Cloud ML API

사용해볼 API는 Vision API, Translation API, Natural Language API이다.
Vision API를 호출해서 OCR을 사용하여 이미지에서 텍스트를 감지한 후 Translation API를 사용해 이미지의 텍스트를 번역, 마지막으로 Natural Language API를 사용해 텍스트를 분석할 것이다.
-
Vision API
Vision API는 REST API와 RPC API를 통해 선행 학습된 강력한 머신러닝 모델을 제공한다.
이미지에 라벨을 할당하고 사전 정의된 수백만 개의 카테고리로 빠르게 분류할 수 있다.
객체와 얼굴을 인식하고 인쇄 및 필기 텍스트를 읽으며 이미지 카탈로그에 유용한 메타데이터를 구축한다. -
Translation API
- Translation API Basic
Google의 인공신경망 기계 번역 기술을 사용해 텍스트를 100개가 넘는 언어로 즉시 번역한다. - Translation API Advanced
Basic과 마찬가지로 신속한 동적 결과를 제공하며 맞춤설정 기능을 추가적으로 제공한다.
맞춤설정은 용어 또는 구문을 분야와 문맥에 맞게 번역하고, 서식이 지정된 문서를 번역할 때 특히 중요한 기능이다.
- Translation API Basic
-
Natural Language API
Natural Language API는 강력하게 선행 학습된 모델을 통해 감정 분석, 항목 분석, 항목 감정 분석, 콘텐츠 분류 및 구문 분석 등의 기능을 수행하고 개발자가 애플리케이션에 자연어 이해(NLU)를 쉽게 적용할 수 있도록 지원한다.
이 외에도 Speech API, Video Intelligence API 등등 다양한 ML API들이 있다.
API 키 생성
curl 로 Vision API에 요청을 보내는 데에 사용할 것이므로 요청URL을 전달할 API 키를 생성해줄 것이다.
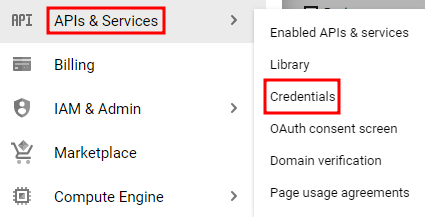
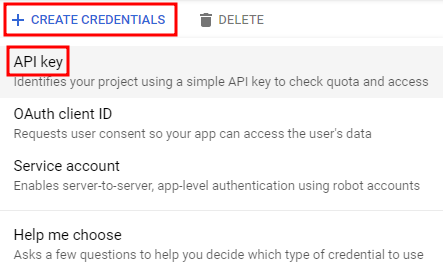
API 키를 생성한 다음 복사해둔다.
Cloud Shell 활성화
export API_KEY=<복사한 API KEY>Cloud Storage 버킷에 이미지 업로드
버킷 생성
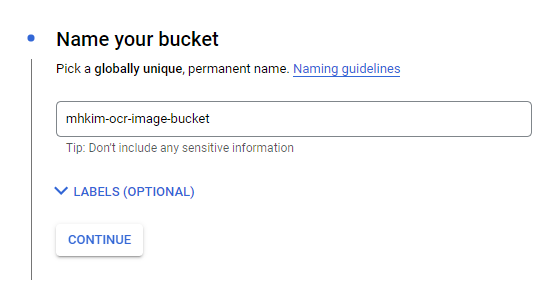
아래의 이미지를 sign.jpg로 저장 후 버킷에 업로드

버킷에 대한 액세스는 비공개로 유지하고 파일을 공개적으로 볼 수 있도록 설정
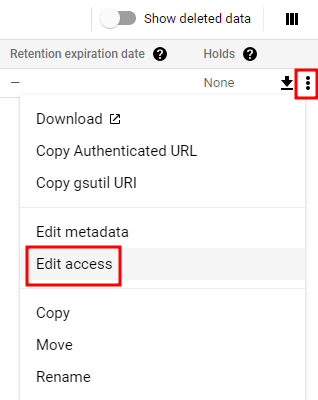
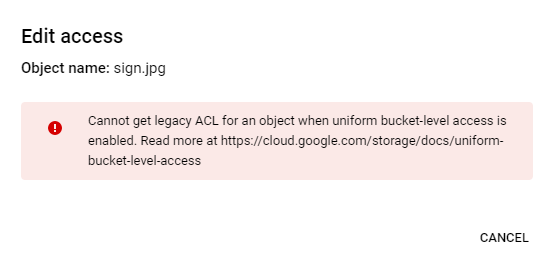
이런 오류가 뜰 것이다. 버킷이 균일한 액세스 제어로 되어 있기 때문에 따로 설정할 수가 없는 것이다.
권한으로 들어가서 균일한이 아니라 세분회된 액세스 제어로 설정해준다.
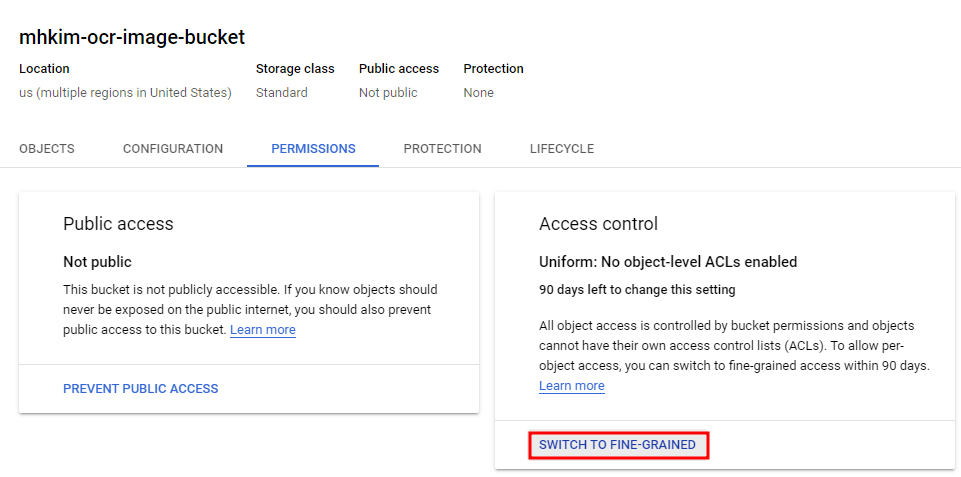
그러고 다시 보면 객체에 대한 액세스를 할 수 있을 것이다.
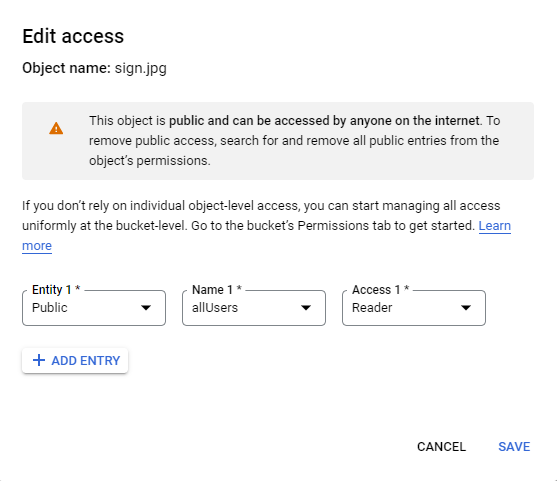
모든 user가 읽을 수 있도록 설정
아래의 json코드 Cloud Shell에서 생성
ocr-request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://mhkim-ocr-image-bucket/sign.jpg"
}
},
"features": [
{
"type": "TEXT_DETECTION",
"maxResults": 10
}
]
}
]
}Vision Api의 TEXT_DETECTION 기능을 사용할 것이다. 그러면 이미지에서 OCR을 실행하여 텍스트를 추출한다.
Vision API 호출
curl -s -X POST -H "Content-Type: application/json" --data-binary @ocr-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}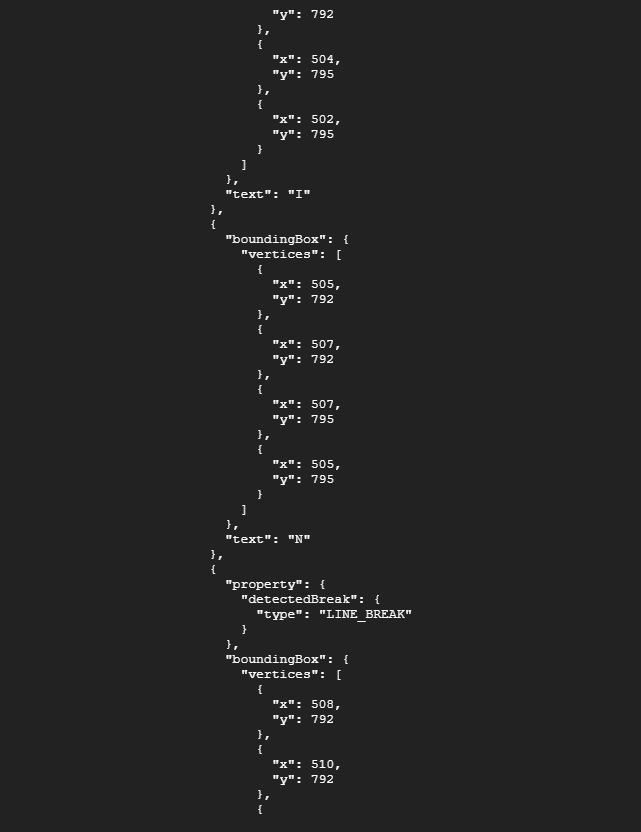
엄청나게 많은 줄이 뜬다.. 어쨌든 이미지가 텍스트를 잘 추출했다는 뜻이다..
여기엔 언어코드(여기선 프랑스어), 텍스트 문자열, 이미지에서 텍스트가 발견된 위치를 나타내는 bounding box가 포함되어 있다. 그런 다음 해당 특정 단어에 대한 bounding box가 있는 텍스트에서 찾은 각 단어에 대한 개체를 얻는다.
curl -s -X POST -H "Content-Type: application/json" --data-binary @ocr-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} -o ocr-response.jsoncurl 응답을 ocr-response.json 파일에 저장한다.
Translation API로 텍스트 번역
Translation API 는 텍스트를 100개 이상의 언어로 번역할 수 있다. 또한 입력 텍스트의 언어를 감지할 수 있다.
프랑스어 텍스트를 영어로 번역하려면 대상 언어(en-US)에 대한 텍스트와 언어 코드를 Translation API에 전달하기만 하면 된다.
아래의 json코드 Cloud Shell에서 생성
translation-request.json
{
"q": "your_text_here",
"target": "en"
}Shell에서 다음 명령어를 통해 Translation API를 호출할 준비를 한다.
STR=$(jq .responses[0].textAnnotations[0].description ocr-response.json) && STR="${STR//\"}" && sed -i "s|your_text_here|$STR|g" translation-request.json아래 명령어를 통해 얻은 응답을 translation-request.json 파일에 복사한다.
curl -s -X POST -H "Content-Type: application/json" --data-binary @translation-request.json https://translation.googleapis.com/language/translate/v2?key=${API_KEY} -o translation-response.json아래 명령어를 통해 Translation API가 잘 동작했는지를 확인할 수 있다.
cat translation-response.json
성공적이다.. 위의 사진에서의 글자와 비교했을때 영어로 번역까지 해서 나왔다.
detectedSourceLanguage는 프랑스어에 대한 ISO 언어코드이다.
Natural Language API로 텍스트 분석
Natural Language API는 엔터티를 추출하고 감정과 구문을 분석하고 텍스트를 범주로 분류할 수 있다.
아래의 json코드 Cloud Shell에서 생성
nl-request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"your_text_here"
},
"encodingType":"UTF8"
}- type
type에서 지원되는 건 PLAIN_TEXT와 HTML이다. - content
분석을 위해 Natural Language API로 보낼 텍스트를 전달한다.
Natural Language API는 텍스트 처리를 위해 Cloud Storage에 저장된 파일을 전송하는 것도 지원합니다.
Cloud Storage에서 파일을 보내려면 'content'를 'gcsContentUri'로 바꾸고 Cloud Storage에서 텍스트 파일의 uri 값을 사용하면 된다. - encodingType
텍스트를 처리할 때 사용할 텍스트 인코딩 유형을 API에 알려준다.
Shell에서 아래 명령어를 실행하여 번역된 텍스트를 위의 json파일에서 content에 해당되는 부분에 복사
STR=$(jq .data.translations[0].translatedText translation-response.json) && STR="${STR//\"}" && sed -i "s|your_text_here|$STR|g" nl-request.json이제 n1-request.json 파일엔 원본 이미지에서 번역된 영어 텍스트가 포함되어 있을 것이다.
analyzeEntities로 Natural Language API의 엔드포인트 호출
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @nl-request.json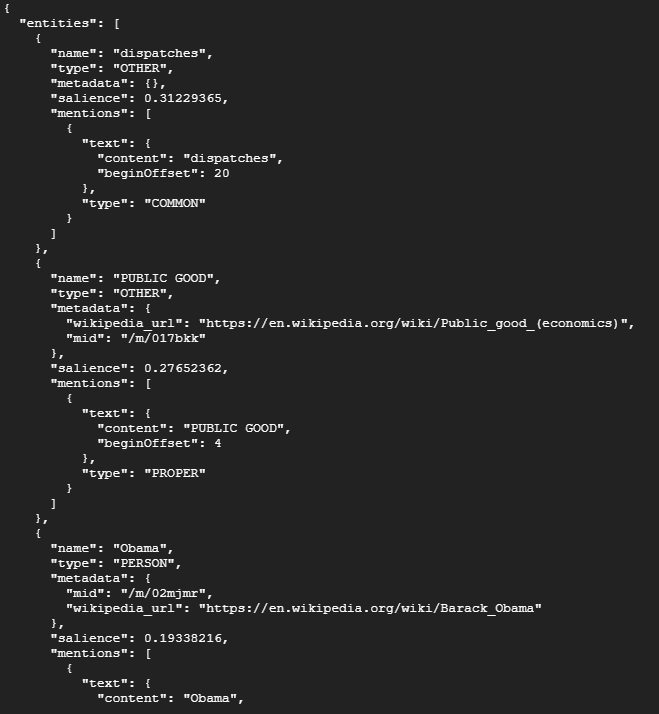
성공
자세히 보면 위키피디아 페이지가 매핑되어 있는 엔터티가 있다.
위키피디아 페이지가 있는 엔티티의 경우 API는 해당 페이지의 URL과 엔티티의 'mid'를 포함한 메타데이터를 제공한다.
'mid'는 구글의 'Knowledge Graph API'에서 이 엔티티에 매핑되는 ID
