Kubeflow와 KRSH로 개발하는 ML Pipeline 맛보기
- kubeflow가 무엇이고 왜 사용하는지
- Python KFP library 활용 ML Pipeline 만들기
KRSH를 통해 선언형으로 파이프라인 관리 방법 알아보기
Kubeflow를 왜 사용하나요?
-
데이터 엔지니어링에서 많이 사용되는 Airflow와 비교되기도함
-
Airflow는 자체 Worker에서 동작함
-
Kubeflow는 Kubernetes 기반으로 동작함
-
모든 Task들이 각각 하나의 Kubeflow 전용 POD에서 작동함
-
Kubernetes의 리소스 스케줄링, 오케스트레이션을 ML Workflow를 만들때 사용할 수 있음
머신러닝 파이프라인은 무엇을 필요로 하나요?

- 동일한 실험을 언제든지 실행할 수 있어야함
- 수동으로 실행하지 않고 자동화시켜서 다른 도구들과 연동할 수 있어야함
- Kubeflow는 '다양한 리소스 할당'과 '타 리소스와의 충돌하지 않는'에 가장 큰 강점
Kubeflow의 Components
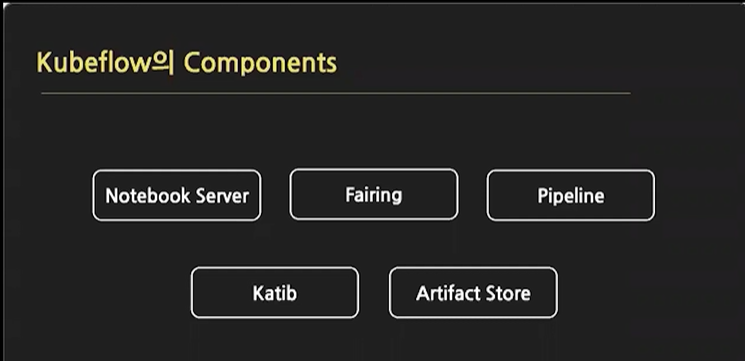
Notebook Server
- 주피터 노트북
- 원하는 사양의 리소스를 할당받음
- 모델 개발
- EDA
Fairing
- 파이프라인 코드를 쉽게 containerizing
- 코드를 kubeflow 파이프라인으로 배포
- Job을 쉽게 submit
Pipeline
- 가장 핵심적인 kubeflow의 components
- component를 연결하고 재사용하기 쉽게 관리
- ML 실험 사이클을 훨씬 빠르게 만들 수 있게함
- 'Argo Workflow'를 백엔드로 사용, Workflow의 각 Task를 컨테이너 기반으로 동작하게하는 도구
Katib : AutoML
- 하이퍼파라미터 Search, Neural Architecutre Search와 같은 AutoML Task를 Kubeflow 상에서 동작시킴
- Random Search, Grid Search ...
- 웹 UI에서 실행하거나 manifest를 작성해서 job을 실행할 수 있음
- 다수 AutoML 라이브러리 통합
Artifact Store
- 파이프라인의 metric와 같은 metadata이나 최종결과물을 저장
파이프 라인 개발 순서
- Notebook Server에서 리소스를 할당받고 Task를 작성
- Fairing을 통해 컨테이너화
- *Pipeline을 통해 배포
- Katib AutoML을 통해 모델 튜닝
- Artifact Store에 결과물 저장
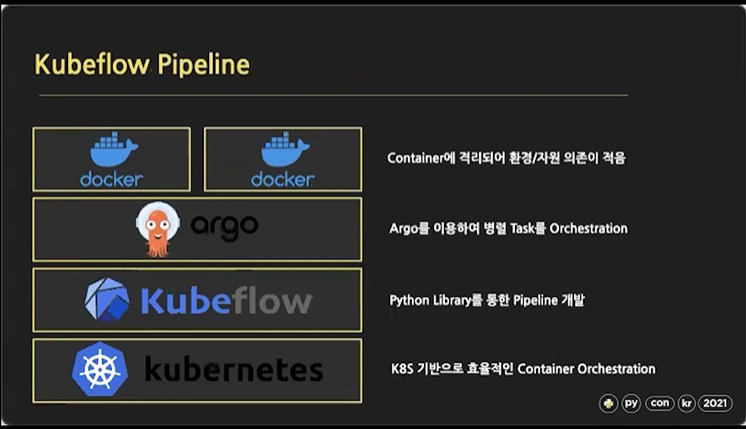
Kubeflow Pipeline
-
Kubeflow의 핵심 Component인 'Pipeline'
-
Kubeflow는 Kubernetes 기반으로 동작하기 때문에 Kubernetes의 모든 자원 관리 기능을 상속받아서 사용함
-
EX) Kubeflow의 Task는 Kubernetes의 POD로 치환되서 동작함
-
Pipeline을 하나 실행시키면 Kubeflow가 설치된 Kubernetes 클러스터에 Kubernetes 리소스 스케줄러에 기반해서 각각의 Node에 POD 형태로 정착하게 됌
-
Kubeflow는 Nvidia나 AMD의 GPU 자원도 요청하고 최대치를 제한할 수 있음
-
Argo는 하나의 Task가 하나의 Container로 동작하면서, 여러 병렬 Task를 실행할 수 있게하는 도구
-
Argo는 Kubeflow Pipeline의 실제 구현체
Python으로 Kubeflow 파이프라인 만들기

- Kubeflow 파이프라인은 기본적으로 계층적 구조
- 가장 상단에 'Pipeline' 개념 존재
- 아래에 1개의 Task를 의미하는 Component가 존재
- Component를 구현하는 Operation들이 존재
파이프라인에 입력 받은 문자열을 'Hello'와 같이 출력하는 간단한 Pipeline 만들기

- KFP 라이브러리의 'pipeline'이라는 데코레이터를 통해 Pipeline을 선언할 수 있음
- 데이코레이터가 달린 pipeline 함수의 인자들은 사용자가 Pipeline을 실행시킬 때 입력 인자로 주입할 수 있음 (현재 name 이라는 인자만 주입)
-
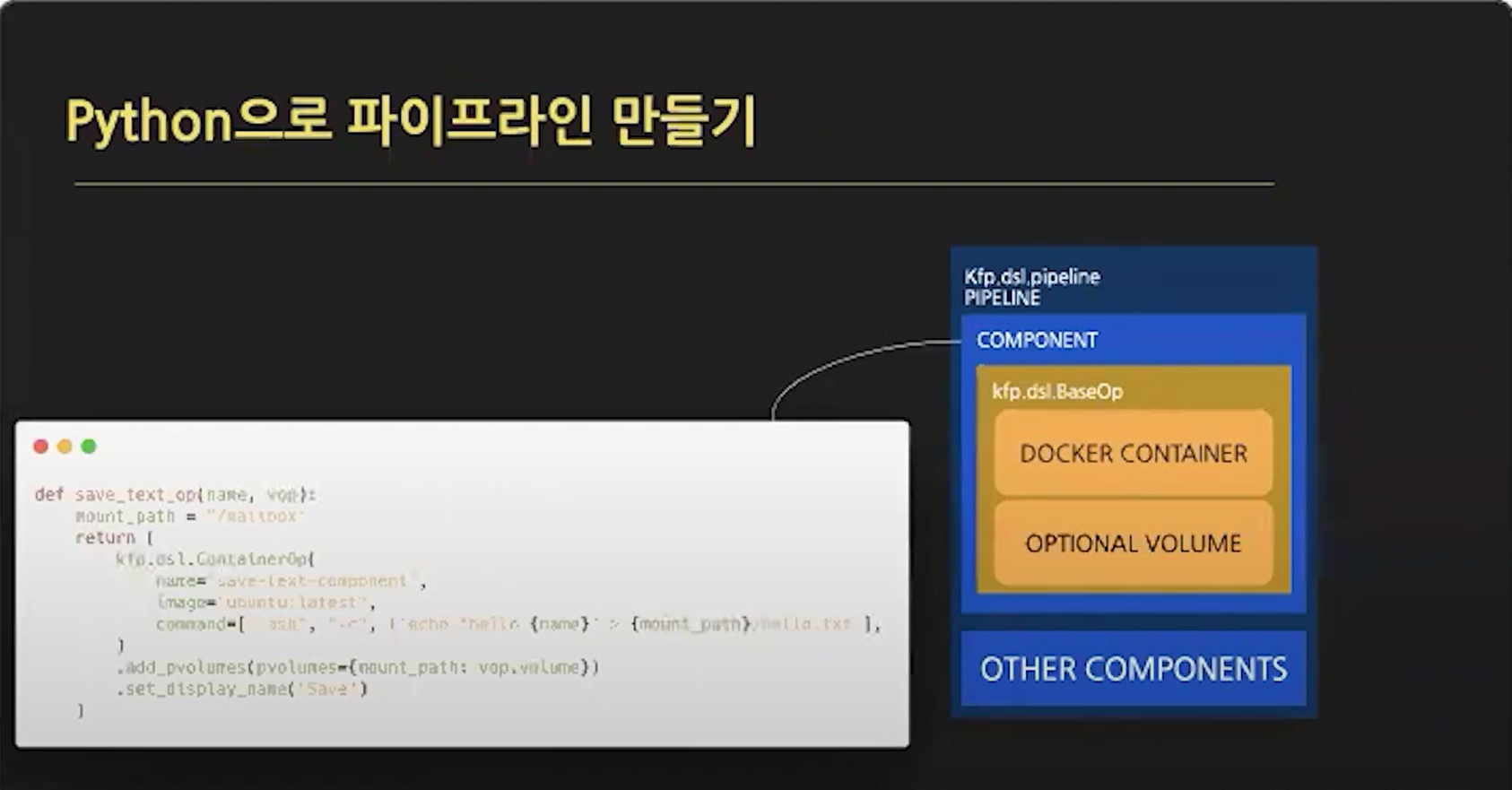
'save_text_op' Component
-
입력받은 이름을 공유 볼륨에 저장하는 Task
-
Pipeline을 선언하였고 Operation 기능으로 Component를 만듬
-
ContainerOp을 통해 Container 안에서 실제 기능을 수행하는 Component를 만들 수 있음
-
Container의 command 기반 수행
-
add_pvolume()를 통해 볼륨을 마운트
-
set_display_name()을 통해 해당 Component가 kubeflow UI상에 표기되는 이름 표기

- 'echo_op' Component
- 공유 볼륨에 저장한 파일을 읽어 출력하는 Task
- 'save_text_op'와 달리 Python 소스 코드 기반 수행
- func_to_container_op()을 통해 Python 코드를 기반으로 바로 컨테이너화된 component를 실행할 수 있음 (light weight python component)
- 도커 파일을 작성하고 빌드하고 ECR에 올리는 번거로운 작업이 필요 없음

- Component를 모두 만든 뒤 전체적인 Pipeline으로 연결하고자함
- VolumeOp()으로 공유 볼륨을 지정하고 'save_text_op', 'echo_op' Component 들을 실행함에 있어 이를 지정함
- after()를 통해 Component의 순서를 지정함
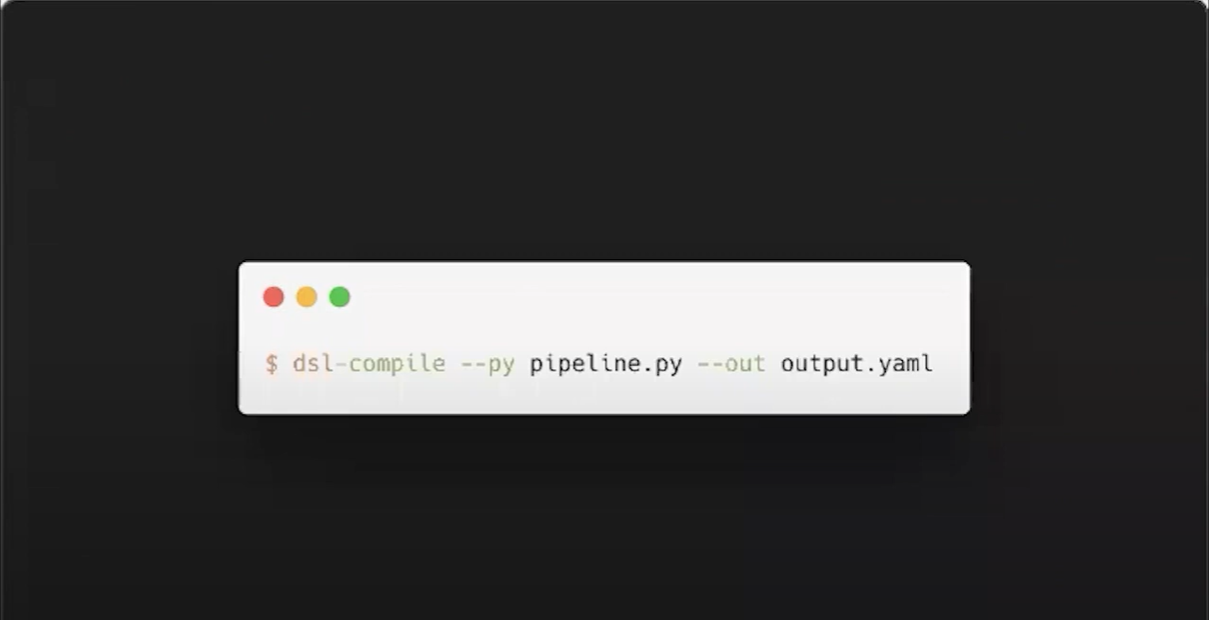
- 이전에 작성한 코드를 kubeflow pipeline으로 사용하기 위해 dsl로 만들어야함
dsl-compile --py <파이프라인_스크립트.py> --output <출력파일.yaml>- 파이프라인을 정의한 .py을 컴파일하여 .yaml로 저장
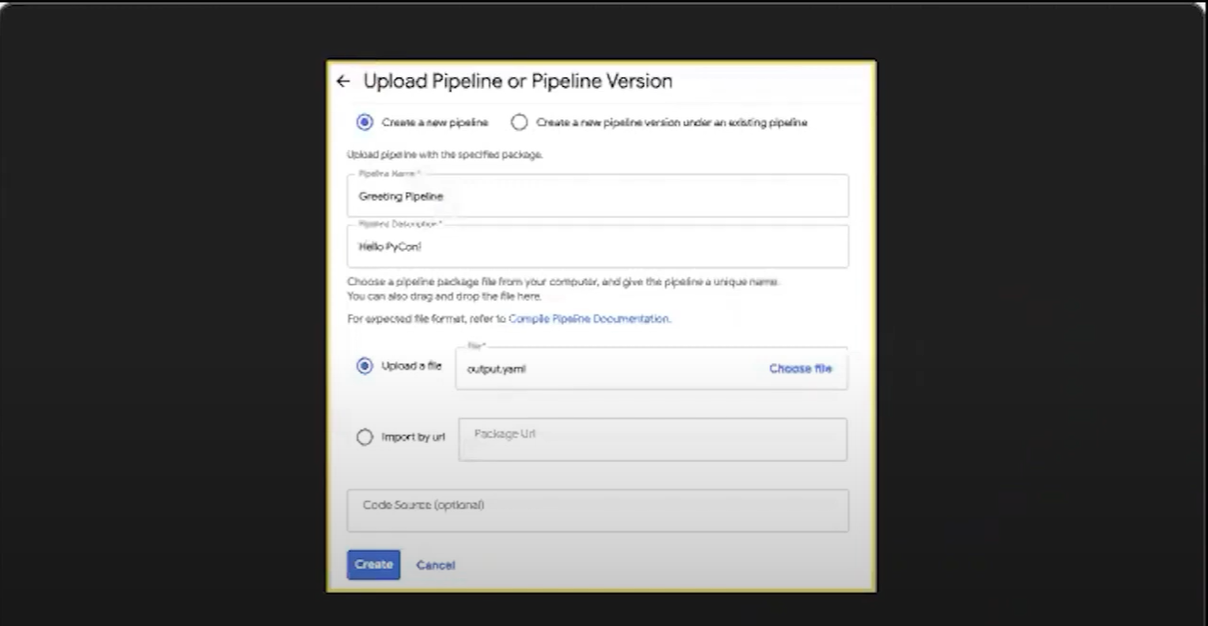
- kubeflow UI에 접속하여 새 Pipeline을 만듬
- 컴파일된 .yaml파일을 업로드하면 생성
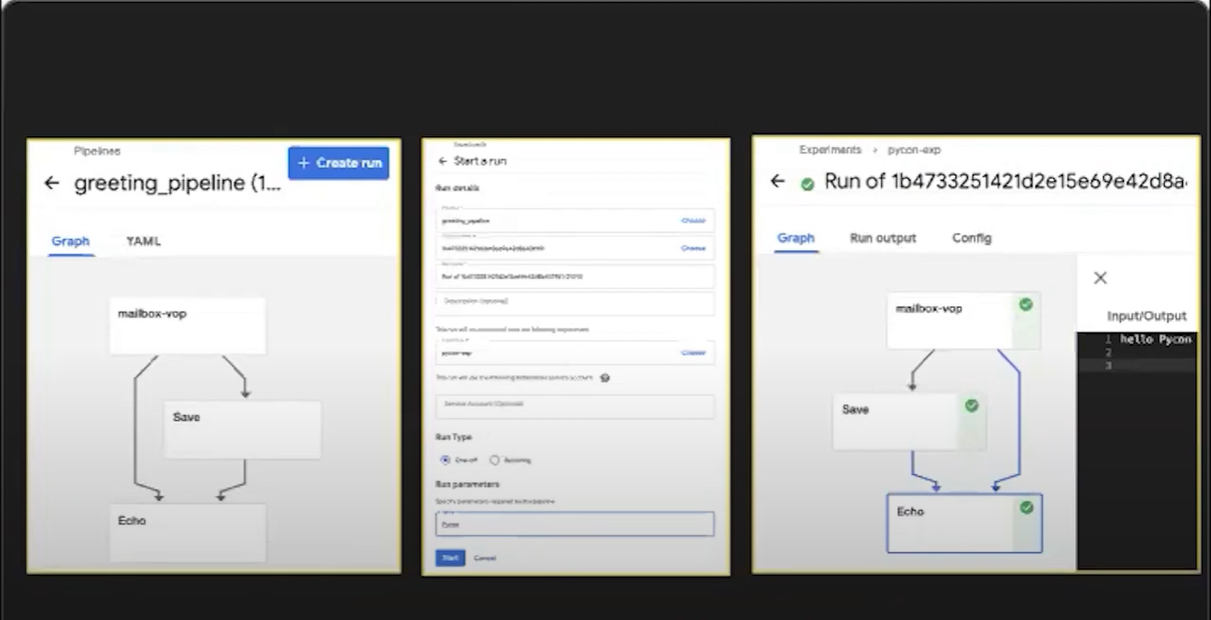
*Workflow 생성
-
공유 볼륨인 'mailbox'를 생성
-
파일을 저장하는 Component인 'Save' 실행
-
파일 내용을 출력하는 Component인 'Echo' 실행
-
'Create run'을 통해 실험을 생성하고 인자를 넣어주면 됌(본 파이프라인에서는 'name' 인자)
