 sentry.server.config.ts 파일과 sentry.client.config.ts 파일을 생성하고 아래와 같이 작성합니다.
❗️참고로 nextjs 프로젝트이기 떄문에 client-side SDK와 server-side SDK를 모두 작성해주어야 합니다.
import * as Sentry from '@sentry/nextjs';
const SENTRY_DSN =
process.env.NEXT_PUBLIC_DEVELOPMENT_SENTRY_DSN || process.env.NEXT_PUBLIC_PRODUCTION_SENTRY_DSN;
Sentry.init({
dsn: SENTRY_DSN,
tracesSampleRate: 1.0,
});
❗️ DSN은 sentry 가입 후 프로젝트를 생성하면 발급받을 수 있습니다.
🛠 Custom Error Component
Vercel을 포함한 서버리스 개발 환경에서 Next.js 서버는 severless function의 크기를 줄이기 위해 "minimal"모드로 동작합니다.
그러한 이유로 특정 에러에 대한 추적이 제대로 이루어지지 않는 경우가 있다.
추가적으로 Next.js에서는 특정 오류가 핸들러에 나타나기 전에 잡아내는 Custom Error bounday가 존재합니다.
Sentry에서 이런 오류를 잡아내기 위해서는 Next.js의 Error Page를 커스텀하는 방식을 사용할 수 있습니다.
import * as Sentry from "@sentry/nextjs";
import type { NextPage } from "next";
import type { ErrorProps } from "next/error";
import NextErrorComponent from "next/error";
const CustomErrorComponent: NextPage<ErrorProps> = props => {
return <NextErrorComponent statusCode={props.statusCode} />;
};
CustomErrorComponent.getInitialProps = async contextData => {
await Sentry.captureUnderscoreErrorException(contextData);
return NextErrorComponent.getInitialProps(contextData);
};
export default CustomErrorComponent;🛠 설정 파일 확장
withSentryConfig 는 Webpack의 Next.js 기본 설정을 확장하는데 사용한다. withSentryConfig는 두 가지 작업을 수행합니다.
-
서버가 시작되고 페이지 로드가 완료됐을 때
sentry.server.config.ts와sentry.client.config.ts파일을 각각 자동적으로 불러옵니다.
withSentryConfig를 사용하는 것이 성능 측정을 시작하고 모든 오류를 추적하기 위한 SDK를 초기화하는 것을 보장하는 유일한 방법입니다. -
Source map을 생성하고 Sentry에 업로드해서
demangled된 코드를 추가할 수 있습니다.
🛠 Source Map 설정
기본적으로 withSentryConfig 는 server와 client의 build에 대해 SentryWebpackPlugin의 인스턴스를 webpack plugin에 추가합니다.
다시 말해, 빌드를 하게 되면(next build) 아래와 같은 특정 작업들이 자동적으로 수행이 됩니다.
Sentry.init()안에release값이 설정sourcemap이 생성되고 Sentry에 업로드
이러한 과정의 결과로 stacktrace를 시작할 수 있습니다.
❗️
1.위 과정은 각각의 파일이 변경할 때 전체 업로드 과정을 다시 실행시키지 않기 위해 dev server(next dev)에서는 동작하지 않습니다.
2. 플러그인에 대한 다양한 옵션들은 여기에서 확인할 수 있습니다:)
🛠 hidden-source-map
배포 설정에 따라, Sentry를 사용할 때 브라우저 개발자 도구에 이전에는 없었던 코드들이 나타날 수가 있습니다.
이 현상은 Webpack devetool 안의 source-map 의 기본 설정 때문에 발생하게 되는데 이를 예방하기 위해 내장된 파일에 주석이 포함되지 않도록 하여 source-map이 브라우저에 표시되지 않도록 하는 hidden-source-map 을 대신 사용할 수 있습니다.
hidden-source-map을 사용하기 위해서는 아래와 같이 설정해주어야 합니다.
const moduleExports = {
sentry: {
hideSourceMaps: true,
},
};🛠 sentry-cli
SentryWebpackPlugin은 설정 파일을 사용하거나 환경 변수를 사용하는 두 가지 방법 중 하나의 방법을 통해 source-map과 release를 관리하기 위해 sentry-cli를 이용합니다.
💡 CLI 설정에 대한 자세한 설명은 여기에서 확인할 수 있습니다
저는 이미 사용하고 있던 플러그인이 있었기 때문에 next.config.js는 아래와 같이 설정해줬습니다.
const nextEnv = require('next-env');
const dotenvLoad = require('dotenv-load');
const { withSentryConfig } = require('@sentry/nextjs');
/** @type {import('next').NextConfig} */
dotenvLoad();
const withNextEnv = nextEnv();
const SentryWebpackPluginOptions = {
silent: true,
};
const imgUrl =
process.env.NODE_ENV === 'development'
? process.env.NEXT_PUBLIC_DEVELOPMENT_IMAGE_BASE_URL
: process.env.NEXT_PUBLIC_PRODUCTION_IMAGE_BASE_URL;
const nextConfig = {
reactStrictMode: true,
swcMinify: true,
images: {
domains: [imgUrl.toString()],
},
async redirects() {
return [
{
source: '/',
destination: '/home',
permanent: true,
},
];
},
sentry: {
hideSourceMaps: true,
},
};
module.exports = withNextEnv(withSentryConfig(nextConfig, SentryWebpackPluginOptions));아래 사진을 보면 내가 임의로 발생시킨 에러뿐 아니라 Hydration에서 그리고 서버에러까지 모두 추적하는 것을 볼 수 있습니다.

Sentry는 발생한 이벤트 로그에 대하여 다양한 정보를 제공합니다.
- Exception & Message: 이벤트 로그 메시지 및 코드 라인 정보 (source map 설정을 해야 정확한 코드라인을 파악할 수 있습니다.)
- Device: 이벤트 발생 장비 정보 (name, family, model, memory 등)
- Browser: 이벤트 발생 브라우저 정보 (name, version 등)
- OS: 이벤트 발생 OS 정보 (name, version, build, kernelVersion 등)
- Breadcrumbs: 이벤트 발생 과정
특히 Sentry가 제공하는 정보 중 하나인 Breadcrumb는 사용자 이벤트의 발생 과정을 보여주는데 이를 통해 유저의 행동을 재현하고 문제를 해결하는데 많은 도움이 될 것 같다고 느껴졌고 이 외의 다른 기능, 정보들을 활용해서 오류를 추적, 대응하고 성능과 사용성을 개선할 수 있고 Slack과 연동해서 발생한 오류에 대해 팀원과 공유할 수 있어서 발 빠르게 문제 상황에 대응할 수 있을것 같다고 생각할 수 있게 만들어준 경험이었습니다:)
참조
