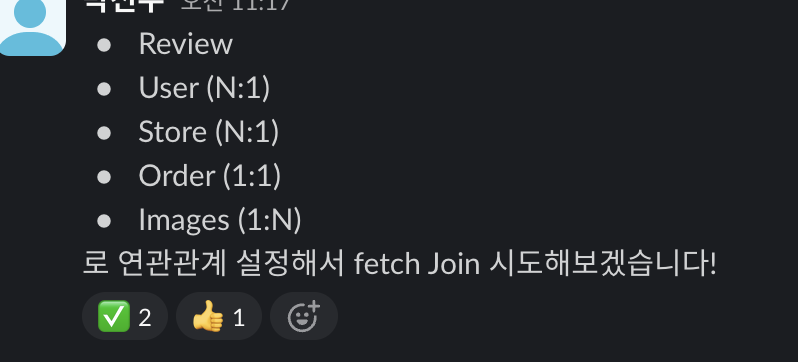
[문제 해결] 리뷰 목록에 닉네임 띄우기: (N+1 문제)
리뷰 화면엔 당연히 닉네임이 있어야지!
public record ReviewResponse(
UUID reviewId,
UUID orderId,
UUID userId,
String nickname, // <-- 문제의 시작 🥲
double rating,
String comment,
List<String> images,
LocalDateTime createdAt,
LocalDateTime updatedAt
) {}Review 도메인의 CREATE API 명세서를 다시 작성하면서 아주 자연스럽게 생각했다.
"아, 리뷰 화면엔 당연히 작성자 닉네임이 보여야지!"
API 명세서를 수정하고 개발을 진행하는데,
앞서 리뷰를 생성할 때는 로그인한 유저의 정보를 Security Context에서 가져와서 넣으면 되니까 Review - User 엔티티 사이의 연관 관계를 깊게 고민할 일이 없었다.
조회될 리뷰와 로그인한 유저는 아무 관련이 없다 🤯
문제를 깨달은 건 조회 기능을 구현할 때였다.
리뷰는 쇼핑몰의 상품 페이지처럼 로그인하지 않은 사용자도 볼 수 있어야 했다.
우리 프로젝트의 구조상, MSA 확장을 염두에 두고 테이블이 서로를 직접 참조하지 않도록(JPA 연관관계를 맺지 않도록) 했기 때문에, Review가 가진 userId를 통해 User 객체를 따로 찾아와야만 했다.
| 서비스 계층에서 조회 로직 흐름 |
|---|
1. reviewRepository.findById(reviewId) ➔ review.userId 획득 |
2. userRepository.findById(review.userId) ➔ user.nickname 획득 |
만약 리뷰 목록 10개를 조회한다면
닉네임 정보 '하나' 때문에
리뷰 10개 조회 (1번) ×
→ user 조회 (10번)
을
해야 한
다
고...?드디어 N+1 문제를 정면으로 마주했다😭
모놀리식(Monolithic) 환경에서의 해결 방법
아직은 하나의 DB를 사용하는 모놀리식 아키텍처라서,
흔히 알려진 N+1 해결 방법들을 적용해 볼 수 있다.
1. Join Query와 DTO 직접 조회 (Projection)
가장 직관적인 방법은 처음부터 연관된 테이블을 조인해서 DTO로 바로 퍼올리는 것이다. JPA 연관관계가 없어도 on 절을 통해 조인이 가능하다.
@Query("""
select new com.project.dto.ReviewResponse(
r.id,
r.orderId,
r.userId,
u.nickname,
r.rating,
r.comment,
r.createdAt,
r.updatedAt
)
from Review r
join User u on r.userId = u.id
where r.id = :reviewId
""")
Optional<ReviewResponse> findReviewResponse(UUID reviewId);2. Fetch Join 사용 (※ 주의점)
일반적인 모놀리스 환경에서 엔티티 간에 JPA 연관관계(@ManyToOne 등)가 잘 매핑되어 있다면, Fetch Join을 사용해 영속성 컨텍스트에 한 번에 끌고 올 수 있다.
@Query("""
select r from Review r
join fetch r.user u
""")
List<Review> findAllReviewsWithUser();💡 주의: MSA를 대비해 엔티티 간의 연관관계 매핑(
@ManyToOne)을 명시적으로 끊어둔 상태라면, JPA 문법상fetch join은 사용할 수 없다!+ MultipleBagFetchException
bag(List) 컬렉션을 두 개 이상 포함된 엔티티로 1:N 컬렉션을 두 개 이상 동시에 fetch join 하면 결과가 폭발적으로 중복되어 (카테시안 곱 발생) JPA (Hibernate)가 막아버리는 경우가 많다고 한다. 실무에서는 해결 방법 정리 연관된 컬렉션 중 하나만
fetch join하고, 나머지는 다른 쿼리로 별도 조회하거나 IN 쿼리로 모아서 쿼리하도록 하는 BatchSize라는 것을 사용한다.3. 목록을 모아서 한 번에 조회 (IN 절 활용)
연관관계가 없는 현재 구조에서 가장 현실적인 방법이다. 리뷰 목록을 먼저 조회하고, 거기서
userId만 추출해 한 번에 회원을 조회한 뒤 애플리케이션 단에서 조립하는 방식이다.
List<Review>조회- 스트림을 돌며
List<userId>추출 userRepository.findAllByIdIn(userIds)로 한 번에 조회 (IN 쿼리 1번 발생)- 조회된 User 리스트를
Map<UUID, String>형태로 변환하여 리뷰 DTO에 닉네임 매핑
만약 MSA 환경이라면? (N+1 네트워크 문제)
처음엔 "어차피 지금은 모놀리스니까 IN 절 쿼리로 처리하자" 싶었다. 그런데 문득 궁금해졌다. 데이터베이스가 분리된 MSA(Microservices Architecture) 환경에서는 이런 N+1 요청을 어떻게 처리할까?
1. API Composition (실시간 조회 방식)
가장 단순한 접근은 Review 서비스가 User 서비스의 API를 직접 호출해서 데이터를 조립하는 것이다.
Client
↓
Review Service
↓ (API 호출)
User Service하지만 이 방식을 목록 조회에 그대로 사용하면 모놀리스의 N+1 쿼리 문제가 네트워크 N+1 문제로 바뀐다.
- 네트워크 호출이 10번 발생하여 지연 시간(Latency) 증가
- User 서비스에 장애가 나면 Review 조회도 실패함 (의존성 결합)
- 트래픽이 몰릴 때 대량 호출로 인한 연쇄 장애 위험
2. MSA - Batch API 요청
모놀리스에서 findAllByIdIn()을 썼던 것처럼, API 호출도 한 번에 모아서 처리하는 방법이다.
POST /users/batch
Content-Type: application/json
{
"userIds": ["uuid-1", "uuid-2", "uuid-3"]
}Review 서비스에서 필요한 userId 목록을 배열로 묶어 User 서비스에 한 번만 요청(Batch API)하면, 네트워크 호출 비용을 획기적으로 줄일 수 있다.
처음 안드로이드 프로젝트를 할 때 NoSQL인 FireBase를 DB로 사용할 때 썼던 방법으로 기억한다. 그 때는 리스트 자료형도 잘 모른 상태로 개발에 뛰어들었는데 새삼 대단하게 느껴진다.
3. 스냅샷 정보(데이터 복제)와 이벤트 기반 동기화
매번 다른 서비스를 호출하는 것 자체가 부담스럽다면, 아예 Review DB에 닉네임 컬럼을 들고 있는 방법도 있다. (역정규화)
// Review 테이블에 nickname 컬럼 추가
@Column(name = "nickname")
private String nickname;리뷰를 작성할 당시의 닉네임을 스냅샷처럼 저장하는 것인데, 유저가 나중에 닉네임을 변경한다면? 이때 이벤트 브로커(Kafka, RabbitMQ 등)를 활용한다.
- User가 닉네임 변경
- User 서비스가
UserNicknameChangedEvent메시지 발행 - Review 서비스가 해당 이벤트를 수신 (구독)
- Review 테이블의
nickname컬럼 업데이트
데이터가 실시간으로 일치하지 않는 약간의 지연은 발생하겠지만, 결과적으로 일관성이 맞춰지는 최종 일관성(Eventual Consistency)을 챙기면서 서비스 간의 결합도를 크게 낮출 수 있다.
정리
현재 프로젝트의 규모와 요구사항(성능 vs 데이터의 실시간 정합성)에 따라 적절한 트레이드오프를 선택하는 것이 중요한 것 같다.
| 방식 | 쿼리 수 | 네트워크 | 코드 복잡도 | 일관성 | 확장성 |
|---|---|---|---|---|---|
| Fetch Join | 1 | x | 낮음 | (즉시) | 의존성 높음 |
| IN 조회 | 2 | x | 중간 | (즉시) | 중간 |
| MSA Batch | 2 + 네트워크 | o | 높음 | (실시간) | 높음 |
| MSA Event-Driven | 1 | △ | 매우 높음 | 약함 (Eventually) | 매우 높음 |
Review Read 구현하기
응답 DTO
@Builder
public record ReviewResponse(
UUID reviewId,
UUID orderId,
UUID userId,
String nickname,
double rating,
String comment,
List<String> images,
LocalDateTime createdAt,
LocalDateTime updatedAt
) {
public static ReviewResponse of(Review review, String nickname) {
return ReviewResponse.builder()
.reviewId(review.getId())
.orderId(review.getOrderId())
.userId(review.getUserId())
.nickname(nickname)
.rating(review.getRating())
.comment(review.getComment())
.images(review.getImages().stream()
.map(ReviewImage::getImageUrl)
.toList())
.createdAt(review.getCreatedAt())
.updatedAt(review.getUpdatedAt())
.build();
}
}목록 조회 DTO는 단일 응답을 감싸는 객체로 만들어준다.
package com.sparta.omin.app.model.review.dto;
import java.util.List;
public record ReviewListResponse(
List<ReviewResponse> reviews
) {
public static ReviewListResponse of(List<ReviewResponse> reviews) {
return new ReviewListResponse(reviews);
}
}
1. Service (IN 조회 방식- MSA Batch API 대응)
@Transactional(readOnly = true)
public ReviewResponse getReview(UUID reviewId) {
Review review = reviewRepository.findById(reviewId)
.orElseThrow(() -> new ApiException(ErrorCode.REVIEW_NOT_FOUND));
User user = userRepository.findById(review.getUserId())
.orElseThrow(() -> new ApiException(ErrorCode.USER_NOT_FOUND));
return ReviewResponse.of(review, user.getNickname());
}
@Transactional(readOnly = true)
public ReviewListResponse getReviews() {
List<Review> reviews = reviewRepository.findAll();
// userId 모으기
List<UUID> userIds = reviews.stream()
.map(Review::getUserId)
.distinct()
.toList();
// User 한번에 조회
List<User> users = userRepository.findAllById(userIds);
Map<UUID, String> nicknameMap =
users.stream()
.collect(Collectors.toMap(User::getId, User::getNickname));
// DTO 변환
List<ReviewResponse> responses = reviews.stream()
.map(review -> ReviewResponse.of(
review,
nicknameMap.get(review.getUserId())
))
.toList();
return ReviewListResponse.of(responses);
}2. JPQL 일반 ON Join + DTO Projection
아직은 모놀리스 환경이기도 하고, IN 절을 써서 애플리케이션 단에서 조립하는 방식은 코드가 길어져서 가독성이 조금 아쉬웠다.
그래서 결국 조인(Join)으로 해결하기로 결정했다!
DB에서 엔티티 대신 DTO로 바로 퍼올리기 (Projection)
JPQL을 사용할 때, 성능 최적화를 위해 엔티티 전체를 조회하지 않고, 딱 필요한 필드만 골라 담는 DTO Projection 방식이 있다.
- 장점: 엔티티를 거치지 않으니 영속성 컨텍스트가 관리할 필요가 없어 '읽기 전용'으로 가볍고 빠르다.
(어차피 연관관계가 없는 일반 조인이라 원래도 영속성 관리는 안 된다.) - 단점: JPQL이 무시무시하게 길어진다. 오타가 나도 런타임에 에러가 터져야만 알 수 있는 그 '문자열'... 😱
// JPQL의 눈물 겨운 패키지 풀 네임 적기...
@Query("""
select new com.xxx.ReviewResponse(
r.id,
r.orderId,
r.userId,
u.nickname,
r.rating,
r.comment,
r.createdAt,
r.updatedAt
)
from Review r
join User u on r.userId = u.id
""")JPQL : 컬렉션을 생성자 안에 바로 넣을 수 있을까...?
JPQL의 new 문법은 치명적인 단점이 있었다.
리뷰에는 리뷰 이미지 List<String> images 가 있는데, 이 컬렉션을 처리하기 까다롭다!
현재 상황을 정리해보면 이렇다:
1. 연관관계 끊어둠: 직접 조인(ON) 필요
2. 1:N 관계 포함: 리뷰 이미지(List) 처리가 필요함
3. 페이징 & 필터: 앞으로 조건이 계속 추가될 예정
이걸 문자열(JPQL)로만 다루다간 내 멘탈이 먼저 나갈 것 같았다. 그래서 결심했다. QueryDSL을 도입하기로!
QueryDSL: (잘 가요 문자열)
QueryDSL은 쿼리를 자바 코드로 작성하게 해주는 타입 안전(Type-Safe) 빌더다.
QReview r = QReview.review;
QUser u = QUser.user;
return queryFactory
.select(Projections.constructor(ReviewResponse.class,
r.id, r.orderId, r.userId, u.nickname,
r.rating, r.comment, r.createdAt, r.updatedAt))
.from(r)
.join(u).on(r.userId.eq(u.id)) // 연관관계 없어도 조인 쌉가능!
.fetch();- 컴파일 시점 체크: 오타 나면 빨간 줄이 바로 뜬다.
- IDE 자동완성:
r.만 쳐도 필드명이 다 나온다. - 동적 쿼리: 분기에 따른
where조건 추가가 쉽다.(QueryDSL이 없던 시절엔 로직마다 문자열을 더해서 구현했다고 한다.)
QueryDSL의 Projection 방식
1️⃣ constructor 방식
Projections.constructor(...)는 JPQL과 비슷하다.
생성자 파라미터 순서가 바뀌어도 컴파일러가 못 잡아서 런타임에 에러가 난다.
2️⃣ fields 방식 (record 사용불가)
Projections.fields(...)는 필드명 기준으로 매핑한다. 하지만 우리가 쓰는 record나 불변 객체에는 적합하지 않다.
Projections.fields는 내부 동작은
- 기본 생성자로 객체를 일단 생성한다.
- Java의 Reflection을 사용해서 필드에 직접 접근해 값을 주입한다.
그런데 우리가 사용한 record는 Java 14부터 도입된 불변(Immutable) 객체이다.
(class와 record의 차이를 가독성 정도로만 생각했는데 이렇게 또 공부가 된다... 공부 많이 된다~)
3️⃣ @QueryProjection (추천! 👍)
DTO 생성자에 어노테이션을 딱! 붙여주면 된다.
public record ReviewResponse(
UUID reviewId,
// ... 생략
) {
@QueryProjection // <--- 여기!
public ReviewResponse { }
}그러면 QueryDSL이 생성해주는 QReviewResponse라는 클래스를 자바 객체 만들 듯이 쓰면 된다.
queryFactory
.select(new QReviewResponse(
r.id, r.orderId, r.userId, u.nickname, // 타입과 순서가 틀리면 컴파일 에러!
r.rating, r.comment, r.createdAt, r.updatedAt
))
...모놀리스에 집중해서 JPQL fetch join만들기
각 엔티티끼리 연관 관계를 맺은 다음에, fetch join을 만들어 해결하기로 했다.
나 혼자 팀에서 엔티티 간의 연관관계 매핑(@ManyToOne)을 명시적으로 끊어둔 상태라고 착각하고 있었다🥲😂
(나.. 왜 그랬지...? 공부하면서 너무 MSA 쪽으로 관심을 둬서 그런 것 같다...)
엔티티 연관관계
지금 리뷰의 연관 관계를 정리하면 다음과 같아진다.
1. 이미지
이미지는 리뷰가 직접 들고있다 생각해서 이미 연관관계를 양방향으로 맺어놨다.
이미지중 하나가 삭제되면 리뷰의 이미지 순서 등을 바꿔줘야하기 때문에 리스트 내부의 각각의 이미지 순서 필드를 리뷰가 관리하는 1:N 양방향 관계가 되어야 한다.
찾아보니 JPA가 순서를 관리해주는 @OrderColumn 도 있다고 한다.
@OneToMany(mappedBy = "review", cascade = CascadeType.ALL, orphanRemoval = true)
private List<ReviewImage> images = new ArrayList<>(); @ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "review_id")
private Review review;
2. 주문
리뷰는 주문 마다 생성할 수 있다.
주문 로직이 리뷰를 볼 일은 없으므로 1:1 단방향 관계를 맺는다.
@JoinColumn(name = "order_id", nullable = false, updatable = false)
@OneToOne(fetch = FetchType.LAZY)
private Order order;3. 가게
가게별로 리뷰를 조회해오기 위해 리뷰:가게 N:1 단방향 관계를 가진다.
@JoinColumn(name = "store_id", nullable = false, updatable = false)
@ManyToOne(fetch = FetchType.LAZY)
private Store store;삽질 +1
양방향 관계를 남용하지 말자
리뷰 작성 시 자신의 가게라면 리뷰를 허용하지 않는 비즈니스 로직이 있고,
가게별 리뷰를 조회하기 때문에 N:1 양방향 관계를 맺는다.
양방향 관계를 맺게 되면 사장님은 '오늘 들어온 신규 주문 1건'만 보고 싶은데,
서버는 아무 필터링 없이 '3년 전 완료된 주문'까지 몽땅 다 탐색하는 쿼리를 날린다.즉, 엔티티 안에 있는 List orders를 호출하는 순간, Hibernate는 내부적으로
SELECT * FROM orders WHERE store_id = ?;Store에 연결된 Order를 다 가져오라는 쿼리를 보낸다.
(
@Where()로 엔티티 연관에 고정된 조건을 걸어줄 순 있긴 하다.
-> 이건 soft delete 조회할 때 사용하면 좋겠다.)삽질 +2
엔티티를 먼저 짠 다음에 쿼리를 생각하자
주문 - 가게?
주문을 조회할 때 가게를 한 번에 가져와 자신의 가게에 리뷰를 남기는 것을 막는 로직에 사용할 수 있도록 연관관계를 추가했다.
주문은 항상 가게 정보를 가지고있으니 주문:가게 = N:1양방향 관계를 맺어주었다.생각해보니 이건 쿼리 최적화를 먼저 생각하고 엔티티를 짜게 된 것인데
엔티티를 먼저 짠 다음에 쿼리 최적화를 해야할지 아니면 정답은 없는지도 궁금해졌다.-> 결국 틀렸다!!@ManyToOne @JoinColumn(name = "store_id", nullable = false, updatable = false) private Store store;@OneToMany(mappedBy = "store", cascade = CascadeType.ALL, orphanRemoval = true) private List<Order> orders = new ArrayList<>();그러고 커밋을 했는데 생각해보다 아차 싶었다.
common영역이 아닌, 내가 맡은 도메인 외의 코드를 건드린 것이 처음이라 말씀을 드려야하는게 맞으려나..? 싶었다. 참고를 부탁드리기 위해 슬랙으로 메시지를 보냈다. (흑역사+1)
팀원과 협업할 땐 어떤 것을 어디까지 노티해야 하는지 튜터님께 물어봐야겠다.
4. 유저
리뷰에서 닉네임 정보를 표시하기 위해 user와 1:N 단방향 관계를 맺는다.
@JoinColumn(name = "user_id", nullable = false, updatable = false)
@ManyToOne(fetch = FetchType.LAZY)
private User user;정리
관계 설정에 따르면 결과적으로 두 개의 파일만 건드려야 한다.
- 리뷰
- ManyToOne 가게
- ManyToOne 유저
- OneToOne 주문
- (OneToMany images) *완료
- 주문
- ManyToOne 가게
- ManyToOne 유저
단일 리뷰 조회
fetch join
manual JPQL
public interface ReviewRepository extends JpaRepository<Review, UUID> {
boolean existsByOrder_IdAndIsDeletedFalse(@NotNull UUID id);
@Query("select r from Review r " +
"join fetch r.user " +
"join fetch r.order " +
"left join fetch r.images " + // 이미지는 없을 수도 있으므로 left join
"where r.id = :reviewId and r.isDeleted = false")
Optional<Review> findByIdAndIsDeletedFalse(@Param("reviewId") UUID reviewId);
}@EntityGraph
/* 실제 나가게되는 쿼리문
select ...
from p_review r
left outer join p_user u on ...
left outer join p_order o on ...
left outer join p_review_image i on ...
where r.id = ? ... and ... false
* */
@EntityGraph(attributePaths = {"user", "order", "images"})
Optional<Review> findByIdAndIsDeletedFalse(@Param("reviewId") UUID reviewId); @EntityGraph의 동작 방식
JPA 표준 사양에서 Entity Graph는 기본적으로 LEFT OUTER JOIN을 사용하도록 설계되어 이미지가 없을 때 처리까지 해준다.
- 26.03.06 튜터님 피드백으로 Entity Graph도 설정 방식에 따라 날아가는 쿼리문이 달라지기 때문에 우선 fetch join에 익숙해 진 후 사용하기를 권장 하셨다.
테스트
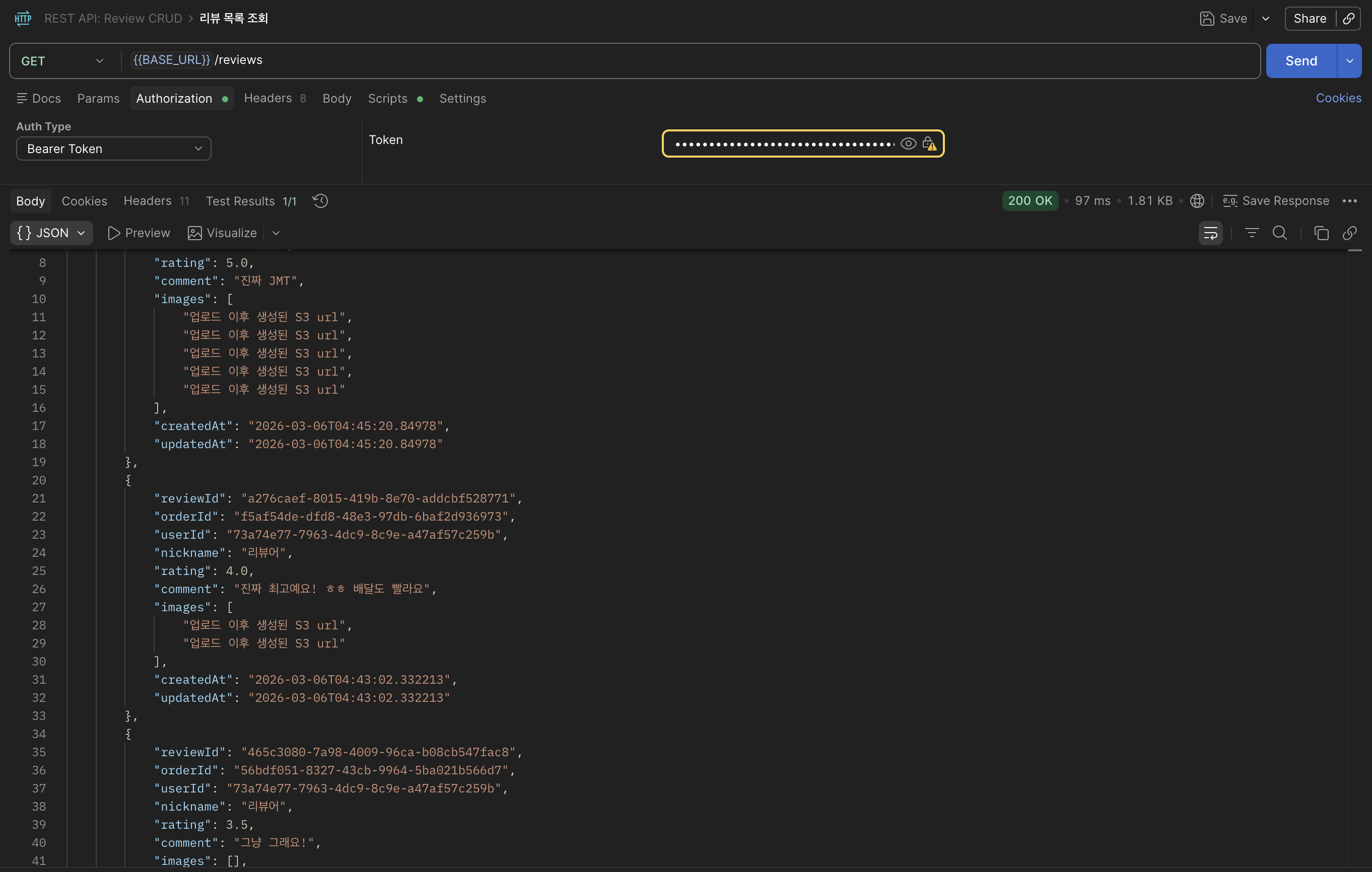
사진 없이 :
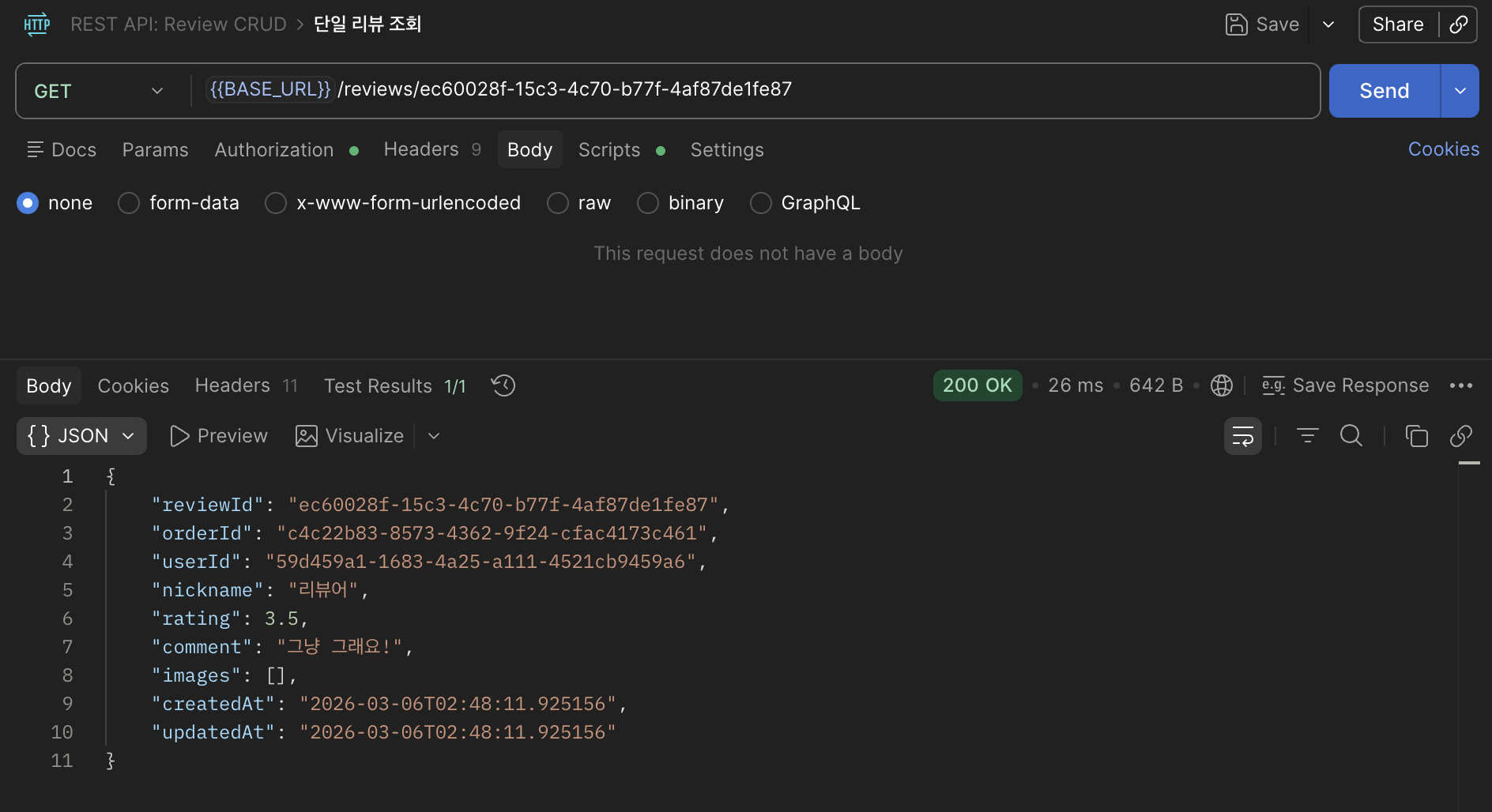
사진 있이 :
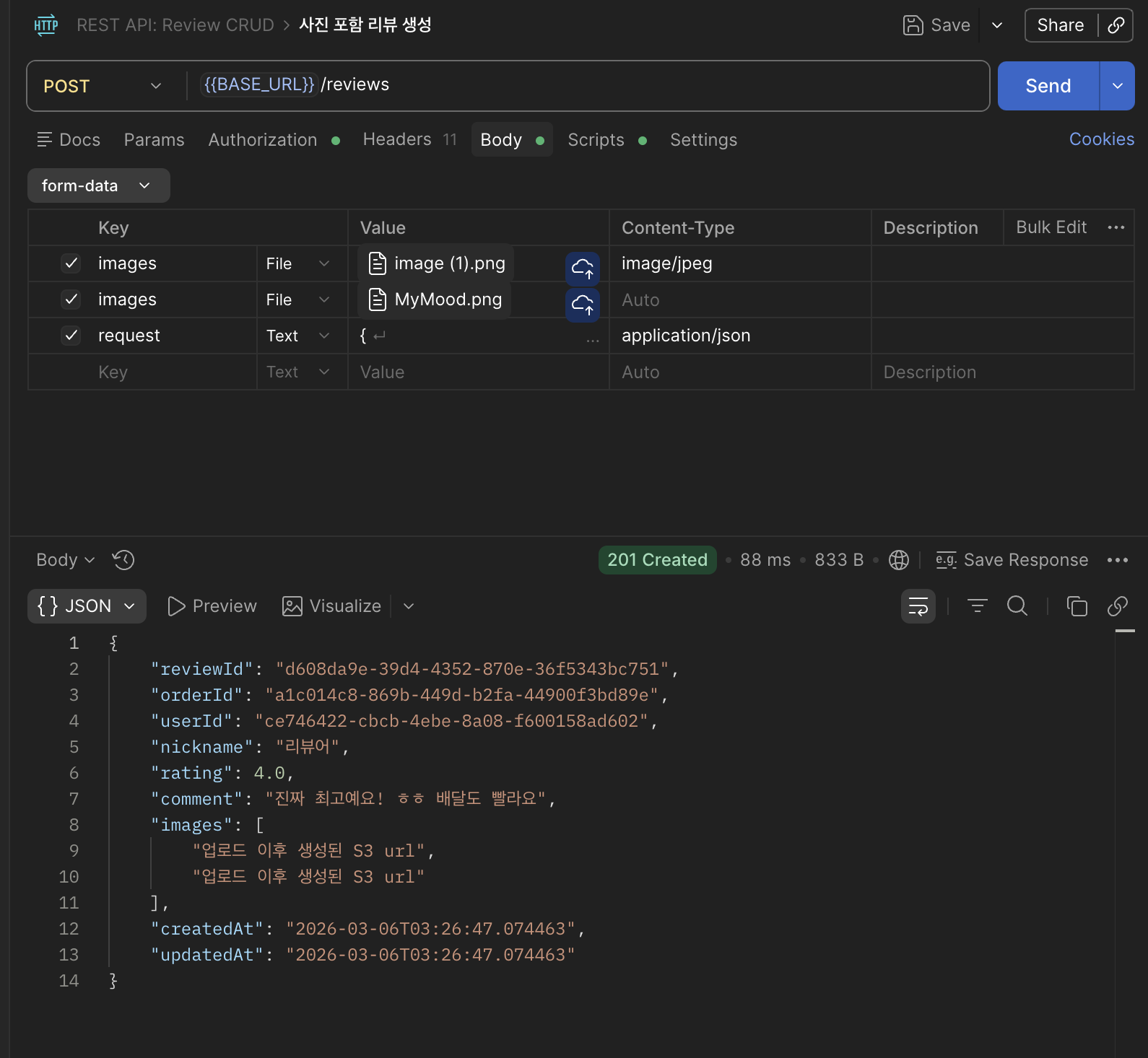
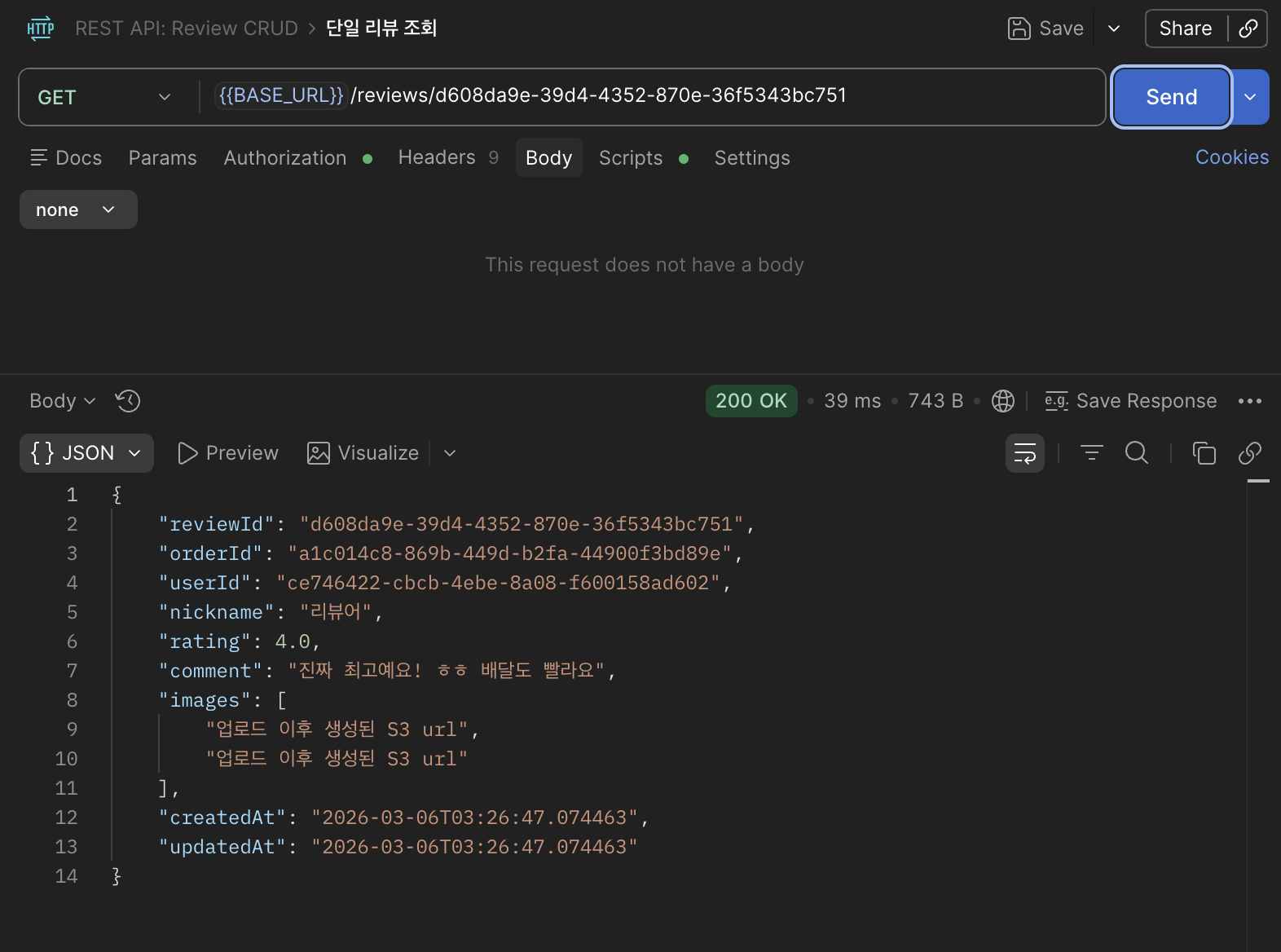
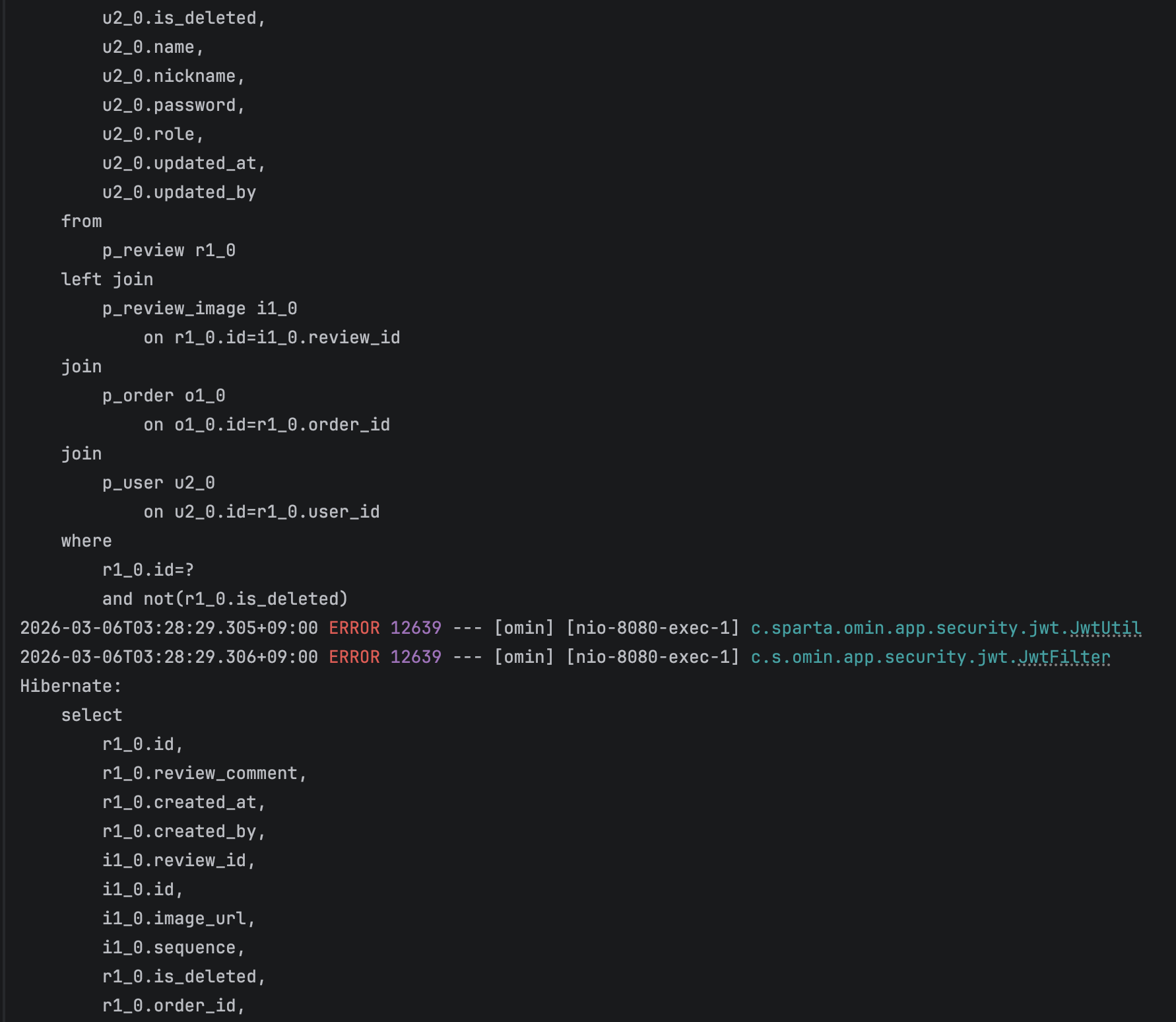
요청마다 쿼리가 한 번 만 보내지는 것을 확인 할 수 있었다.
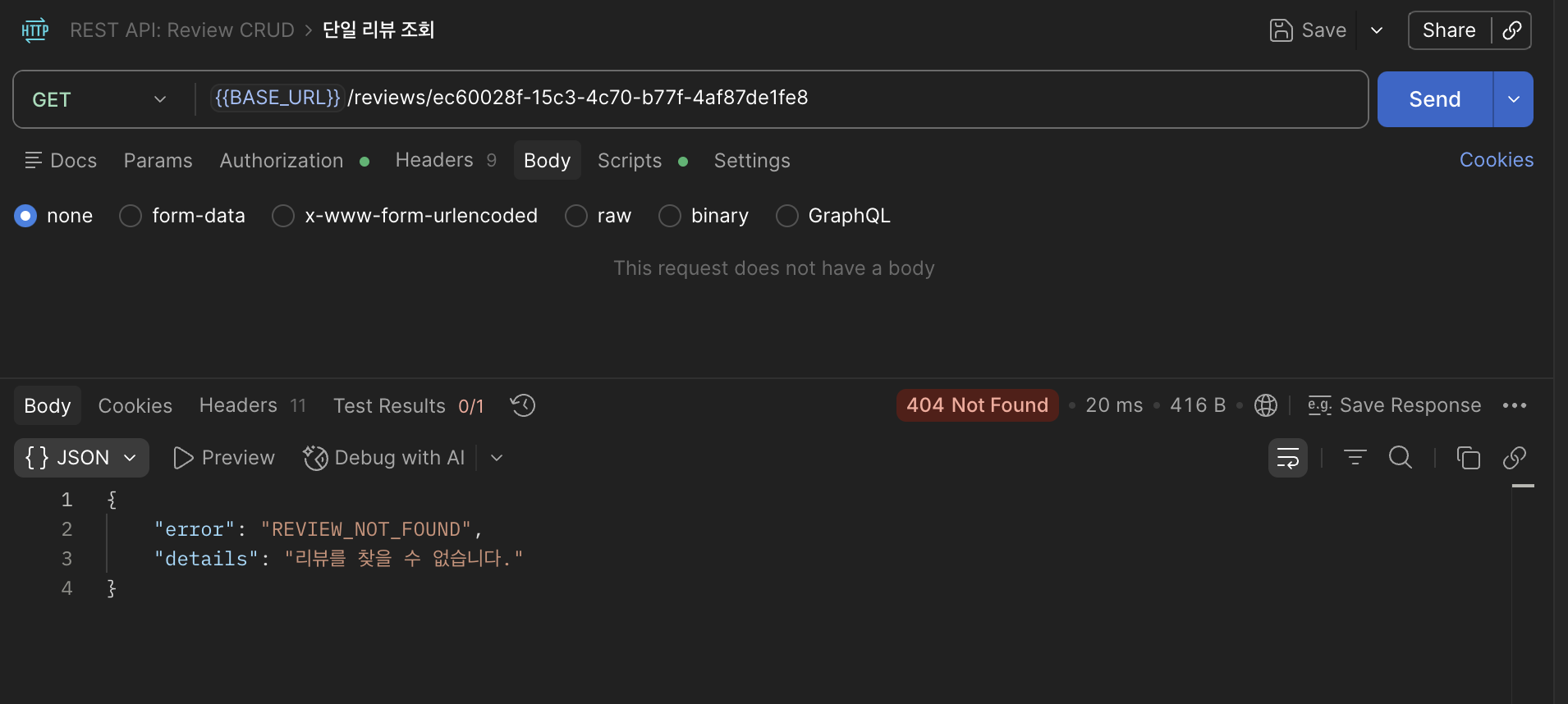
+ 이 테스트의 경우 UUID 형식이 맞지 않는데, (기존 조회 PathVariable에서 맨 뒷자리를 지움)
나중에 다른 문자열을 주었을 땐 컨트롤러 요청에서 UUID 타입 에러가 났는데 저건 통과했어서 왜 그런가 알아봤더니
UUID.fromString()이 내부적으로 각 블록을 16진수로 파싱하기 때문에 leading zero로 보정되면서 파싱되는 경우가 있어 그렇다고 한다.
즉, 마지막 글자를 0으로 채우면서 UUID 타입이 된 것이었다.
목록 조회
Slice
페이징 방법 외에 커서 기반 슬라이스 목록 조회 방법도 있다고 한다.
Pagable
Pageable은 페이지 요청 정보를 담는 객체입니다.
즉, 클라이언트가 몇 번째 페이지를 요청하는지, 한 페이지에 몇 개를 보여줄지, 어떤 컬럼 기준으로 정렬할지 등을 전달받을 수 있다.
(예시)
GET {BASE}/reviews ? page=1 &size=5 &sort=createdAt,descpage= 1 → 두 번째 페이지 (0부터 시작)size= 5 → 한 페이지당 5개 데이터sort= createdAt,desc → createdAt 기준 내림차순
Paging 요청 Controller
@GetMapping("/reviews")
public ResponseEntity<Page<ReviewResponse>> getReviews(@PageableDefault(size = 10, sort = "createdAt", direction = Sort.Direction.DESC) Pageable pageable) {
Page<ReviewResponse> response = reviewService.getReviews(pageable);
return ResponseEntity.ok(response);
} @PageableDefault는 페이지 요청 값이 없을 때 기본값을 지정하는 어노테이션이다.
Page<T>
Page<T>는 실제 조회 결과와 페이징 정보를 함께 담는 객체이다.
주요 필드로
content → 조회된 데이터 리스트
totalElements → DB에 있는 전체 데이터 개수
totalPages → 전체 페이지 수
number → 현재 페이지 번호
size → 요청한 페이지 크기
를 가지는데,
Spring Data JPA가 자동으로 데이터 수에 맞춰 계산한다.
예를 들어 클라이언트가 요청한 페이지 크기보다 DB 데이터가 적으면,
content에는 실제 존재하는 데이터만 들어가고,
totalElements와 totalPages도 자동으로 DB 데이터 수에 맞춰 계산된다.
Paging Service
public ReviewResponse getReviews(Pageable pageable) {
Page<Review> reviewPage = reviewRepository.findAllByIsDeletedFalse(pageable);
return reviewPage.map(ReviewResponse::from);
} Page<T>의 map()은 페이지 안에 들어있는 각각의 객체를 변환하는 메서드이다.
Paging Repository
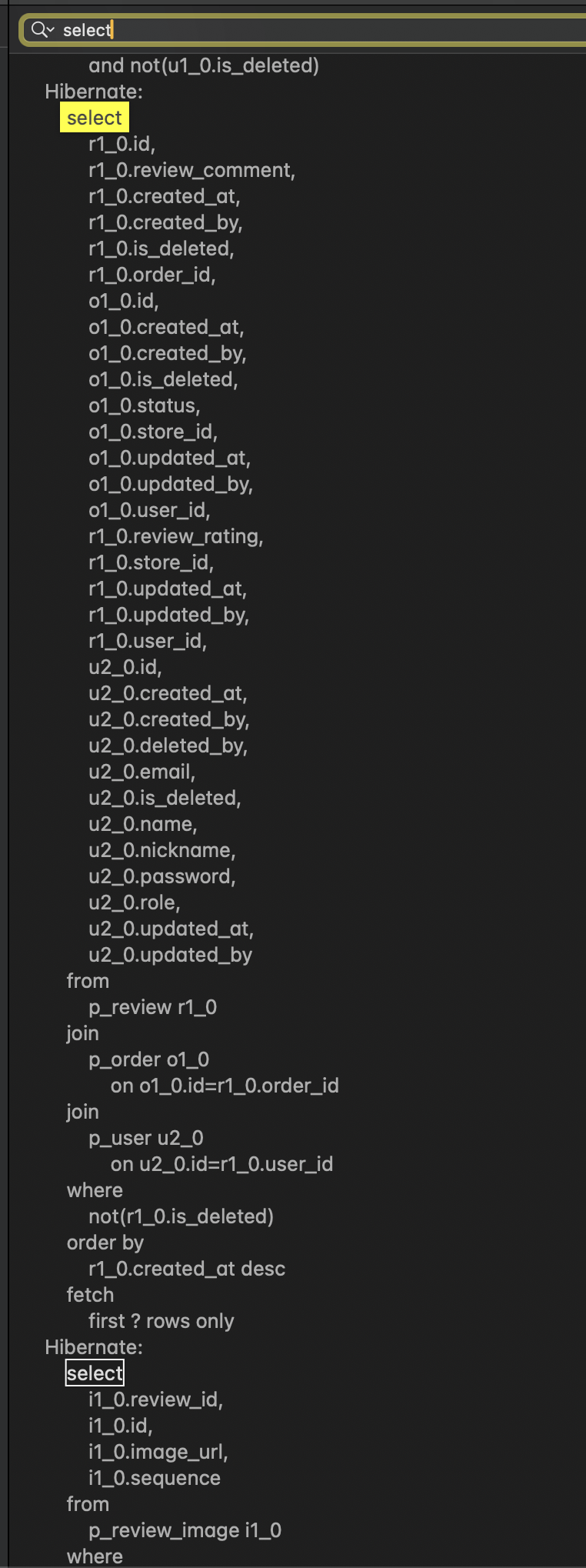
페이징을 쿼리할 땐 OneToMany 관계의 Collection(이미지)을 fetch join에서 제외한다.
만약 Collection을 Join 쿼리에 포함시키게 된다면,
SELECT r.*, u.*, o.*, i.*
FROM review r
LEFT JOIN user u ON ...
LEFT JOIN order o ON ...
LEFT JOIN image i ON ...
LIMIT 10;페이징 단위(10개 리뷰)와 쿼리 LIMIT 단위(10행)가 달라져서 잘못된 페이징이 발생하게 된다.
그래서 우선 단일 객체만 fetch join 하고 (User, Order 등)
@EntityGraph(attributePaths = {"user", "order"})
Page<Review> findAllByIsDeletedFalse(Pageable pageable);컬렉션(images)은 Lazy 로딩 → 필요할 때만 쿼리로 가져오도록하는데,
이 때 요청을 한 번에 가져오도록 batch_fetch_size를 정해 줄 수 있다.
한 번에 데려올 Collection 객체 크기 지정하는 방법
그리고 이 크기를 지정해주는 방법엔 다음 방법이 있는데, 설정을 적용하는 우선순위는 Spring Data JPA와 Hibernate의
'좁은 범위(구체적인 설정)가 넓은 범위(일반적인 설정)를 이긴다'는 원칙을 따라
계층(Hierarchy) 적으로 적용된다.
1. Repository 메서드에서 동적으로 조절
// @Service
public Page<ReviewResponse> getReviews(Pageable pageable) {
// 1. 리뷰 본체만 먼저 조회 (N건)
Page<Review> reviews = reviewRepository.findAll(pageable);
List<UUID> reviewIds = reviews.map(Review::getId).toList();
// 2. 리뷰 ID들을 사용해 이미지들을 한 번에 조회 (1번의 쿼리)
// reviewIds의 개수가 곧 배치 사이즈이다.
List<ReviewImage> allImages = reviewImageRepository.findAllByReviewIdIn(reviewIds);
// 3. 메모리(Map)에서 매칭 (Java Stream 활용)
Map<UUID, List<ReviewImage>> imageMap = allImages.stream()
.collect(Collectors.groupingBy(img -> img.getReview().getId()));
// 4. DTO 조립
return reviews.map(review -> ReviewResponse.from(review, imageMap.get(review.getId())));
}2. 엔티티 필드 레벨에서 설정
@Entity
public class Review extends BaseEntity {
// ... 다른 필드들
@BatchSize(size = 50) // 이 리뷰의 이미지를 가져올 때만 특별히 50개씩 IN 절로 묶어서 가져옴
@OneToMany(mappedBy = "review", cascade = CascadeType.ALL, orphanRemoval = true)
private List<ReviewImage> images = new ArrayList<>();
} 여기서 @BatchSize의 size는 "리뷰 1개가 가진 이미지의 개수"가 아니라, "한 번의 쿼리로 조회할 리뷰 엔티티의 개수"를 의미한다.
size는 크게 잡을수록 쿼리 횟수가 줄어들어 성능에 유리하다. (보통 100~500 사이를 추천한다고 한다)
3. spring 전역 설정
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100나는 이 방법들 중 적용방식이 쉽고 영향 범위가 명확해서 엔티티 필드 레벨에서 설정하기로 했다.
테스트
+ 오후 튜터님 피드백
테스트코드 작성방법
- 각각의 어노테이션의 기능을 잘 파악하기
- 테스트 파일의 이름은
<원본테스트클래스명>Test // given테스트에 필요한 전제 조건이나 테스트 데이터를 준비하는 부분 표시하는 주석// When & Then테스트하려는 실제 동작(메서드 실행 등)을 수행하는 부분 & 실행 결과를 검증하는 부분을 표시하는 주석- 테스트 코드에서 중복되는 부분은 helper 함수들로 모아 Helper 클래스로 빼서 상속받아 사용하기
@DisplayName으로 테스트 목적을 명확하게 작성하고 팀원들과 컨벤션 맞추기- fixture를 자동으로 만들어주는 라이브러리(예:
Fixture Monkey,Fixture Generator등)를 활용하면 테스트 데이터 생성이 편해진다.
중간에 일이 생겨서 일찍 조퇴하게 되어 뒷 부분은 자세히 못 적었다.
다행히 팀원분이 튜터님께서이 작성해주신 코드를 깃헙에 올려주셨다. (나중에 볼 코드 +1)
