Ollama란?
GPT, Claude, Gemini 등 대형 언어모델이 여전히 핫이슈이다. 하지만 이런 LLM을 사용하려면 보통 클라우드의 API를 사용해야 하고 그에 따른 비용도 만만치 않다.
Ollama는 무료로 오픈소스 LLM을 로컬 환경에서 실행하고 배포를 할 수 있게 해주는 AI 도구이다.
여기서 사용할 Google Gemma2뿐 아니라 다른 오픈 모델인 Llama, Mistral, Qwen2도 자유롭게 내 PC에서 호스팅 할 수 있다.
LLM 사용 뿐 아니라, Fine-Tuning을 할 시에도 클라우드의 API를 사용하면 모두 비용이지만 Keras와 같은 오픈소스 프레임워크를 사용하여 내 입맛에 맞게 조정이 가능하다.
Cloud Run GPU
하지만 여기선 내 로컬 PC에서 호스팅하진 않을 것이고 테스트를 위해 Cloud Run에 띄울 것이다.

왜냐면 아직 GA되진 않았지만 이제 Cloud Run에서 LLM과 같은 AI 추론 워크로드나 동영상 트랜스코딩 및 3D 렌더링 등의 작업을 위해 GPU가 지원되기 때문이다.
GPU는 NVIDIA L4 GPU가 지원된다.
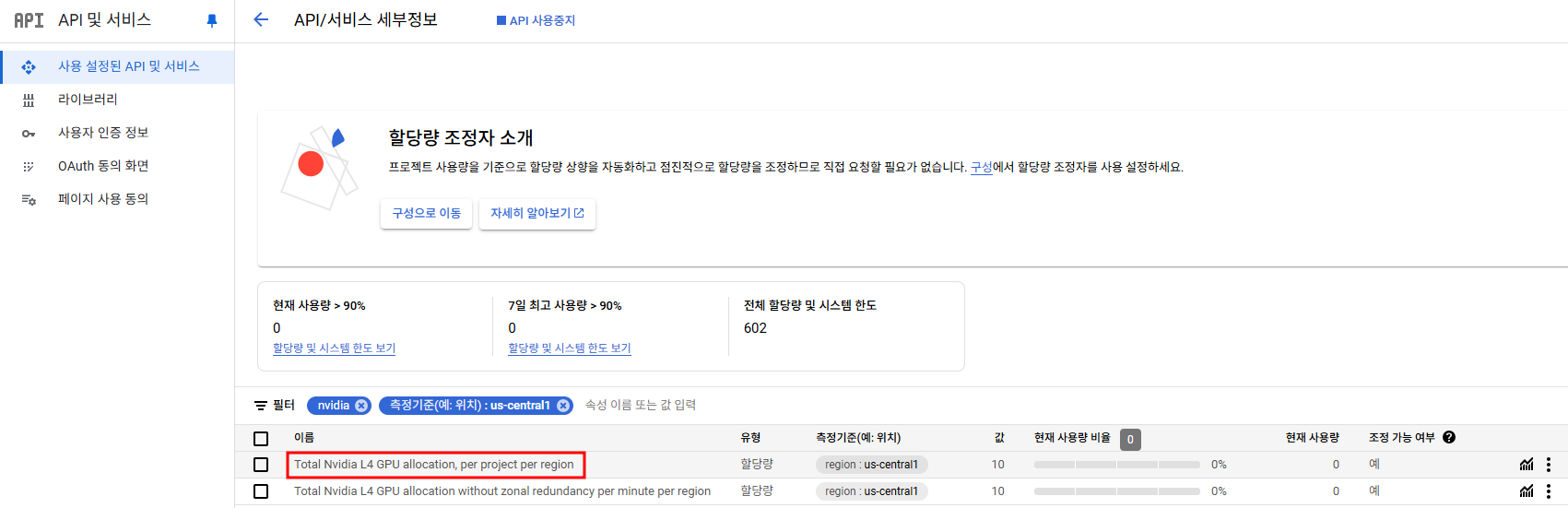
현재로썬 아직 us-central1, asia-northeast1, europe-west4에서만 지원되고 따로 API 할당량 조정 신청을 해야만 사용할 수 있다.
할당량 조정
GCP 콘솔 > API및 서비스 > Cloud Run Admin API 검색
난 us-central1에 배포할 것이므로 us-central1의 해당 항목에 대해서 할당량 조정을 신청했었다. 승인까지 최소 하루정도 걸리는 듯?!
(원래는 값이 0)
이제 Cloud Run에 LLM을 호스팅 해보자.
LLM 호스팅
사용할 모델은 gemma2:2b
Dockerfile
FROM ollama/ollama:0.3.6
# Listen on all interfaces, port 8080
ENV OLLAMA_HOST 0.0.0.0:8080
# Store model weight files in /models
ENV OLLAMA_MODELS /models
# Reduce logging verbosity
ENV OLLAMA_DEBUG false
# Never unload model weights from the GPU
ENV OLLAMA_KEEP_ALIVE -1
# Store the model weights in the container image
ENV MODEL gemma2:2b
RUN ollama serve & sleep 5 && ollama pull $MODEL
# Start Ollama
ENTRYPOINT ["ollama", "serve"]Cloud Run은 기본적으로 8080 포트를 listen 하므로 OLLAMA_HOST를 8080으로 매핑해줬지만 Ollama가 사용하는 default 포트는 11434이다. 해당 포트를 사용하려면 OLLAMA_HOST를 따로 적을 필요는 없고, 11434 포트를 EXPOSE한 후에 Cloud Run에 배포시 포트를 11434로 열어주면 된다.
이미지 빌드, Cloud Run에 배포는 Cloud Build를 통해 자동화했다.
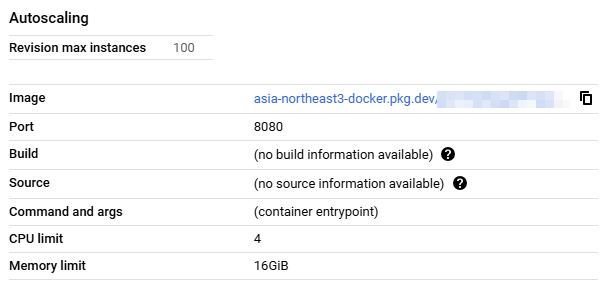
Cloud Run - only CPU
cloudbuild.yaml
# ...빌드쪽 설정 생략
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: 'gcloud'
args: [
'run',
'deploy',
'mhk-ollama-cpu-test',
'--image',
'asia-northeast3-docker.pkg.dev/<프로젝트 ID>/<저장소 이름>/<이미지 이름>:$TAG_NAME',
'--region',
'us-central1',
'--allow-unauthenticated',
'--memory',
'16Gi',
'--cpu',
'4',
'--timeout',
'600s',
'--platform',
'managed'
]
# ...확인
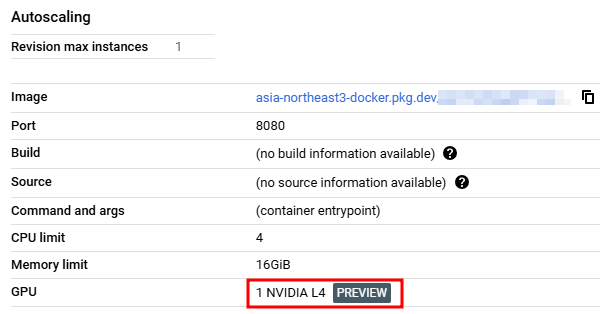
Cloud Run - with GPU
cloudbuild.yaml
# ...빌드쪽 설정 생략
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: 'gcloud'
args: [
'run',
'deploy',
'mhk-ollama-gpu-test',
'--image',
'asia-northeast3-docker.pkg.dev/<프로젝트 ID>/<저장소 이름>/<이미지 이름>:$TAG_NAME',
'--region',
'us-central1',
'--allow-unauthenticated',
'--memory',
'16Gi',
'--cpu',
'4',
'--gpu',
'1',
'--gpu-type',
'nvidia-l4',
'--no-cpu-throttling',
'--max-instances',
'1',
'--timeout',
'600s',
'--platform',
'managed'
]
# ...확인
모델 호출
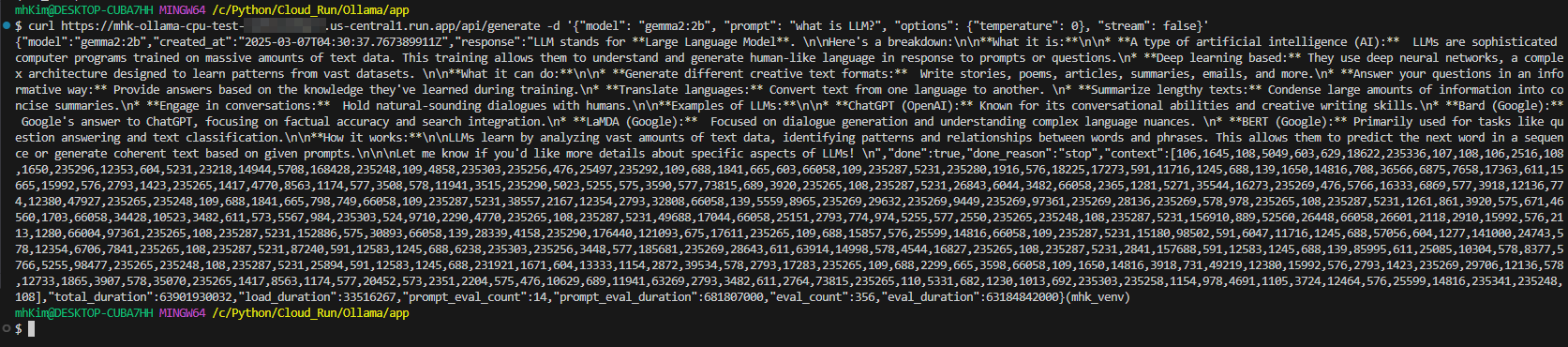
Ollama API 호출
기본적으로 model, prompt의 파라미터가 필요한데 호출을 하면 아래처럼 응답이 streaming으로 출력된다...
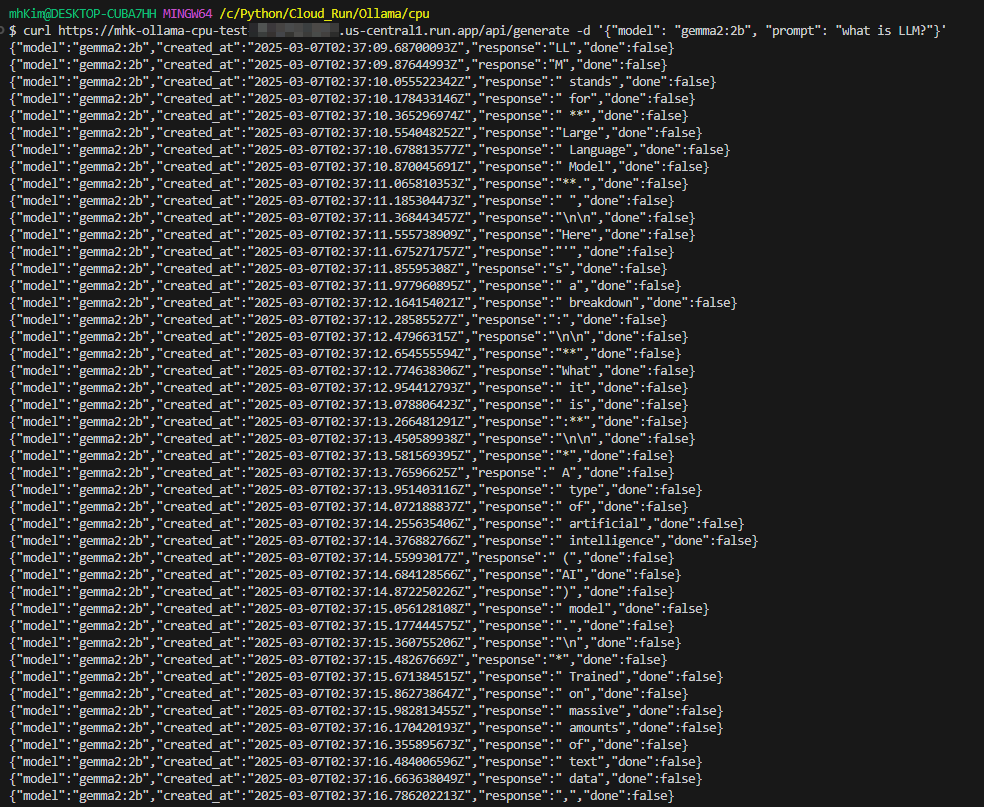
한 번에 출력을 하기 위해선 stream 파라미터를 추가하여 false로 설정하면 되고, temperature와 같은 다양한 파라미터 설정도 가능하다.
애플리케이션 구현
생성한 LLM 서버를 호출하여 Cloud Run의 GPU 성능 테스트를 할 수 있는 streamlit 애플리케이션을 만들어보자!!
app.py
import streamlit as st
import requests
import time
# API 엔드포인트 정의
ENDPOINTS = {
"gemma2:2b - CPU": "<CPU만 사용하는 Cloud Run Endpoint URL>/api/generate",
"gemma2:2b - GPU": "<GPU 사용하는 Cloud Run Endpoint URL>/api/generate"
}
# Streamlit UI
st.header("Ollama를 사용한 나만의 LLM 호스팅하기")
st.write("#### CPU, GPU 사용별 모델 응답 비교를 위한 성능 테스트 봇입니다.")
# 백엔드 선택 드롭다운
model_option = st.selectbox(
"모델 선택",
["gemma2:2b - CPU", "gemma2:2b - GPU"]
)
# 채팅 UI
chat_input = st.text_input("질문을 입력하세요:", "")
# 전송
if st.button("전송"):
if chat_input.strip():
# 선택된 백엔드의 API 엔드포인트
api_url = ENDPOINTS[model_option]
# API 요청 데이터
data = {
"model": "gemma2:2b",
"prompt": chat_input,
"options": {"temperature": 0},
"stream": False
}
# API 요청
with st.spinner("응답 생성 중..."):
start = time.time()
response = requests.post(api_url, json=data)
end = time.time()
if response.status_code == 200:
response_json = response.json()
answer = response_json.get("response", "응답을 가져올 수 없습니다.")
st.write("### 응답:")
st.write(answer)
st.write("### 시간:")
st.write(f"{start-end}초")
else:
st.error(f"오류 발생: {response.status_code}")
else:
st.warning("질문을 입력하세요.")
streamlit run
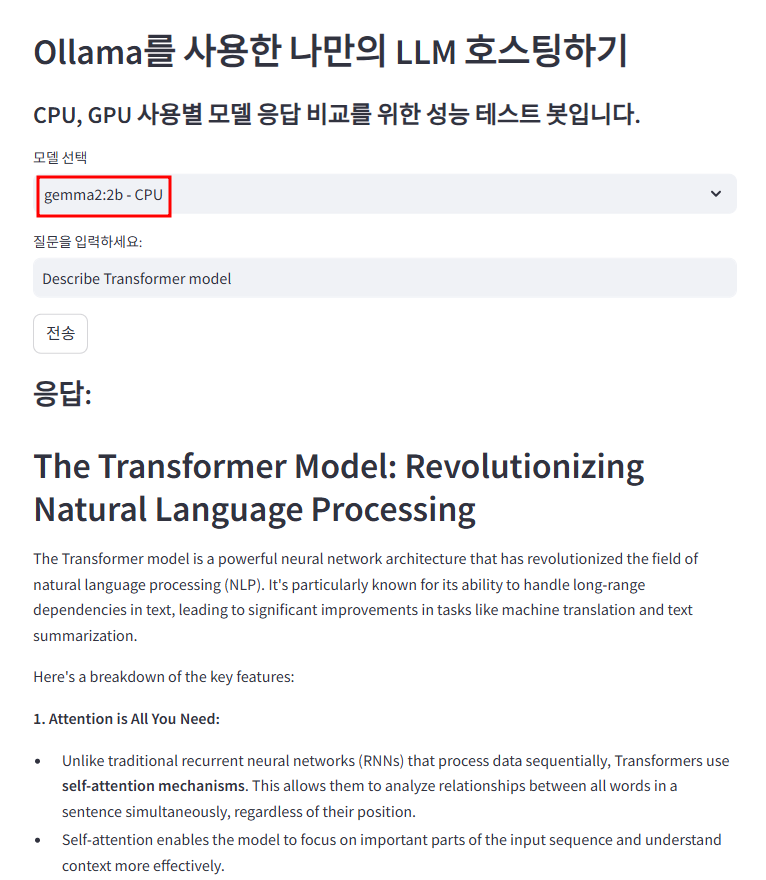
Q : Describe Transformer model
Cloud Run - only CPU

Cloud Run - with GPU
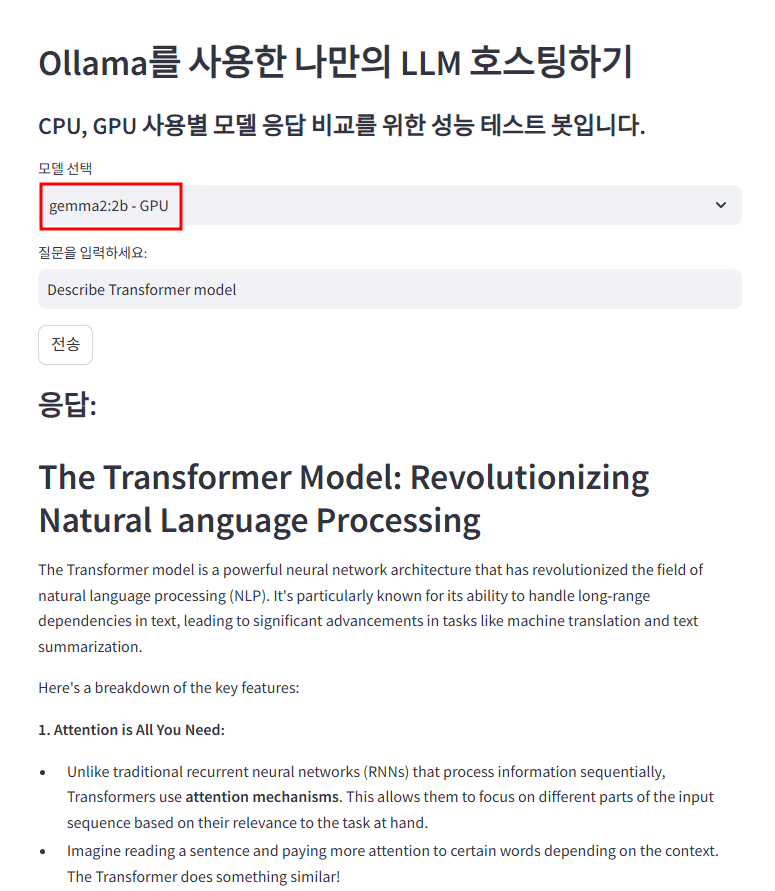

- only CPU : 97초
- with GPU : 22초
gemma2의 2b 모델이 아닌 9b 혹은 27b 모델을 사용하면 이보단 나을 것으로 보이나, 해당 모델에선 응답 속도 측면에서 기본적으로 약 4배 이상의 성능 차이를 보이는 것을 확인할 수 있다.
[Ollama를 사용한 나만의 LLM 호스팅하기 참고]
- https://cloud.google.com/run/docs/tutorials/gpu-gemma2-with-ollama?hl=ko
- https://medium.com/google-cloud/cloud-run-gpu-make-your-llms-serverless-5188caacc667
[Ollama API 참고]
