
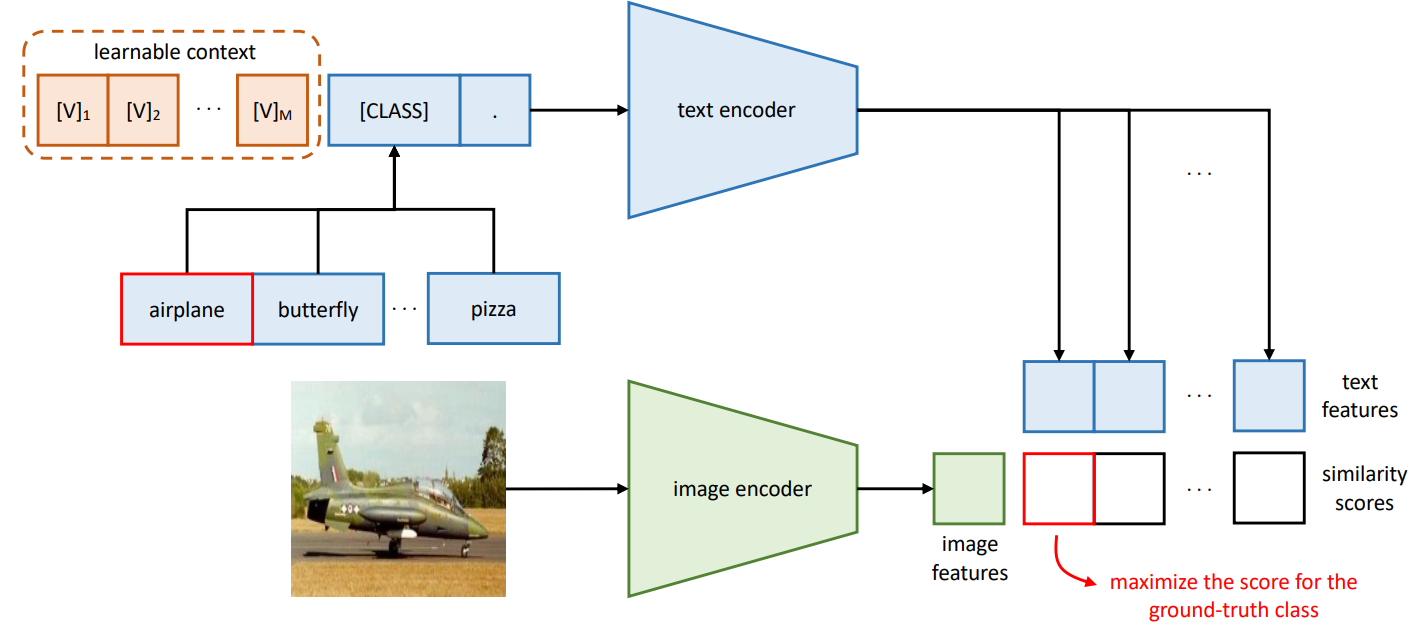
Background : CoOp
- VLP task에서 prompt를 어떠한 방식으로 만들어내는지에 따라 task별 성능이 매우 달라짐
(ex : 가장 좋은 성능을 보이는 prompt를 기준으로 학습을 진행했더라도 다른 task에서는 또다시 prompt engineering 과정을 처음부터 다시) - 해당 Task 에 가장 적절한 Prompt 를 찾는 데에는 필요한 시간이 너무 많기 때문에 prompt 자체를 최적화하는 Context Optimization(CoOp) 제시

프롬프트를 두가지 방식으로 제안

-
Unified Context :
전체 데이터에 대해서 하나의 context 를 학습
-
Class-specific Context :
각 class 마다의 context를 학습 → Fine-grained Classification 이 필요할 때 효과적
Loss :
Limitation
- 기존의 Text 구조 체계가 무너지기 때문에 성능을 높이는데는 유용하지만 관계성을 보여주는데는 한계
- 학습 과정에서 context가 downstream task에 overfit
→ ID class에 대해서는 좋은 성능 - OOD class에 대해서는 낮은 성능


Main Contribution
- CLIP 모델 기반의 few-shot OOD detection 방식 LoCoOp 제안
- CLIP 의 Local Feature 에서 Noise(배경) 를 활용하여 OoD Regularization 을 수행 → ID Text Embedding 에서 불필요한 정보 제거
- 기존 OoD 방법보다 효율적 + GL-MCM 과 높은 호환성 + 높은 성능
Methods
문제 정의
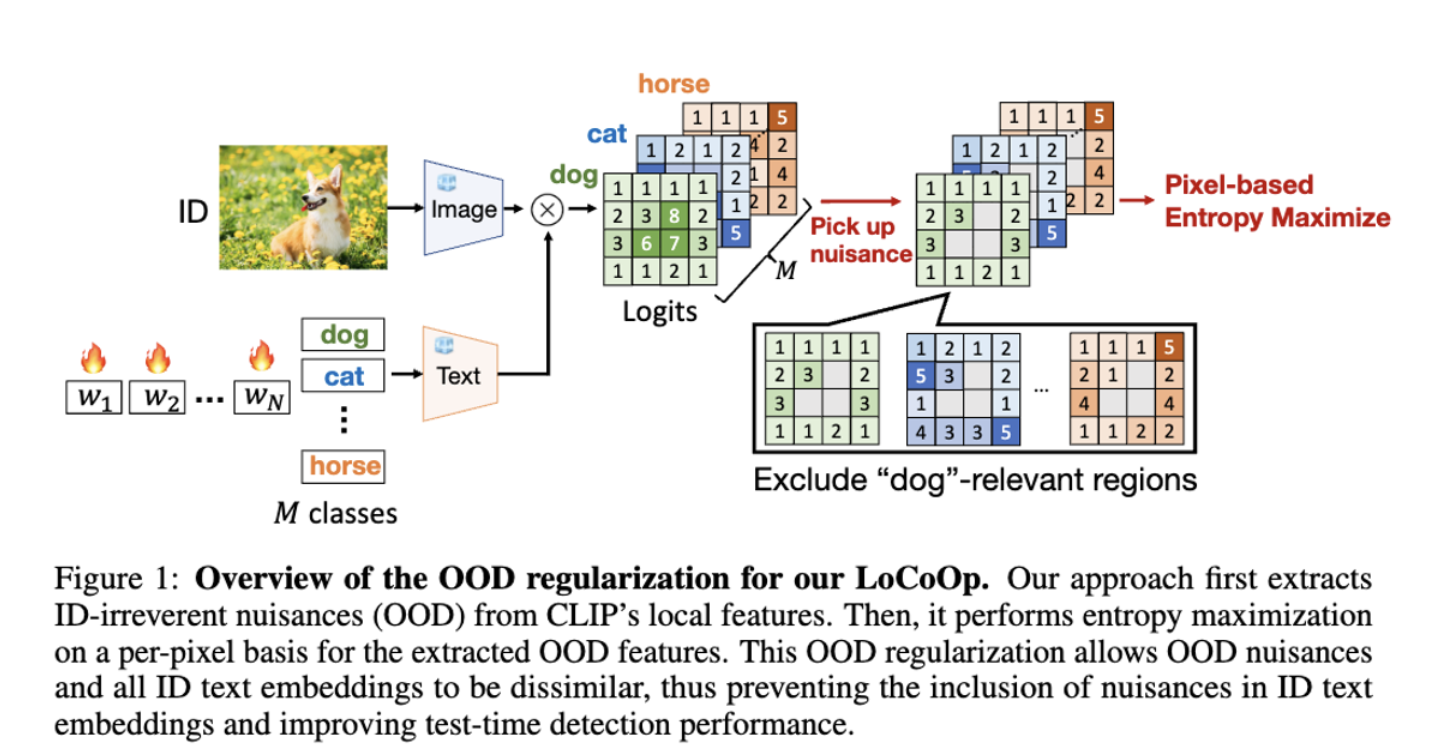
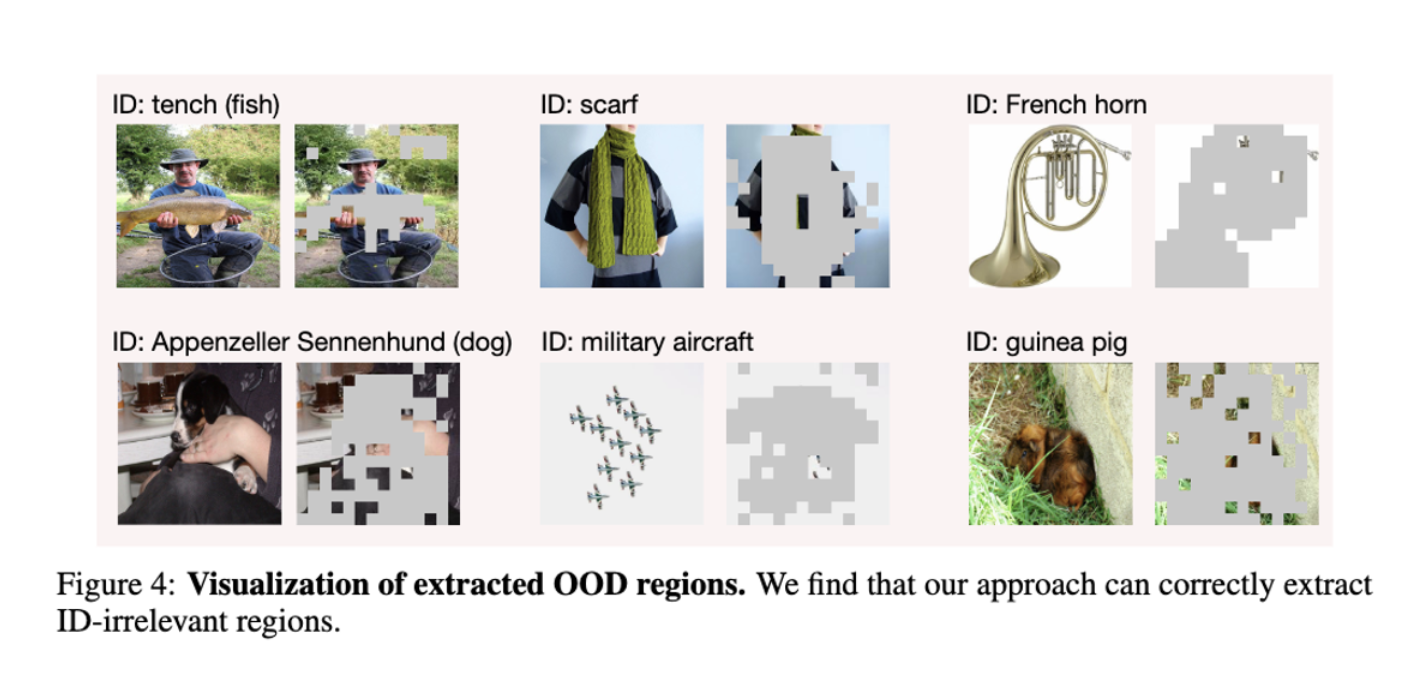
- Extraction of ID-irrelevant regions
이미지와 텍스트의 Logit 값이 큰 것은 ID Class 를 판별하는데 필요한 영역이라고 생각 - Logit 값이 작은 부분들을 ID Class 와 관련이 없는 영역이라고 판단
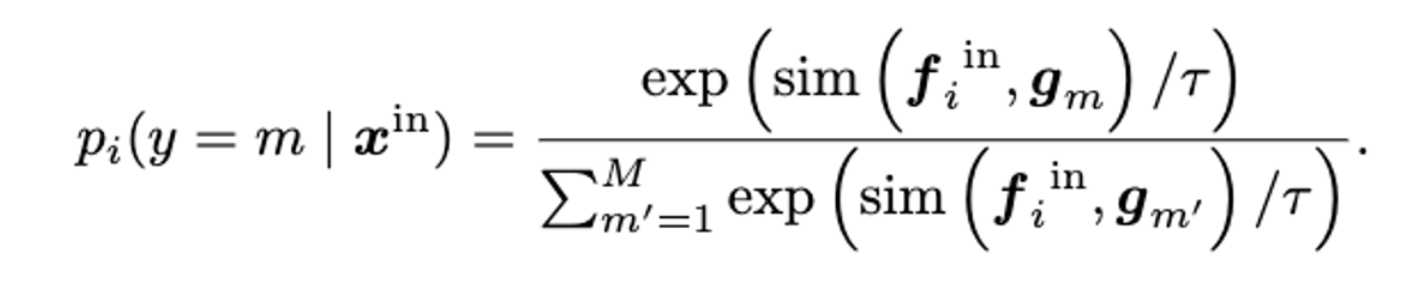
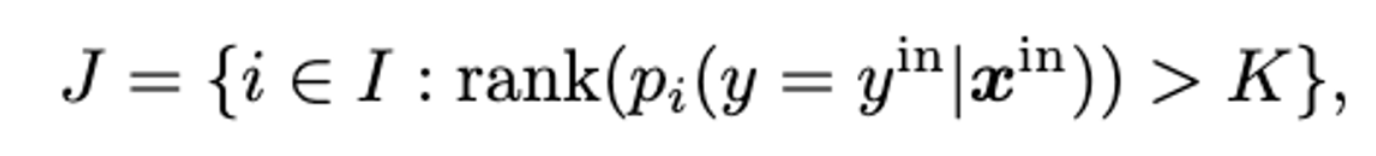
K 값 이상인 경우 ID Class 를 식별하는데 필요한 영역으로 판단 - 제외
- OOD regularization =
ID와 OOD (out-of-distribution) 가 서로 잘 분리될 수 있도록
j 픽셀에 대한 Entropy 를 최대화 = 배경이 어떤 특정 클래스에 속하지 않도록 만든다
Experiments
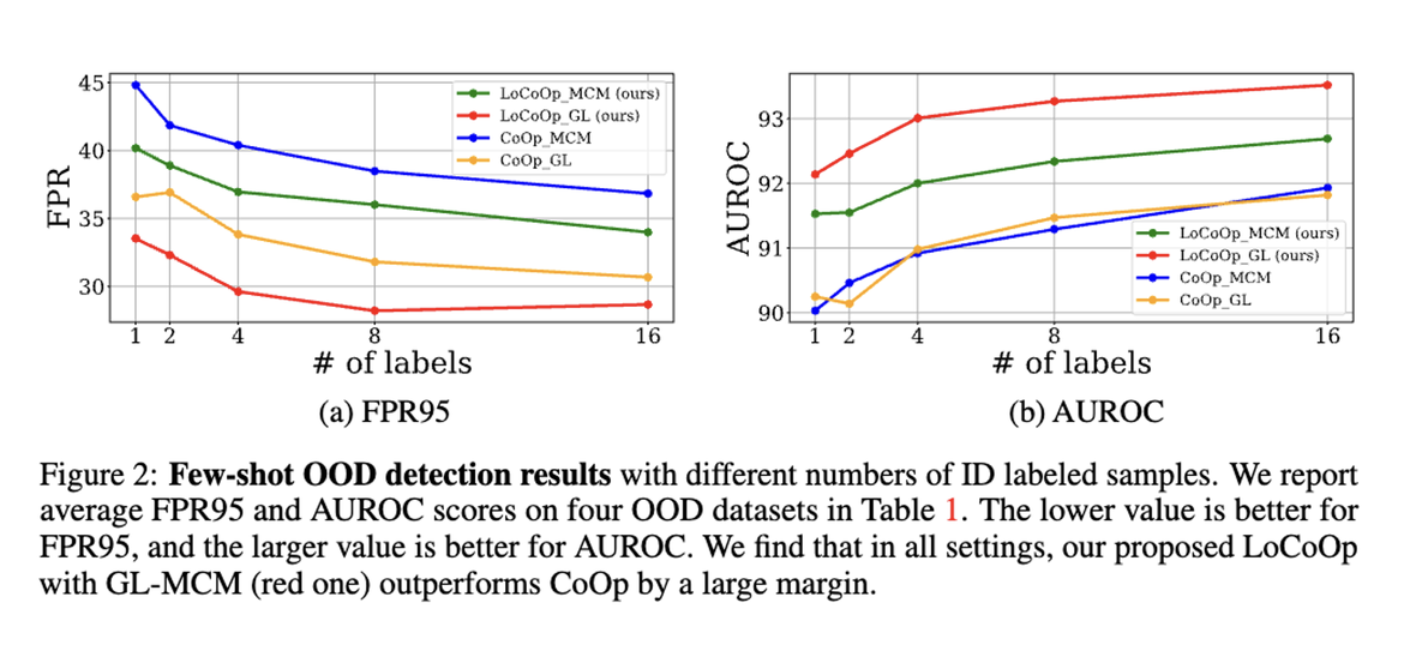
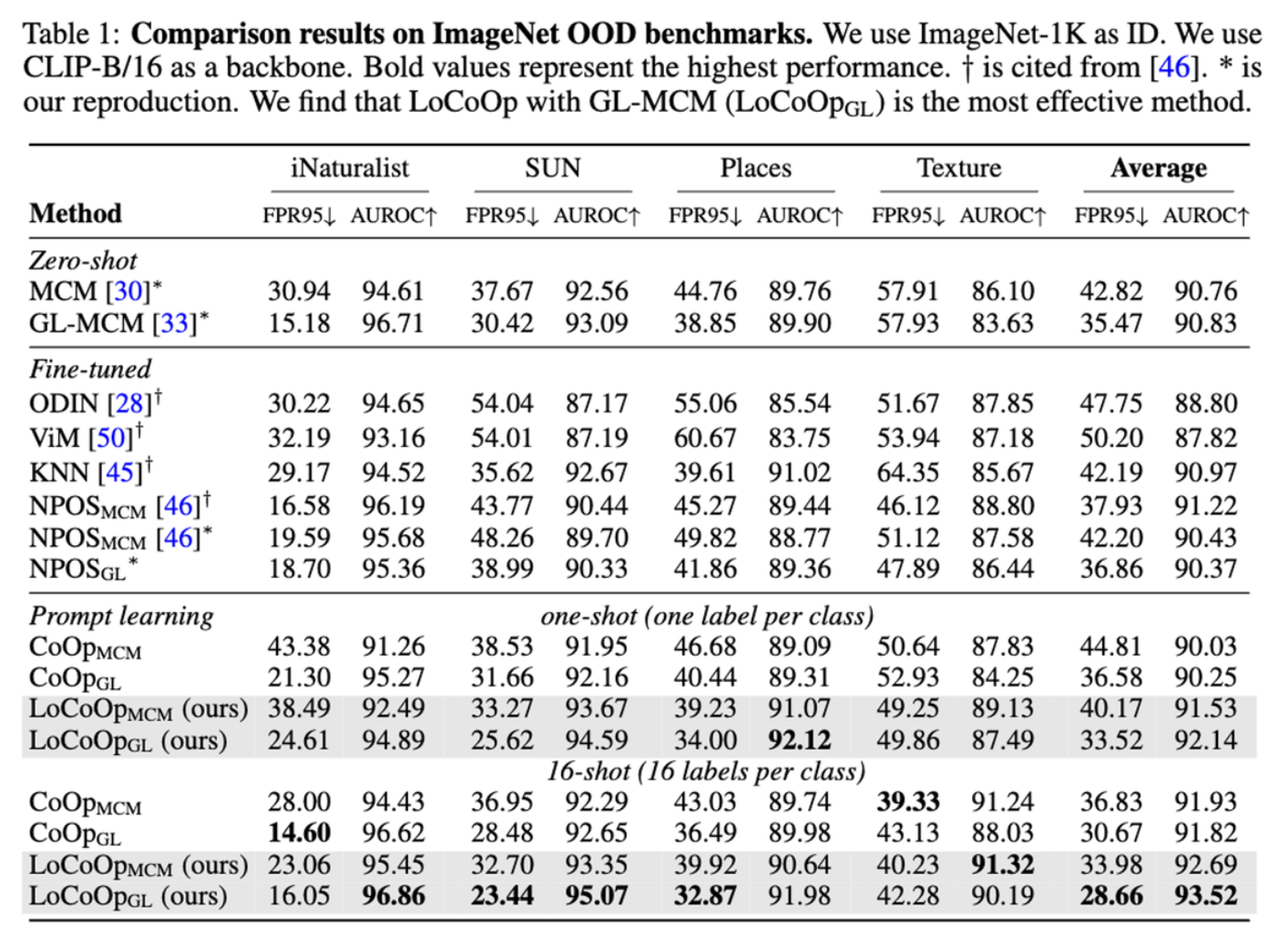
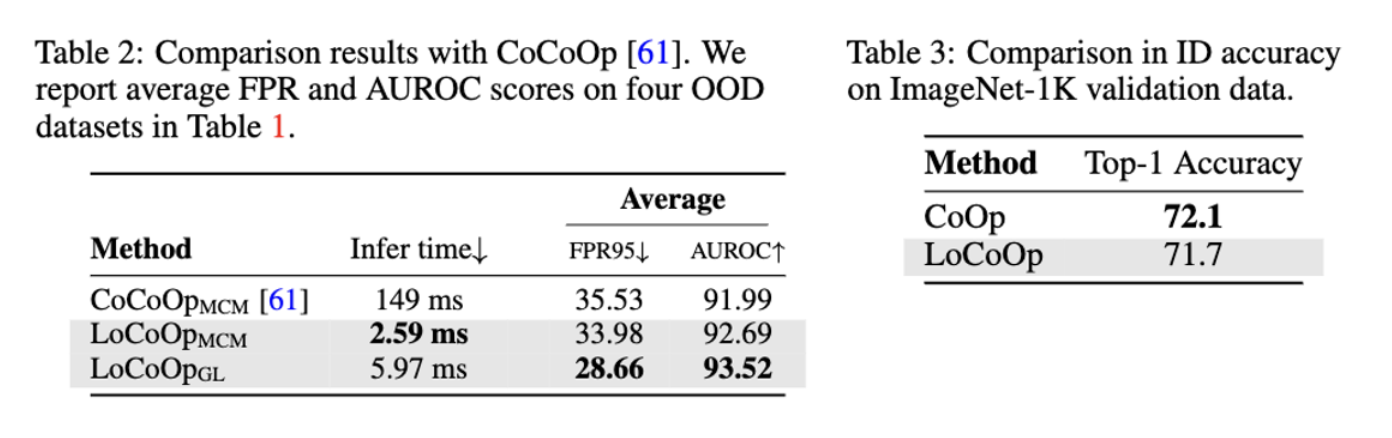
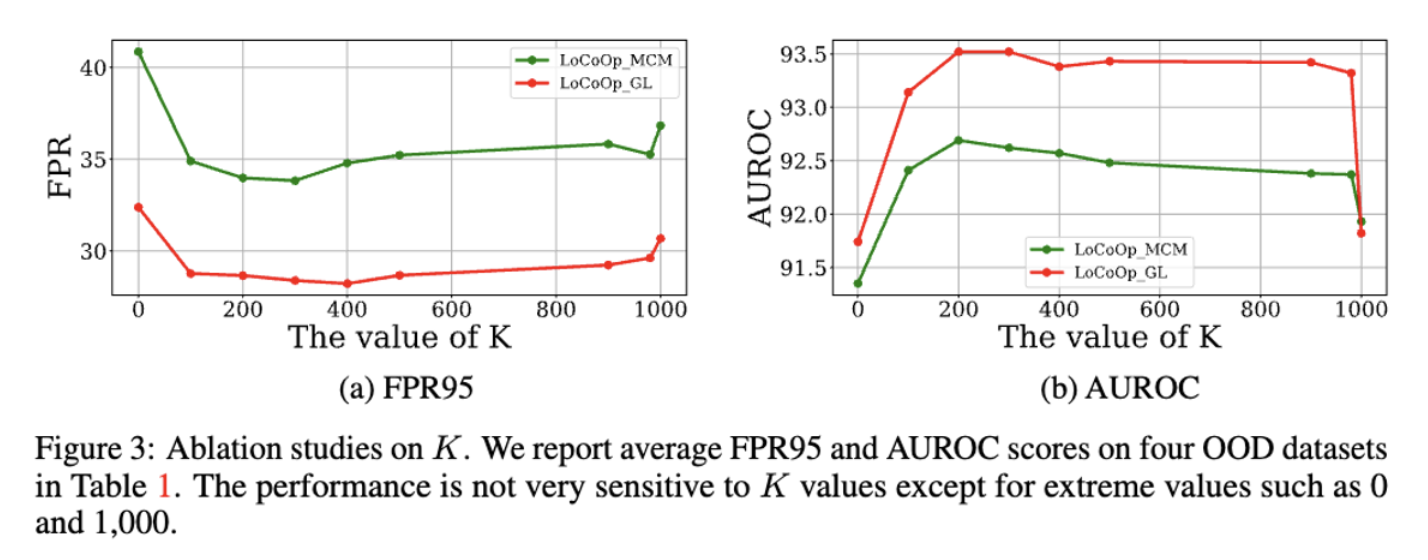
(K = Hyperparameter → 100 에서 극적인 향상 200 이후까지 높게 유지, 1000 이하)
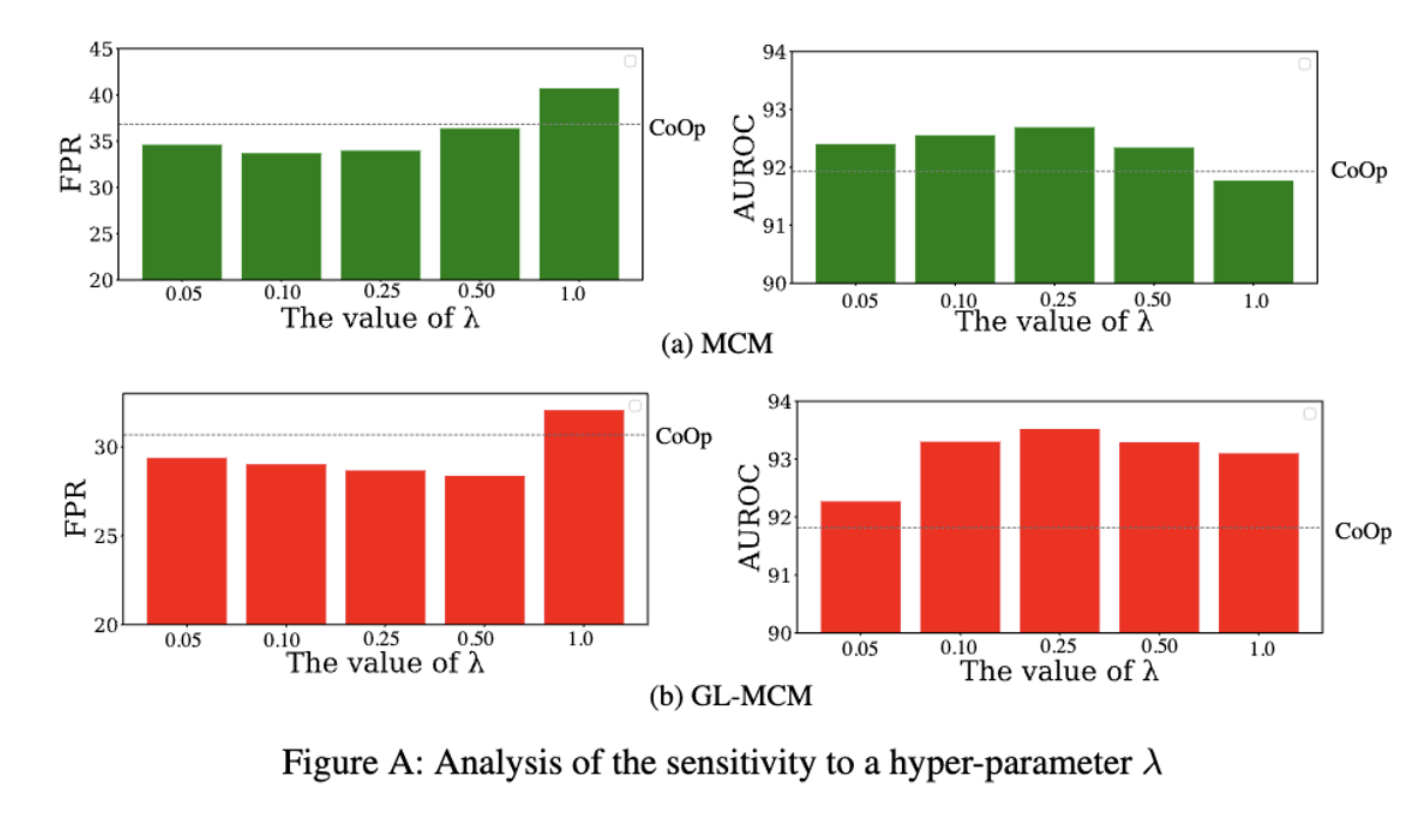
로 실험을 진행
