9. 워드 임베딩
- 텍스트를 컴퓨터가 이해하고, 효율적으로 처리할 수 있게 단어를 벡터로 표현하는 방법
- 표현들의 종류
- 희소 표현 Sparse Representation
- 원 -핫 인코딩을 통해 생성된 원 -핫 벡터는 표현하고자 하는 단어의 인덱스만 1이고 나머지 인덱스는 전부 0인 벡터 표기법이다. 이렇게 생성된 벡터와 이 벡터가 쌓인 모양의 행렬은 대부분의 성분이 0으로 존재하는데, 이런 형태를 희소 표현 sparse representation이라 부른다
- 원-핫 벡터를 sprase vector 라 부른다
- 희소 벡터의 문제점은 단어 개수가 늘어나면 벡터 차원이 한없이 커지는 점이다. 코퍼스의 단어가 N개이면, 원-핫 벡터의 차원또한 N이 된다. 이러한 벡터 표현은 공간적 낭비를 불러온다
- 밀집 표현 Dense Representation
- 사용자가 설정한 값으로 벡터 표현의 차원을 맞춘다. 이 과정에서 더이상 0과 1만이 아니라 실수값을 갖게 된다
- 워드 임베딩Word Embedding을 통해 단어를 밀집 벡터dense vector 로 표현한다
- 밀집 벡터를 워드 임베딩을 통해 나온 결과라 하여 임베딩 벡터embedding vector라 불리기도 한다
- 분산 표현 Distributed Representation
- 비슷한 문맥에서 등장하는 단어는 비슷한 의미를 갖는다는 가정을 전제한다
- 단어의 의미를 벡터의 여러 차원에 분산하여 표현한다. 이렇게 되면 일 필요가 없어지므로, 상대적으로 저차원으로 줄어들게 된다
Word2Vec
Word2Vec의 특징
- 은닉층이 1개인 얕은 신경망(shallow neural network)이다.
- 또한 Word2Vec의 은닉층은 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않으며 룩업 테이블이라는 연산을 담당하는 층으로 투사층(projection layer)이다
CBOW (Continous Bag of Words)
- 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법
- 예 : "The fat cat sat on the mat"
- ['The', 'fat', 'cat', 'on', 'the', 'mat']으로부터 sat을 예측하기로 하자 - 용어
- 중심 단어center word: 예측하고자 하는 단어
- 주변 단어 context word: 예측에 사용되는 단어
- 윈도우(window): 앞, 뒤로 몇 개의 단어를 볼지를 결정하는 범위. 윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n이다
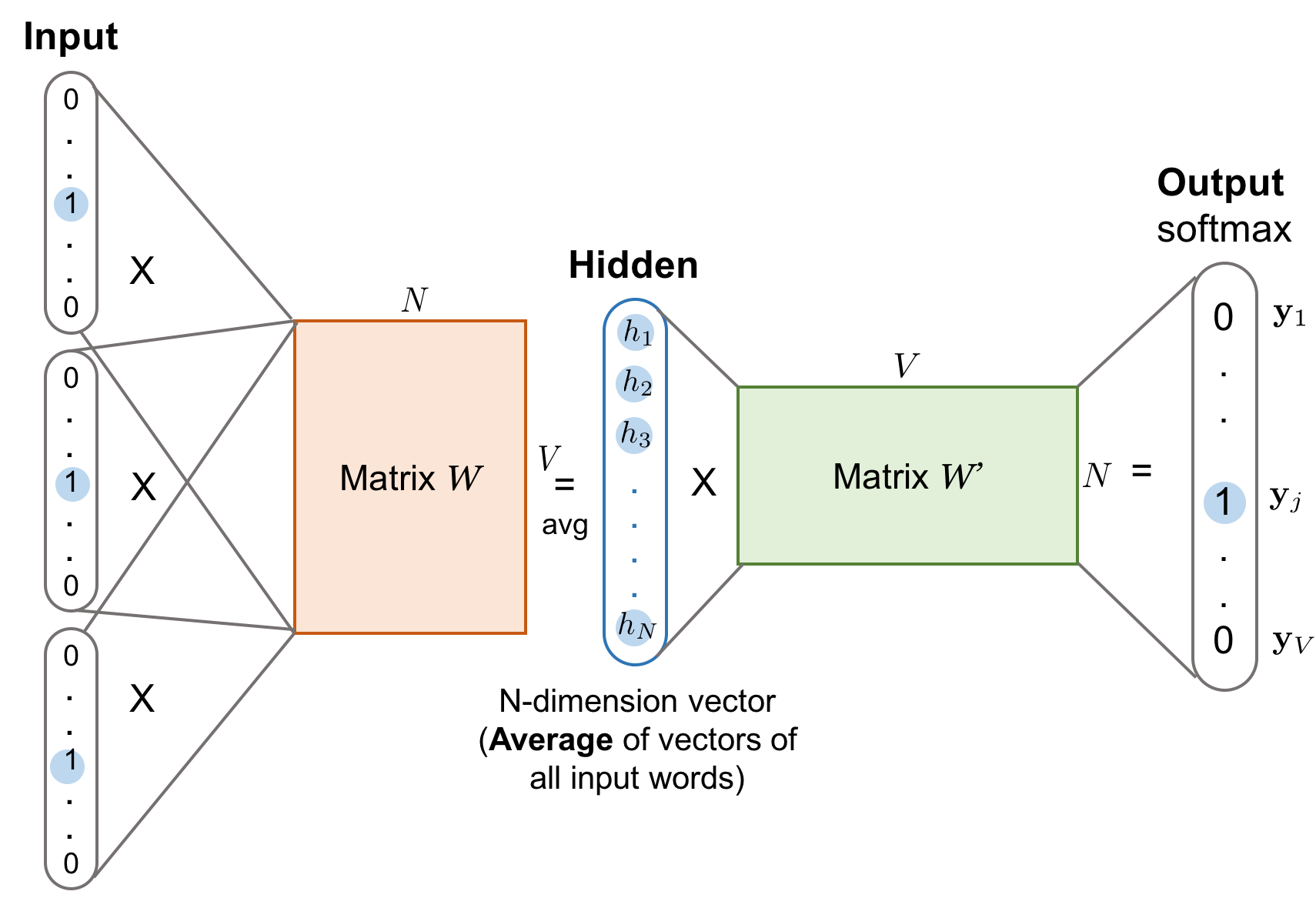
- 가중치 는 행렬이며, 투사층에서 출력층사이의 가중치 는 행렬이다
- 여기서 는 단어 집합의 크기(원-핫 벡터의 크기), 는 임베딩 후 벡터의 크기를 의미한다
- CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해 계속해서 이 W와 W'를 학습해가는 구조이다
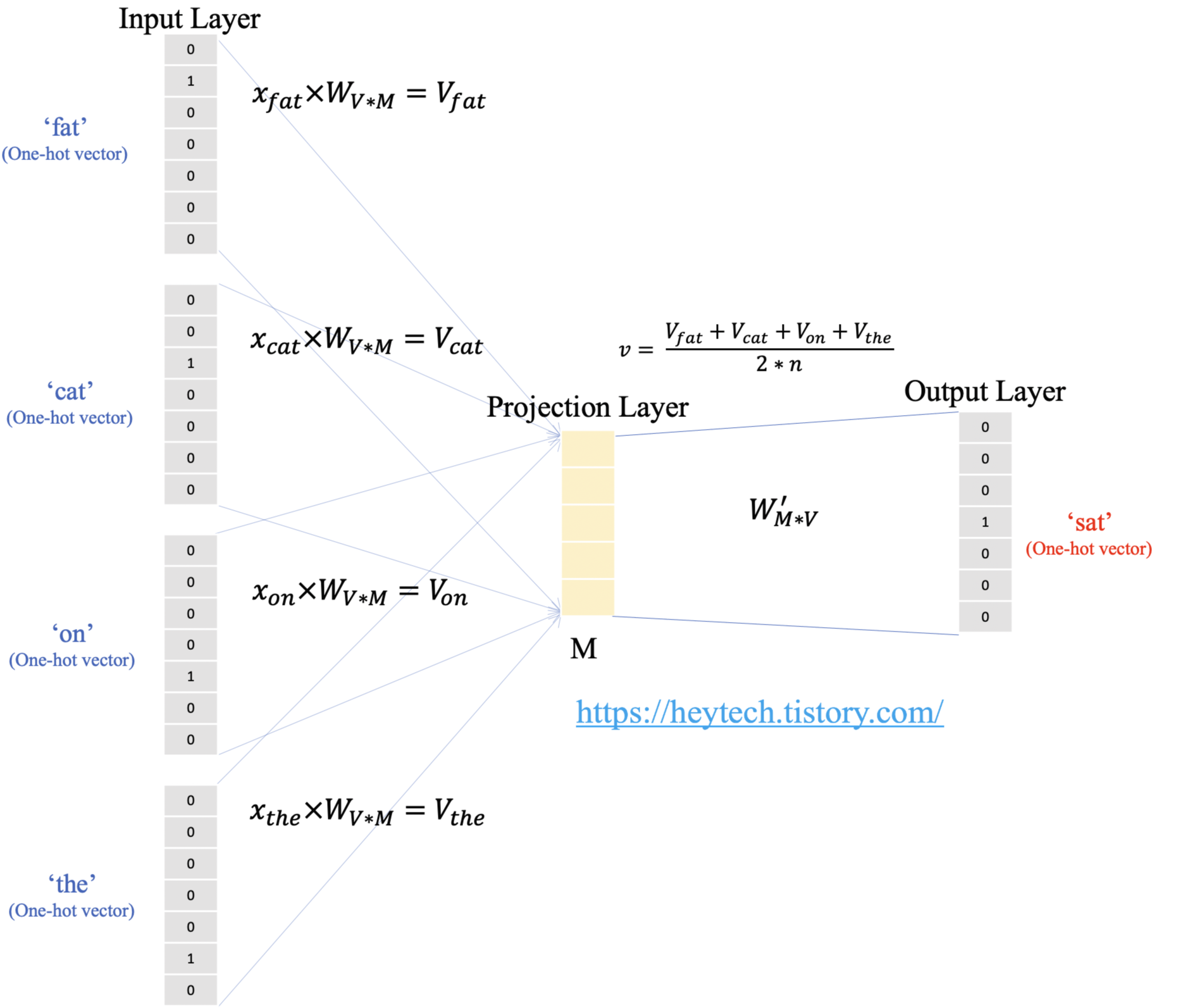
- (주변 단어의 원-핫 벡터에 대해서 가중치 행렬 가 곱해 만든) 벡터들은 투사층에서 만나 이 벡터들의 평균인 벡터를 구하게 된다
- 이렇게 구해진 평균 벡터는 두번째 가중치 행렬 과 곱해진다
Skip-gram

- 중심 단어에서 주변 단어를 예측한다. 앞서 언급한 예문에 대해서 동일하게 윈도우 크기가 2일 때, 데이터셋은 다음과 같이 구성된다
- 여러 논문에서 성능을 비교해보앗을 때 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있다
NNLM과 Word2Vec의 비교
- NLM은 다음 단어를 예측하는 언어 모델이 목적이므로 다음 단어를 예측하지만, Word2Vec(CBOW)은 워드 임베딩 자체가 목적이므로 다음 단어가 아닌 중심 단어를 예측하게 하여 학습한다
- Word2Vec는 일반적으로 NNLM보다 훨씬 빠른 학습 속도를 가진다
네거티브 샘플링을 활용한 Word2Vec 구현
- Word2Vec은 역전파 과정에서 모든 단어의 임베딩 벡터값의 업데이트를 수행하지만, 만약 현재 집중하고 있는 중심 단어와 주변 단어가 '강아지'와 '고양이', '귀여운'과 같은 단어라면, 사실 이 단어들과 별 연관 관계가 없는 '돈가스'나 '컴퓨터'와 같은 수많은 단어의 임베딩 벡터값까지 업데이트하는 것은 비효율적이다
- 네거티브 샘플링은 문제를 다중분류에서 이진분류로 바꿈으로서 문제를 해결한다.
- 중심단어와 주변단어를 입력으로 하고, 두 단어가 윈도우 크기내 존재하는 이웃관계일지 그 확률을 예측한다
- 예를 들어, CBOW 모델로 가정한다면, 'you' 와 'goodbye' 라는 2개의 맥락 단어가 입력으로 주어졌을 때, 가운데에 나올 단어가 무엇인가? 라는 다중분류 문제를 해결해왔다.
- 그런데 이를 약간의 관점을 변형하여 이진분류 문제로 바꿀 수 있다. 방금 예시를 든 경우로 하자면, 'you' 와 'goodbye' 라는 2개의 맥락 단어가 입력으로 주어졌을 때, 가운데에 나올 단어는 'say'인가? 아닌가? 로 바꿀 수 있게 된다.

안녕하세요!