이벤트 발행: 상태와 행위 사이의 고민
API 구현이 마무리되어가면서 UserCreated, UserUpdated, UserWithdraw 이벤트 발행 로직을 추가해야 했다.
통계 테이블에 주로 사용될 Created와 Withdraw 같은 경우 식별자인 UserId만 날려주면 될 것 같았지만, 가장 상태 변화가 많은 Updated가 문제였다. Payload를 어떻게 짜야 할지 감이 오지 않았다.
이전 프로젝트에서는 이에 대해 깊게 고민할 시간 없이, 일단 기능이 동작하도록 조회(Read) API를 설계할 때처럼 DTO에 모든 필드를 선언해두고 값이 있는 것만 채워서 보내면 된다고 막연하게 생각했다. 조회 API는 클라이언트가 "내가 필요한 정보를 직접 골라가는(Pull)" 방식이기에, 최대한 많은 선택지를 열어두는 것이 미덕이었기 때문이다.
하지만 메시징 기반의 아키텍처를 깊이 파고들수록 이 방식의 허점이 보였다. '전달되지 않은 값'과 'null로 변경된 값'을 구분할 수 없다는 점은 데이터 정합성의 치명적인 결함이었고, 이는 결국 Consumer에게 모든 책임을 떠넘기는 무책임한 설계였다.
Kafka 이벤트 발행: Payload는 바뀐 정보만 보내야 할까?
단순하게 생각하면 데이터를 최소화하는 'Partial Update'가 정답 같았지만, 분산 환경의 특성을 고려하니 이야기가 달라졌다. 결국 MVP 단계에서는 핵심 필드를 포함한 Full Body(상태 스냅샷)를 보내는 것이 시스템 안정성 면에서 훨씬 유리하다는 결론을 내리게 되었다. 그 구체적인 이유는 다음과 같다.
- 왜 '수정된 필드'만 보내면 안 되는가? (Partial Update의 함정)
수정된 필드만 보내면 패킷의 크기를 줄여 네트워크 비용을 아낄 수 있지만, 분산 시스템 환경에서는 다음과 같은 치명적인 문제가 발생한다.
순서 보장 및 정합성 문제: 네트워크 지연 등으로 Kafka 파티션 내 이벤트 처리 순서가 꼬일 경우(Update A -> Update B가 뒤바뀜), 부분 필드 업데이트는 데이터 상태를 예측 불가능하게 만든다.
Consumer의 복잡도 증가: 만약 정보를 받는 서비스가 유저 프로필의 일부를 자신의 DB에 복사본(Replica)으로 들고 있는 형태라면, 바뀐 정보만 왔을 때 문제가 생긴다. 기존 데이터와 수신한 변경 데이터를 합치기(Merge) 위해 매번 자신의 DB를 조회해야 하며, 이는 곧 성능 저하와 로직의 복잡성으로 이어진다.
결국 송신 측(Producer)의 작은 최적화가 수신 측(Consumer)의 데이터 정합성 리스크와 불필요한 DB 조회 비용이라는 거대한 부담으로 돌아가는 셈이다.
- 운영을 해봐야 '진정한 최적화'가 가능하다
현재 구축 중인 거래 서비스와 모임 서비스가 유저의 어떤 정보를 '정말로' 자주 사용할지는 실제 운영 데이터가 쌓여야 정확히 판단할 수 있다.
지금 당장은 isSuspended(정지 여부) 상태 값만 중요해 보이지만, 추후 "유저 평점에 따라 가입 가능한 모임을 제한하자"는 기획이 추가된다면 어떨까? 이때마다 이벤트를 수정하고 여러 서비스를 재배포하는 비용보다, 처음부터 비즈니스 핵심 필드들을 세트로 묶어 발행하는 것이 향후 변경에 훨씬 유연하게 대응할 수 있는 전략이다.
- Consumer별 다양한 요구사항 대응
마이크로서비스마다 유저 정보에 대해 기대하는 바는 제각각이다.
거래 서비스: 주로 평점(Rating)과 정지 여부(isSuspended)가 궁금하다.
모임 서비스: 주로 권한(Role)과 화면에 표시할 닉네임(Nickname)이 궁금하다.
Full Body 방식을 선택하면, 각 서비스는 공통된 이벤트를 수신한 뒤 본인들에게 필요한 정보만 골라 쓰고 나머지는 무시하면 된다. 이는 "보내는 쪽은 엄격하게 표준을 지키고, 받는 쪽은 필요한 것만 관대하게 수용하는" MSA의 견고한 원칙(Postel's Law)을 시스템에 적용하는 것과 같다.
- "도메인 스냅샷"으로서의 Full Body
여기서 말하는 Full Body는 비밀번호나 전화번호 같은 민감한 개인정보까지 모두 포함한 DB의 전체 복사본이 아니다. 비즈니스 의사결정에 필요한 최소한의 필수 필드 세트를 의미한다.
권장 페이로드 구성 예시: userId, nickname, role, rating, isSuspended, updatedAt
이 방식은 사용하지 않는 정보는 DTO 설계 단계에서 아예 제외하여 브로커의 통신 낭비를 막는다. 반면 포함된 필드들은 일부 값만 변경되었더라도 항상 '전체 최신 상태'를 담아 보냄으로써, Consumer가 별도의 User DB 조회 없이 즉시 비즈니스 로직을 수행할 수 있게 한다.
💡 마치며: 설계의 관점 변화
조회 API가 손님이 원하는 걸 골라 담는 '뷔페'라면, 이벤트는 받은 사람이 추가적인 고민 없이 바로 먹기만 하면 되는 '완성된 한 상'이어야 한다.
단순히 "무엇이 바뀌었다"는 단편적인 사실만 툭 던지는 게 아니라, "이 유저의 현재 모습은 이렇다"는 최종 결과를 통째로 전달하는 방식을 선택했다. 데이터가 조금 무거워지더라도, 이렇게 해야 정보를 받는 쪽에서 따로 기존 데이터를 찾아보거나 합치는 수고를 덜 수 있기 때문이다.
또한, 설령 중간에 이벤트 하나를 놓치는 배달 사고가 나더라도, 다음 이벤트가 도착하는 순간 다시 최신 정보로 채워질 수 있다. 시스템이 따로 손대지 않아도 스스로 오류를 이겨내는 힘을 갖게 되는 셈이다.
결국 내가 코딩하기 편한 방식보다 데이터를 받는 사람(Consumer)이 작업하기 편한 방식을 고민하는 것이, 전체 시스템을 훨씬 안정적으로 만드는 지름길이라는 것을 배울 수 있었던 유익한 과정이었다.
Kafka
KRaft 모드 사용 이유
Kafka 4.0 부터 Zookeeper 지원 중단 → 미래 대비
컨테이너 1개 줄어듦
Bitnami 가 Docker Hub 에 새 버전 안 올림
ObjectMapper 직접 매핑 (TypeId 헤더 미사용)
TypeId 헤더의 문제
Spring Kafka 의 기본 동작:
[Producer]
KafkaTemplate.send("topic", event)
↓
JSON 으로 직렬화 + Header 에 __TypeId__ 추가
↓
__TypeId__ = "com.pagely.bookservice.domain.event.payload.BookSearchedEvent"
↓
Kafka 에 전송
[Consumer]
Kafka 에서 받음
↓
__TypeId__ 헤더 확인 = "com.pagely.bookservice.domain.event.payload.BookSearchedEvent"
↓
"이 클래스 내 클래스패스에 있나?"
↓
❌ 없음 — Consumer 의 패키지는 com.pagely.aiservice.ai.infrastructure...Producer 와 Consumer 가 같은 패키지 경로 가져야 작동 (Producer ↔ Consumer 결합도 ↑)
MSA 에서는 각 서비스가 자기 패키지 → 경로 다름
매핑 설정 (spring.json.type.mapping) 으로 해결 가능하지만 운영 부담 ↑
다른 언어 (Python, Node.js) Consumer 는 Java 타입 헤더 의미 없음 = Polyglot 환경 (Java + Python + Node.js 혼용)
ObjectMapper 직접 매핑
[Producer 측]
- JSON 직렬화 (헤더에 TypeId 안 넣음)
spring.json.add.type.headers: false
[Consumer 측]
- String 으로 받음
value-deserializer: StringDeserializer
- ObjectMapper 로 자기 클래스에 매핑
BookSearchedEvent event = objectMapper.readValue(json, BookSearchedEvent.class);장점:
- Producer/Consumer 클래스 경로 의존 없음
- 다른 언어 Consumer 호환
- 이벤트 구조만 일치하면 됨
단점:
- 타입 안전성 ↓ (런타임에 매핑 실패 가능)
- 필드 누락 / Nullable 검증 필요
Topic
메시지가 목적지별로 분류되는 카테고리나 논리적인 채널 (예: "회원가입 이벤트 채널", "결제 완료 채널")
주제(Topic)'별로 게시판을 만들어놓고 "알아서 가져가" 하는 방식
토픽 이름 규칙 {domain}.{event}
팀 문서에 따름
meeting.created
meeting.schedule.created
meeting.schedule.status-changed
meeting.attendance.joined
meeting.attendance.status-changed
(이벤트별 토픽 분리)장점:
- Consumer 가 필요한 토픽만 구독 가능
- 토픽별 정책 차별화 가능 (retention, partition 수 등)
- 토픽 이름만 봐도 무슨 이벤트인지 명확
단점:
- 토픽 수 많아짐 (이벤트마다 1개)
- 운영 부담 ↑
Outbox/Inbox 서비스 별 분리 vs 공통
팀 문서 결론: 서비스별 분리
1. 공통 Outbox/Inbox Repository 사용 (중앙 집중형 테이블)
모든 서비스가 단 하나의 outbox 테이블을 같이 사용하는 방식
물리적 구조: 전체 시스템에 DB 테이블이 1개뿐이다.
WHERE 절의 필요성):
하나의 테이블에 '회원가입 이벤트', '거래 생성 이벤트', '모임 생성 이벤트'가 전부 뒤섞여 저장된다.
만약 '모임 서비스'의 스케줄러(Polling)가 이벤트를 주워다 카프카에 발행하려고 할 때,
전체 테이블을 그냥 긁어오면 '거래 생성 이벤트'까지 가져오게 되는 대참사가 발생
따라서 모임 서비스는 쿼리를 날릴 때 반드시 WHERE domainType = "MEETING" 같은 조건을 걸어서 자기 이벤트만 골라내야함
"자신이 발행하는 모든 이벤트의 domainType들이 where 조건에 추가될 수 있음"
치명적 단점:
모든 트래픽이 한 테이블로 몰리니 DB 병목 현상이 생기고,
모임 서비스 테이블에 문제가 생기면 거래 서비스 이벤트 발행도 멈추는(단일 장애점) MSA의 안티 패턴
서비스별 Outbox/Inbox 분리 (독립 테이블 - 💡채택된 방식)
각 서비스가 자신의 DB에 자신만의 outbox 테이블을 따로 쪼개어 가지는 방식
물리적 구조:
거래 서비스 DB에 trade_outbox 테이블 1개,
모임 서비스 DB에 meeting_outbox 테이블 1개
...(총 N개)
WHERE 절이 필요 없는 이유):
모임 서비스의 스케줄러는 자기 DB에 있는 meeting_outbox 테이블만 보면된다.(이 테이블엔 100% 모임 관련 이벤트만 들어있다.)
그래서 복잡하게 WHERE 절로 필터링할 필요 없이,
SELECT * FROM outbox ORDER BY 생성일 LIMIT 10 처럼
가장 오래된 순서대로 단순히 퍼올리기만 하면 되어 훨씬 로직이 단순해진다.
아웃박스 패턴(Outbox Pattern)
Outbox 패턴:
DB 트랜잭션 안에서 Outbox 테이블에 저장
→ 별도 Poller 가 Kafka 로 발행
→ DB 와 Kafka 가 분리됨Outbox 저장의 핵심 — 같은 트랜잭션에 묶기
목표: User 저장과 Outbox 저장을 원자적으로 (: 둘 다 성공 or 둘 다 실패)
BEFORE_COMMIT 시점
[1] @Transactional 시작
[2] userRepository.save(user) — DB INSERT
[3] eventPublisher.publishEvent(...) — Spring 이벤트 발행
[4] @TransactionalEventListener(BEFORE_COMMIT) 호출
└ outboxRepository.save(outbox) — DB INSERT (같은 트랜잭션 안)
[5] 트랜잭션 커밋 ✅
└ User INSERT + Outbox INSERT 동시 커밋AFTER_COMMIT 시점
[1] @Transactional 시작
[2] userRepository.save(user) — DB INSERT
[3] eventPublisher.publishEvent(...)
[4] 트랜잭션 커밋 ✅ — User 저장 확정
[5] @TransactionalEventListener(AFTER_COMMIT) 호출
└ outboxRepository.save(outbox) — 새 트랜잭션
[6] 만약 여기서 실패하면? ❌
→ User 는 이미 저장됨, Outbox 는 없음
→ **불일치 발생**Kafka 발행은 트랜잭션 밖 Outbox Poller 에서
┌──────────────────────────────────────────────────────────┐
│ @Transactional 안에서 │
│ │
│ ┌────────────────────┐ │
│ │ UserApplicationService.signup() │
│ └─────────┬──────────┘ │
│ │ │
│ ▼ │
│ userRepository.save(user) ← INSERT │
│ │ │
│ ▼ │
│ eventPublisher.publishEvent(...) ← Spring 이벤트 │
│ │ │
│ ▼ │
│ @TransactionalEventListener(BEFORE_COMMIT) │
│ │ │
│ ▼ │
│ outboxRepository.save(outbox) ← INSERT │
│ │ │
│ 트랜잭션 커밋 ✅ │
│ (User + Outbox 함께 커밋 — 원자성) │
└──────────────────────────────────────────────────────────┘
별도 스레드 (스케줄러)
↓
┌──────────────────────────────────────────────────────────┐
│ OutboxPoller @Scheduled │
│ │
│ 1. published=false 인 Outbox 조회 │
│ 2. kafkaTemplate.send(topic, payload) │
│ 3. 성공 시 published=true │
│ 4. 실패 시 그대로 (다음 사이클에서 재시도) │
└──────────────────────────────────────────────────────────┘
↓
Kafka Broker
↓
Consumer (다른 서비스)정합성
메시지 전달 보장 수준 (Delivery Semantics)
분산 시스템에서 메시지를 보낼 때 보장 수준은 3가지로 나뉜다.
At-most-once (최대 1회)
"메시지가 손실될 수 있지만 절대 중복되지 않음"
[Producer] → 발행 시도 → [Broker]
실패 시?
→ 재시도 안 함 (포기)예:
IoT 센서 (온도 측정) — 한 번 측정값 놓쳐도 다음 값 받으면 됨
비핵심 로깅
위험: 이벤트 손실. 회원가입 같은 중요 이벤트엔 부적합.
At-least-once (최소 1회)
"메시지가 절대 손실되지 않지만 중복될 수 있음"
[Producer] → 발행 시도 → [Broker]
실패 시 재시도
→ 같은 메시지 두 번 갈 수 있음예:
Outbox 패턴 ⭐ (우리가 만들 것)
일반적인 분산 시스템 기본값
조건: Consumer 가 idempotent (멱등) 해야 안전.
멱등성:
[Outbox Poller]
publish UserCreatedEvent {userId: alice} → Kafka
Kafka 응답 받기 전 timeout
→ Poller 가 재시도
→ 같은 이벤트 또 발행
[Notification Service Consumer]
receive UserCreatedEvent {userId: alice}
→ "alice 환영 메일 발송"
receive UserCreatedEvent {userId: alice} ← 중복!
→ 또 발송하면? alice 가 환영 메일 두 번 받음 ❌Exactly-once (정확히 1회)
"손실도 중복도 없음"
이상적이지만 분산 환경에서 매우 어려움.
Kafka 0.11+ 에서 부분적 지원 (Kafka 내부에 한해).조건:
Producer / Consumer / Broker 모두 협조
트랜잭션 모드 활성화
성능 비용 ↑
예:
결제 금액 차감 (절대 두 번 안 됨)
송금
현실: 대부분 시스템이 At-least-once + idempotent Consumer 조합으로 exactly-once "효과" 를 냄.
Ordering (순서 보장)
시간 순서:
[t1] alice 가입
[t2] alice 가 닉네임 변경 (alice → ALICE)
이벤트 발행:
UserCreatedEvent {nickname: "alice"}
UserNicknameChangedEvent {old: "alice", new: "ALICE"}
Consumer 가 받는 순서:
케이스 a: Created → Changed (정상)
케이스 b: Changed → Created (역순 도착)
↑
alice 도 모르는데 ALICE 로 바뀌었다는 이벤트 먼저?
→ 처리 불가Kafka 의 구조:
Topic: user.created
├── Partition 0 ────────── Consumer 1 처리
├── Partition 1 ────────── Consumer 2 처리
└── Partition 2 ────────── Consumer 3 처리
Partition 안에서는 순서 보장 ✅
Partition 사이에서는 순서 보장 X ❌해결: 메시지 키로 같은 파티션 보내기
kafkaTemplate.send(
"user.created",
event.getDomainId(), // ← 메시지 키 (UUID)
event
);Kafka 의 동작:
메시지 키가 같으면 → 항상 같은 파티션 에 들어감
같은 파티션 안에서는 순서 보장
→ 같은 alice 의 이벤트는 모두 같은 파티션 → 순서 유지
domainId 를 키로 = 같은 entity 의 이벤트는 같은 파티션 → 순서 보장.
kafkaTemplate.send(
topic,
event.getDomainId(), // ← 메시지 키로 사용
event
);Inbox 패턴
Outbox: Producer 측의 안전 장치
└ DB 트랜잭션 안에서 이벤트 기록 → Poller 가 발행
Inbox: Consumer 측의 안전 장치
└ 받은 이벤트 ID 기록 → 중복 방지 + 처리 진행 추적흐름
[Consumer 측]
receive event from Kafka
↓
@Transactional 시작
├─ Inbox 에 event_id 저장 시도
│ ├─ 이미 있음? → 중복! 처리 무시
│ └─ 새 이벤트? → 저장
├─ 비즈니스 로직 실행 (sendWelcomeEmail 등)
└─ Inbox 의 처리 상태 PROCESSED 마킹
↓
트랜잭션 커밋CREATE TABLE p_inbox (
event_id UUID PRIMARY KEY,
received_at TIMESTAMP,
processed_at TIMESTAMP,
payload JSONB
);@Transactional
public void handle(UserCreatedEvent event) {
// 1. 중복 체크 + 기록
if (inboxRepository.existsByEventId(event.getEventId())) {
log.info("이미 처리된 이벤트, 무시: {}", event.getEventId());
return;
}
inboxRepository.save(new InboxEntry(event.getEventId(), event));
// 2. 비즈니스 처리
sendWelcomeEmail(event);
// 3. 처리 완료 마킹
inboxRepository.markProcessed(event.getEventId());
// 트랜잭션 커밋 시 함께 처리
}Inbox 의 효과
- 중복 방지: 같은 event_id 두 번 들어오면 두 번째 무시
- 처리 추적: 받았지만 처리 못 한 이벤트 추적 가능
- 재시도 안전: 처리 중 실패 시 다시 처리해도 안전
이벤트 발행 :
kafka 설정
dependencies {
// ... 기존 의존성
// Kafka
implementation 'org.springframework.kafka:spring-kafka'
// ... 기존 계속
}spring:
application:
name: user-service
# ... 기존 spring 설정
kafka:
bootstrap-servers: ${KAFKA_BOOTSTRAP_SERVERS:localhost:9092}
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
spring.json.add.type.headers: false # TypeId 헤더 비활성화
# 신뢰성 보강 (선택)
acks: all # 모든 ISR 에 복제 확인 후 ACK
retries: 3 # 발행 실패 시 재시도 횟수
enable.idempotence: true # 중복 발행 방지 (Producer 측)
# ... 기존 다른 섹션bootstrap-servers
Kafka 브로커 주소
환경변수로 외부화 → 로컬/스테이징/운영 다른 값
기본값: localhost:9092 (로컬 개발)
key-serializer: StringSerializer
메시지 키는 String (UUID 문자열)
value-serializer: JsonSerializer
메시지 값은 JSON 직렬화
ObjectMapper 자동 사용
spring.json.add.type.headers: false ⭐
__TypeId__ 헤더 안 넣음
Consumer 가 ObjectMapper 직접 매핑ISR(In-Sync Replicas) = 리더(Leader) 파티션의 데이터를 완벽하게 따라잡고 있는 복제본(Follower)들의 그룹
acks: all =리더 + 모든 ISR 복제 후 ACK (가장 안전)
acks: 1 = 리더만 받으면 ACK (균형)
acks: 0 = ACK 안 받음 (가장 빠름, 손실 가능)
retries:3 = 발행 실패 시 3번 재시도
enable.idempotence: true = 같은 메시지 중복 발행 방지 (Producer 측 Exactly-once)
[Producer]
메시지 발행
→ Kafka 가 ACK 보냄
→ 네트워크 지연으로 Producer 가 ACK 못 받음
→ Producer 가 재시도 → 같은 메시지 또 발행 ❌
[idempotence=true]
Producer 가 각 메시지에 시퀀스 번호 부여
Kafka 가 시퀀스 추적 → 중복 발행 자동 무시
→ 발행 단계의 멱등성 보장 ⭐- 추가로 Outbox 의 published=true 마킹 으로 한 번 더 보호
Outbox 테이블 (Flyway)
-- Outbox 테이블 — Outbox 패턴의 핵심
-- DB 트랜잭션 안에서 이벤트 기록 → 별도 Poller 가 Kafka 로 발행
-- 트랜잭션 일관성 보장 (User 저장 = 이벤트 기록 원자적)
CREATE TABLE p_outbox
(
-- 기본 식별자
id UUID PRIMARY KEY,
-- 이벤트 메타
aggregate_type VARCHAR(50) NOT NULL, -- USER, MEETING 등
aggregate_id UUID NOT NULL, -- 엔티티 ID (메시지 키로 활용)
event_type VARCHAR(100) NOT NULL, -- USER_CREATED, USER_UPDATED 등
topic VARCHAR(100) NOT NULL, -- user.created, user.updated 등
-- 페이로드
payload JSONB NOT NULL, -- 이벤트 본문 (JSON)
-- 발행 추적
published BOOLEAN NOT NULL DEFAULT FALSE,
published_at TIMESTAMP,
failure_count INT NOT NULL DEFAULT 0,
last_failure_at TIMESTAMP,
last_failure_message TEXT,
-- 감사 필드 (BaseEntity 와 동일)
created_at TIMESTAMP NOT NULL,
created_by UUID NOT NULL,
updated_at TIMESTAMP,
updated_by UUID,
deleted_at TIMESTAMP,
deleted_by UUID
);
-- Poller 가 가장 자주 사용할 인덱스
-- "미발행 이벤트를 created_at 순으로 조회"
CREATE INDEX idx_outbox_unpublished
ON p_outbox (created_at)
WHERE published = FALSE AND deleted_at IS NULL;
-- 디버깅 / 운영용 — 특정 aggregate 의 이벤트 조회
CREATE INDEX idx_outbox_aggregate
ON p_outbox (aggregate_type, aggregate_id)
WHERE deleted_at IS NULL;
-- 코멘트 (PostgreSQL)
COMMENT ON TABLE p_outbox IS 'Outbox 패턴 이벤트 저장소. Poller 가 published=false 인 이벤트를 Kafka 로 발행';
COMMENT ON COLUMN p_outbox.aggregate_type IS '이벤트가 속한 도메인 타입 (USER, MEETING 등)';
COMMENT ON COLUMN p_outbox.aggregate_id IS '이벤트의 entity ID. Kafka 메시지 키로 사용 (순서 보장)';
COMMENT ON COLUMN p_outbox.event_type IS '구체적 이벤트 타입 (USER_CREATED 등)';
COMMENT ON COLUMN p_outbox.topic IS '발행 대상 Kafka 토픽 (user.created 등)';
COMMENT ON COLUMN p_outbox.payload IS '이벤트 본문 JSON';
COMMENT ON COLUMN p_outbox.published IS '발행 완료 여부';
COMMENT ON COLUMN p_outbox.failure_count IS '발행 실패 횟수 (재시도 추적)';이벤트 페이로드 검색/필터링 가능성 있어 JSONB 사용
PostgreSQL 의 JSONB:
바이너리 JSON 형식
인덱싱 가능 (GIN)
JSON 연산자 사용 가능 (->>, @> 등)
TEXT 보다 약간 더 무거움
미발행 이벤트만 인덱스 (Partial Index)
Partial Index = 특정 조건의 행만 인덱스에 포함하는 것
미발행 이벤트만 인덱스 → 인덱스 크기 ↓
Poller 가 항상 WHERE published = FALSE 로 조회
Poller가 발행 실패 시 카운트와 메시지 기록
failure_count INT,
last_failure_at TIMESTAMP,
last_failure_message TEXT,향후 운영 도구에 활용할 수 있음:
실패 횟수 많은 이벤트 알림
일정 횟수 초과 시 DLQ 로 이동
OutBox 엔티티
package com.pagely.userservice.infrastructure.messaging.outbox;
import com.pagely.common.entity.BaseEntity;
import org.springframework.data.domain.Persistable;
/**
* Outbox 패턴의 이벤트 저장 엔티티.
*
* <p><b>생명주기</b></p>
* <ol>
* <li>도메인 트랜잭션 안에서 {@link #of} 로 생성 + 저장 (published=false)</li>
* <li>OutboxPoller 가 미발행 이벤트 조회</li>
* <li>Kafka 발행 성공 시 {@link #markPublished} 호출 → published=true</li>
* <li>발행 실패 시 {@link #recordFailure} 호출 → failure_count++</li>
* </ol>
*
* <p><b>id 와 aggregate_id 차이</b></p>
* <ul>
* <li>id: Outbox 엔티티 자체의 PK (UUID 자동 생성)</li>
* <li>aggregate_id: 이벤트가 가리키는 도메인의 엔티티의 ID (예: User.id)</li>
* </ul>
*/
@Entity
@Getter
@Table(name = "p_outbox")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class OutboxEvent extends BaseEntity implements Persistable<UUID> {
@Id
@Column(columnDefinition = "UUID")
private UUID id;
@Column(name = "aggregate_type", nullable = false, length = 50)
private String aggregateType;
@Column(name = "aggregate_id", nullable = false, columnDefinition = "UUID")
private UUID aggregateId;
@Column(name = "event_type", nullable = false, length = 100)
private String eventType;
@Column(name = "topic", nullable = false, length = 100)
private String topic;
/**
* JSON 직렬화된 이벤트 페이로드. Hibernate 6+ 가 String → JSONB 자동 매핑.
*/
@JdbcTypeCode(SqlTypes.JSON)
@Column(name = "payload", nullable = false, columnDefinition = "JSONB")
private String payload;
@Column(name = "published", nullable = false)
private boolean published;
@Column(name = "published_at")
private LocalDateTime publishedAt;
@Column(name = "failure_count", nullable = false)
private int failureCount;
@Column(name = "last_failure_at")
private LocalDateTime lastFailureAt;
@Column(name = "last_failure_message", columnDefinition = "TEXT")
private String lastFailureMessage;
// ====================================================================
// 팩토리 메서드
// ====================================================================
/**
* 새 Outbox 이벤트 생성.
*/
public static OutboxEvent of(
String aggregateType,
UUID aggregateId,
String eventType,
String topic,
String payload
) {
if (aggregateType == null || aggregateType.isBlank()) {
throw new IllegalArgumentException("aggregateType 은 필수입니다.");
}
if (aggregateId == null) {
throw new IllegalArgumentException("aggregateId 는 필수입니다.");
}
if (eventType == null || eventType.isBlank()) {
throw new IllegalArgumentException("eventType 은 필수입니다.");
}
if (topic == null || topic.isBlank()) {
throw new IllegalArgumentException("topic 은 필수입니다.");
}
if (payload == null || payload.isBlank()) {
throw new IllegalArgumentException("payload 는 필수입니다.");
}
OutboxEvent event = new OutboxEvent();
event.id = UUID.randomUUID();
event.aggregateType = aggregateType;
event.aggregateId = aggregateId;
event.eventType = eventType;
event.topic = topic;
event.payload = payload;
event.published = false;
event.failureCount = 0;
return event;
}
// ====================================================================
// 상태 변경
// ====================================================================
/**
* 발행 성공 마킹.
*/
public void markPublished() {
this.published = true;
this.publishedAt = LocalDateTime.now();
}
/**
* 발행 실패 기록.
*/
public void recordFailure(String message) {
this.failureCount++;
this.lastFailureAt = LocalDateTime.now();
this.lastFailureMessage = truncateMessage(message);
}
private String truncateMessage(String message) {
if (message == null) {
return null;
}
// 저장할 때 DB 부하 방지, 읽어올 때 메모리 절약, DB허용 길이 초과시 데이터 저장 자체 실패를 미리 방지
return message.length() > 2000 ? message.substring(0, 2000) : message;
}
// ====================================================================
// Persistable 구현
// ====================================================================
@Override
public boolean isNew() {
return getCreatedAt() == null;
}
}
JPA 기능을 활용한 JSONB 매핑
@JdbcTypeCode(SqlTypes.JSON)
@Column(name = "payload", nullable = false, columnDefinition = "JSONB")
private String payload;메시지 브로커로 전달할 실제 데이터(이벤트 본문)를 저장하는 필드.
애플리케이션 코드에서는 다루기 쉬운 String 타입을,
DB에 저장될 때는 Hibernate 6의 @JdbcTypeCode를 통해 JSONB 타입으로 자동 변환되도록 처리한다.
도메인 이벤트 Repository
package com.pagely.userservice.infrastructure.messaging.outbox;
import com.pagely.userservice.infrastructure.persistence.jpa.JpaOutboxRepository;
@Repository
@RequiredArgsConstructor
public class OutboxRepositoryAdapter implements OutboxRepository {
private final JpaOutboxRepository jpaRepository;
@Override
public OutboxEvent save(OutboxEvent event) {
return jpaRepository.save(event);
}
@Override
public List<OutboxEvent> findUnpublished(Pageable pageable) {
return jpaRepository.findUnpublished(pageable);
}
@Override
public List<OutboxEvent> findFailedExceedingThreshold(int threshold, Pageable pageable) {
return jpaRepository.findFailedExceedingThreshold(threshold, pageable);
}
}
도메인 이벤트
BaseEvent
private final String eventId; // String (UUID.toString)
private final String eventType; // 자동 = getClass().getSimpleName()
private final String domainType;
private final String domainId; // String
private final Instant occurredAt; // UTC
private final Object payload;생성자:
(String domainType, UUID domainId, Object payload) - domainId
(String domainType, Object payload) — domainId 없는 케이스
(String domainType, String domainId, Object payload) — 메인 생성자UserCreatedEvent
public class UserCreatedEvent extends BaseEvent {
public static final String DOMAIN_TYPE = "USER";
public static final String TOPIC = "user.created";
private UserCreatedEvent(UUID userId, Payload payload) {
super(DOMAIN_TYPE, userId, payload);
}
public static UserCreatedEvent from(User user) { ... }
public record Payload(
UUID userId,
String loginId,
String email,
String nickname,
Role role,
LocalDateTime createdAt
) {
}
}Consumer
ObjectMapper mapper = new ObjectMapper();
mapper.registerModule(new JavaTimeModule());
// JSON → record
UserCreatedEvent event = mapper.readValue(json, UserCreatedEvent.class);
// 단, BaseEvent 의 payload 가 Object 라
// Consumer 가 명시적으로 record 로 매핑 필요
JsonNode payloadNode = ...;
UserCreatedEvent.Payload payload = mapper.treeToValue(payloadNode, UserCreatedEvent.Payload.class);
RESTfull 엔드포인트 구조
월요일 MVP 시연을 앞두고, API문서를 정리하다가 권한 분리를 하게되면서 원래의 API문서와 달라진점이 꽤 많다는 것을 알게되었다.

특히 개발을 하면서, "/me" 나, "/admin" 등 URL에 순수한 자원에 대한 정보가 아닌, 권한에 대한 정보가 나타나게 된것이 RESTful 구조에서 벗어난게 아닌가 걱정이 됐다.
권한에 따른 엔드포인트 분리 이유
개발 중, 권한에 따른 엔드포인트를 분리(GET /me와 GET /{userId} )하고,
서비스 레이어에는 권한 검증 로직을 넣지 않는 것으로 결론을 내렸다.
- 서비스 레이어의 오염 방지 (관심사의 분리)
엔드포인트를 합쳐서 서비스 레이어로 넘기면 향후 관리가 굉장히 힘들어집니다.
만약 컨트롤러 코드에서getUser(currentUserId, targetUserId, role)같은 형태로 서비스에 넘기게 되면, 아래와 같이 서비스 레이어에 프레젠테이션/권한 계층의 로직이 섞이게 된다.
if (!currentUserId.equals(targetUserId) && role != Role.MASTER) {
throw new ForbiddenException();
} ...여기에 나중에 서비스 확장으로 Role.CREATOR(작가/출판사)나 Role.SYSTEM(내부 배치) 같은 권한이 추가되면 서비스 코드를 계속 수정해야한다. (처음엔 Stretegy 패턴으로 추상화를 통해 복잡한 분기를 감추면 해결 할 수 있다고 생각해 시도해보았는데, 코드 이해와 DTO구현체 관리가 힘들 것 같아 방법을 바꿨다.)
결국 권한 검증은 지금처럼 컨트롤러의 @AuthRequired로(권한을 검증하는 커스텀 어노테이션) 프레젠테이션 레이어에서 끝내고,
서비스 레이어는 "id가 주어지면 유저 데이터를 반환한다"는 순수한 역할만 유지하는 것이 장기적인 시스템 안정성에 좋다고 판단했다.
- 조회 응답 데이터(DTO)의 형태와 적용되는 비즈니스 로직이 다름
관리자용 조회 엔드포인트에서는 유저 정보에 더해 Auditing 정보까지 포함된AdminUserInfoResponse를 반환한다.
이외에도 일반 유저가 '내 정보'를 볼 때 필요한 데이터(닉네임, 성별 등)와, 관리자가 '특정 유저 정보'를 볼 때 필요한 데이터(가입일, 정지 여부 등)는 다르다.
엔드포인트를 하나로 합치면 이 DTO 분기 처리도 해줘야 하고, 한 컨트롤러 메서드가 두 가지 성격의 응답을 내려주게 되어 책임이 불분명해진다.
결론적으로, 권한 제어와 API 응답의 명확성을 위해 컨트롤러에서 엔드포인트를 나누고, 비즈니스 로직(서비스 레이어)은 순수하게 유지하는 현재의 접근 방식이 향후 확장성을 고려했을 때 훨씬 더 나은 설계
/me는 이미 훌륭한 RESTful 관례?
사실 /me는 Github, Spotify, Facebook 등 세계적인 기업들의 API에서도 표준처럼 사용하는 '가상의 자원 식별자(Virtual Resource Identifier)'다.
"현재 인증된 토큰의 주체"라는 특수한 자원을 가리키는 고유 명사처럼 취급되기 때문에, RESTful 원칙을 크게 훼손하지 않는다고 한다.
수정 결과

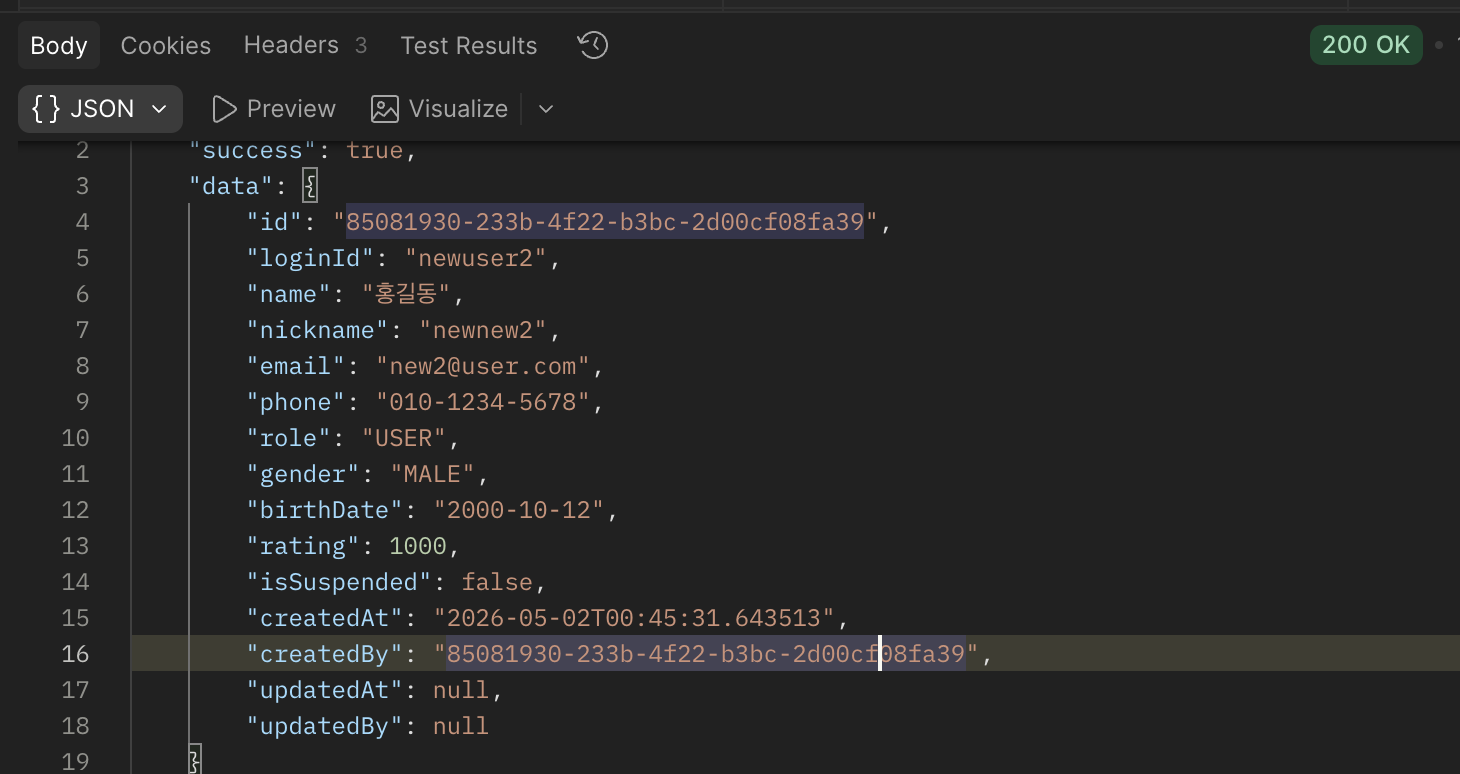
UserContext AuditAware 공통모듈 적용 후 CreatedBy 어플리케이션 주입이 안되는 오류 해결
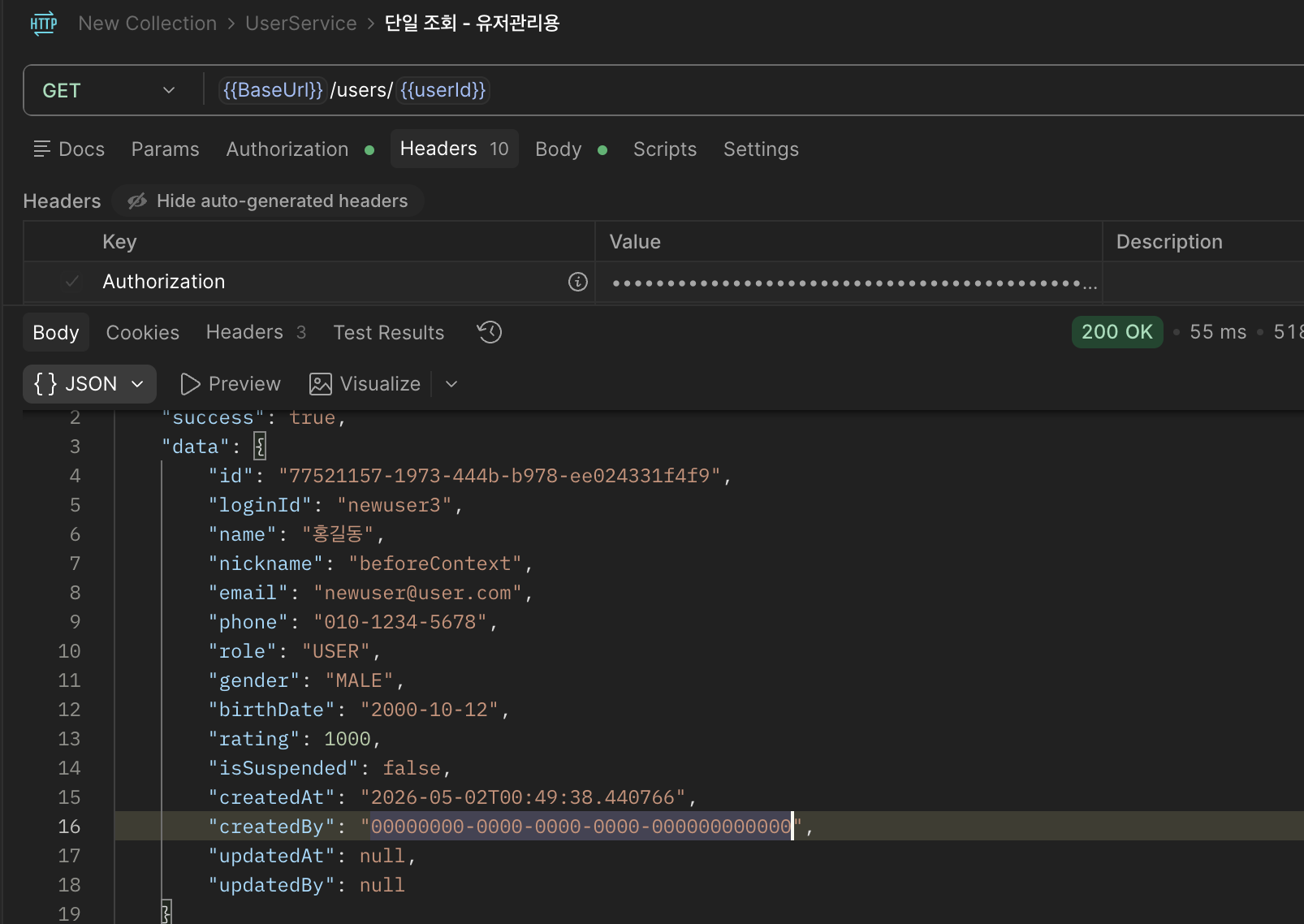
CreatedBy 자동 주입에 사용되는 AuditAware가 UserContext를 기반으로 동작하기 때문에, 이 UserContext에 정보를 채워넣어 해결했다.
// 회원가입 로직
...
// AuditorAware가 신규 유저 본인 ID를 읽어갈 수 있도록 컨텍스트 주입
UserContextHolder.set(new UserContext(user.getId(), user.getRole()));
try {
User saved = userRepository.save(user); // save() 대신 saveAndFlush()를 사용하여 즉시 제약 조건을 검사함
eventPublisher.publishEvent(UserCreatedEvent.from(saved));
return SignupResponse.from(saved);
} catch (DataIntegrityViolationException e) {
throw resolveDuplicateException(e);
} finally {
UserContextHolder.clear(); // ThreadLocal 정리
}
}
create 메서드에서도 Audit 부분을 지워준다.
public static User create(...) {
User user = new User();
user.id = UUID.randomUUID();
user.loginId = loginId;
user.email = email;
user.password = hashedPassword;
user.name = name;
user.role = Role.USER;
user.nickname = nickname;
user.phone = phone;
user.gender = gender;
user.birthDate = birthDate;
user.rating = 1000;
user.isSuspended = false;
// createdBy / updatedBy → AuditorAware가 채움
return user;
}