BigQuery ML
표준 SQL 쿼리를 사용하여 머신러닝 모델을 만들고 실행할 수 있다.
대규모 데이터 세트의 머신러닝에는 ML 프레임워크에 대한 광범위한 프로그래밍과 지식이 필요하지만 BQML을 사용하면 간단한 SQL문을 사용하여 ML 모델을 빌드하고 평가할 수 있다.
가장 큰 장점은 DW에서 다른 곳으로 데이터를 내보내지 않아도 된다는 것
이로인해 모델 개발 및 혁신 속도가 향상된다.
지원 모델
모델이 훈련된 위치에 따라 두 가지로 분류될 수 있다.
- BigQuery 내에서 빌드되고 학습되는 기본 제공 모델.
선형회귀, 로지스틱 회귀, K-means, 행렬 분해 및 시계열 모델 등 - BigQuery 외부에서 학습된 외부 모델(커스텀 모델)
AutoML Table, DNN, Vertex AI에서 학습된 부스트 트리 모델 등
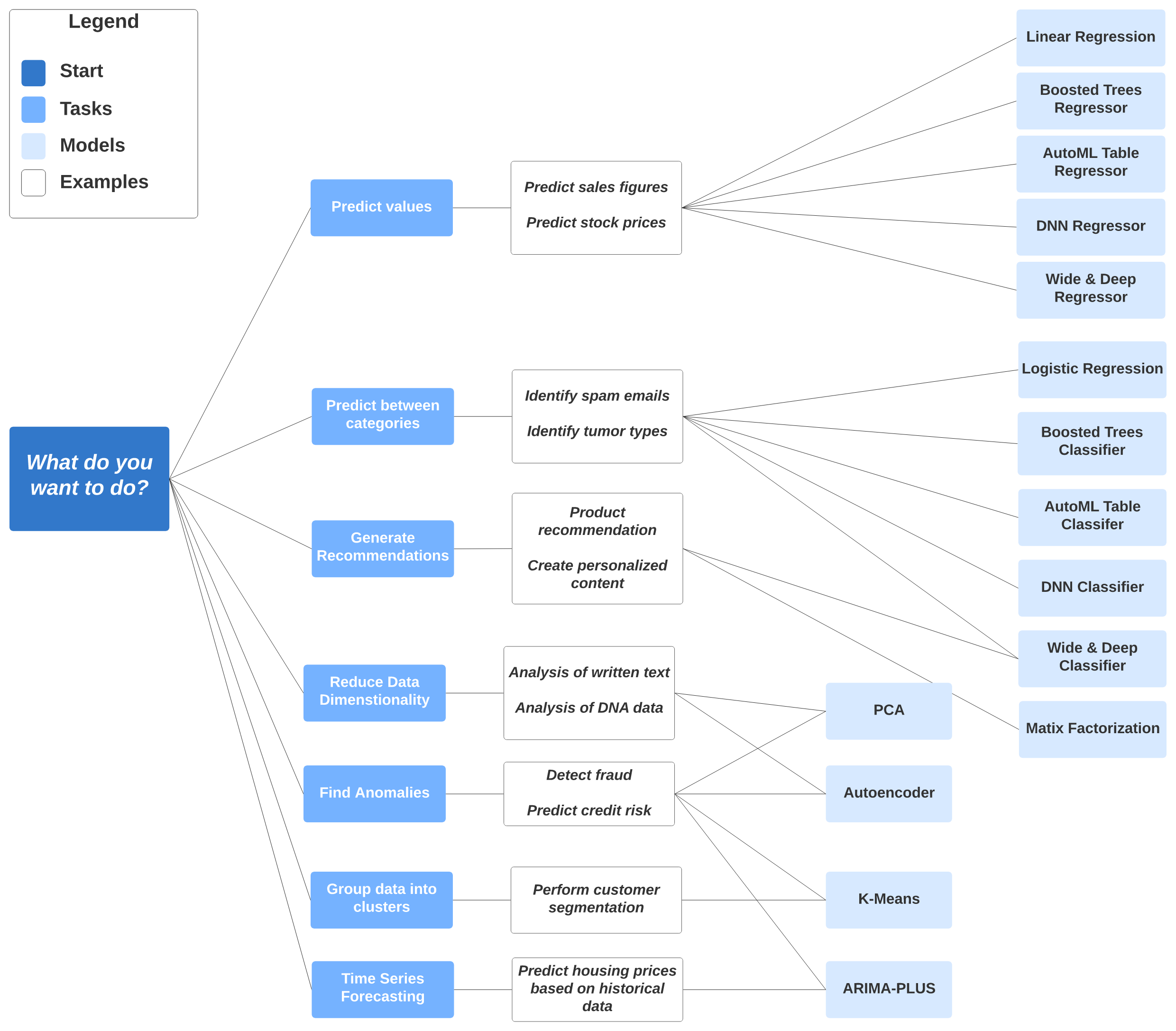
- 예측용 선형 회귀 (Linear Regresstion)
- 분류용 이진/멀티클래스로 로지스틱 회귀(Logistic Regression)
- 데이터 세분화용 K-means clustering
- 제품 추천 시스템을 만들기 위한 행렬 분해(Matrix Factorization)
- 시계열 예측 수행을 위한 시계열(Time series Prediction)
- XGBoost 기반 분류 및 회귀 모델을 만들기 위한 부스팅된 트리
- 분류 및 회귀 모델의 TensorFlow 기반 심층신경망을 만들기 위한 심층신경망(DNN)
- 특성 추출 또는 모델 선택 없이 최적 모델을 만들기 위한 AutoML Tables
Tensorflow 모델 가져오기 등이 모두 지원된다.
할당량, 리전
프로젝트 단위로 할당량을 적용한다.
BigQuery에서 SQL문으로 작업하는 것이기 때문에 BigQuery 쿼리 작업 및 할당량 및 한도가 적용되고 CREATE MODEL에는 다음의 한도가 적용된다.

서울 리전은 모든 ML모델이 지원되고 멀티 리전은 EU와 US만 지원된다.
펭귄 체중 예측
모델 생성
US 멀티 리전에 bqml_tutorial 데이터 세트 생성
(여기서 사용하는 public dataset이 US에 위치하기 때문)
bigquery-public-data.ml_datasets.penguins
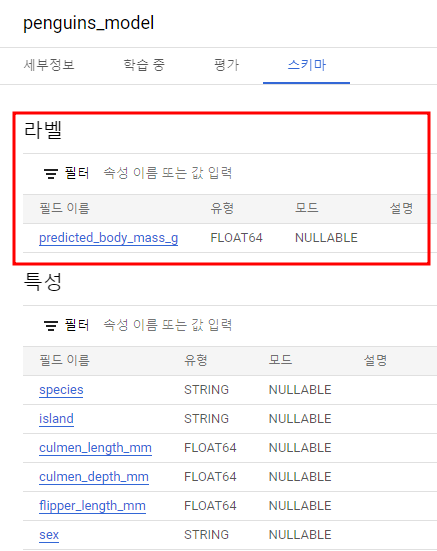
- species — 펭귄의 종(문자열)
- island — 펭귄이 사는 섬(문자열)
- culmen_length_mm — 컬멘 길이(밀리미터)(FLOAT64).
- culmen_depth_mm — 컬멘 깊이(밀리미터)(FLOAT64)
- flipper_length_mm — 지느러미의 길이(밀리미터)(FLOAT64)
- sex — 펭귄의 성별(문자열)
CREATE OR REPLACE MODEL `bqml_tutorial.penguins_model`
OPTIONS
(model_type='linear_reg',
input_label_cols=['body_mass_g']) AS
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL- OPTIONS(model_type='linear_reg', input_label_cols=['body_mass_g']) -> 선형회귀 모델을 뜻한다.
- body_mass_g열은 입력 라벨 열. 선형 회귀 모델에서 라벨 열은 실수치여야 한다. 즉, 열 값은 실수여야 한다.
CREATE MODEL과 OPTIONS만 입력해서 모델을 생성할 수 있고 콘솔에서 각종 지표들을 확인할 수 있다.

선형 회귀 모델을 평가할 때 초점은 예측 수치의 정확도를 평가하는 것이므로 '평가'에선 아래와 같이 평균 절대 오차(MAE), 평균 제곱 오차(MSE) 및 예측 값과 실제 값 간의 편차를 측정하는 결정계수(R^2)가 나온다.
로직스틱 회귀 분석을 하게 되면 '평가'에선 confusion matrix, ROC Curve 및 accuracy, precision, Recall, F1 score의 값들이 나온다.

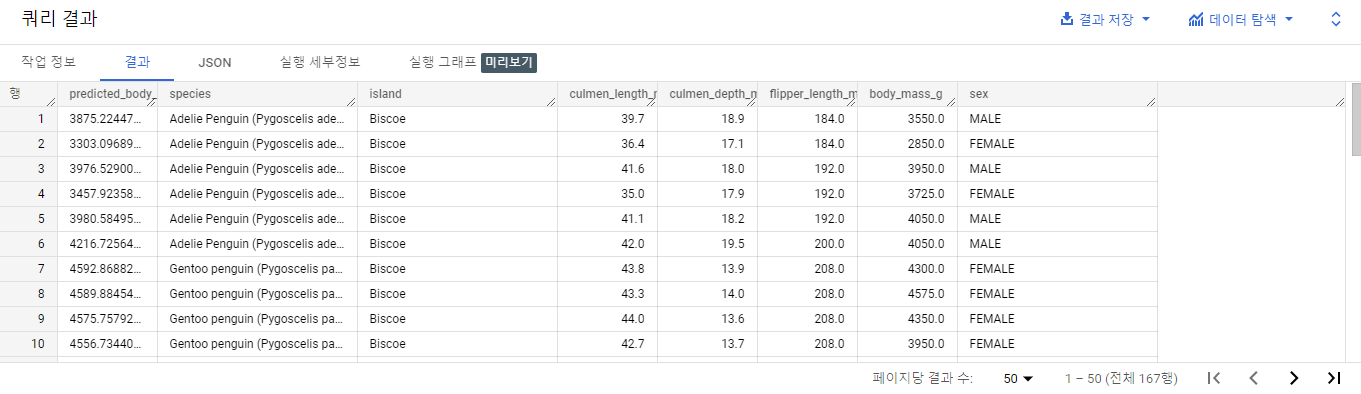
예측 생성
모델을 사용하여 Biscoe에 있는 모든 펭귄의 체질량을 그램 단위로 예측
SELECT
*
FROM
ML.PREDICT(MODEL `bqml_tutorial.penguins_model`,
(
SELECT
*
FROM
`bigquery-public-data.ml_datasets.penguins`
WHERE
body_mass_g IS NOT NULL
AND island = "Biscoe"))결과 확인
[BigQuery ML 참고]
https://cloud.google.com/bigquery/docs/bqml-introduction?hl=ko
