
KR-SBERT를 활용한 연애 상담 챗봇 프로젝트 입니다.
- 자연어 처리 기술을 활용한 챗봇 미니 프로젝트입니다! 준비 중인 'AI 스피커 컨텐츠 기획/개발' 최종 프로젝트에 필요한 지식/원리들을 선행학습 하기 위해 시작하게 된 프로젝트입니다.
프로젝트 계획서

- 프로젝트 계획서입니다. 총 5명의 조원들과 협업했습니다!!!
- 프로젝트 진행 기간은 2023-02-07 ~ 2023-02-10 4일 소요되었습니다.
- 모델 개발과 백엔드 업무를 담당했습니다!
프로젝트 내용
-
주제 선정 : 연애 상담 챗봇
-
데이터 수집 및 전처리
-
데이터 수집
프로젝트 초기 AI hub에서 '감정 대화 데이터', '제품 상담 데이터'들을 중심으로 입력/출력 데이터들을 구축.
하지만 이와 같은 데이터들은 수 많은 상황들이 다양하게 묘사한 문장들로 구성되어있어 모델의 성능이 많이 떨어졌음. 그리하여 '감정 대화 데이터'의 입력 데이터에 나오는 주제를 중심으로 직접 연애/이별/썸에 관한 상담(질문) 데이터를 생성. -
데이터 전처리
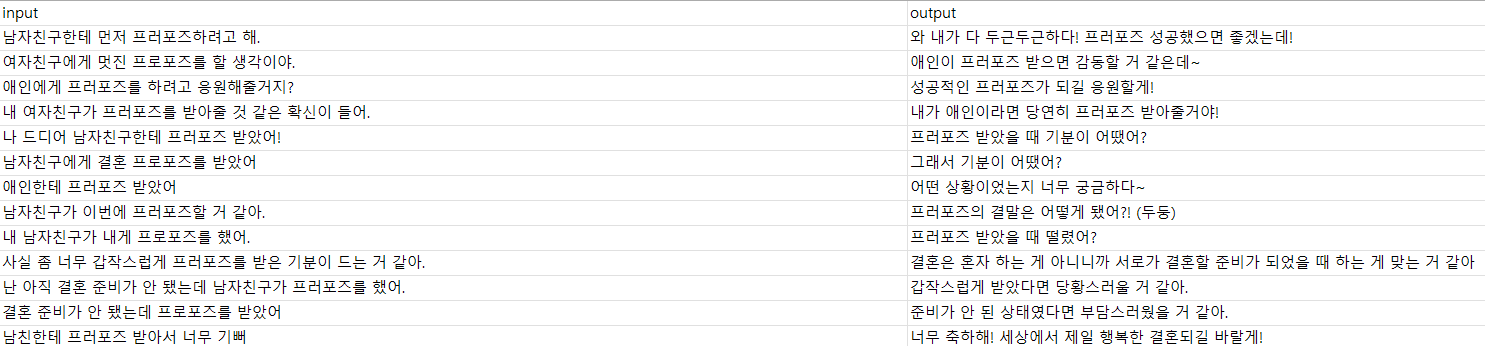
같은 의미의 다양한 표현방식의 입력 데이터들로 구축하고 그에 대응되는 적절한 출력 데이터들을 생성. 출력 데이터들 또한 '상담'이라는 테마에 맞게 다양한 답변 내용으로 편집. 약 1000개의 입력/출력 데이터로 구성.
예시)
여자친구에게 프로포즈를 할 생각이야
=>애인이 프로포즈 받으면 감동할 거 같은데?~
애인에게 프로포즈를 하려고. 응원해줄꺼지?
=> 성공적인 프러포즈가 되길 응원할게!
-
입력(input) PADDING
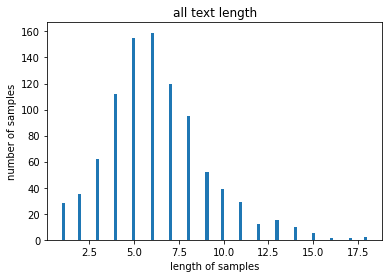
1)입력(input)의 최대길이 구하기
Komoran 라이브러리 활용하여 문장별 형태소 tokenize. 후 주격조사, 목적격 조사 등 중요도가 떨어지는 형태소들을 제외한 핵심 형태소 추출. 문장별 핵심 형태소 길이 분포 파악.
-
!pip install konlpy
from konlpy.tag import Komoran
tokenizer = Komoran()
data = pd.read_csv('data.csv')
data.head()
input_tokenized = [[token+"/"+POS for token,
POS in tokenizer.pos(input)] for input in data['input']]
exclusion_tags = [
'JKS', 'JKC', 'JKG', 'JKO', 'JKB', 'JKV', 'JKQ',
'JX', 'JC',
'SF', 'SP', 'SS', 'SE', 'SO',
'EP', 'EF', 'EC', 'ETN', 'ETM',
'XSN', 'XSV', 'XSA'
]
f = lambda x: x in exclusion_tags
core_input_tokenized = []
# i는 문장의 갯수
for i in range(len(input_tokenized)):
temp = []
# data_tokenized[0]=> 한 문장
# j는 한 문장을 구성하는 '단어/품사' 갯수
for j in range(len(input_tokenized[i])):
# f에 품사를 넣음
# exclusion_tags 리스트에 포함되지 않는 품사면 append!
# 필요없는 품사가 아니면 append
# (조사 같은 것들은 제외!)
if f(input_tokenized[i][j].split('/')[1]) is False:
temp.append(input_tokenized[i][j].split('/')[0])
core_input_tokenized.append(temp)
import numpy as np
import matplotlib.pyplot as plt
# 불용어들을 제외한 '의미있는' 단어들의 길이들을 모아놓은 num_tokens
num_tokens = [len(tokens) for tokens in core_input_tokenized]
num_tokens = np.array(num_tokens)
# 평균값, 최댓값, 표준편차
print(f"토큰 길이 평균: {np.mean(num_tokens)}")
print(f"토큰 길이 최대: {np.max(num_tokens)}")
print(f"토큰 길이 표준편차: {np.std(num_tokens)}")
plt.title('all text length')
plt.hist(num_tokens, bins=100)
# bins는 가로축 구간의 개수
# (막대 그래프의 갯수)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()PADDING 최대 길이는 20으로 책정
2) 최대길이(MAX_LEN) 기준으로 PADDING
Kormoran 라이브러리 기반 전처리 클래스,객체 생성.
말뭉치 형태소 활용 word2indexing, 불필요 품사 제거
import pandas as pd
import tensorflow as tf
from tensorflow.keras import preprocessing
import pickle
class Preprocess:
def __init__(self, word2index_dic='/content/drive/MyDrive/새싹_인공지능SW교육/프로젝트/새싹_자연어처리프로젝트/love_chatbot_sbert_v2(custom_data)/data/chatbot_dict/chatbot_dict.bin' ,userdic=None): # userdic 인자에는 사용자 정의 사전 파일 경로 입력가능
# 단어 인덱스 사전 불러오기 추가
if(word2index_dic != ''):
f = open(word2index_dic, "rb")
self.word_index = pickle.load(f)
f.close()
print("단어 사전 로드 완료..")
else:
self.word_index = None
print("단어 사전 로드 실패..")
# 형태소 분석기 초기화
self.komoran = Komoran(userdic=userdic)
# 제외할 품사
# 참조 : https://docs.komoran.kr/firststep/postypes.html
# 관계언 제거, 기호 제거
# 어미 제거
# 접미사 제거
self.exclusion_tags = [
'JKS', 'JKC', 'JKG', 'JKO', 'JKB', 'JKV', 'JKQ',
# 주격조사, 보격조사, 관형격조사, 목적격조사, 부사격조사, 호격조사, 인용격조사
'JX', 'JC',
# 보조사, 접속조사
'SF', 'SP', 'SS', 'SE', 'SO',
# 마침표,물음표,느낌표(SF), 쉼표,가운뎃점,콜론,빗금(SP), 따옴표,괄호표,줄표(SS), 줄임표(SE), 붙임표(물결,숨김,빠짐)(SO)
'EP', 'EF', 'EC', 'ETN', 'ETM',
# 선어말어미, 종결어미, 연결어미, 명사형전성어미, 관형형전성어미
'XSN', 'XSV', 'XSA'
# 명사파생접미사, 동사파생접미사, 형용사파생접미사
]
# 형태소 분석기 POS 태거
def pos(self, sentence):
return self.komoran.pos(sentence)
# 불용어 제거 후 필요한 품사 정보만 가져오기
def get_keywords(self, pos, without_tag=False):
f = lambda x: x in self.exclusion_tags
word_list = []
for p in pos:
if f(p[1]) is False:
word_list.append(p if without_tag is False else p[0])
return word_list
# 키워드를 단어 인덱스 시퀀스로 변환
def get_wordidx_sequence(self, keywords):
if self.word_index is None:
return []
w2i = []
for word in keywords:
try:
w2i.append(self.word_index[word])
except KeyError:
# 해당 단어가 사전에 없는 경우 OOV 처리
w2i.append(self.word_index['OOV'])
return w2i
p = Preprocess(word2index_dic='/content/drive/MyDrive/새싹_인공지능SW교육/프로젝트/새싹_자연어처리프로젝트/love_chatbot_sbert_v2(custom_data)/data/chatbot_dict/chatbot_dict.bin',
userdic=None)data.csv의 입력문장들 tokenize한 후 word2indexing
!pip install tqdm
from tqdm import tqdm
sequences = []
check_keywords = True
# text는 모든 문장들의 list
for sentence in tqdm(inputs):
# 문장을 [(단어1,품사1),(단어2,품사2)...] 로 변환
pos = p.pos(sentence)
# get_keywords(pos, without_tag=True) => 불용어 처리 후 품사(태그)없이 단어들만의 list
# keywords : 불용어 처리된 [(단어1,품사1),(단어2,품사2)...], list형
keywords = p.get_keywords(pos, without_tag=True)
# 첫번째 keywords 와 sequence[0] 어떻게 대응되는지 체크해보고 싶음
if check_keywords is True:
print(keywords)
check_keywords = False
# 태그없이 '단어'만 있는 keywords에서 [[단어1,단어2],[단어1,단어2,단어3]...]들을 인덱싱해줌
# 우리가 만든 단어사전에 없으면(OOV token이므로 인덱스 1로 고정)
seq = p.get_wordidx_sequence(keywords)
sequences.append(seq)MAX_LEN = 20 으로 설정이후 'post'방식의 PADDING
MAX_SEQ_LEN = 20
padded_seqs = preprocessing.sequence.pad_sequences(sequences,
maxlen=MAX_SEQ_LEN, padding='post')예시) (array([ 217, 82, 377, 3546, 128, 1494, 356, 37, 1612, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
4. embedding data
KR_SBERT의 SentenceTransformer 활용하여 input들의 대응되는 embedding data 생성.csv로 생성한 후 torch.save 함수로 .pt 파일 생성
# KR-SBERT 설치
!pip install -U sentence-transformers
import pandas as pd
from tqdm import tqdm
tqdm.pandas()
import torch
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
data['embedding_vector'] = data['input'].progress_map(lambda x : model.encode(x))
data.to_excel("data_embedding.xlsx", index=False)
embedding_data = torch.tensor(data['embedding_vector'].tolist())
torch.save(embedding_data, 'embedding_data.pt') 
- 어플리케이션 실행
- Django 프레임워크 기반 웹 어플리케이션
#url.py
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('', views.home, name='home'),
path('trying', views.trying, name='trying'),
]#views.py
from django.conf import settings
from django.shortcuts import render
from django.http import JsonResponse
from django import http
from .chatbot import communicate
from datetime import datetime
from .CustomFormatter import CustomFormatter
import logging
import os
BAN_STACK = {}
CURRENT_PATH = os.path.dirname(os.path.realpath(__file__))
logger = logging.getLogger()
ch = logging.StreamHandler()
ch.setFormatter(CustomFormatter())
logger.addHandler(ch)
fileHandler = logging.FileHandler(filename=CURRENT_PATH + '/log.txt', encoding='utf-8')
file_format = logging.Formatter(
"(%(asctime)s) %(message)s",
'%Y/%m/%d %I:%M:%S %p'
)
fileHandler.setFormatter(file_format)
logger.addHandler(fileHandler)
def home(request):
remote_ip = request.META['REMOTE_ADDR']
# if BAN_STACK.get(remote_ip) >= 3:
# settings.BLOCKED_IPS.append(remote_ip)
if remote_ip in settings.BLOCKED_IPS:
return http.HttpResponseForbidden('<h1>응 니 밴임~</h1>')
if request.method == "GET":
return render(request, "fapp/home.html", {})
def trying(request):
temp = request.GET.get('message')
x_forwarded_for = request.META.get('HTTP_X_FORWARDED_FOR')
if x_forwarded_for:
ip = x_forwarded_for.split(',')[0]
else:
ip = request.META.get('REMOTE_ADDR')
with open('C:/myapp/fapp/static/fword_list.txt', 'r', encoding='utf-8') as f:
stopwords = f.readlines()
for word in stopwords:
if word in temp:
logger.critical(str(ip) + ': ' + temp)
# if ip not in BAN_STACK:
# BAN_STACK[ip] = 1
# else:
# BAN_STACK[ip] += 1
break
result = communicate(temp)
return JsonResponse(result, content_type='application/json', safe=False, json_dumps_params={'ensure_ascii':False})# chatbot.py
# 모델 load, 대화 스킬 알고리즘, 이스터에그
import torch
import numpy as np
import pandas as pd
from sentence_transformers import SentenceTransformer, util
import random
# SBERT 모델 불러오기
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
# 학습된 input, output df 불러오기
data = pd.read_csv('C:/myapp/fapp/chatbot/data/csv/연애시뮬레이션(실험8)_전처리.csv')
data = data[['input','output']]
# input별 embedding data 불러오기
embedding_data = torch.load('C:/myapp/fapp/chatbot/data/embedding_data/custom_love_embedding_data.pt')
# 가장 최근 input
last_sentence = ''
# 가장 최근 출력 idx
last_sim_idx_list = []
# 현재 중복 cnt
overlap_cnt = 0
# 학습에 없는 질문 리스트
unexpected_input_list = []
def talk_to_bot(sentence):
global last_sentence
global last_sim_idx_list
global overlap_cnt
global unexpected_input_list
# 최종 출력 답변
answer = ''
# 알아듣는 문장 유사도 임계값
input_thresholds = 0.6
# 중복 문장 유사도 임계값
overlap_thresholds = 0.85
remove_sim_idx = None
# 띄어쓰기 있는 사용자 input
origin_sentence = sentence
sentence = sentence.replace(" ","")
sentence_encode = model.encode(sentence)
sentence_tensor = torch.tensor(sentence_encode)
last_sentence = last_sentence.replace(" ","")
last_sentence_encode = model.encode(last_sentence)
last_sentence_tensor = torch.tensor(last_sentence_encode)
overlap_cos_sim = util.cos_sim(sentence_tensor, last_sentence_tensor)
cos_sim = util.cos_sim(sentence_tensor, embedding_data)
failedList = [
'응애 나 아기 챗봇!',
'꺅! 오빠 팬이에요! 데이터 주세요!',
'삐빅! 데이터가 수집되었습니다!',
'꺼억! 공짜 데이터 +1 감사합니다!',
'지직! import new_Data....1110101..... ',
]
rand_num1 = random.random()
# 예상 외의 input 입력 시
if cos_sim[0][int(np.argmax(cos_sim))] < input_thresholds:
answer = str(random.choice(failedList)) + '<br>문장 유사도 : '+ str(round(float( cos_sim[0][int(np.argmax(cos_sim))]),2))
answer += '<br>새로운 데이터로 아기 챗봇 ' + str({round(rand_num1*50,1)}) + '% 성장!'
# print(answer)
unexpected_input_list.append(origin_sentence)
return last_sentence, last_sim_idx_list, overlap_cnt, answer
# 이전 질문과 문장이 0.85이상 유사하면
# 해당 질문-답변 출력 X
# 총 3번까지
if overlap_cos_sim >= overlap_thresholds and overlap_cnt < 3 :
# print('************************ 이전 질문과 유사함 ************************')
remove_sim_idx_list = last_sim_idx_list
for i in remove_sim_idx_list:
cos_sim[0][int(i)] = 0
overlap_cnt += 1
# print(f'이전 출력 idx: {last_sim_idx_list}')
# print(f'이전 질문과 유사도: {overlap_cos_sim}')
# print(f'중복횟수 : {overlap_cnt}')
else:
overlap_cnt = 0
last_sim_idx_list = []
# print(f'사용자의 질문: {sentence} \n')
dot_score = util.dot_score(sentence_tensor, embedding_data)
ascending_cos_sim = np.sort(cos_sim)
descending_cos_sim = ascending_cos_sim[::-1]
# print(f'cos_sim 유사도 내림차순: {ascending_cos_sim}')
# print(f'--------------------------- 최우선 순위 질문/답변 ---------------------------')
# print(f"가장 높은 코사인 유사도 idx : {int(np.argmax(cos_sim))}")
# 동일한 문장 유사도 input 일 때, 랜덤으로 출력
max_cos_sim = cos_sim[0][np.argmax(cos_sim)]
same_cos_sim_list = []
for idx,one_cos_sim in enumerate(cos_sim[0]):
if one_cos_sim == max_cos_sim:
same_cos_sim_list.append(idx)
# print(f'same_cos_sim_list 크기: {len(same_cos_sim_list)}')
if len(same_cos_sim_list) == 1:
# data에서 선택된 질문 출력
best_sim_idx = int(np.argmax(cos_sim))
sentence_qes = data['input'][best_sim_idx]
# print(f"선택된 질문 = {sentence_qes}")
# data에서 선택된 질문 문장에 대한 인코딩
selected_qes_encode = model.encode(sentence_qes)
# 유사도 점수 측정
# print(f'np.dot(sentence_tensor, selected_qes_encode) 값: {np.dot(sentence_tensor, sentence_encode)}')
# print(f'(np.linalg.norm(sentence_tensor) 값: {np.linalg.norm(sentence_tensor)}')
# print(f'(np.linalg.norm(selected_qes_encode) 값: {np.linalg.norm(selected_qes_encode)}')
# print(f'util.cos_sim 활용 코사인 유사도 : {cos_sim[0][best_sim_idx]}')
score = np.dot(sentence_tensor, sentence_encode) / (np.linalg.norm(sentence_tensor) * np.linalg.norm(selected_qes_encode))
# print(f"직접 수식 작성한 코사인 유사도 = {score}")
# 답변
answer = data['output'][best_sim_idx]
# print(f"\n답변 : {answer}\n")
# 최근 출력한 idx 기억
last_sim_idx_list.append(int(np.argmax(cos_sim)))
else:
rand_num2 = random.choice(same_cos_sim_list)
# print(f'같은 문장 유사도 list:{same_cos_sim_list}')
# print(f'rand_num2 뽑음!')
# print(rand_num2)
# data에서 선택된 질문 출력
best_sim_idx = rand_num2
sentence_qes = data['input'][best_sim_idx]
# print(f"선택된 질문 = {sentence_qes}")
# data에서 선택된 질문 문장에 대한 인코딩
selected_qes_encode = model.encode(sentence_qes)
# 유사도 점수 측정
# print(f'np.dot(sentence_tensor, selected_qes_encode) 값: {np.dot(sentence_tensor, sentence_encode)}')
# print(f'(np.linalg.norm(sentence_tensor) 값: {np.linalg.norm(sentence_tensor)}')
# print(f'(np.linalg.norm(selected_qes_encode) 값: {np.linalg.norm(selected_qes_encode)}')
# print(f'util.cos_sim 활용 코사인 유사도 : {cos_sim[0][best_sim_idx]}')
score = np.dot(sentence_tensor, sentence_encode) / (np.linalg.norm(sentence_tensor) * np.linalg.norm(selected_qes_encode))
# print(f"직접 수식 작성한 코사인 유사도 = {score}")
# 답변
answer = data['output'][best_sim_idx]
# print(f"\n답변 : {answer}\n")
# 최근 출력한 idx 기억
last_sim_idx_list.append(int(best_sim_idx))
# 중복 input 대응을 위해 이전sentence 저장
last_sentence = sentence
# 최우선 순위 질문 벡터 초기화
cos_sim[0][best_sim_idx] = 0
# 후순위 답변/질문 디버깅
# print(f'--------------------------- 후순위 답변/질문 디버깅 ---------------------------')
for i in range(1,6):
# print(f'<{i}순위 Case>')
# print(f"가장 높은 코사인 유사도 idx : {int(np.argmax(cos_sim))}")
# data에서 선택된 질문 출력
best_sim_idx = int(np.argmax(cos_sim))
sentence_qes = data['input'][best_sim_idx]
# print(f"선택된 질문 = {sentence_qes}")
# data에서 선택된 질문 문장에 대한 인코딩
selected_qes_encode = model.encode(sentence_qes)
# 유사도 점수 측정
# print(f'np.dot(sentence_tensor, selected_qes_encode) 값: {np.dot(sentence_tensor, sentence_encode)}')
# print(f'(np.linalg.norm(sentence_tensor) 값: {np.linalg.norm(sentence_tensor)}')
# print(f'(np.linalg.norm(selected_qes_encode) 값: {np.linalg.norm(selected_qes_encode)}')
# print(f'util.cos_sim 활용 코사인 유사도 : {cos_sim[0][best_sim_idx]}')
score = np.dot(sentence_tensor, sentence_encode) / (np.linalg.norm(sentence_tensor) * np.linalg.norm(selected_qes_encode))
# print(f"직접 수식 작성한 코사인 유사도 = {score}")
# 답변
answer = data['output'][best_sim_idx]
# print(f"\n답변 : {answer}\n")
# 최우선 순위 질문 벡터 초기화
cos_sim[0][best_sim_idx] = 0
# print(f'-------------------------------------------------------------------------------')
if random.choice([True, False]):
if '~' in answer:
answer = answer.strip('.').strip('?').strip('!').strip('~')
answer += ', 사용자야~'
return last_sentence, last_sim_idx_list , overlap_cnt , answer
if '?' in answer:
answer = answer.strip('.').strip('?').strip('!').strip('~')
answer += ', 사용자야?'
return last_sentence, last_sim_idx_list , overlap_cnt , answer
if '!' in answer:
answer = answer.strip('.').strip('?').strip('!').strip('~')
answer += ', 사용자야!'
return last_sentence, last_sim_idx_list , overlap_cnt , answer
else:
answer = answer.strip('.').strip('?').strip('!').strip('~')
answer += ', 사용자야.'
return last_sentence, last_sim_idx_list , overlap_cnt , answer
else:
return last_sentence, last_sim_idx_list , overlap_cnt , answer
def easterEgg(message):
Users = {
'장동근': ['nayosibal.png'],
'임정민': ['limsirung.png'],
'고준호': ['yummy.png'],
'구현모': ['catch_java.png'],
'김태성': ['kk.png'],
'손원준': ['onejoon.png'],
'심재훈': ['jaehun.png'],
'심현우': ['baekjun_son.png'],
'최해정': ['pepe.png'],
'이종은': ['pigeon.png'],
'곽지섭': ['church_nunna.png'],
'김다나': ['danaka_san.png'],
'진솔': ['yaml_ddak.png', 'sol1.png'],
'윤율': ['yy_company.png']
}
for user in Users:
if user in message or user[1:3] in message:
message = Users[user]
return message
def communicate(message):
message = easterEgg(message)
if isinstance(message, list):
_STATIC_SRC = '/static/img/EasterEgg/'
answer = _STATIC_SRC + random.choice(message)
else:
_, _, _, answer = talk_to_bot(message)
return answer- 사용 예시
1) 사용자 이름 언급
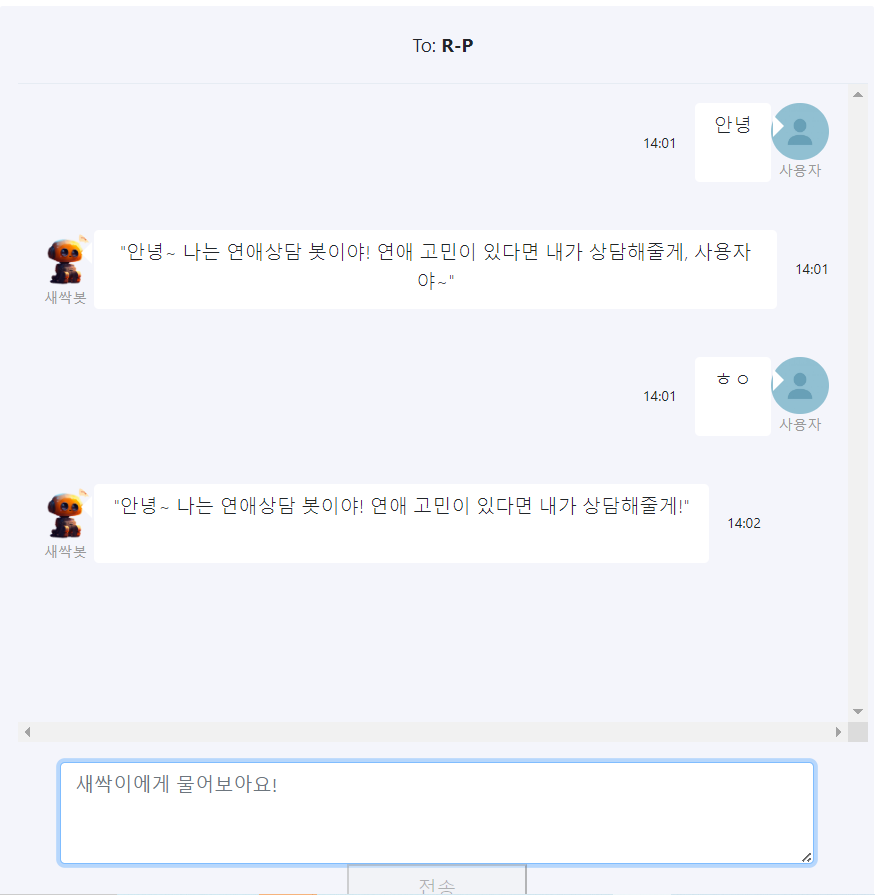
2) 랜덤 답변
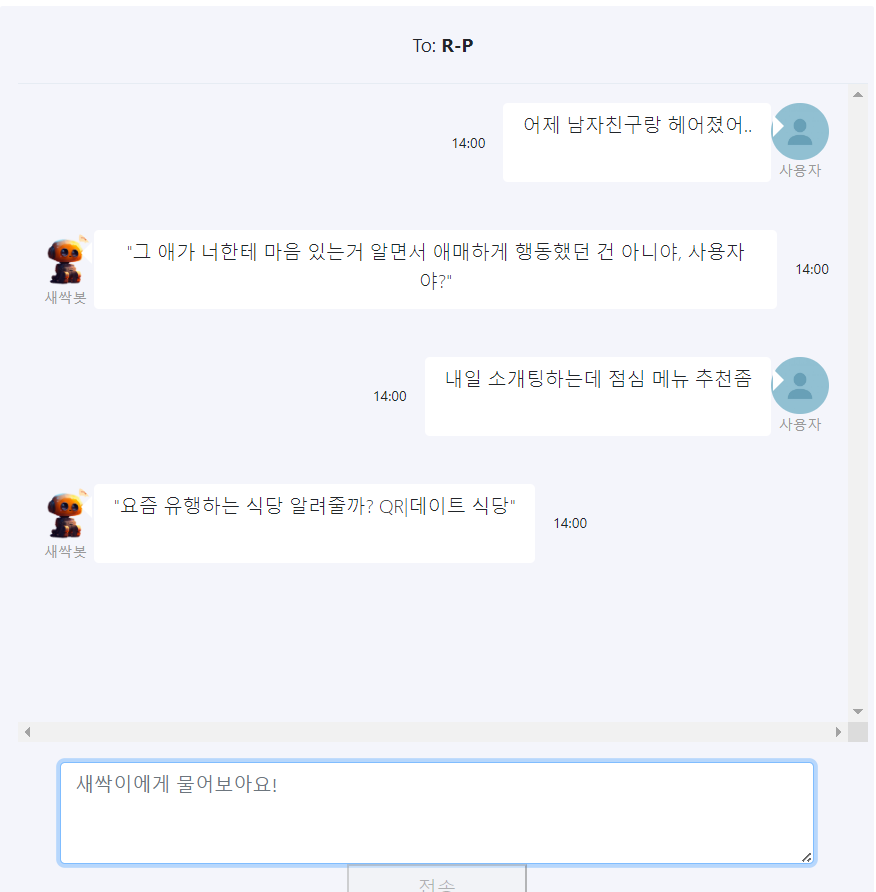
3) 중복 답변 일시 제거
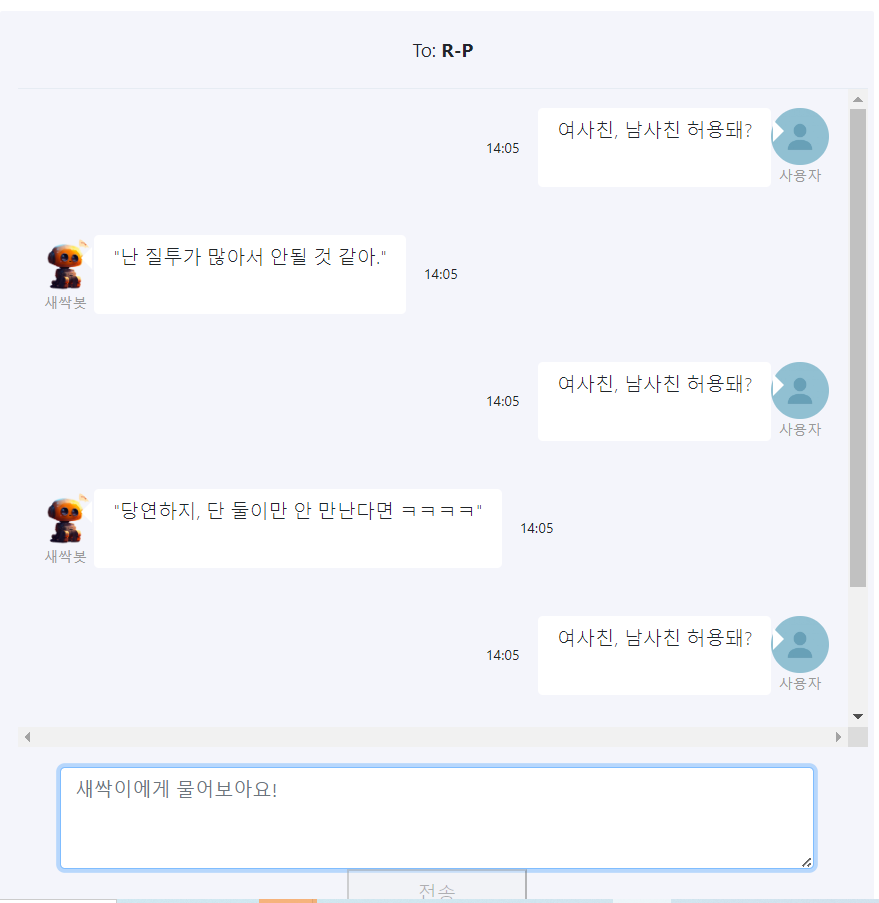
4) 구글 폼 질문 조사
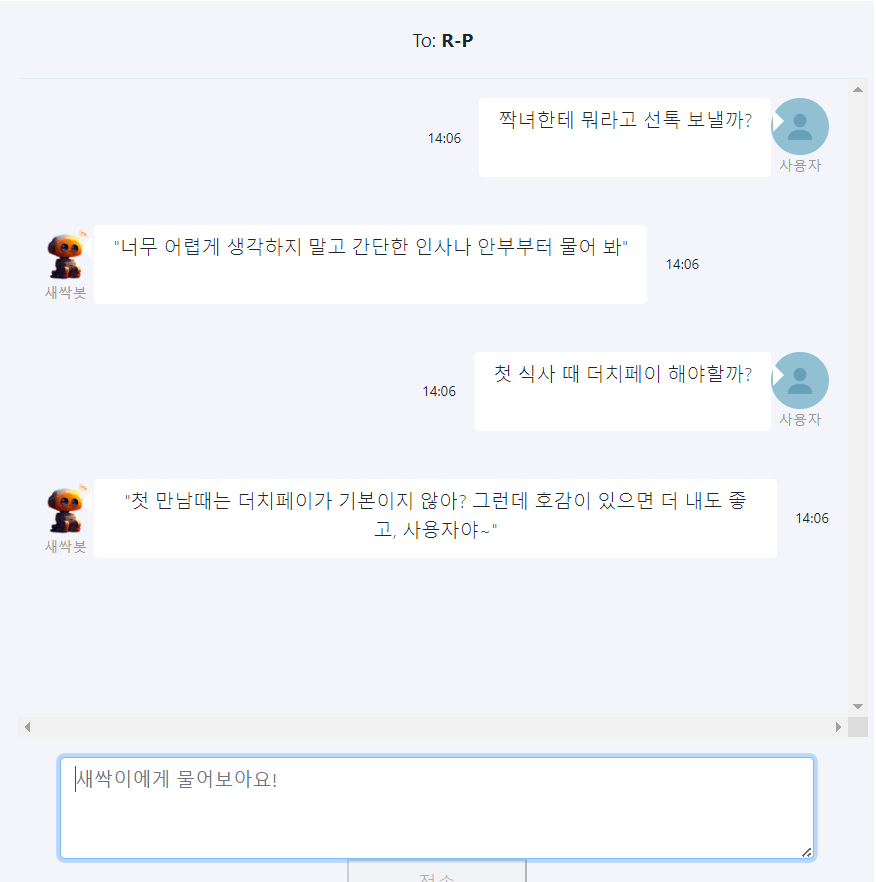
5) etc...
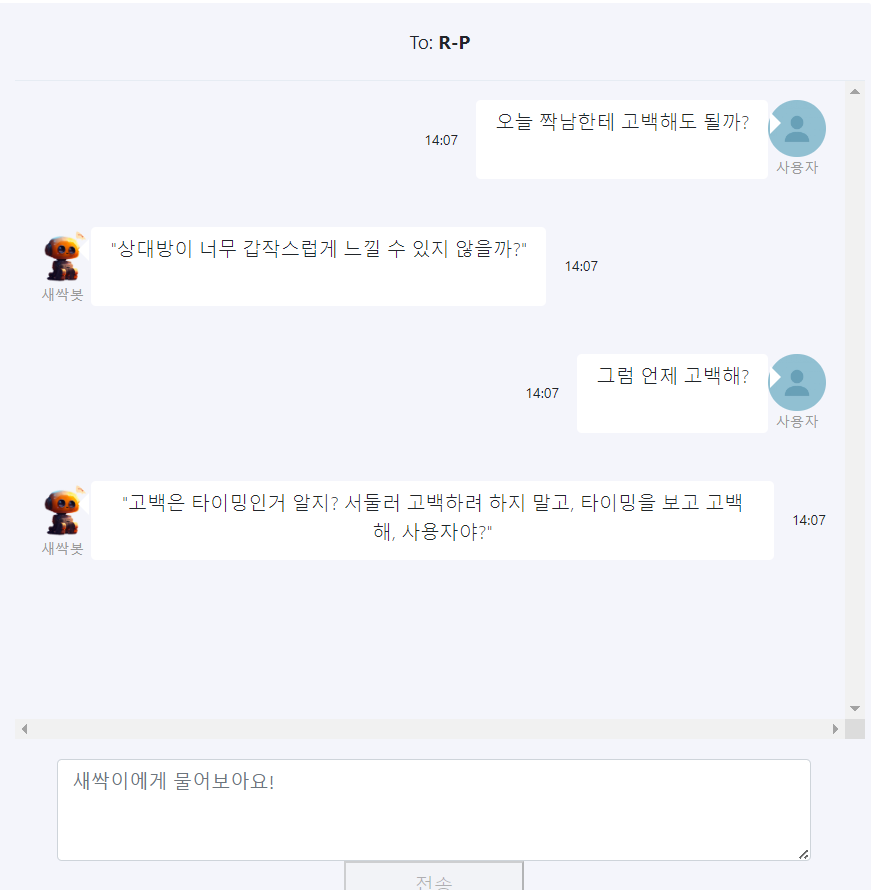
발표 PPT 및 설명은 자연어 처리_연애 상담 챗봇_프로젝트 (2)을 참고하시면 되겠습니다. 감사합니다🐸🐸🐸


👍