
인덱스
인덱스는 데이터를 효율적으로 탐색하는 방법.
인덱스를 사용해 조회하게 되면 실제 데이터까지 접근할 필요가 없으므로 조회 성능을 향상 시킨다.
커버링 인덱스
쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스.
즉 SELECT, WHERE, ORDER BY, LIMIT, GROUP BY 등에서 사용되는 모든 컬럼이 인덱스 컬럼 안에 다 포함되는 경우를 의미.
select 절까지 포함하게 되면 너무 많은 컬럼이 인덱스에 포함되기 때문에, 커버링 인덱스는 select 를 제외한 나머지만 우선적으로 수행한다.
커버링 인덱스가 적용된 쿼리
// 커버링 인덱스 적용 전
SELECT *
FROM boards
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈
// 커버링 인덱스 적용 후
SELECT *
FROM boards as b
JOIN (SELECT id
FROM boards
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈) as cover
on cover.id = b.idJOIN 내부에 select, where, order by, limit 항목들이 인덱스 컬럼으로만 이루어져서 인덱스 내부에서 쿼리를 충족시키는 모든 데이터를 갖고있다.
따라서 커버링 인덱스로 조회한 id를 통해 실제로 데이터 블록에서 조회 할 항목들을 빠르게 조회 할 수 있다.
일반 인덱스 조회 vs 커버링 인덱스 조회
일반적인 조회 쿼리는 order by, limit 이 수행 될 때 데이터 블록에 접근하여 쿼리 속도의 저하로 이어진다.
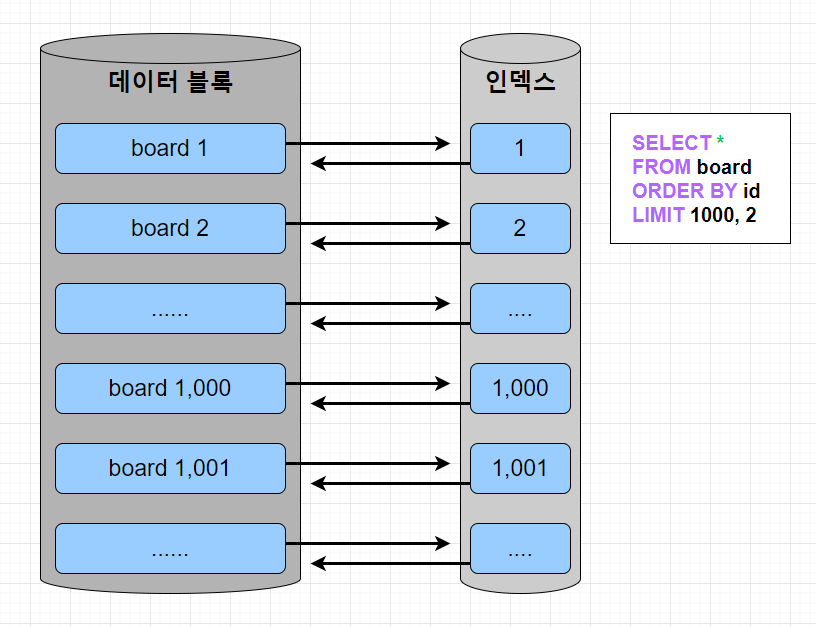
커버링 인덱스가 적용된 조회 쿼리의 경우 where, order by, limit을 인덱스 검색으로 처리한 다음에 특정 row에 대해서만 데이터 블록에 접근하므로 쿼리 속도 향상이 된다.
이때 클러스터 인덱스(PK)인 id는 모든 인덱스에 자동으로 포함되므로
페이징 작업까지는 커버링 인덱스로 빠르게 처리하고 마지막에 필요로 되는 컬럼만 가져온다.

커버링 인덱스 적용
QueryDSL에서는 from절에서 서브쿼리를 지원하지 않는다.
따라서
1) 커버링 인덱스를 활용하여 조회 대상의 PK를 조회하고
2) 조회한 PK로 필요한 컬럼을 조회한다.
public Page<Match> findList(Pageable pageable, MatchSearchRequest searchRequest) {
// 커버링 인덱스로 PK인 id 조회
List<Long> ids = queryFactory
.select(match.id)
.from(match)
.where(eqStartAt(searchRequest.getMatchDay()),
eqGender(searchRequest.getGender()),
eqStatus(searchRequest.getMatchStatus()),
eqPersonnel(searchRequest.getPersonnel()),
eqStadiumName(searchRequest.getStadiumName()))
.orderBy(match.id.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
// 대상이 없을 경우 빈페이지 반환
if (CollectionUtils.isEmpty(ids)) {
return Page.empty();
}
// 조회한 PK인 id로 select절 조회
List<Match> matchList = queryFactory
.selectFrom(match)
.where(match.id.in(ids))
.orderBy(match.startAt.asc())
.fetch();
// 조회한 PK인 id로 페이지수 조회
JPAQuery<Long> countQuery = queryFactory
.select(match.count())
.from(match)
.where(match.id.in(ids));
return PageableExecutionUtils.getPage(matchList, pageable, countQuery::fetchOne);
}
참조
