최종 프로젝트 시작 전 이전 프로젝트 정리
스스로 사용한 기술을 명확히 정리
왜 그 기술을 선택했는지 설명
어떤 문제를 어떻게 해결했는지 구조화
이력서 / 포트폴리오 / 면접 답변까지 연결되는 형태로 정리
[회고] 모놀리스부터 MSA까지
📅 프로젝트 개요
- 프로젝트 1: 모놀리식 기반 '오더의 민족' (리뷰 시스템 담당)
- 프로젝트 2: MSA 기반 'Apang' (유저 서비스 및 공통 모듈 담당)
🏗️ 1. 모놀리식 프로젝트: 리뷰 시스템의 확장성 및 안정성 확보
[사용 기술] Spring Boot, JPA, MySQL, Redis, AWS S3
[담당 역할] 리뷰 도메인 전반 설계 및 구현, S3 이미지 업로드 및 폴백 전략 구축
🔍 핵심 고민 및 해결
- 리뷰 평점 통계의 동시성 이슈 처리
- 다수 사용자의 동시 리뷰 작성 시 평점 데이터 정합성 문제 발생 가능성 인지.
- 비관적 락(Pessimistic Lock) 검토했으나, 병목 현상 방지를 위해 배치(Batch) 처리 우선 선택하여 DB 부하 관리.
- (Next Step) 실시간성 보완을 위해 Redis Atomic Increment를 활용한 하이브리드 전략 설계 중.
- 외부 API 의존성 관리 (S3 폴백 전략)
- S3 업로드 실패 시 전체 서비스 중단 방지를 위해 로컬 저장소 또는 재시도 로직을 포함한 폴백(Fallback) 전략 구성.
- 도메인 중심 리팩토링
ReviewService의 검증 로직(소유권, 수정 가능 기간 등)을Review엔티티 내부로 응집시켜 서비스 계층 비대화 방지 및 객체지향적 구조 확립.
🌐 2. MSA 프로젝트: 공통 모듈 규격화 및 유저 도메인 설계
[사용 기술] Spring Cloud Gateway, OpenFeign, Kafka, Spring Data JPA, QueryDSL
[담당 역할] 공통 규격(Pagination) 모듈화, Outbox/Inbox 패턴 분석 및 통합, 유저 서비스 설계
🔍 핵심 고민 및 해결
- 유저 서비스: 효율적 데이터 관리를 위한 Sparse Table 설계
- Master, Manager, Owner, Customer 등 다양한 역할(Role) 대응을 위해 희소 테이블(Sparse Table) 구조 채택.
- 조회 빈도가 높은 서비스 특성상 조인 오버헤드(Join Overhead)를 최소화하여 읽기 성능(Read Performance)을 극대화하기 위한 결정.
-
DDD 기반 응집도 높은 설계: 유저 상태 변경 로직이 서비스 계층에 산재하던 문제를 해결하기 위해 도메인 메서드(updateProfile, updateRole 등)를 구현하여 엔티티가 스스로 상태를 관리하도록 설계.
-
객체 생성 전략: 정적 팩토리 메서드(User.create)로 생성 시점의 유효성 검증을 강제
-
예외 처리 고도화: 첫 번째 프로젝트 모놀리스 프로젝트의 단일 RuntimeException 사용을 개선하여 도메인 특화 예외(UserNotFoundException 등)로 세분화해 클라이언트 피드백 및 트러블슈팅 효율 강화.
-
(Planned)
- 엔드포인트 기반 RBAC: 구조적 단점 보완 및 보안 강화를 위해 유저 서비스에서 권한 검증 후 타 도메인 서비스로 요청을 전달하는 흐름을 설계하여 도메인 간 격리 실현 계획.
- 배송 담당자 배정 로직 고도화 (Round-Robin)
- 문제: 특정 배송 기사에게 업무가 쏠리지 않도록 공정하게 배정해야 하며, 서버 재시작 시에도 배정 순서가 초기화되지 않고 유지되어야 함.
- 해결 (PostgreSQL Sequence 활용): 메모리 기반 카운터의 한계를 극복하고 분산 서버 환경(Multi-instance)에서의 상태 공유 문제를 해결하기 위해 PostgreSQL의 Sequence를 도입. 허브별 가용 인원을 조회한 뒤, 시퀀스 값을 통해 배정 순서를 영속적으로 관리함.
- 성능 최적화 고려: 현재 DB 기반의 시퀀스를 사용 중이나, 트래픽 증가에 따른 병목 현상을 방지하기 위해 Redis를 활용한 카운팅 성능 향상을 추가로 고려 중임.
- 공통 모듈: 페이지네이션(Pageable) 규격화 및 메시징 시스템 통합
- 공통 규격 직접 구현: 프로젝트 전반에서 사용되는 페이징(
Pageable) 처리 기준 등 공통 규격을 직접 설계/모듈화하여 일관성 있는 API 응답 구성. - 라이브러리 분석 및 통합: 제공된
Outbox/Inbox공통 모듈을 단순히 활용하는 것에 그치지 않고 내부 코드를 깊이 분석하여 분산 시스템의 메시징 흐름을 파악하여 담당 도메인에 연동. - [이해하고 활용한 핵심 메시징 흐름]
AFTER_COMMIT이벤트: DB 트랜잭션 커밋 완료 후에만 메시지 발행이 트리거되도록 보장OutboxRelayScheduler: 미전송 건 재시도 및 최종 실패 시 DLT(Dead Letter Queue) 전송을 통한 유실 방지 구조 파악.InboxAdvice: 수신 측에서message_id기반 중복 필터링을 통해 멱등성(Idempotency)을 유지하는 메커니즘 적용.
- 공통 규격 직접 구현: 프로젝트 전반에서 사용되는 페이징(
🚀 핵심 역량 요약 (STAR)
- [데이터 설계 및 고도화] 다중 역할 시스템 대응을 위한 Sparse Table 구조 설계 및 PostgreSQL Sequence를 활용한 영속적이고 공정한 배정 로직 구현.
- [객체지향 설계] Rich Domain Model 및 정적 팩토리 메서드 적용으로 서비스 계층 복잡도를 낮추고 데이터 무결성을 확보하는 리팩토링 수행.
- [라이브러리 분석 및 통합] 이미 작성된 Outbox/Inbox 공통 모듈의 내부 로직을 심층 분석하여 담당 도메인에 연동. 블랙박스 형태의 라이브러리를 화이트박스화하여 활용하는 코드 리딩 및 기술 통합 역량 발휘.
🛠️ Action Items (Self-Feedback)
- 설계의 코드화: Sparse Table 설계에 따른 역할별 세부 권한 로직 및 도메인 엔드포인트 연동 실제 구현 마무리.
- 배송 배정 성능 향상: 시퀀스 기반 배정 로직을 Redis로 고도화하여 대규모 트래픽 환경에서의 성능 오버헤드 테스트 진행.
- 메시징 예외 시나리오 확장: DLT(Dead Letter Queue)에 쌓인 메시지의 수동 복구 로직 및 모니터링 체계 고민.
💡 회고 요약
모놀리식 환경에서는 리뷰 시스템을 구현하며 동시성 문제와 외부 API 의존성에 대한 대응을 경험했고, 이를 통해 단순 기능 구현을 넘어 데이터 정합성과 서비스 안정성을 고려하는 개발로 나아갈 수 있었다.이후 MSA 환경에서는 유저 도메인과 공통 모듈을 설계하며, 역할 구조에 따른 데이터 모델링(Sparse Table), 분산 환경에서의 상태 관리(PostgreSQL Sequence), 메시징 시스템(Outbox/Inbox)을 직접 다루며 확장성과 일관성을 동시에 만족시키는 설계를 고민하게 되었다.
단순히 기술을 쓰는 것에서 벗어나, 내부 동작을 직접 분석하고 적용하면서 "왜 이 구조를 선택했는지 설명할 수 있는 개발자"로 한 단계 성장할 수 있었다. 기능 구현 중심에서 벗어나 시스템 전체 흐름과 트레이드오프를 고민하게 된 계기가 된 프로젝트였다.
장애처리
장애 대응, 코드 리뷰, 서비스 운영의 현실
🚨 장애는 설계로 예방한다
장애는 예고 없이 발생하며, 전체 서비스가 멈추는 구조는 위험하다.
문제가 생긴 섹션만 숨기고 나머지는 정상 제공되도록 부분 격리 설계가 필수적이다.
장애 상황에선 침착한 멘탈 관리와 사전 대응 프로세스가 개발자의 핵심 역량이다.
🧐 의심스러운 코드는 침묵하지 않는다
코드에서 미흡한 부분을 발견하면 그냥 넘기지 않는다.
혼자 판단하기 어렵다면 동료, 선임과 공유해 집단지성으로 명확성을 확인한다.
작은 침묵이 나중엔 큰 장애로 돌아온다. 사소한 의심도 반드시 공유하는 문화가 중요하다.
🛡️ 서비스 오픈은 시작이다
오픈은 유지보수와 모니터링의 시작점이다.
애플리케이션의 세부 사항은 담당 개발자가 가장 잘 안다. 그 책임을 끝까지 가져가거나, 명확하게 인수인계해야 한다.
오픈 이후에도 서비스의 품질을 지켜내는 것이 개발자의 진짜 책임이다.
장애 사전 식별을 위한 통합 모니터링 체계 구축
고객이 먼저 장애를 발견하고 접수하는 상황은 기업 평판과 서비스 경험에 치명적인 영향을 미친다. 따라서 서비스 내부에서 상태를 지속적으로 관찰하고 장애를 조기 식별하는 체계적인 모니터링이 필수적이다.
1. 백엔드 중심: 인프라 및 애플리케이션 모니터링
시스템 자원 및 예측: CPU, 메모리, 네트워크 대역폭 등 리소스를 실시간 추적하여 성능 병목을 잡는다. 머신러닝 기반의 예측 분석을 적용하면 비정상 패턴을 사전 감지해 장애를 막을 수 있다.
통합 로그 및 성능(APM): 앱의 응답 시간과 오류율을 측정하고, 중앙 집중형 관리 시스템으로 모든 로그를 통합해 예외 상황을 조기 탐지한다. 주기적인 서비스 헬스 체크로 정상 동작 여부를 상시 검증해야 한다.
2. 프론트엔드 중심: 사용자 경험(UX) 모니터링
E2E(End-to-End) 테스트: 셀레니움과 같은 도구로 사용자의 전체 이용 경로를 모니터링해 실제 체감 지연이나 실패 요청을 파악한다.
RUM(Real User Monitoring): 구글 애널리틱스 등으로 실제 유저의 웹 브라우저 내 페이지 로드 시간과 응답 시간을 측정한다. 이와 함께 고객 지원 채널의 피드백을 수집해 잠재적 문제를 파악한다.
3. 피로도를 최소화하는 알림 시스템
무분별한 알림은 어떤 것이 진짜 중요한 장애인지 파악하기 어렵게 만든다. 명확한 임계값과 경고 기준을 설정해 알림 채널을 분리해야 한다.
장애 발생 시 복구 프로세스(예: 앱 재시작)가 즉시 실행되도록 자동화 스크립트와 알림을 연동하는 것이 효과적이다.
4. 실무 활용 도구 및 운영 고려사항
핵심 모니터링 도구:
Prometheus & Grafana: 메트릭 데이터 수집 및 대시보드 시각화
ELK 스택: 대규모 로그 데이터의 수집(Logstash), 저장(Elasticsearch), 시각화(Kibana)
New Relic: 실시간 애플리케이션 성능(APM) 및 사용자 경험 모니터링
중앙 집중식으로 데이터를 관리하고, 팀 간 원활한 공유 체계를 만들어야 한다.
장애 시뮬레이션 테스트를 정기적으로 수행해 모니터링 시스템 자체가 정상 작동하는지 지속적으로 점검하는 것이 좋다.
특강 - ELK를 이용한 CQRS 및 모니터링 시스템 구현
🔍 ELK Stack
Elasticsearch + Logstash + Kibana 세 도구의 조합이다.
로그를 수집하고 → 정제하고 → 저장하고 → 시각화하는 전 과정을
하나의 스택으로 통합해서 처리할 수 있다.
🧐 왜 쓰는가
배포 이후 장애가 발생했을 때, EC2에 직접 접속해서 로그 파일을 뒤지는 방식은 너무 느리고 비효율적이다.
또한 데이터가 수십만 건을 넘기 시작하면 단순 조회조차 성능이 급격히 저하된다.
ELK는 이 두 가지 문제를 동시에 해결한다.
- Logstash → 다양한 소스의 로그를 수집·전처리하는 ETL 파이프라인
- Elasticsearch → 역인덱스(Inverted Index) 기반의 고속 검색 저장소
- Kibana → 수집된 데이터를 대시보드로 시각화
⚡ Elasticsearch가 빠른 이유

RDBMS의 LIKE '%keyword%' 방식과 달리,
단어 기준으로 인덱스를 미리 구성해두기 때문에 키워드 검색이 즉시 가능하다.
대용량 텍스트 데이터 검색에 특화된 구조이다.
왜 많은 서비스 중 ELK일까?
NoSQL + Grafana/Loki 조합으로도 로그 저장과 시각화는 가능하다.
그러나 ELK는 수집부터 시각화까지 하나의 스택으로 통합되어 있고,
대용량 텍스트 검색에 특화된 Elasticsearch 덕분에 실무에서 널리 선택된다.
| 구분 | 항목 | 설명 |
|---|---|---|
| ✅ 장점 | End-to-End 통합 스택 | 수집 → 정제 → 저장 → 시각화를 ELK 하나로 구성 가능하다 |
| ✅ 장점 | 강력한 전처리 | Logstash가 저장 전 로그를 분석·가공하는 ETL 역할을 수행한다 |
| ✅ 장점 | 고속 검색 | 역인덱스(Inverted Index) 구조로 수백만 건 데이터도 빠르게 조회된다 |
| ⚠️ 단점 | 높은 자원 소모 | 강력한 기능만큼 인프라 비용이 크다 |
| ⚠️ 단점 | 복잡한 설정 | 구성 요소가 많아 초기 설정과 러닝 커브가 높다 |
실습
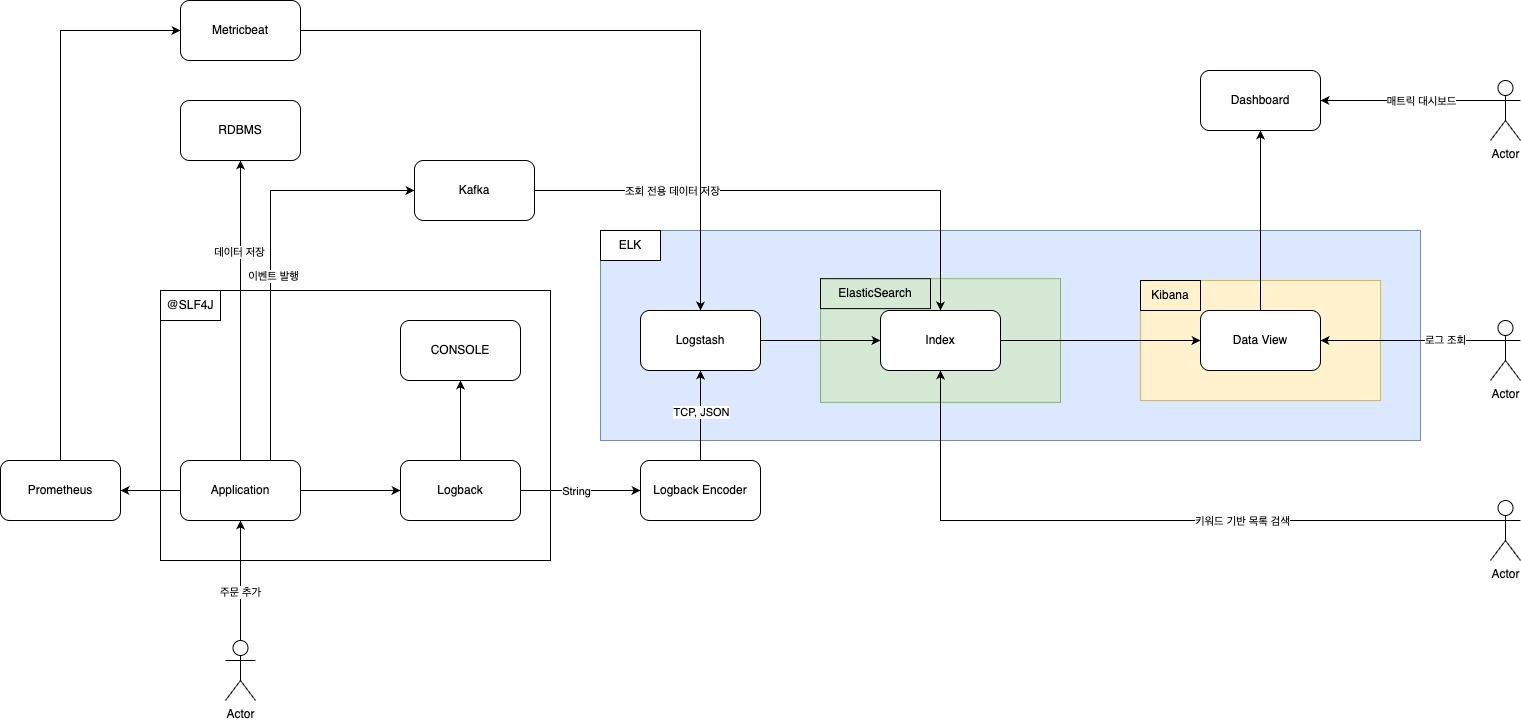
- ElasticSearch 를 이용한 CQRS 구현
- Logstash 를 연동하여 애플리케이션 로그 확인
- Metricbeat, Prometheus 를 이용한 애플리케이션 메트릭 정보 시각화
초기 세팅
# 1. ELK 도커 클론
git clone https://github.com/Kkaekkae/docker-elk
# 2. 실행
docker compose up setup
docker compose up -d
# 3. Kibana 접속 확인
# http://localhost:5601 / ID: elastic / PW: .env의 ELASTIC_PASSWORD// build.gradle
implementation 'org.springframework.data:spring-data-elasticsearch:5.4.1'# application.yml
spring:
data:
elasticsearch:
host: localhost:9200
username: elastic
password: password@Configuration
public class ElasticConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
.withBasicAuth("elastic", "password")
.build();
}
}// 저장될 Document 정의
@Document(indexName = "order")
public class SearchOrder {
@Id private String id;
private Long orderId;
private Long totalPrice;
@Field(name = "order_status", type = FieldType.Keyword)
private OrderStatus status;
@Field(type = FieldType.Date)
private LocalDate createdAt;
}조회
BoolQuery.Builder boolQuery = QueryBuilders.bool();
// 가격 범위
boolQuery.must(QueryBuilders.range(b -> b.number(n ->
n.field("totalPrice").gte(startPrice.doubleValue()).lte(endPrice.doubleValue()))));
// 상품명 검색
boolQuery.must(QueryBuilders.queryString(f ->
f.fields(List.of("product_list.name")).query("*%s*".formatted(productName))));
SearchHits<SearchOrder> hits = elasticsearchOperations.search(
NativeQuery.builder().withQuery(boolQuery.build()._toQuery()).build(),
SearchOrder.class
);생성
// Repository 선언
public interface OrderElasticSearchRepository
extends ElasticsearchRepository<SearchOrder, String> {}
// 저장
orderElasticSearchRepository.save(searchOrder);Logstash 연동
// build.gradle
implementation 'net.logstash.logback:logstash-logback-encoder:8.0'<!-- resources/logback-spring.xml -->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<destination>localhost:50000</destination>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp><timeZone>UTC</timeZone></timestamp>
<logLevel /><loggerName /><message /><stackTrace />
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="LOGSTASH" />
</root>// 로그 확인용 예시
@Slf4j
@Service
public class SearchOrderServiceImpl {
public List<OrderSearchResponse> search(String productName, ...) {
log.info("get orders productName: {}", productName);
}
}
// Kibana Discover → logs-* 에서 확인Micrometer를 이용한 분산 추적
// build.gradle
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-tracing-bridge-brave'
implementation 'io.zipkin.reporter2:zipkin-reporter-brave'# application.yml
management:
zipkin:
tracing:
endpoint: "http://localhost:9411/api/v2/spans"
tracing:
sampling:
probability: 1.0설정 후 조회 API를 호출하면 Kibana 로그에 traceId, spanId 가 자동으로 찍힌다.
traceId: 요청 전체를 관통하는 ID (MSA 전 서비스 동일)spanId: 각 서비스 단계별 개별 ID
