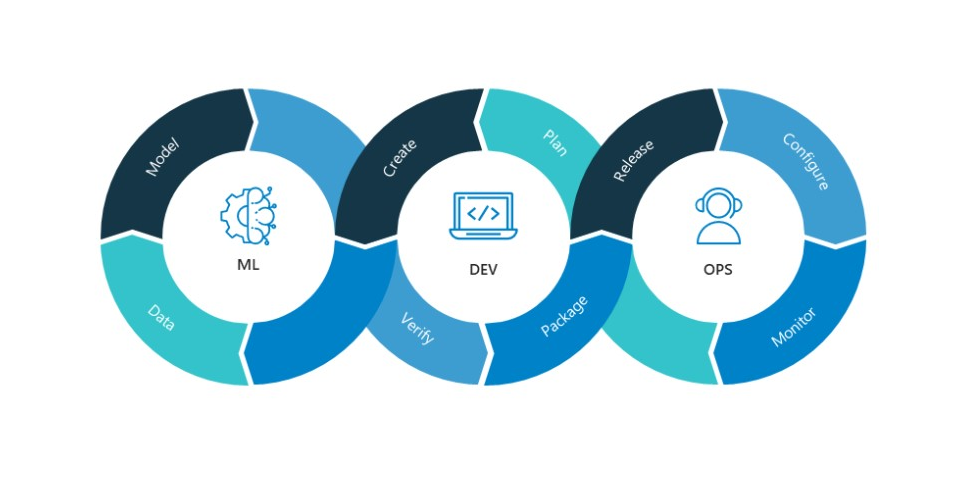
Wandb 소개
- 유튜브 'AIKU : 고려대학교 정보대학 딥러닝 학회' AIKU 2023-01 정기세미나 Week 6 : WandB 자료를 참고하였습니다.
-
"Machine learning experiment tracking, dataset versioning and model evaluation"
-
Experiments
-
Reports
-
Artifacts
-
Tables
-
Sweeps : Hyperparameter optimization, 하이퍼파라미터 튜닝 자동화
-
Launch
-
Models
1. Sign in
2. Install
3. Init

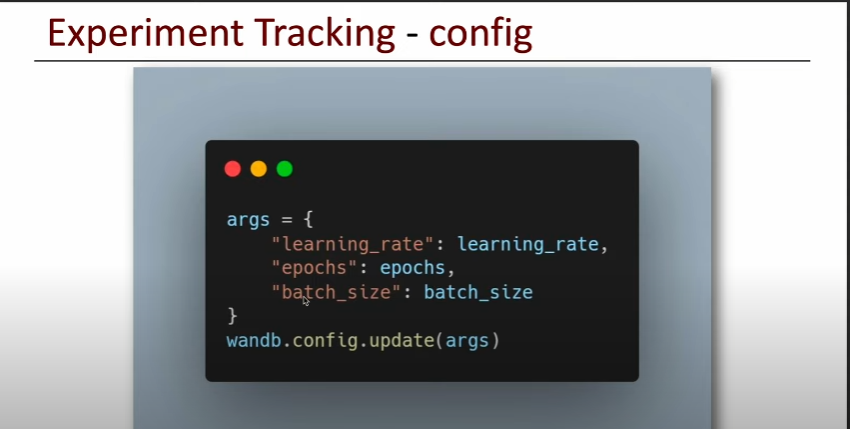
4. Config
5. Train (Logging)
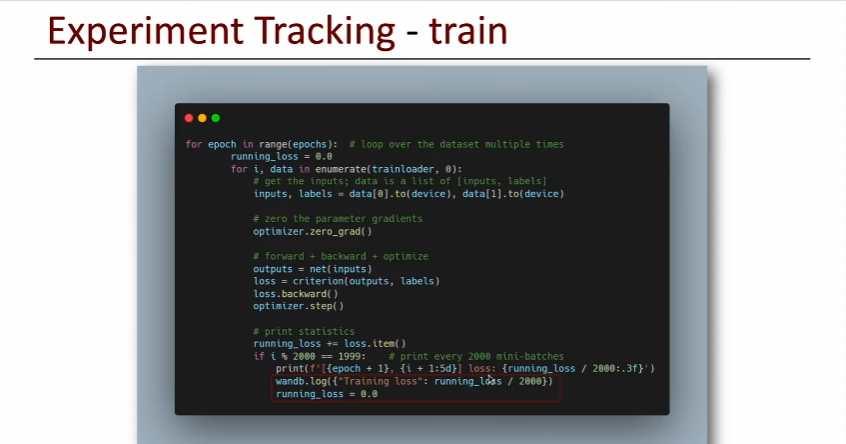
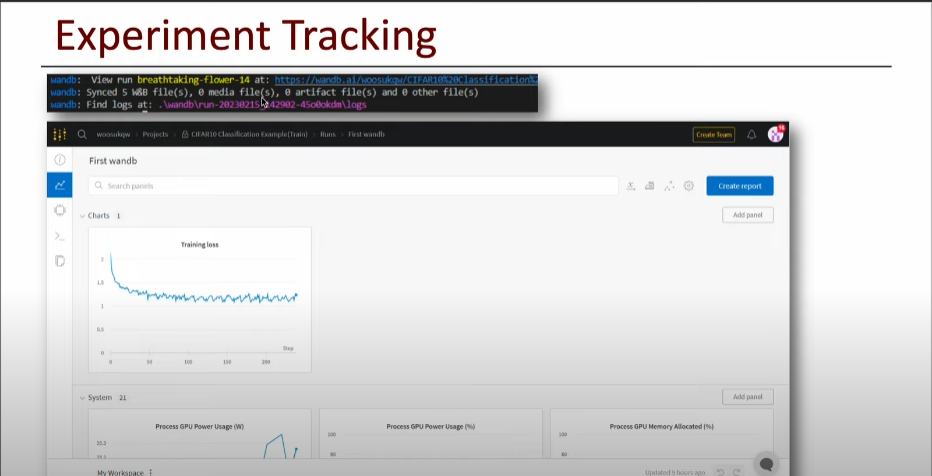
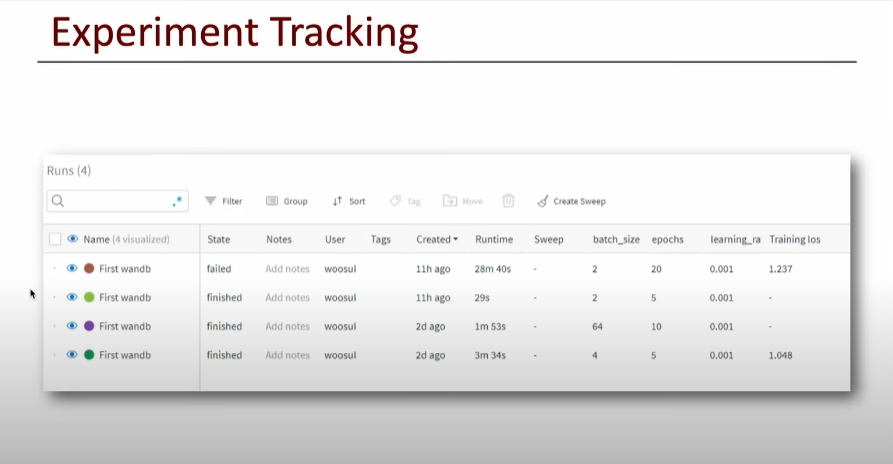
6. Test (Inferencing Check)
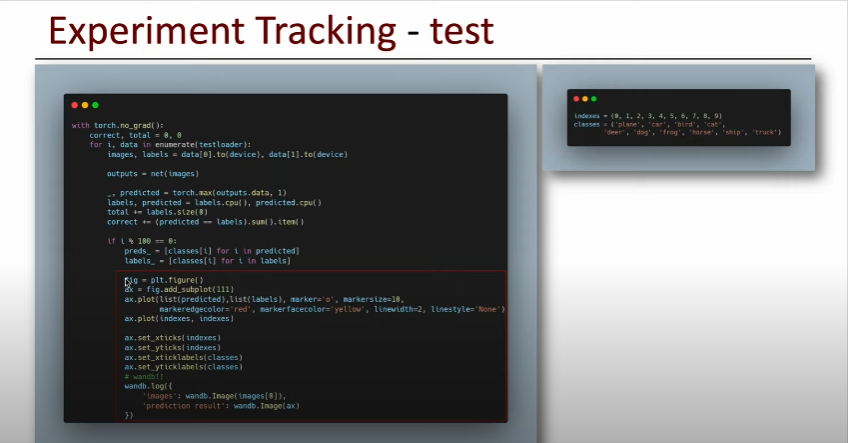
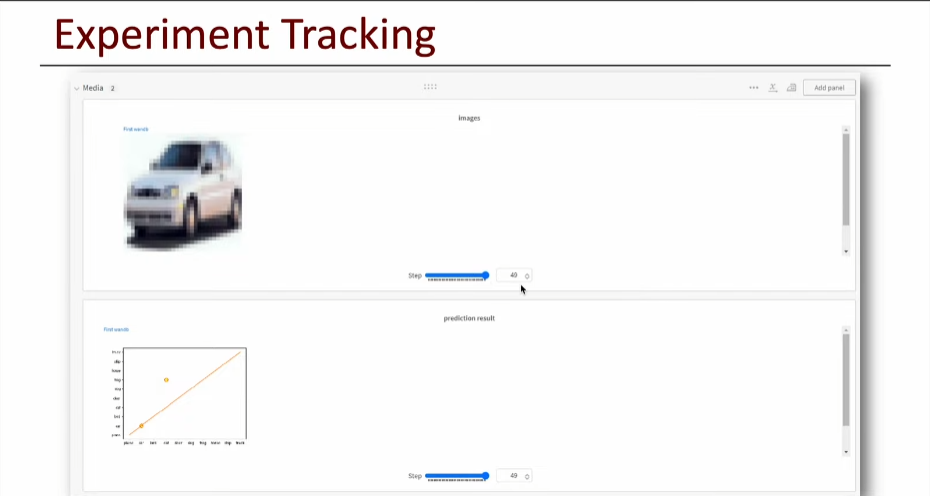
- 특정 Step에서의 Inference 결과 확인 가능
7. Sweeps (Tune Hyperparameters)
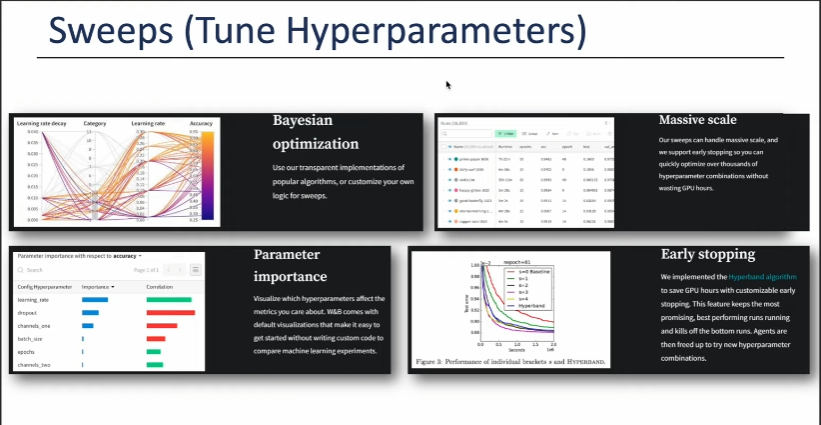
-
Bayesian optimization : 파라미터 최적화
-
Massive scale
-
Parameter importance : 파라미터 중요도
-
Early stopping
-
Define the sweep configuration
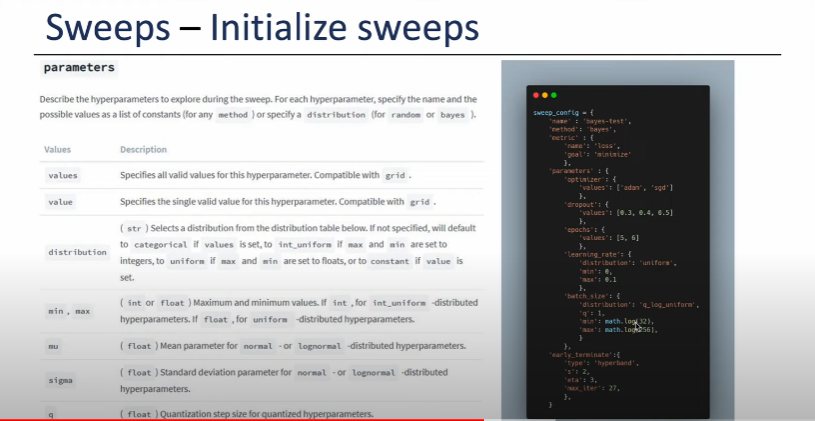
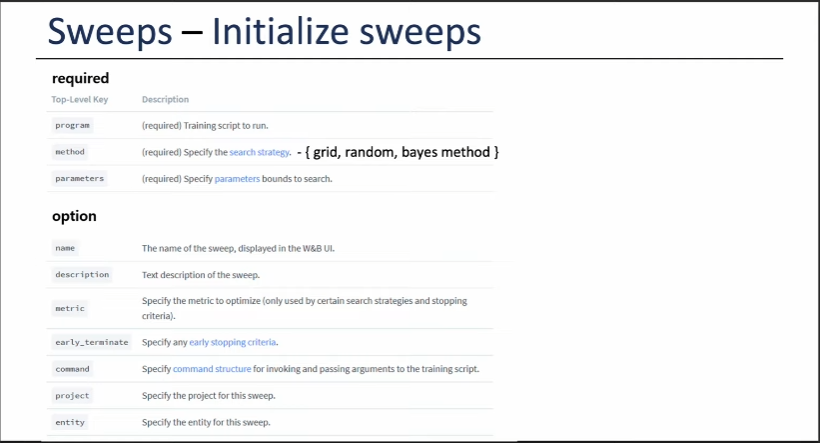

- Sweep 활용 Train
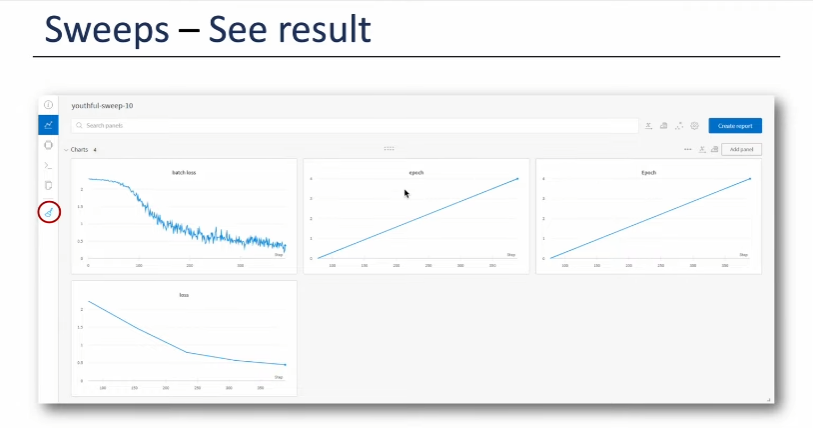

- Hyperparameter 조합별 Loss 시각화
Wandb 예제
# init
import wandb
# !wandb login
wandb.init(project='MLOps_Interview_CIFAR10_Classification',
name='Train_2'
)# config
learning_rate = 0.0001
epochs = 20
batch_size = 16
args = {
"learning_rate": learning_rate,
"epochs": epochs,
"batch_size": batch_size
}
wandb.config.update(args)# datasets
import torch
from torch import nn
from torch.utils.data import DataLoader, random_split
from torchvision import datasets
from torchvision.transforms import ToTensor
from torchvision import transforms
# Define transformation
transform = transforms.Compose([transforms.ToTensor()])
# Download training data from open datasets.
full_training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=transform,
)
# Split training data into train and validation sets
train_size = int(0.8 * len(full_training_data))
valid_size = len(full_training_data) - train_size
training_data, validation_data = random_split(full_training_data, [train_size, valid_size])
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=transform,
)# dataloader
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=args['batch_size'])
valid_dataloader = DataLoader(validation_data, batch_size=args['batch_size'])
test_dataloader = DataLoader(test_data, batch_size=args['batch_size'])
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break# cuda
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")# network
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)# cost function / optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=args['learning_rate'])# def train / valid / test
def train(dataloader, model, loss_fn, optimizer, epoch):
size = len(dataloader.dataset)
model.train()
total_loss = 0
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
total_loss += loss.item()
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
wandb.log({"train_loss": total_loss / len(dataloader)}, step=epoch)
def validate(dataloader, model, loss_fn, epoch):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
valid_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
valid_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
valid_loss /= num_batches
correct /= size
print(f"Validation Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {valid_loss:>8f} \n")
wandb.log({"valid_loss": valid_loss, "valid_acc": correct}, step=epoch)
def test(dataloader, model, loss_fn, epoch):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
wandb.log({"test_loss": test_loss, "test_acc": correct}, step=epoch)# train, valid, test
epochs = args['epochs']
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer, t)
validate(valid_dataloader, model, loss_fn, t)
test(test_dataloader, model, loss_fn, t)
print("Done!")# save
save_dir = './models/'
torch.save(model.state_dict(), save_dir + "model.pth")
print("Saved PyTorch Model State to model.pth")# load
save_dir = './models/'
torch.save(model.state_dict(), save_dir + "model.pth")
print("Saved PyTorch Model State to model.pth")# inference
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')
https://github.com/min731