프로젝트를 진행하면서 모임 평가, 판매 평가, 구매 평가라는 세 가지 유형의 리뷰(평가) 시스템을 구현해야 하는 상황에 직면했다.
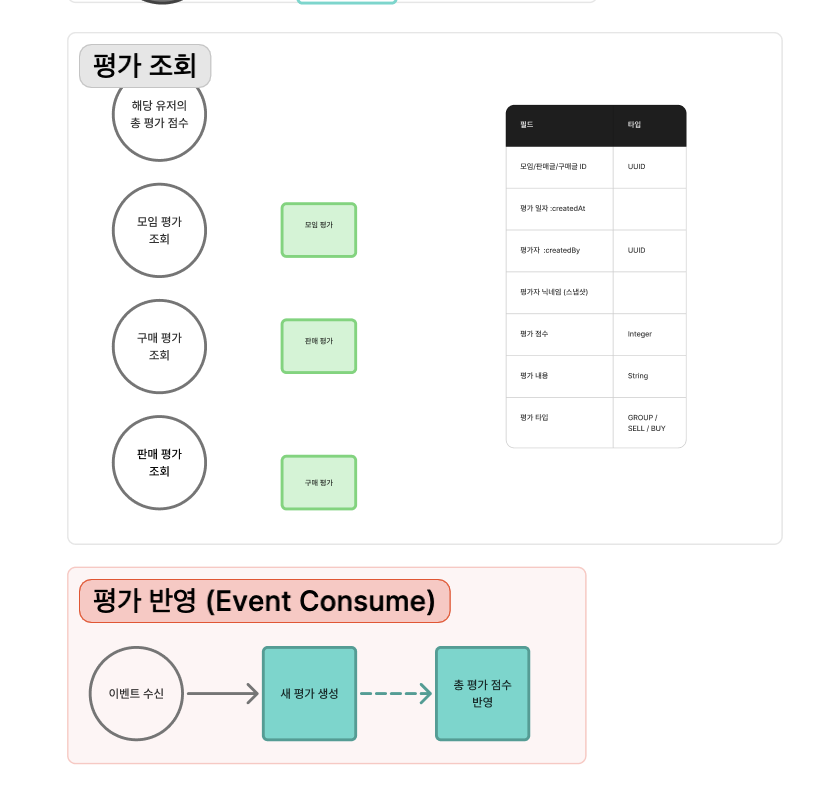
위의 구성도를 보면 알 수 있듯이, 이 세 가지 평가는 필드 구성이 완전히 동일하다.
평가 일자, 평가자, 평가자 닉네임 스냅샷, 평가 점수, 평가 내용
여기서 깊은 고민에 빠졌다.
평가 필드가 동일한데, 타입별로 테이블을 다 찢어야 할까?
아니면 지금 구성도처럼 하나의 테이블에 type 필드(GROUP/SELL/BUY)를 둬서 통합해야 할까?"
오늘은 이 데이터 모델링 딜레마를 도메인 주도 설계(DDD)와 MSA 원칙 관점에서 어떻게 해결해 나갔는지 정리해 본다.
🚨 처음의 착각: "필드가 같으니까 하나의 평가 서비스로 빼면 어떨까?"
가장 먼저 든 생각은 평가만을 전담하는 별도의 마이크로서비스를 만들고, 거대한 하나의 통합 리뷰 테이블을 두는 것이었다.
처음에 클로드AI가 제시해준 방안:
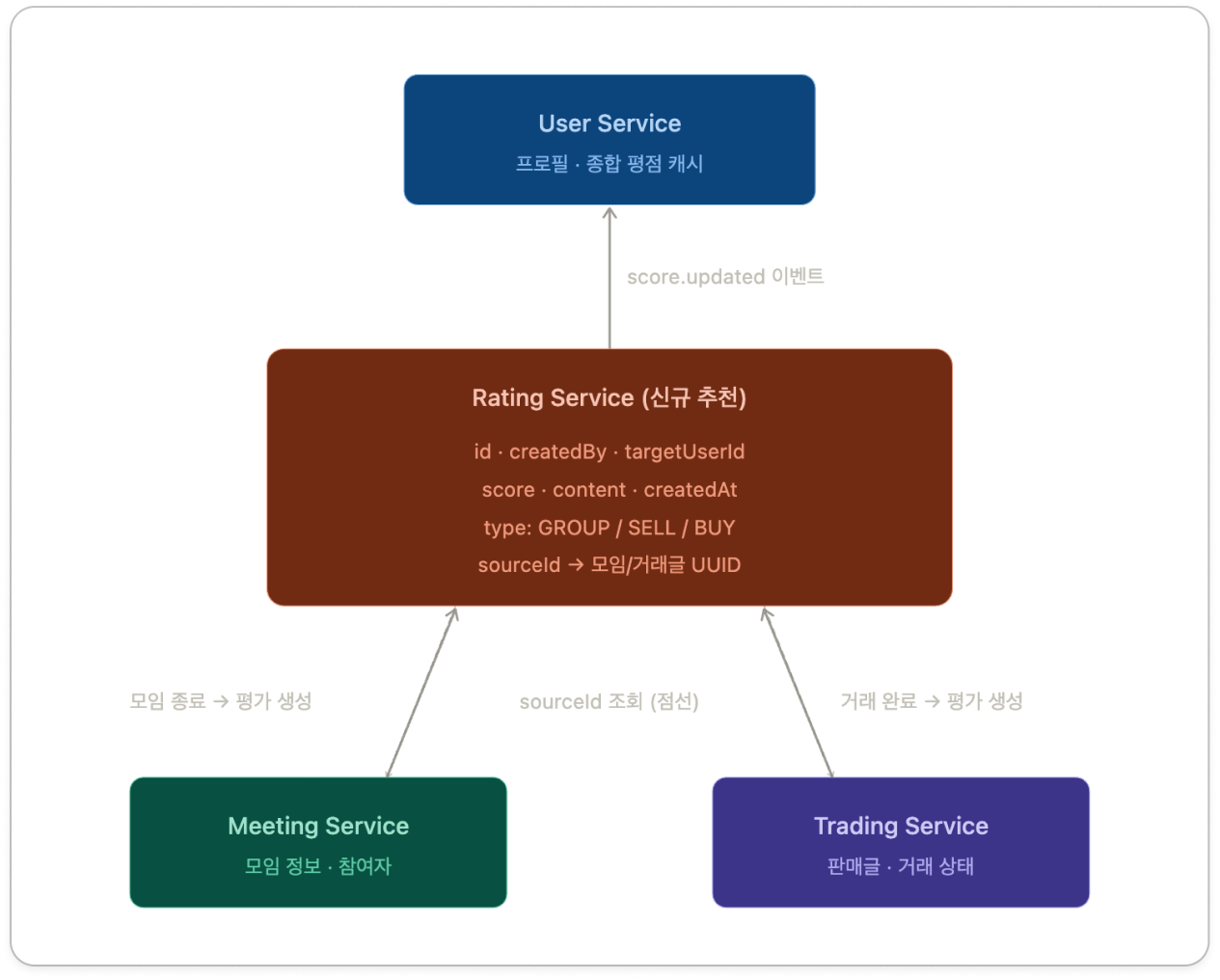
하지만 이는 MSA의 핵심 원칙을 정면으로 위배하는 안티 패턴이었다.
MSA에서는 각 서비스가 자신의 데이터베이스를 소유하고 도메인 응집도를 높게 가져가야 한다.
만약 리뷰 전용 서비스를 따로 빼버리면,
- 모임이 종료된 후 리뷰를 남길 수 있다
- 거래가 완료되어야 평가가 가능하다라는 핵심 비즈니스 로직들이 여러 서비스에 파편화되어 버린다.
도메인 경계가 깨지고 결합도만 높아지는 최악의 결과를 낳게 되는 것이다.
결국 "전체 통합"은 애초에 선택지가 될 수 없음을 깨달았다.
💡 나의 선택: 서비스별 분리 + 서비스 내 도메인 통합
남은 선택지는
1. 모든 타입을 완전히 분리하는 것
2. 서비스별로만 분리하고 그 안에서 묶는 것두가지 였다.
결론적으로 나는 2번 방식을 채택했다.
"모임" 서비스 -> group_review 테이블
"중고거래" 서비스 -> trade_review 테이블
(내부에 type: SELL / BUY 필드 사용)
🧐 왜 이 방식을 선택했는가?
1. 도메인의 양면성과 응집도
판매 평가와 구매 평가는 결국 '중고거래'라는 동일한 도메인 내에서 발생하는 한 트랜잭션의 양면이다.
같은 거래 서비스 내에 속해 있고 스키마도 동일하므로, 이를 굳이 sell_review와 buy_review로 물리적으로 찢을 필요가 없었다.
반면 '모임 평가'는 도메인 자체가 아예 다른 모임 서비스에 속해 있으므로 별도의 테이블로 완전히 분리하는 것이 자연스럽다.
2. 스키마 중복 최소화 및 확장성
서비스 내에서 테이블을 통합하면 스키마 중복을 줄일 수 있다.
추후 중고거래 도메인 내에서 새로운 타입의 평가가 추가되더라도 테이블을 새로 파는 대신 type 필드만 확장하면 되므로 유연하게 대처할 수 있다.
3. 이벤트 기반의 느슨한 결합 (Event Consume)
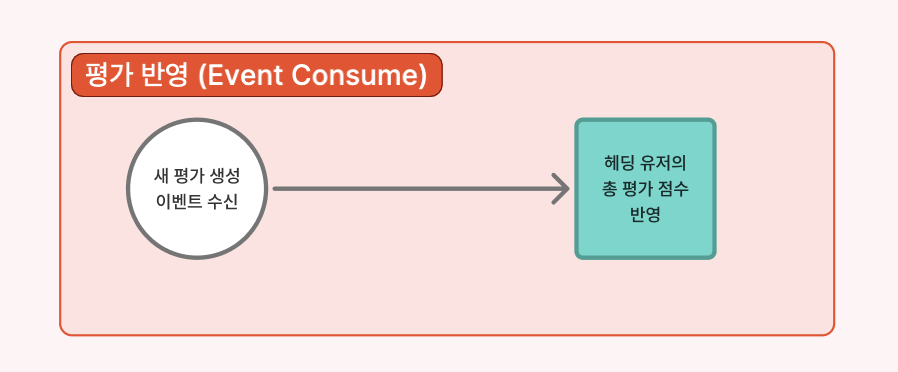
구상한 설계도를 보면 '평가 반영 (Event Consume)' 프로세스가 있다.
새 평가가 생성되면 이벤트를 수신하여 해당 유저의 '총 평가 점수'에 반영하는 구조다.
도메인별로 테이블을 깔끔하게 분리해 두면, 중고거래 서비스나 모임 서비스가 각자의 평가를 DB에 저장한 직후 메세지 브로커(Kafka 등)를 통해 이벤트를 발행하기만 하면 된다.
유저의 총점수를 관리하는 유저 도메인 에서는 각 서비스의 DB 구조를 알 필요 없이 이벤트만 컨슘하여 점수를 업데이트하면 되므로 MSA의 비동기 통신과 단일 책임 원칙에 완벽하게 부합한다.
🛠 구현시 성능/구조적 기술적 이슈와 해결 방안
이 구조를 실제 구현하기 전 몇 가지 짚고 넘어가야 할점 들을 추가로 알아보았다.
다형성 연관관계와 FK (Foreign Key) 제약
중고거래 도메인의 trade_review 테이블 하나에
판매글 ID와 구매글 ID가 모두 들어오게 된다.
trade_review
- id (UUID)
- target_id (UUID) -- 판매글 ID or 구매글 ID
- type (enum: SELL, BUY)
- reviewee_id (UUID) -- 평가 대상 유저
- reviewer_id (UUID) -- 평가자 (createdBy)
...여기서 target_id는 타입에 따라 가리키는 대상(판매글 테이블 vs 구매글 테이블)이 달라지는 다형성 연관(Polymorphic Association)을 가진다.
따라서 데이터베이스 레벨에서 강력한 외래 키(FK) 제약조건을 걸 수가 없다.
처음엔 (평가에 대한 원본 글이 삭제되면 Id가 허공을 가리키게 되지 않나?) 데이터 무결성이 걱정되었지만,
다시 생각해 보니 MSA 환경에서는 어차피 다른 서비스의 엔티티 ID를 참조할 때 FK를 걸지 않고 느슨한 결합으로 유지하는 것은 지극히 정상이다.
데이터 정합성은 애플리케이션 레벨의 로직과 이벤트 보상 트랜잭션 등을 통해 보장하는 것이 맞다.
[+ 비하인드: 왜 Soft Delete인가?]
MSA 환경에서는 어차피 다른 서비스의 엔티티 참조를 고민하다가 Soft Delete의 이유에 대해서도 더 잘 알게 되었다.
프로젝트 정책상 모든 엔티티에 Soft Delete를 적용해 왔는데, 처음엔 그 이유에 대해서 정확히 알지 못했다.
막연히 '운영상 나중에 필요해 질 때가 있어 삭제하지 않고 일단 가지고 있어야 한다' 라고만 알고 있었다.
사실 Soft Delete를 사용하면 조회할 때마다 where is_deleted = false를 붙여야 해서 번거롭기도 하고,
(물론 JPA @Where나 @SQLRestriction으로 자동화할 수 있지만!)
추가로 데이터가 계속 쌓여 인덱스 효율이 떨어지는 것도 생각해볼 수 있다. (이후 설명)
하지만 Soft Delete는 다음과 같은 이유로 사용된다.
-
Dangling Pointer 방지:
평가 데이터가 가리키는 원본 글이 물리적으로 증발하는 것을 막아준다. -
비즈니스 연속성:
실수로 지운 평가를 즉시 복구할 수 있는 안전장치가 된다. -
데이터의 가치:
삭제된 데이터조차 사용자 행동 패턴 분석을 위한 훌륭한 자산이 되기 때문이다.
[++ Soft Delete와 조회 성능]
Soft Delete를 하면 실제로는 사용하지 않는 데이터가 DB와 인덱스에 계속 남게 된다.
물리 삭제(Hard Delete)를 했다면 인덱스 트리에서 제거되었을테지만,
데이터들이 그대로 자리를 차지하고 있는 것이다.
인덱스의 크기가 비대해지면 다음과 같이 성능 저하가 일어난다.
1. 새로운 데이터를 삽입/수정할 때 인덱스 갱신 비용이 커짐
2. 조회 시에 불필요하게 커진 인덱스 페이지를 스캔해야 하므로
메모리(Buffer Pool) 효율이 떨어짐즉, 전체 데이터 중 삭제된 데이터의 비중이 높아질수록 '조회 성능의 가성비'가 나빠진다.
하지만 이런 성능적 트레이드오프를 고려해도 데이터 복구 가능성과
MSA 환경에서의 참조 무결성 유지가 더 큰 가치를 가지기에,
실무에서는 필요하다면 '일정 기간 지난 삭제 데이터는 아카이빙 테이블로 이관'하는 등의 전략으로 보완한다.
2. 복합 인덱스(Composite Index)를 통한 조회 성능 최적화
단일 테이블로 합쳤기 때문에 전체 데이터를 풀 스캔(Full Scan)하는 N+1 문제나 성능 저하가 발생하지 않도록 DB 인덱스 전략을 꼼꼼하게 세워야 한다.
특정 유저가 받은 판매 평가만 모아보거나, 특정 게시글의 리뷰만 조회하는 쿼리가 매우 빈번할 것이다.
따라서 단일 컬럼 인덱스가 아닌, type을 포함한 복합 인덱스 구성이 필수적이다.
CREATE INDEX idx_reviewee_type ON trade_review (reviewee_id, type);
CREATE INDEX idx_target_type ON trade_review (target_id, type);@Entity
@Table(name = "trade_review", indexes = {
@Index(name = "idx_reviewee_type", columnList = "reviewee_id, type"),
@Index(name = "idx_target_type", columnList = "target_id, type")
})
public class TradeReview {
@Id
@GeneratedValue(strategy = GenerationType.UUID)
private UUID id;
@Column(name = "reviewee_id")
private UUID revieweeId;
@Column(name = "target_id")
private UUID targetId;
@Enumerated(EnumType.STRING)
private ReviewType type; // SELL, BUY
// ... 나머지 필드
}[+ 왜 하필 '복합' 인덱스인가?]
trade_review 테이블은 판매(SELL)와 구매(BUY) 데이터가 한데 섞여 있는 구조다.
만약 유저 ID로만 인덱스를 잡는다면, 특정 유저의 '판매 리뷰'만 조회하고 싶을 때 DB는 불필요하게 '구매 리뷰'까지 들춰봐야 하는 비효율이 발생한다.
이를 해결하기 위해 (reviewee_id, type)처럼 두 컬럼을 묶은 복합 인덱스(Composite Index)를 생성한다.
이렇게 하면 데이터가 인덱스 안에서 유저별, 그리고 그 유저 안에서 타입별로 미리 정렬되어 저장된다.
결과적으로 DB는 수많은 데이터 사이를 헤매는 '풀 스캔' 없이, 우리가 원하는 데이터가 있는 지점으로 자석처럼 한 번에 찾아갈 수 있게 된다.
마무리
단순히 "필드가 똑같네? 합치자!" 혹은 "용도가 다르네? 나누자!"라는 1차원적인 생각에서, 도메인의 경계가 어디인가를 기준으로 데이터베이스를 설계해보는 좋은 경험이었다.
결과적으로 각 서비스는 자신만의 명확한 책임을 가지게 되었고, 이벤트 컨슘을 통한 총점 반영 파이프라인도 훨씬 깔끔하게 구축할 수 있을 것 같다.
