Spring Batch
Spring Batch는 대량 데이터를 일괄 처리(batch processing) 하기 위한 프레임워크이다.
Spring Batch는 보통 3단계 실행 구조,(데이터 읽기/가공/조작)
5단계로 동작한다.
Job
└ Step
└ (Chunk)
├ ItemReader
├ ItemProcessor
└ ItemWriter근데 어디서 많이 본 기억이 나는데..? 뭔지 기억이 안난다
용어 정리하기
1. Job
Job은
전체 배치 작업을 이르는 말로, 하나의 배치 프로그램을 뜻한다.
가게별 평균 평점 처리 Job
2. Step
Step은 Job 안의 작업 단계를 말한다.
가게별 평균 평점 처리 Job
├ Step1: 파일 읽기
├ Step2: 데이터 가공
└ Step3: DB 저장3. ItemReader
데이터 읽기에 해당하는
- CSV 파일 읽기
- DB 조회
- API 데이터 읽기 등을 말한다.
4. ItemProcessor
데이터 가공 / 변환에 해당하는
데이터 필터링
값 계산
포맷 변환등을 말한다.
5. ItemWriter
데이터 저장에 해당하는
DB 저장
파일 저장
API 전송배치 종류 정하기
전략 선택: 증분 업데이트 vs 전체 재집계
배치를 구현하기 전에 어떤 방식으로 데이터를 집계할지 먼저 결정해야 했다.
부분 재집계 (Selective Reprocessing)
특정 시간 동안 업데이트된 가게(Store)들을 추출한 뒤,
해당 가게의 모든 리뷰를 다시 조회하여 통계를 재계산하는 방식
- 정확도 높음
- 로직 단순 (수정 / 삭제 / 이동 신경 안 써도 됨)
- 리뷰 많으면 비용 증가
증분 업데이트 (Incremental Processing)
마지막 배치 이후 변경된 리뷰(Review) 데이터를 기반으로
기존 통계에 값을 반영하는 방식
- 계산 속도 빠름
- 이미 통계에 반영된 데이터가 이후 수정되거나 삭제될 수 있기 때문에,
이전 상태를 확인할 수 있는 이력 저장 및 처리 로직이 필요하다.
하이브리드 방식 (부분 재집계 + 증분 업데이트)
현업에선 이 두 가지 방식을 모두 적용한 배치 방식을 사용하기도 한다
(그런데 얼마나 어려운지 감도 안온다...)
배달앱의 리뷰는 사용자가 수정하거나 삭제할 수 있으며,
가게 평점은 가게 노출이나 주문 선택에 영향을 주는 중요한 지표이다.
그래도 리뷰 데이터는 주문 로그와 같은 대규모 트래픽 데이터에 비해 상대적으로 규모가 크지 않다.
이러한 특성을 고려했을 때,
변경된 가게의 리뷰를 전체 재집계하는 부분 재집계 방식이 더 적합하다고 판단했다.
만약 증분 방식을 적용한다면 리뷰 수정이나 삭제가 발생했을 때
기존 통계에 반영된 값을 정확히 보정하기 위해 이전 상태를 기록해야 한다.
하지만 현재 구현된 수정/삭제 로직에서는 이력 저장 구조나 처리 로직을 추가로 설계해야 한다.
따라서 현재 시스템 구조에서는 증분 방식보다
부분 재집계 방식이 구현 복잡도와 데이터 정합성 측면에서 더 적절하다고 판단했다.
부분 재집계 방법은 튜터님 말씀대로 배치 실행 주기를 어떻게 설정할지 고민이 필요하다 하셨는데,
초당 생성되는 데이터 수와 초당 처리 가능한 데이터 수를 기반으로
배치가 한 번에 처리해야 할 데이터 양을 계산하고,
허용 가능한 지연 시간과 배치 실행 시간을 고려하여
배치 주기를 설계할 수 있다. (배치는 주기의 30% 안에 끝나야 안전)
가상으로 우리 앱을 사용하는 사용자가 하루에 5000 명 있다고 치고, 내가 일주일에 배달음식을 한 두번 시켜먹으니까, 약 5일 정도는 주문 수가 비슷하고 주말 이틀정도 주문 수가 많아 하루에 1000명 정도 비슷한 식사 시간대에 주문을 한다고 치고, 주문을 한다고 리뷰를 모두 남기진 않으니 70퍼센트 정도만 작성, 한다 치고, 최악의 경우를 대비해 시간을 정하면 저녁시간대 5시~8시 3시간동안 주문이 많다 쳐서 모두 그 사이에 주문을 하고 리뷰를 작성하면 10800 초 동안 700개 작성, 초 당 0.1개 정도...? (0.065)
+ Redis사용해 UX 경험 높이기
DB 배치를 돌리기 전 Redis 의 Atomic 연산 사용해 실시간으로 평점을 캐싱하여 보여주는 사용자의 UX경험 향상을 고려할 수 있다.
여러 서버가 동시에 명령을 날려도 synchronized 키워드를 쓴 것처럼 명령어가 묶여서 실행되기에 Atomic이 보장되는 Redis의 INCR와 같은 명령어를 사용하면 유저의 액션에 대한 즉각적인 피드백이 이루어지도록 할 수 있다.
Spring Batch 의존성 추가
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-batch'
}의존성 추가 찾는 방법
문득 새 프레임워크를 사용할 때 이런 의존성 추가는 어디에서 찾아 보는걸까 하는 궁금증이 들어 검색해봤다.
spring-boot-starter-* 형태를 가진 공식에서 제공되는 스타터는 Spring 문서의 Build systems - starters 항목을 통해서 확인 할 수 있다.
또, 해당 의존성의 공식 홈페이지를 참고하거나 Spring Initializr에서 의존성을 추가하고 Explore로 확인하거나 확인할 수 있다고 했다.
나는 이 중에서 프로젝트의 버전에 맞는 의존성 추가문을 볼 수 있기 때문에, Sping Initializr를 가장 자주 사용할 것 같다.
BatchConfig 파일 생성
@Configuration
@EnableBatchProcessing
public class BatchConfig {
}Jop 메서드 추가
package com.sparta.omin.common.config;
import com.sparta.omin.app.model.review.repos.ReviewRepository;
import com.sparta.omin.app.model.stats.entity.StoreRatingStat;
import com.sparta.omin.app.model.stats.repos.StoreRatingStatRepository;
import jakarta.persistence.EntityManagerFactory;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.data.RepositoryItemReader;
import org.springframework.batch.item.data.builder.RepositoryItemReaderBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.domain.Sort;
import org.springframework.transaction.PlatformTransactionManager;
import java.util.Collections;
import java.util.UUID;
@Configuration
@RequiredArgsConstructor
public class StoreRatingBatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final EntityManagerFactory entityManagerFactory;
private final StoreRatingStatRepository statRepository;
private final ReviewRepository reviewRepository;
@Bean
public Job updateStoreRatingJob() {
return new JobBuilder("updateStoreRatingJob", jobRepository)
.start(updateStoreRatingStep())
.build();
}
@Bean
public Step updateStoreRatingStep() {
return new StepBuilder("updateStoreRatingStep", jobRepository)
.<UUID, StoreRatingStat>chunk(100, transactionManager) // 100개씩 묶어서 처리
.reader(storeIdReader())
.processor(storeRatingProcessor())
.writer(storeRatingWriter())
.build();
}
/**
* 1. ItemReader: 평점 계산이 필요한 Store ID들을 읽어옴
* (최근 리뷰가 달린 가게들만 조회하도록 Query를 짤 수도 있습니다)
*/
@Bean
public RepositoryItemReader<UUID> storeIdReader() {
// 여기서는 예시로 모든 Store ID를 읽어오는 방식을 취합니다.
// 실제로는 '최근 1시간 내 리뷰가 수정/삭제된 StoreID'만 가져오는 것이 효율적입니다.
return new RepositoryItemReaderBuilder<UUID>()
.name("storeIdReader")
.repository(reviewRepository) // ReviewRepository에 Custom Query 필요
.methodName("findDistinctStoreIdsWithRecentReviews")
.pageSize(100)
.sorts(Collections.singletonMap("id", Sort.Direction.ASC))
.build();
}
/**
* 2. ItemProcessor: 해당 Store의 모든 리뷰를 읽어 통계 객체 생성
*/
@Bean
public ItemProcessor<UUID, StoreRatingStat> storeRatingProcessor() {
return storeId -> {
// 해당 가게의 삭제되지 않은 모든 리뷰 평점 집계
// List<Double> ratings = reviewRepository.findAllRatingsByStoreId(storeId);
// double avg = ratings.stream().mapToDouble(Double::doubleValue).average().orElse(0.0);
// long count = ratings.size();
// 신규 StoreRatingStat 객체를 만들거나 기존 것을 업데이트해서 반환
// (기존 Entity의 update 메서드 활용)
return calculatedStat;
};
}
/**
* 3. ItemWriter: DB에 일괄 저장 (Bulk Update)
*/
@Bean
public ItemWriter<StoreRatingStat> storeRatingWriter() {
return chunk -> statRepository.saveAll(chunk.getItems());
}
}0. updateStoreRatingJob
@Bean
public Job updateStoreRatingJob() {
return new JobBuilder("updateStoreRatingJob", jobRepository)
.start(updateStoreRatingStep())
.build();
}새 Job을 생성하고 start()를 통해 첫 step을 updateStoreRatingStep()으로 등록한다.
1. updateStoreRatingStep
@Bean
public Step updateStoreRatingStep() {
return new StepBuilder("updateStoreRatingStep", jobRepository)
.<UUID, StoreRatingStat>chunk(100, transactionManager) // 100개씩 묶어서 처리
.reader(storeIdReader())
.processor(storeRatingProcessor())
.writer(storeRatingWriter())
.build();
}데이터 읽기/가공/저장 3대장을 등록한다.
- <>chunk
- processor
- writer
2. storeIdReader()
storeIdReader
// 최근 10분 내 리뷰가 수정/삭제된 StoreID 가져오기
@Bean
public RepositoryItemReader<UUID> storeIdReader() {
LocalDateTime timeAgo = Loca lDateTime.now().minusMinutes(10).minusSeconds(5); // 누락 방지
return new RepositoryItemReaderBuilder<UUID>()
.name("recentActiveStoreIdReader")
.repository(reviewRepository)
.methodName("findDistinctStoreIdsByUpdatedAtAfter")
.arguments(Collections.singletonList(timeAgo)) //시간 파라미터 주입
.pageSize(100)
.sorts(Collections.singletonMap("store.id", Sort.Direction.ASC))
.build();
}reviewRepository 의 findDistinctStoreIds[ByUpdatedAt]After() 쿼리 메서드를 통해
배치스케줄 주기(1시간) 동안 생성/수정/삭제된 Store의 ID를 찾아올 수 있다.
배치 주기동안 생성/수정/삭제를 알 수 있는 플래그 : UpdatedAt
시스템에서 평점이 변하는 시점 = 리뷰의 생성/수정/삭제(soft delete) = UpdatedAt Audit 가 동작한다.
ReviewRepository
public interface ReviewRepository extends JpaRepository<Review, UUID> {
// 최근 특정 시간 이후에 변경(등록/수정/삭제)된 리뷰가 있는 가게 ID 목록 조회
@Query("SELECT DISTINCT r.store.id FROM Review r WHERE r.updatedAt >= :since")
Page<UUID> findDistinctStoreIdsByUpdatedAtAfter(@Param("since") LocalDateTime since, Pageable pageable);
// 전체 가게 ID 조회 (기본용-선택)
@Query("SELECT DISTINCT r.store.id FROM Review r")
Page<UUID> findAllDistinctStoreIds(Pageable pageable);
}3. ItemProcessor (계산 로직)
@Bean
public ItemProcessor<UUID, StoreRatingStat> storeRatingProcessor() {
return storeId -> {
// 1. 해당 가게의 모든 (삭제되지 않은) 리뷰 점수를 가져옴
List<Double> ratings = reviewRepository.findRatingsByStoreIdAndIsDeletedFalse(storeId);
if (ratings.isEmpty()) return null; // 리뷰가 다 삭제된 경우 등 예외처리
// 2. 통계 계산
long totalReview = ratings.size();
double totalSum = ratings.stream().mapToDouble(Double::doubleValue).sum();
double avgRating = totalSum / totalReview;
// 3. 기존 통계 엔티티 조회 또는 생성
StoreRatingStat stat = statRepository.findByStoreId(storeId)
.orElse(StoreRatingStat.create(storeId, 0));
// 4. 데이터 업데이트 (엔티티 내부 메서드 활용)
// StoreRatingStat에 배치용 업데이트 메서드를 추가하면 좋습니다.
stat.updateFullStat(totalReview, totalSum, avgRating);
return stat;
};
}성능 개선 ver (DB안에서 계산)
@Query("SELECT COUNT(r), SUM(r.rating) FROM Review r " +
"WHERE r.store.id = :storeId AND r.isDeleted = false")
Object[] countAndSumByStoreId(@Param("storeId") UUID storeId);@Bean
public ItemProcessor<UUID, StoreRatingStat> storeRatingProcessor() {
return storeId -> {
// 1. DB에서 해당 가게의 '진짜' 통계 정보를 한 줄로 가져옴 (성능 최적화)
Object[] result = (Object[]) reviewRepository.countAndSumByStoreId(storeId);
long realCount = (long) result[0];
double realSum = (result[1] != null) ? (double) result[1] : 0.0;
// 2. 기존 통계 테이블 정보를 가져옴
StoreRatingStat stat = statRepository.findByStoreId(storeId)
.orElseGet(() -> StoreRatingStat.create(storeId, 0));
// 3. '차이'를 더하는 게 아니라, 실제 리뷰 데이터 기준으로 '동기화'
stat.syncStat(realCount, realSum);
return stat;
};
}이미 테이블에 총점이 있는데 왜 다시 계산하느냐고 물으신다면, 배치는 "정기 점검"이기 때문입니다.
데이터 정합성 보장: 실시간 로직(increase)에서 아주 드문 확률로 레이스 컨디션이 발생해 값이 꼬였을 때, 배치가 돌면서 실제 리뷰 개수를 세어 값을 완벽하게 교정합니다.
동시성 문제 해방: ReviewService에서 평점을 실시간으로 업데이트할 때는 비관적 락(withLock)이 필요하지만, 배치 실행 중에는 락을 걸지 않고 계산한 뒤 마지막에 Writer에서 한 번에 업데이트하므로 훨씬 가볍습니다.
단순함: updateRatingByDiff처럼 차이값을 계산할 필요 없이, "현재 상태"를 "실제 상태"와 맞추기만 하면 됩니다. (-> 내...내가 이걸 몇 시간을 들여서 만든건데...🥺)
4. ItemWrite
@Bean
public RepositoryItemWriter<StoreRatingStat> storeRatingWriter() {
return new RepositoryItemWriterBuilder<StoreRatingStat>()
.repository(statRepository)
.methodName("save") // saveAll로 동작함
.build();
}설정된 Job을 실행하기
Scheduler
@Component
@RequiredArgsConstructor
public class StoreRatingScheduler {
private final JobLauncher jobLauncher;
private final Job updateStoreRatingJob;
@Scheduled(cron = "0 0/10 * * * *") // 10분마다 실행
public void runUpdateRatingJob() {
try {
JobParameters params = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(updateStoreRatingJob, params);
} catch (Exception e) {
log.error("Batch Job 실행 중 에러 발생: {}", e.getMessage());
}
}
}Reader 와 Scheduler 의 주기 일치시키기
크론 스케줄 표기
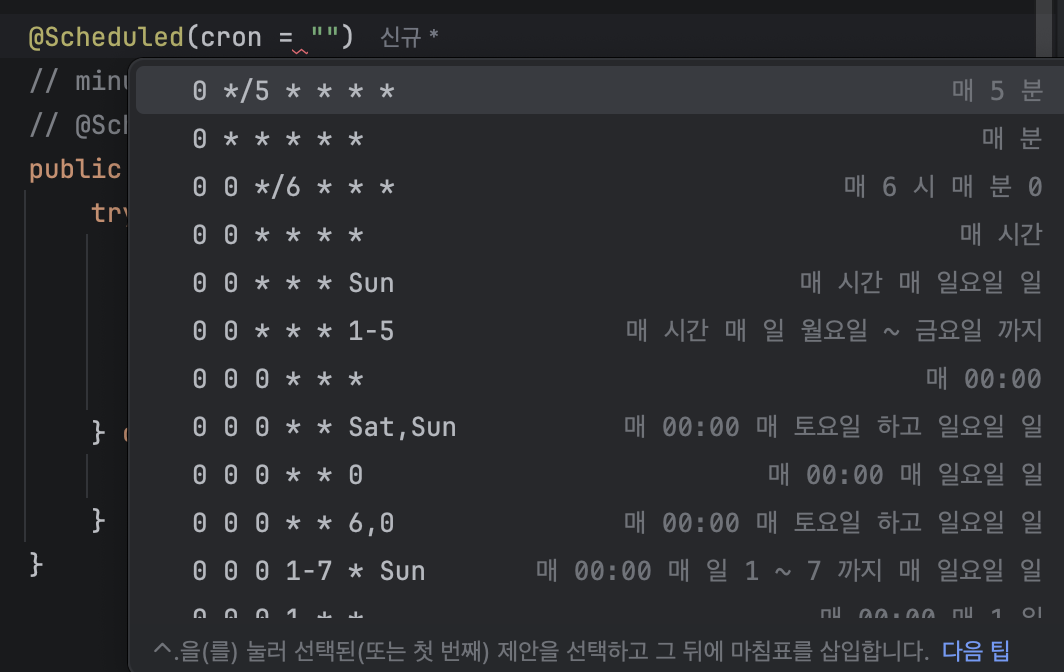
| 스케줄러 주기 (Cron) | Reader 조회 범위 (minus...) | 비고 |
|---|---|---|
| 0 0 * * * * (매 시간) | LocalDateTime.now().minusHours(1) | 가장 표준적인 방식 |
| 0 0/10 * * * * (10분마다) | LocalDateTime.now().minusMinutes(10) | 실시간성이 높을 때 |
| 0 0/30 * * * * (30분마다) | LocalDateTime.now().minusMinutes(35) | 안전빵 (추천) |
위 표와 같이 배치 주기를 스케줄러와 Reader에서 쿼리 메서드에 넣어주는 변수와 같게 맞추는 것이 맞지만,
배치 실행 시간이나 서버 간의 미세한 시간 차이 때문에 딱 맞춰 설정하면 1~2초 차 로 데이터를 놓칠 수 있어 쿼리 변수 실행 주기보다 아주 살짝 길게 설정해준다.
// 예: 10분마다 실행되는 배치라면
LocalDateTime window = LocalDateTime.now().minusMinutes(11); // 1분의 여유를 둠또, 지난번 배치가 성공한 시간"을 DB(Batch Meta Table)에서 꺼내와서 그 시간 이후의 데이터를 조회하는 JobParameter 방법도 있다.
Reader에 사용된 LocalDateTime.now()
// 최근 10분 내 리뷰가 수정/삭제된 StoreID 가져오기
@Bean
@StepScope // 중요: 배치가 실행될 때마다 빈을 새로 생성함
public RepositoryItemReader<UUID> storeIdReader(@Value("#{jobParameters['requestDate']}") String requestDate // 실행 시점 파라미터를 받을 수도 있음
) {
LocalDateTime timeAgo = LocalDateTime.now().minusMinutes(10).minusSeconds(5); // 누락 방지
return new RepositoryItemReaderBuilder<UUID>()
.name("recentActiveStoreIdReader")
.repository(reviewRepository)
.methodName("findDistinctStoreIdsByUpdatedAtAfter")
.arguments(Collections.singletonList(timeAgo)) //시간 파라미터 주입
.pageSize(100)
.sorts(Collections.singletonMap("store.id", Sort.Direction.ASC))
.build();
}@StepScope 또는
jobParameters 를 사용해야한다.
@Value("#{jobParameters['requestDate']}"jobParameters는 두 가지 방식으로 채울 수 있다.
Scheduler 에게 부탁하기
@Component
@RequiredArgsConstructor
public class StoreRatingScheduler {
private final JobLauncher jobLauncher;
private final Job updateStoreRatingJob;
@Scheduled(cron = "0 0/10 * * * *") // 10분마다 실행
public void runJob() {
try {
// 여기가 '주문서' 작성하는 곳입니다!
JobParameters params = new JobParametersBuilder()
.addString("requestDate", LocalDateTime.now().toString()) // 이 값이 #{jobParameters['requestDate']}로 들어감
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
jobLauncher.run(updateStoreRatingJob, params);
} catch (Exception e) {
// 에러 처리
}
}
}2. jar 파일 실행 시 부여
$ java -jar omin-app.jar --spring.batch.job.name=updateStoreRatingJob requestDate=2024-03-11왜 굳이 이걸 써야 하나요? (중요!)
스프링 배치에는 "똑같은 일은 두 번 하지 않는다"는 고집스러운 철학이 있습니다.
중복 실행 방지: 스프링 배치는 Job 이름 + JobParameters를 합쳐서 하나의 ID(JobInstance)를 만듭니다.
만약 10시에 배치가 성공했는데, 10시 1분에도 똑같은 파라미터로 배치를 돌리려고 하면? 스프링 배치는 "이미 성공한 기록이 있는데 왜 또 해? 안 해!"라며 거절합니다.
그래서 매번 실행할 때마다 LocalDateTime.now()나 timestamp 같은 '계속 변하는 값'을 파라미터로 넣어줘서 "이건 아까랑 다른, 새로운 실행이야!"라고 알려주는 거예요.
application batch 설정
# 배치 관련 설정:
spring:
batch:
jdbc:
initialize-schema: always # 배치에 필요한 테이블(실행 이력) 없으면 생성
job:
enabled: false # 서버 켜자마자 배치 여부정리- 하나의 Job 내부 구성 (Chunk 방식)
우리가 작성한 updateStoreRatingJob은 다음과 같은 3단계 레이어로 구성된다.
ItemReader:
최근배치주기시간내 리뷰 변화가 있는 Store ID 목록을 페이징하여 읽어옴.
-
ItemProcessor:
읽어온 각 Store ID에 대해 실제 평균 평점과 리뷰 개수를 계산. -
ItemWriter:
계산된 결과를p_store_rating_stat테이블에 일괄 업데이트(Bulk Update).
만약 Step을 더 추가한다면? (확장성)
하나의 Job 안에 여러 개의 Step을 두어 처리 단계를 나눌 수 있다.
만약 이 작업에 Step을 더 추가하면 다음 기능을 고려해볼 수 있다.
Step 1 (집계): 가게별 평점 계산 및 DB 반영 (updateStoreRatingJob)
Step 2 (캐시 갱신): 평점이 변경된 가게들의 정보를 Redis 캐시에서 삭제하거나 갱신
Step 3 (알림): 평점이 급격히 하락한 가게 주인에게 경고 알림 발송
고려해야 할 '배치 운영' 포인트
Job 하나로 끝내기 위해 다음 사항들을 체크해보세요.
멱등성(Idempotency): 배치가 중간에 실패해서 다시 돌려도 결과가 같아야 합니다. (전체 리뷰 기반 재계산 방식은 멱등성이 보장되므로 안전합니다.)
Job Parameter: 배치를 수동으로 실행할 때도 대비해 run.date 같은 파라미터를 받을 수 있게 설정해야 합니다.
트랜잭션 관리: Chunk 단위(예: 100개 가게)로 트랜잭션이 커밋되므로, 중간에 에러가 나도 앞선 100개는 안전하게 저장됩니다.
테스트
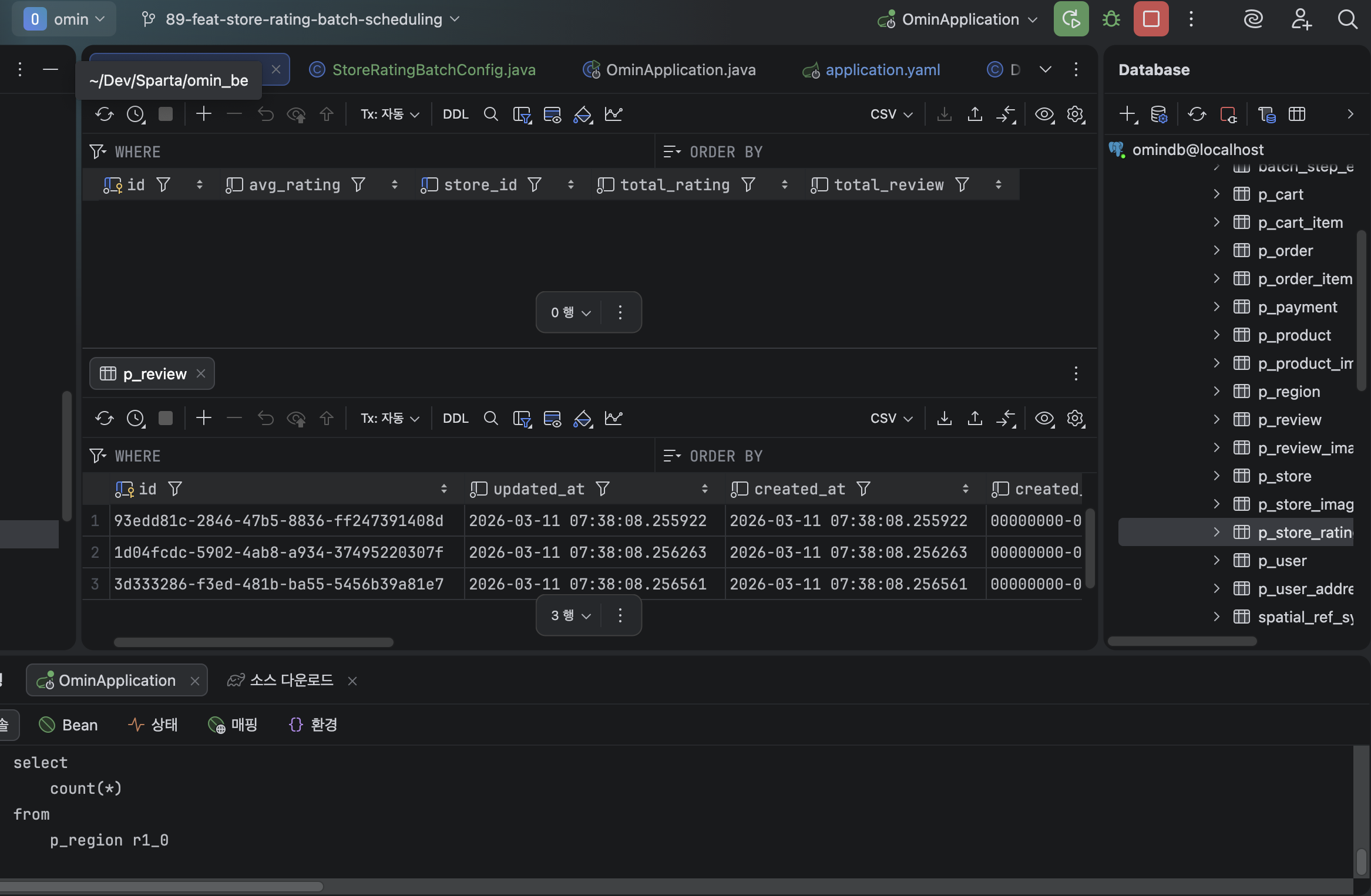
Spring DataInitalizer로 SpringBoot 실행시 리뷰 데이터가 생성되어 UpdatedAt이 실행 시간으로 생성 된다.
현재 가게별 별점 통계를 만들지 않아 통계 테이블은 데이터가 들어있지 않다.
그 사이 리뷰 데이터 하나를 날려준다.
soft delete 가 되어 UpdatedAt이 변경된 상태로 DB에 남게 된다.
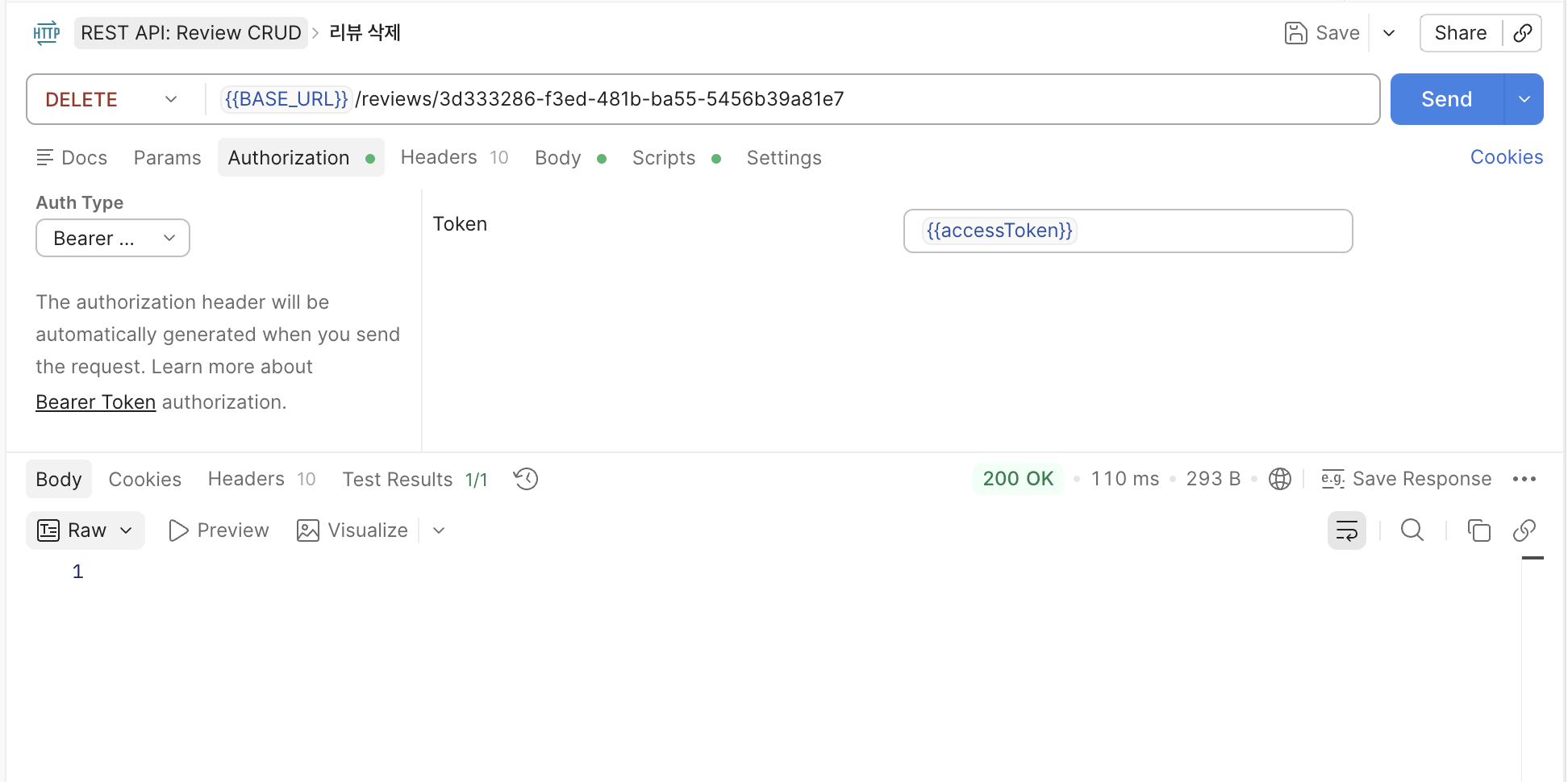
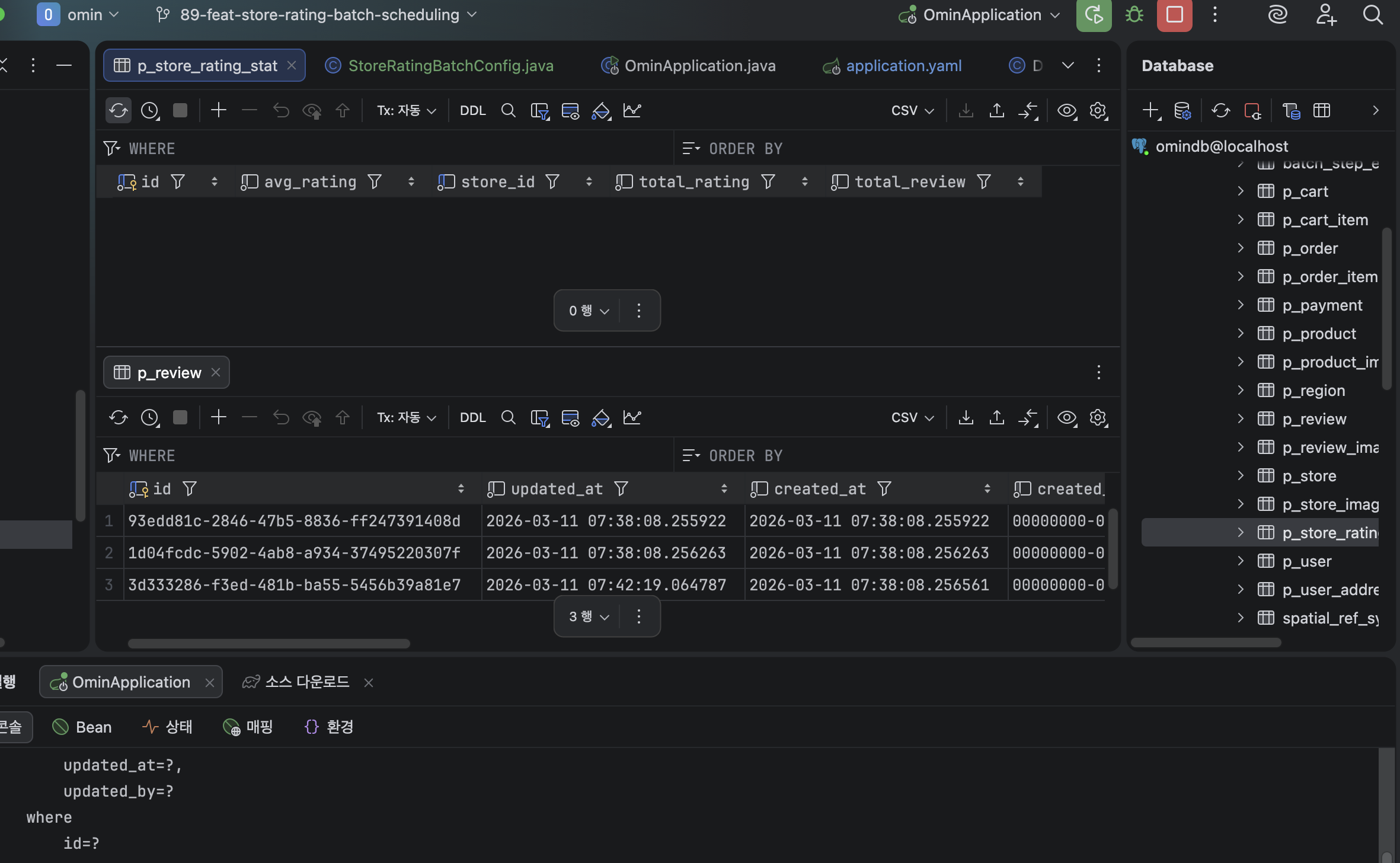
...? 이 정도면 좀 되야하는거 아닌가요 ...!!
