

결론: 설치는 되었지만 하루 종일 삽질을 하였다.
사전 작업
기초 개념 정리
Tensorflow : 구글(Google)에서 만든 수치, 통계, 대규모 머신러닝 워크 로드를 제공하여 딥러닝 프로그램 구현을 쉽게 할 수 있도록 돕는 오픈소스 라이브러리
ROCm : AMD GPU에서 PyTorch를 사용할 수 있게 해주어 GPU 가속을 돕는 소프트웨어 툴
PyTorch : NVIDIA GPU 가속 연산을 위한 툴
amdgpu-dkms : AMD GPU HW 모듈 관리 툴(AMD GPU는 Instinct와 Radeon 계열로 나뉨)
CUDA Toolkit : NVIDIA GPU 가속화 툴 킷
cuDNN : 딥 뉴럴 네트웨크를 위한 GPU 가속화 라이브러리로 TensorFLow, PyTorch, Theano 등 대중적으로 널리 사용되는 딥러닝 프레임워크를 가속화
CUDA 부분 참고 https://velog.io/@whattsup_kim/gpu%EA%B0%9C%EB%B0%9C%ED%99%98%EA%B2%BD%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0
사양 및 호환성 확인
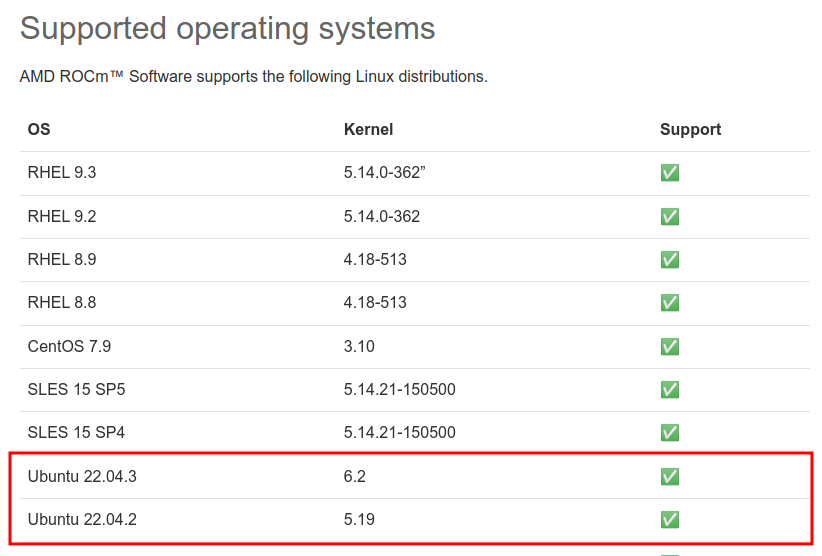
- ROCm 호환성 체크
Ubuntu 22.04 운영체제의 경우 kenrel 5.19 ~ 6.2 지원 확인
https://rocm.docs.amd.com/projects/install-on-linux/en/latest/reference/system-requirements.html
Pytorch 호환성 체크
최신 release Pytorch 설치 시 Python 3.8 ~ 3.11 버전 지원 확인
https://pytorch.kr/get-started/locally/#mac-python

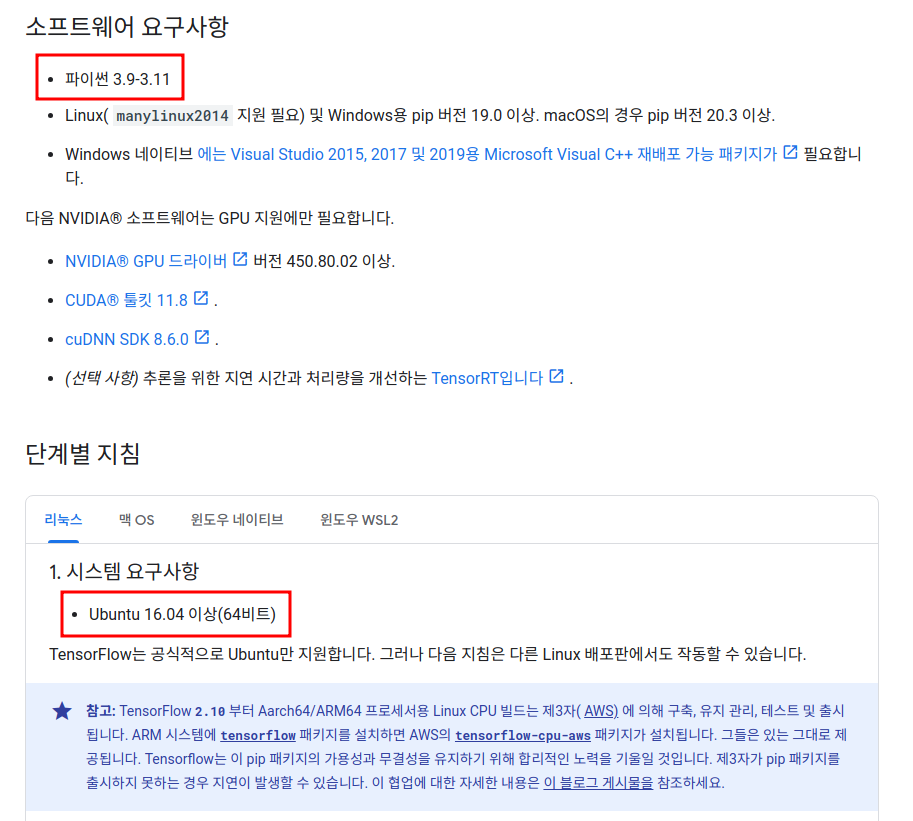
Tensorflow 호환성 체크
Python 3.9 ~ 3.11 및 Ubuntu 16.04 (64bit) 이상 지원 확인
https://www.tensorflow.org/install/pip?hl=ko
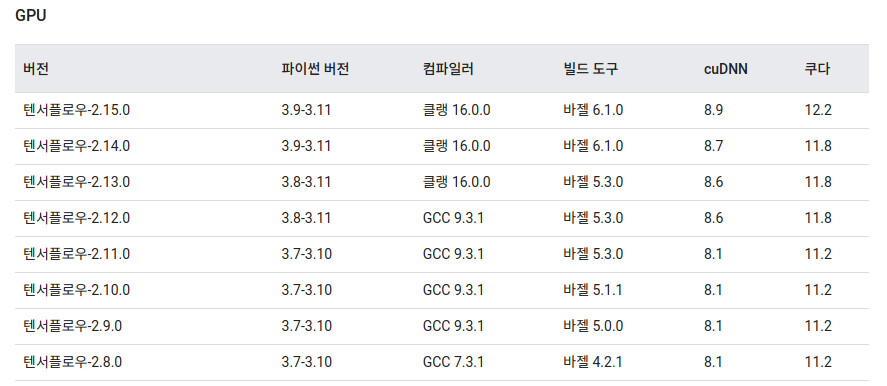
Tensorflow와 CUDA와의 버전 호환성과 CUDA와 NVIDIA driver 버전의 호환성 크로스 체크
https://www.tensorflow.org/install/source?hl=ko#gpu
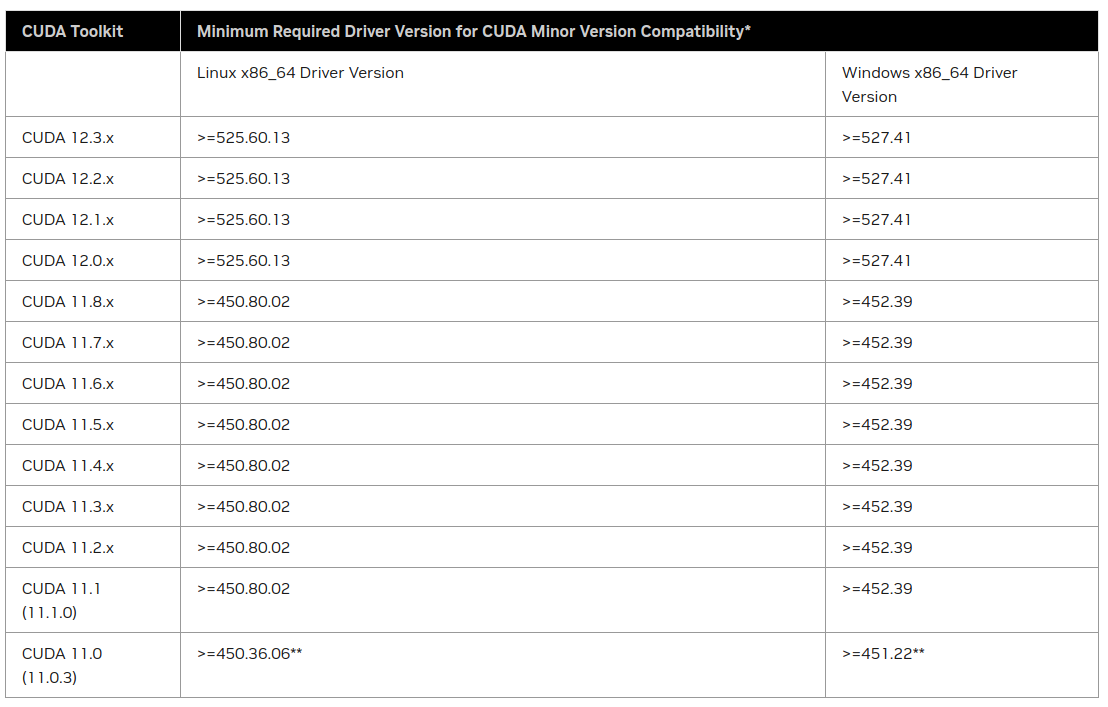
설치 루틴 결정

위 구조를 보아 amdgpu-dkms > Python > ROCm > Tensorflow > PyTorch 순으로 결정
서버 세팅
kernel Ver 확인 및 업그레이드
# 확인 방법
uname -r
===
5.15.0-75-generic
===6.2 버전으로 업그레이드 진행
# 설치
apt install -y linux-generic-hwe-22.04
# 부팅 커널 목록에서 우선순위 확인
awk -F"--class" '/menuentry/ && /with Linux/ {print $1}' /boot/grub/grub.cfg | awk '{print i++ " : " $5,$6,$7,$8}' | sed -e "s/'/ /g"
===
0 : 6.2.0-39-generic
1 : 6.2.0-39-generic (recovery mode)
2 : 5.15.0-91-generic
3 : 5.15.0-91-generic (recovery mode)
4 : 5.15.0-75-generic
5 : 5.15.0-75-generic (recovery mode)
===
reboot
uname -r
===
6.2.0-39-generic
===GPU 확인
lspci -k | grep 'VGA compatible controller'
lspci | grep -i vga위 두 명령어로 확인 시 QXL paravirtual graphic card로 출력된다면 VM 환경일 가능성이 높으므로 아래 명령어로 재확인
# 방법 1
apt install -y hwinfo
hwinfo --gfxcard | egrep 'Model|Device'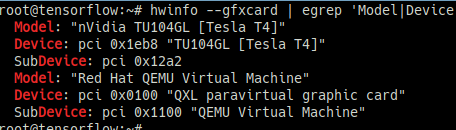
# product 부분 확인
lshw -C display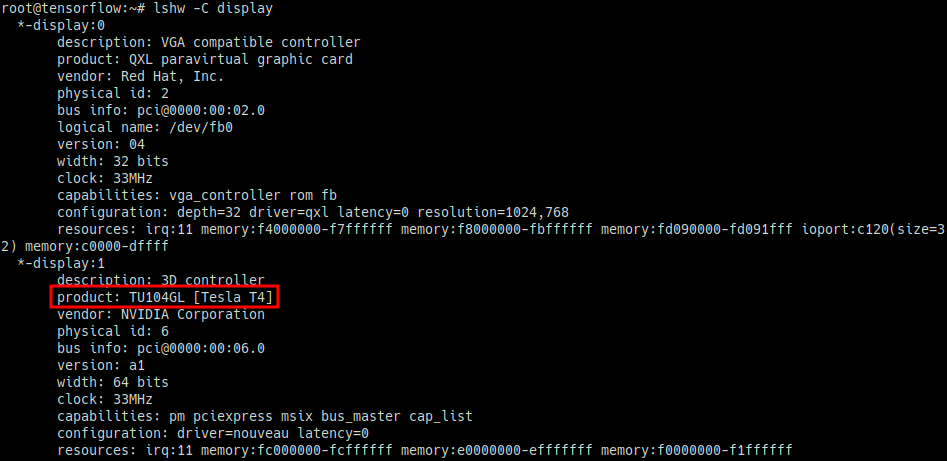
Python3 버전 확인
python3 -V
===
Python 3.10.12
===설치
amdgpu-dkms
cd /usr/local/src
wget http://repo.radeon.com/amdgpu-install/latest/ubuntu/jammy/amdgpu-install_6.0.60000-1_all.deb
dpkg -i amdgpu-install_6.0.60000-1_all.deb
amdgpu-install --usecase=hiplibsdk, rocm
# --no-dkms 옵션을 제외하고 사용하면 dkms를 이용하지 않고 직접 빌드한 커널 모듈로 선택 가능
dpkg -l | grep amdgpu-dkms
===
iU amdgpu-dkms 1:6.3.6.60000-1697589.22.04 all amdgpu driver in DKMS format.
iU amdgpu-dkms-firmware 1:6.3.6.60000-1697589.22.04 all firmware blobs used by amdgpu driver in DKMS format
===
dkms status
dpkg --configure -a

amdgpu 모듈 허용
lsmod | grep amdgpu
modprobe amdgpu
lsmod | grep amdgpu
echo "amdgpu" | sudo tee -a /etc/modules-load.d/amdgpu.conf
rebootROCm 설치
echo -e 'Package: *\nPin: release o=repo.radeon.com\nPin-Priority: 600' \
| sudo tee /etc/apt/preferences.d/rocm-pin-600
apt update -y
apt install -y rocm-hip-sdk
※ Err 발생 시 apt --fix-broken install -y 실행하여 패키지 수리해보기
tee --append /etc/ld.so.conf.d/rocm.conf <<EOF
/opt/rocm/lib
/opt/rocm/lib64
EOF
ldconfig
export PATH=$PATH:/opt/rocm-6.0.0/bin
apt install -y rocm-dkms rocm-opencl-sdk
apt reinstall amdgpu-dkms
# 또는
apt install -y rocmrocm-smi --version
===
ROCM-SMI version: 2.0.0+ad5d1b6
ROCM-SMI-LIB version: 6.0.0
===
apt show rock-libs -a
rocm-smi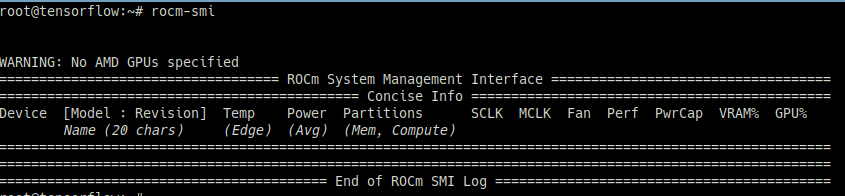
No AMD GPUs specified 출력
rocminfo
GPU 정보 출력 불가
왜인지 이유를 찾다가 테스트 용으로 받은 서버가 Tesla 라는 것을 다시 인지하였고 위 과정은 NVIDIA GPU Tesla 서버에서는 적용이 불가한 테스트 였지만 그래도 목표로 한 Tensorflow와 Pytorch까지 설치해보고 기록을 남겨두기로 함
Tensorflow 설치
python3 -m pip install tensorflow
python3 -m pip show tensorflow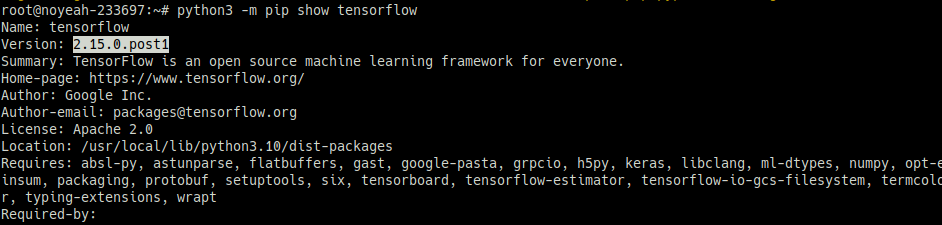
python3 -c 'import tensorflow as tf; print("The version of TensorFlow is", tf.__version__)'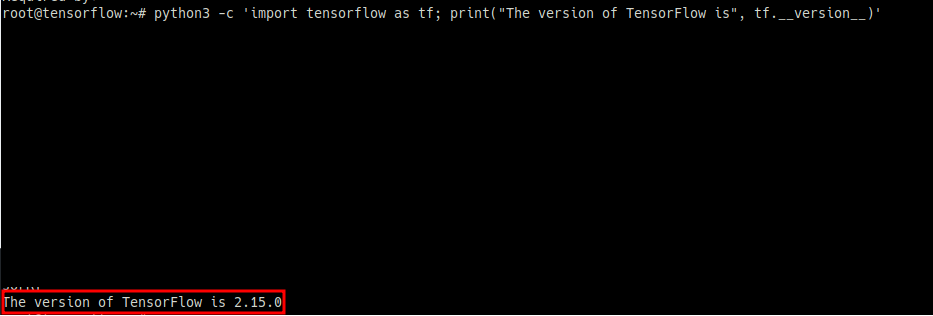
트러블슈팅
아래 에러 발생 시 조치 방법
/usr/bin/python3: No module named pip# apt로 설치
apt install -y python3-pipNVIDIA GPU driver 설치
CUDA 설치를 위한 사전작업이므로 호환성을 확인하고 진행
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
권장 및 설치 가능한 driver 목록 확인
apt install -y ubuntu-drivers-common
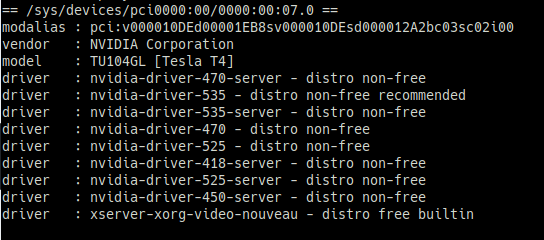
ubuntu-drivers devices
===
== /sys/devices/pci0000:00/0000:00:07.0 ==
modalias : pci:v000010DEd00001EB8sv000010DEsd000012A2bc03sc02i00
vendor : NVIDIA Corporation
model : TU104GL [Tesla T4]
driver : nvidia-driver-470-server - distro non-free
driver : nvidia-driver-535 - distro non-free recommended # recommended가 default 권장 버전
driver : nvidia-driver-525-server - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-525 - distro non-free
driver : nvidia-driver-418-server - distro non-free
driver : nvidia-driver-525-server - distro non-free
driver : nvidia-driver-450-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
===
apt install -y nvidia-driver-525 nvidia-utils-525 nvidia-kernel-common-525
reboot
nvidia-smi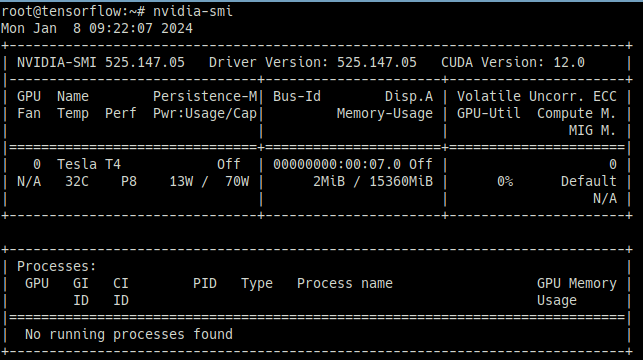
CUDA Version에서 지원 CUDA 버전을 확인할 수 있으나 CUDA 홈페이지에서 보는 편이 더 정확함
트러블 슈팅
아래 에러 발생 시 조치 방법
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.GPU driver 재설치를 진행해야 하며, 기존 버전으로 이전에는 문제 없이 사용했다고 하면 같은 버전으로 재설치해도 무관함. 작업 중에 셧다운은 하면 안되고 작업을 다 끝낸 뒤 리부팅해야 함
apt update -y && apt upgrade -y
apt autoremove -y nvidia-driver-525 nvidia-utils-525 nvidia-kernel-common-525
apt update -y && apt upgrade -y
apt install -y nvidia-driver-525 nvidia-utils-525 nvidia-kernel-common-525
reboot
nvidia-smiCUDA 12.2 설치
설치용 실행 파일 다운로드 및 설치 진행 시 많은 시간이 소요되며, 서버 내부 용량이나 자원이 여유로운 상태인지 확인하고 실행해야 함.
설치 파일 내부적으로 cuda 버전에 호환되는 nvidia-driver 버전 중 최신 버전으로 driver를 설치하는 과정이 포함되어 있으니 이를 제외하는 옵션으로 설치파일 실행
https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/cuda-12-2-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=runfile_local
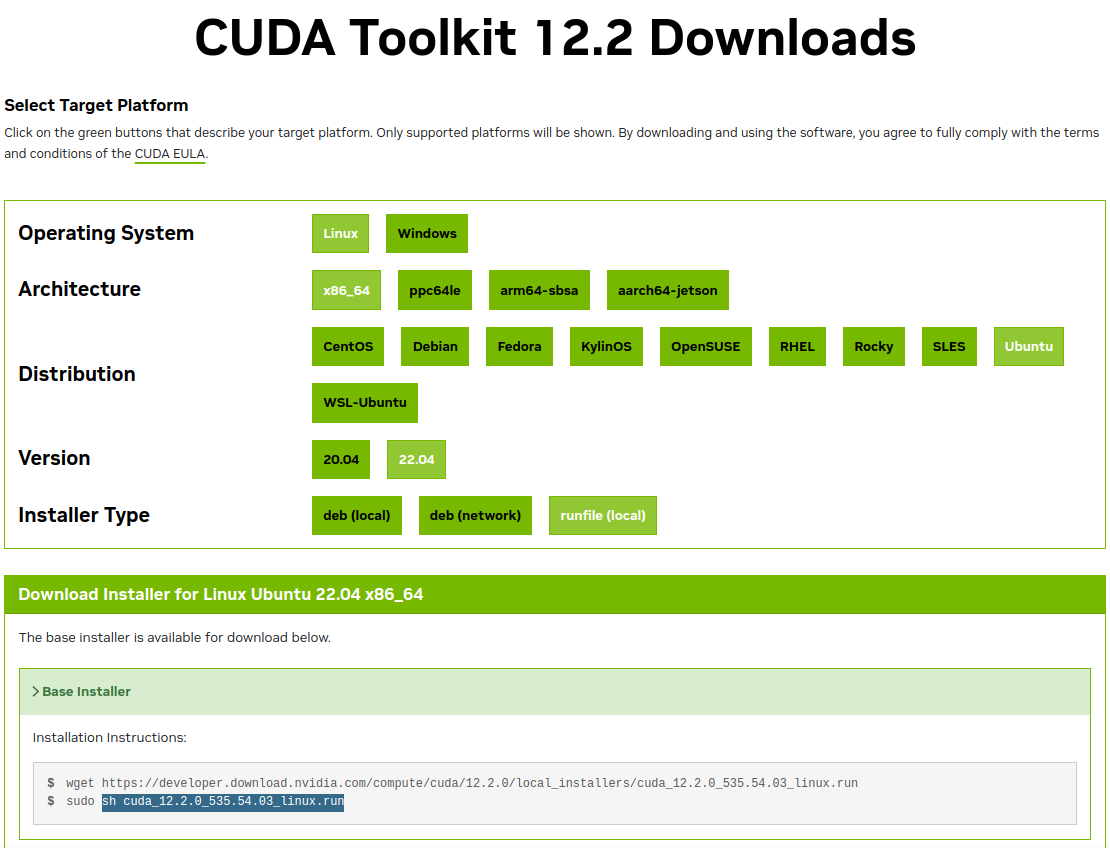
cd /usr/local/src
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
chmod +x cuda_12.2.0_535.54.03_linux.run
sh cuda_12.2.0_535.54.03_linux.run --toolkit --silent설치파일 실행 옵션
--toolkit : nvidia-driver를 제외하고 cuda만 설치
--silent : 옵션을 사용하면 선택사항을 고르는 화면 없이 자동으로 설치됨
--override : 기존 cuda 설치가 되어 있더라도 덮어쓰기 됨
--toolkitpath=/usr/local/cuda-12.2 : toolkit 설치 경로를 지정
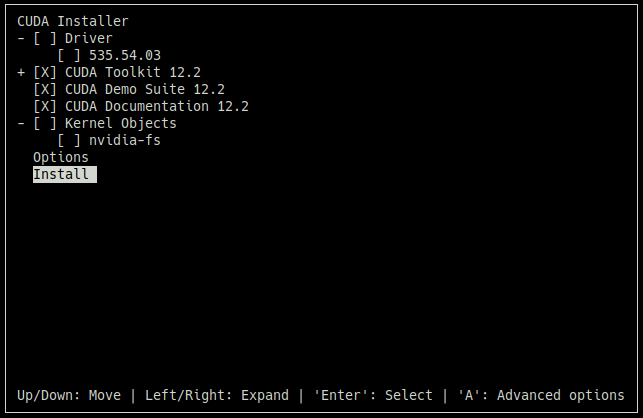
만일 선택사항을 고르도록 설치를 진행하면 아래 이미지와 같이 진행할 수 있음
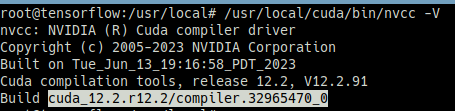
아직 환경 변수를 추가하지 않았기 때문에 전체 경로로 아래 명령어를 찾아 실행하고 버전이 잘 출력되면 설치 완료
cuDNN 8.9 설치
CUDA 12.2 버전에 호환되는 버전 확인하고 설치
로그인을 해야 설치 파일을 받을 수 있음
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse896-120
설치 방법은 패키지 deb 파일을 다운로드하고 apt로 설치하는 방법과 압축 파일을 이용하여 다운로드된 파일을 경로에 복사하는 방법이 있음
1. deb 패키지를 이용한 설치
Local Installer for Ubuntu22.04 x86_64(Deb) 다운로드
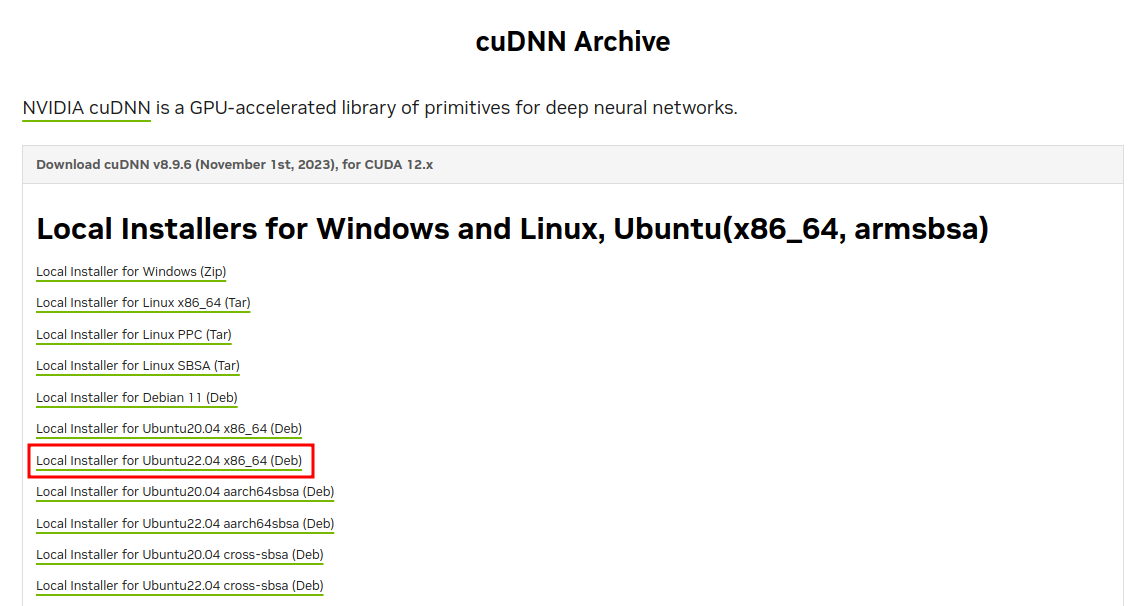
dpkg -i cudnn-local-repo-ubuntu2204-8.9.6.50_1.0-1_amd64.deb
cp -arp /var/cudnn-local-repo-ubuntu2204-8.9.6.50/cudnn-local-1998375D-keyring.gpg /usr/share/keyrings/
apt update -y
# 실제 설치
apt install -y libcudnn8=8.9.6.50-1+cuda12.2
# sample code와 라이브러리 문서 다운로드
apt install -y libcudnn8-samples=8.9.6.50-1+cuda12.22. 압축 파일을 이용한 설치
패키지 설치를 더 권장하는데 압축 파일을 통해 설치 시 링크 처리 할 때 하단에 있는 경로를 전부 찾아 걸어줘야 하기 때문임. 글 작성 시에는 8.9.7 버전으로 다운로드 하였기에 아래처럼 입력했지만 다른 버전을 설치하거나 환경이 달라지면 하나씩 찾아서 걸어줘야 하기 때문에 오류가 발생할 가능성이 높아짐
Local Installer for Linux x86.64 (Tar) 다운로드
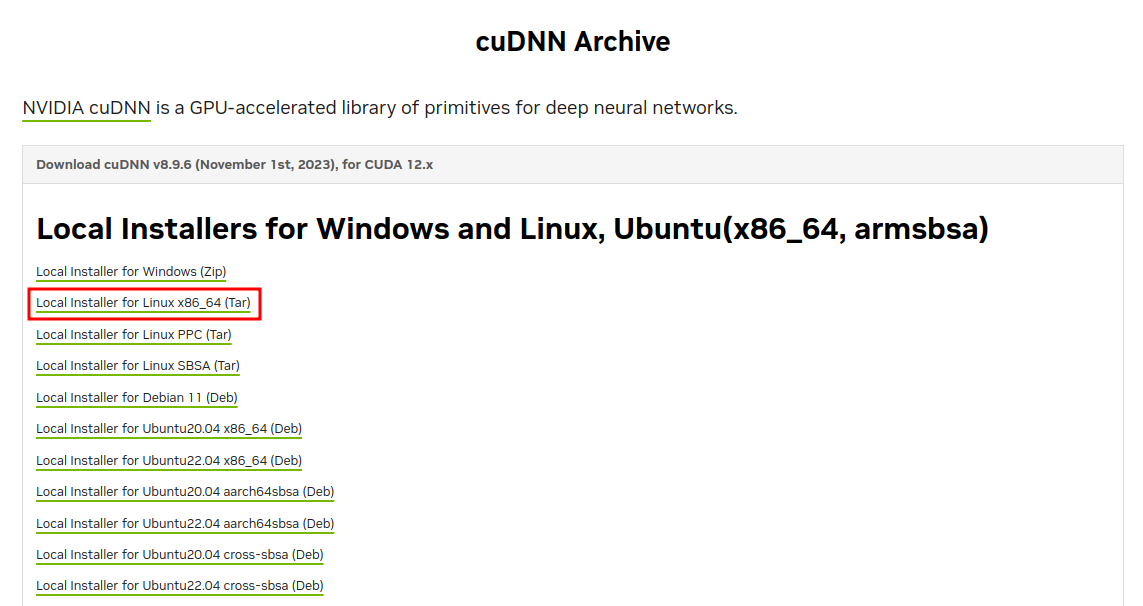

tar -xJvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
cd cudnn-linux-x86_64-8.9.7.29_cuda12-archive/
cp -arp include/cudnn* /usr/local/cuda/include
cp -arp lib/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.9.7 /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.9.7 /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.9.7 /usr/local/cudatargets/x86_64-linux/lib/libcudnn_cnn_train.so.8
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.9.7 /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.9.7 /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.9.7 /usr/local/cuda/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
ln -sf /usr/local/cuda/targets/x86_64-linux/lib/libcudnn.so.8.9.7 /usr/local/cuda/targets/x86_64-linux/lib/libcudnn.so.8 CUDA 환경 변수 추가
vi ~/.bashrc
===
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"
===
source ~/.bashrc환경 변수가 잘 추가되었다면 nvcc -V을 바로 사용할 수 있음
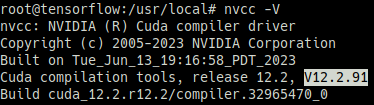
Pytorch 설치
python3 -m pip install torch torchvision torchaudiohttps://pytorch.kr/get-started/locally/
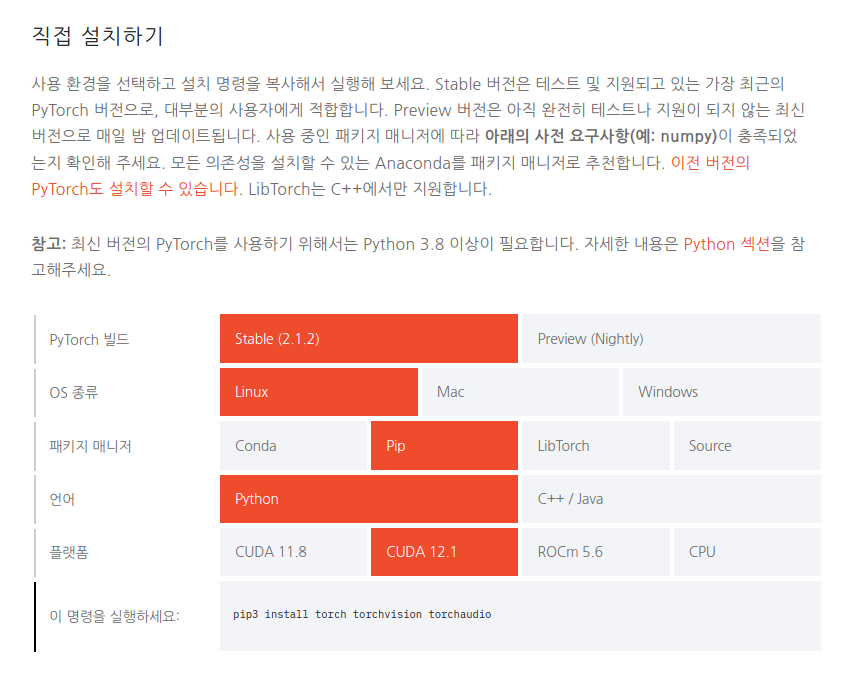
설치 완료되었다면 아래 코드를 실행시켜 보고 인식이 잘 되는지 확인함
vi cuda_test.py
===
import torch
print("cudnn version:{}".format(torch.backends.cudnn.version()))
print("cuda version: {}".format(torch.version.cuda))
===
chmod +x cuda_test.py
python3 cuda_test.py
===
cudnn version:8902
cuda version: 12.1
===CUDA 12.1에 맞춰 재설치
Pytorch와 CUDA 12.2 호환 불가
무언가 이상한 점을 깨달았는데 아무리 해도 가상 환경으로 돌리지 않는 이상 CUDA 12.2 설치한 버전과 설치한 Pytorch가 호환이 되지 않는다.
12.2 버전이 아직 공식 릴리즈 되지 않았다고 한다. 버전을 낮춰 12.1 버전을 설치하는 방법을 아래와 같이 작성하였다.
호환성 확인
CUDA 12.1 설치를 가장 우선순위로 두고 호환성 체크 시 아래와 같음
- Tensorflow: 2.15.x → 2.14.x 다운 그레이드
2.14.x 기준 CUDA 11.8 ↑, cuDNN 8.7 ↑ - nvidia-driver : CUDA 12.2와 12.1 버전 모두 같은 diriver 버전 지원 (변동 X)
- cuDNN : 8.9.6 설치 (CUDA 12.x 등 메이저 버전에 따라 파일이 같음)
Tensorflow 2.14 설치
python3 -m pip install tensorflow==2.14
python3 -m pip show tensorflow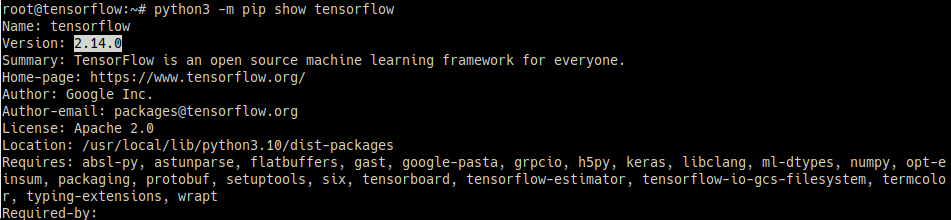
CUDA 12.1 설치
https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=runfile_local
cd /usr/local/src
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
chmod +x cuda_12.1.0_530.30.02_linux.run
cuda_12.1.0_530.30.02_linux.run --toolkit --silent
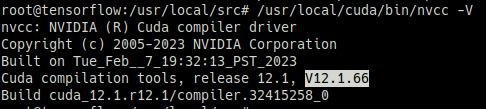
# 설치 확인
/usr/local/cuda/bin/nvcc -V
===
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Feb__7_19:32:13_PST_2023
Cuda compilation tools, release 12.1, V12.1.66
Build cuda_12.1.r12.1/compiler.32415258_0
===
cuDNN 8.9 설치
(윗 부분과 같아 생략)
pytorch 설치
(윗 부분과 같아 생략)
설치 확인
python3 cuda_test.py
===
cudnn version:8907
cuda version: 12.1
===
