
Attention Method를 알기 위해서는 RNN의 흐름과 LSTM의 깊은 이해가 필요하다.
RNN
가장 먼저 살펴볼 RNN은 기본적인 RNN의 형태인 Vanila RNN에 대한 얘기이다.
RNN은 Recurrent Neural Network의 줄임형태이며, 한국어로는 순환신경망이라고 얘기한다.
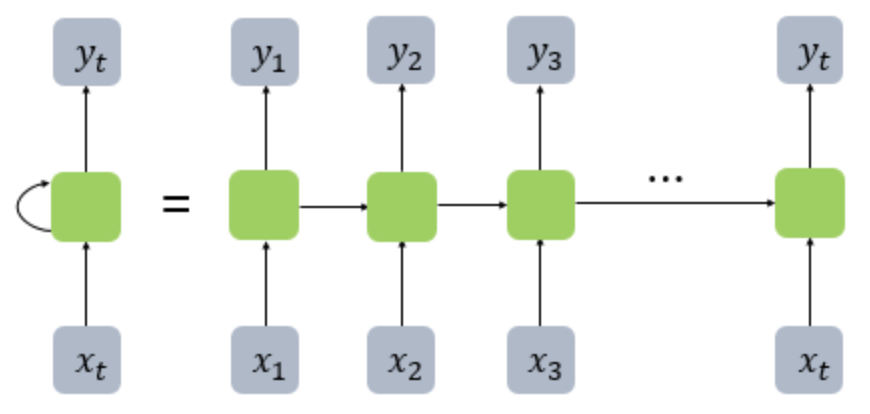
그림에서 초록색 부분을 Cell이라 하는데, 각 Cell에서 이전 상태의 값을 저장하고 있기에, 일종의 메모리역할을 수행한다. 따라서 메모리셀 또는 RNN셀이라고 부른다.
메모리셀은 출력층 방향으로 출력의 값을 보내거나, 다음 은닉층의 방향으로 현재 은닉층의 정보인 을 전달한다.
수식적으로 표현하면 다음과 같다.
은닉층 :
출력층 :
단 여기서 f는 활성화 함수이다.
각 시점에서의 은닉층의 형태는 동일해야 하기에, 연산이 진행될때의 각 크기는 다음과 같다.
따라서 은닉층의 형태를 표현하면 다음과 같다.
LSTM
LSTM은 Long Short-Term Memory의 줄임말로, 한국말로는 장단기 메모리라고한다. RNN의 일종으로 바닐라 RNN의 한계점을 극복하기 위해 등장하였다.
기존 Vanila RNN의 문제점 - the problem of Long-Term Dependencies (장기 의존성 문제)
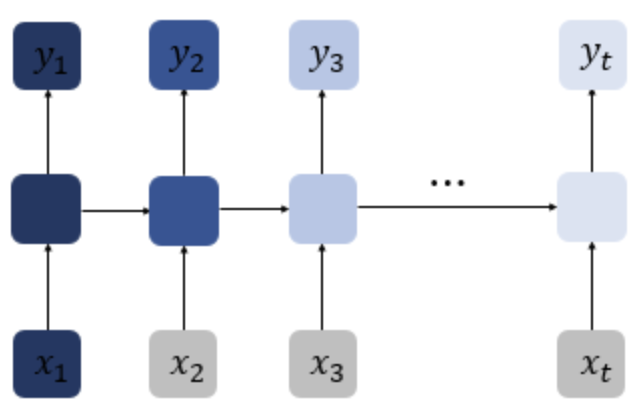
이미지 참조 : 딥러닝을 이용한 자연어 처리 입문
기존의 RNN은 이전의 은닉층에 의존을 많이 하고 있다. 따라서 time step이 긴 은닉층 정보의 반영은 적게 될 수 밖에 없다. 하지만 문자열에서는 문장의 앞에 나오는 정보가 중요한 의미를 가지는 경우가 많기에, 이러한 문제점은 critical하다.
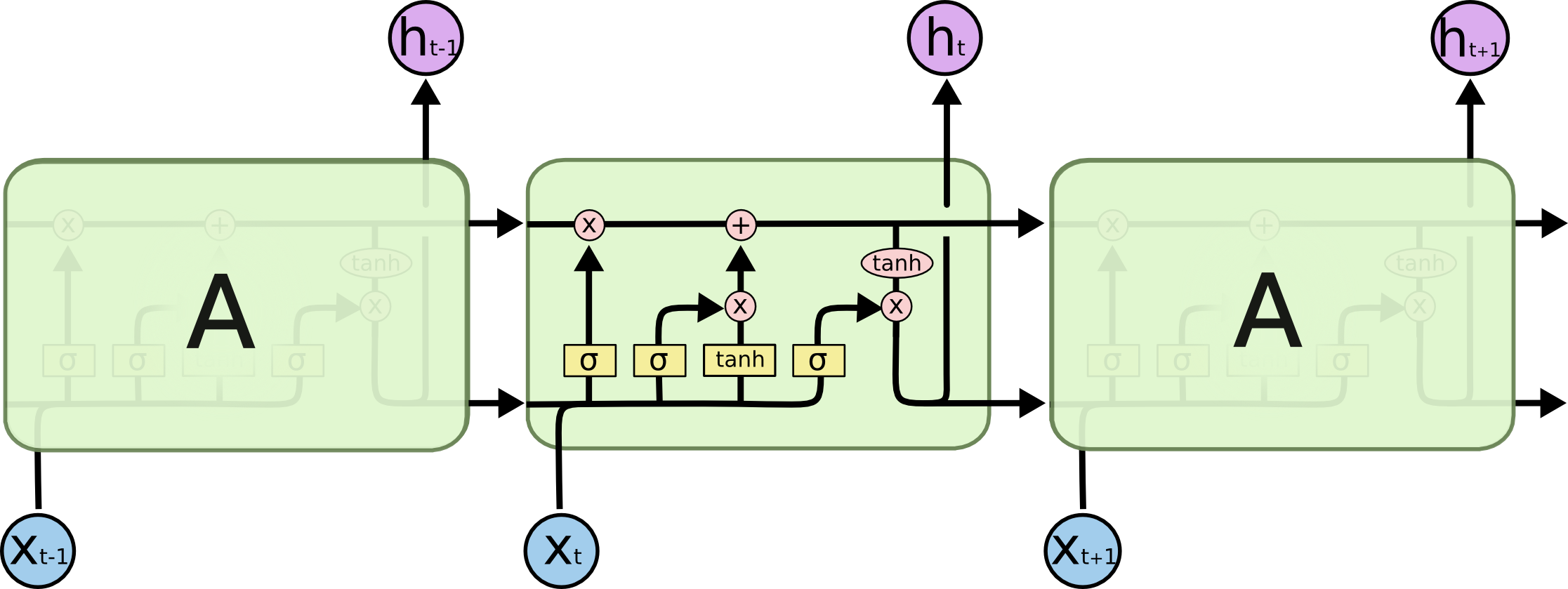
이미지 참조 : Long Short-Term Memory
LSTM의 구조는 다음과 같이 4개의 노란색의 Neural Network Layer을 이용하여 서로 정보를 주고 받을 수 있도록 한다.
LSTM의 가장 핵심적인 요소는 cell state이다.
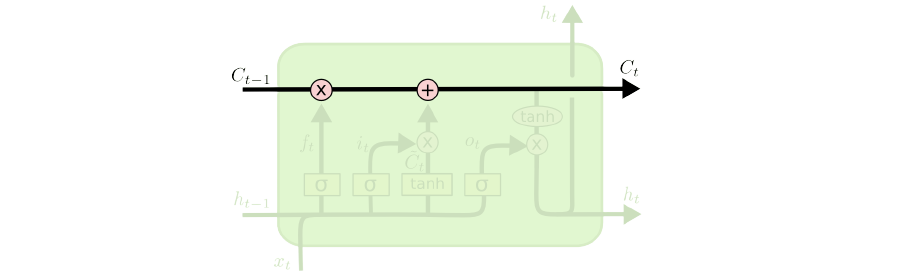
이미지 참조 : Long Short-Term Memory
동일한 cell state에 빨간색의 x연산과 +연산을 통하여 cell state에 정보를 변형하거나 추가할 수 있다.
첫번째 x연산에서는 Sigmoid Layer()에서 0~1사이의 숫자를 통하여 각 컴포넌트가 얼마만큼의 가중치를 반영해야할지를 결정짓는다.
why?
sigmoid의 함수의 경우 0~1의 값을 출력하는 활성화 함수로써 이를 이용하여 가중치를 계산한다. 이를 바탕으로 0의 값이 도출되면, 이전의 state는 제거한다는 의미이고, 1이 도출되면 이전 cell state를 계속 가져간다는 의미이다.
step 1 : Forget Gate Layer
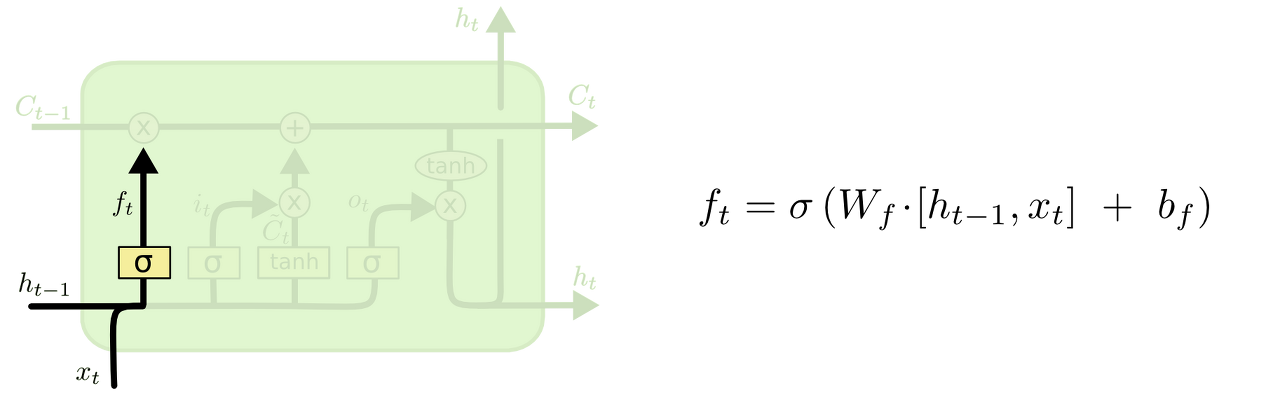
LSTM의 첫번째 단계로는 sigmoid layer을 이용하여 이전 cell state ()을 얼마나 가중치를 둘 것(버릴것) 인지에 대해서 계산한다.
따라서 이를 forget gate layer이라 한다.
step 2 : Input Gate Layer
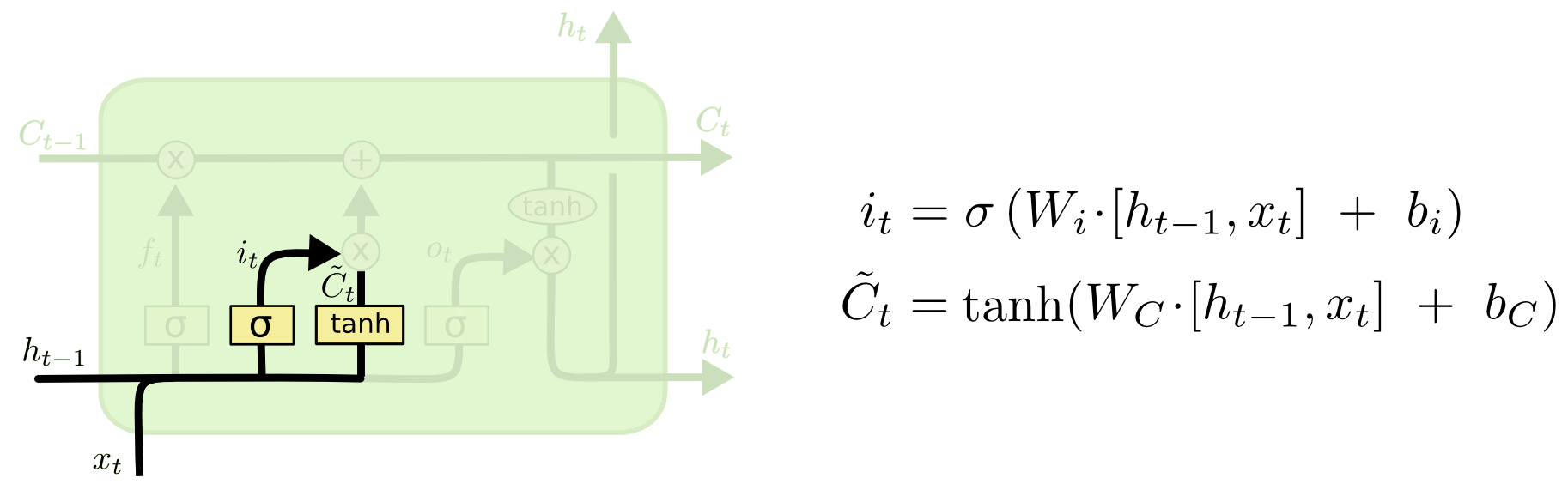
LSTM의 두번째 단계로는 앞으로 들어오는 정보중에 어떠한 정보를 새롭게 저장할 것인지를 결정하는 단계이다. 과거 Cell State인 를 update하여 새로운 Cell State인 를 생성한다.
앞의 Forget Gate Layer 에서 에 를 곱하여 잊어버리도록 하였으므로, 새로운 정보에 대한 값인 를 더한다
여기서 sigmoid layer을 통해 계산된 는 의 정보가 추가되는 비율을 설정해 준 것이며, 가 새로 들어온 정보를 바탕으로 계산한 결과이다.
step 3 : Upate Cell State
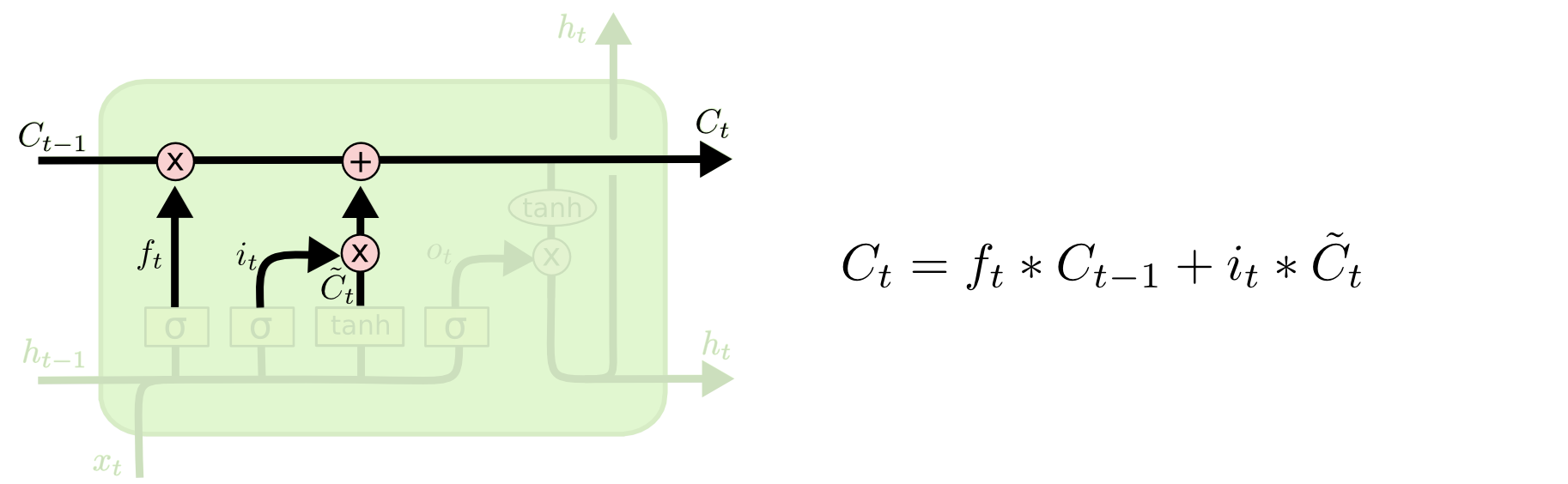
이전의 들어온 cell state의 값을 일부 잊어버리고, 새로운 정보를 추가한다. 이렇게 진행하면 새로운 cell state인 를 생성할 수 있다.
step 4 : Output Gate Layer
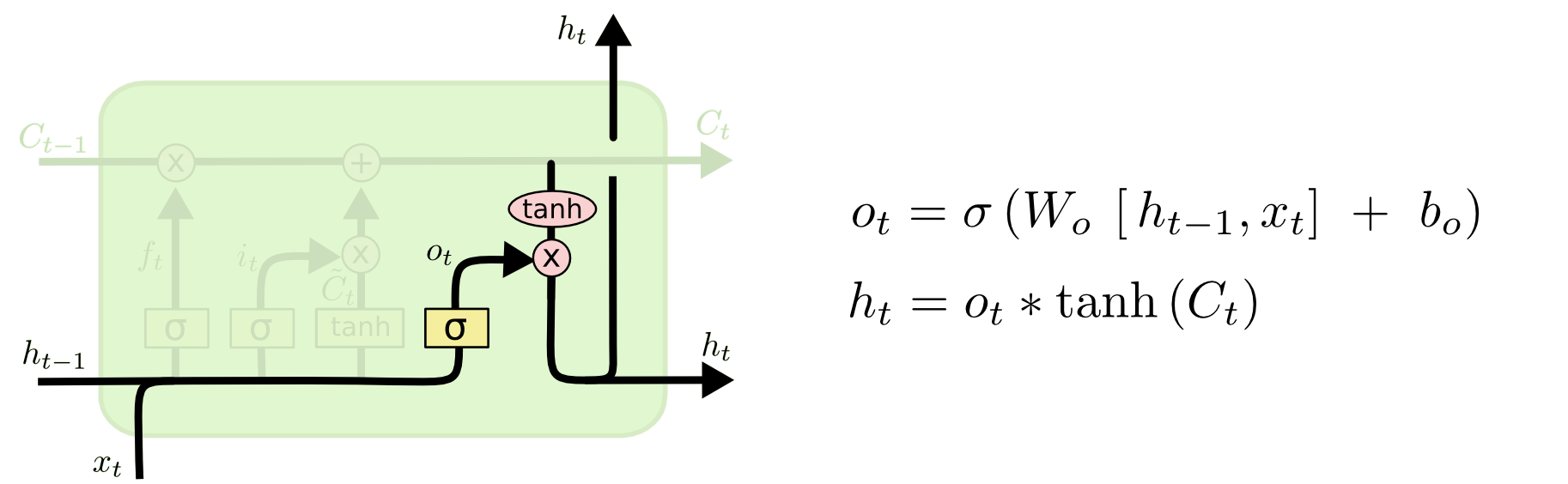
output gate Layer에서는 우리가 계산한 새로운 cell state의 어느 부분을 output으로 내보낼지를 결정짓는다. input을 바탕으로 sigmoid layer을 계산한다. sigmoid를 바탕으로 cell state의 어떤 부분을 output으로 내보낼지를 결정한다. 그리고 를 이용하여 -1 와 1 사이의 값으로 바꾼다. 이후 sigmoid의 값과 곱해주어 원하는 부분만 output으로 보내준다.
이러한 특징들때문에, LSTM이 대부분의 문제에 대해서 RNN보다 높은 성능을 보여주고 있다.
seq2seq
한 시퀀스의 모델을 다른 시퀀스의 모델로 변환해주는 과정을 수행해주는 딥러닝 모델이다. 이는 Encoder와 Decoder의 모듈을 사용하여 입력 시퀀스를 원하는 출력 시퀀스로 변환한다.
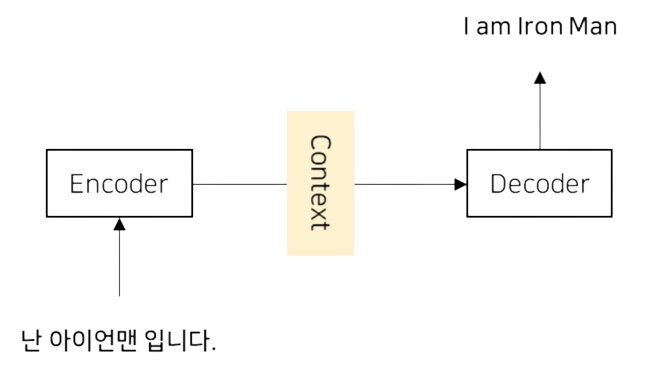
그림으로 표현하면 다음과 같이 Encoder을 통하여 context vector을 생성하고, Decoder을 바탕으로 원본 데이터를 만들어낸다.
Encoder
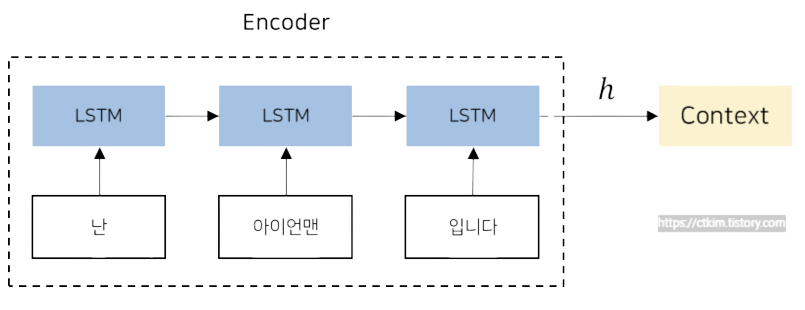
인코더가 생성한 Context Vector 은 LSTM의 마지막 hidden state이다. 또한 Context Vector은 고정되어있는 크기의 벡터이다.
즉 input sentece의 길이에 상관없이 고정된 크기의 output을 나타낸다.
Decoder
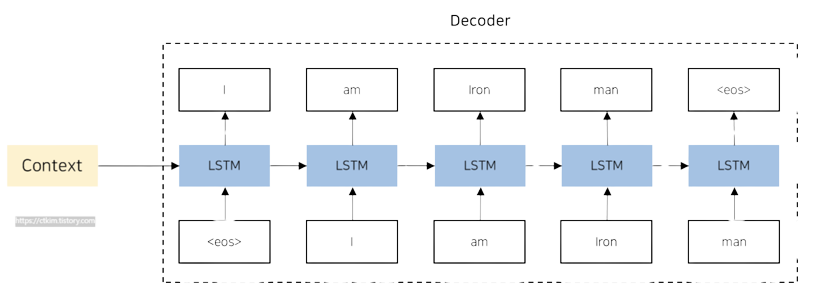
디코더는 인코딩을 진행한 결과인 Context Vector을 바탕으로 출력 시퀀스를 생성한다. 디코더의 예측은 소프트맥스 활성화 함수를 통해 확률 분포로 변환되며, 가장 높은 확률을 가지는 단어가 생성된다.
Attention
기존 RNN을 기반으로 구현한 seq2seq는 크게 2가지 문제점을 가지고 있다.
1. 하나의 고정된 크기의 벡터에 모든 정보를 저장하려고 하니 정보의 손실이 일어난다.
2. RNN의 고질적인 문제인 기울기 소실 (vanishing gradient)의 문제가 발생한다.
어텐션은 디코더에서 출력을 진행하는 매 시점마다 인코더의 전체 입력 문장을 참고한다는 점이다. 단, 모든 문장을 확인하는 것이 아닌, 필요한 부분을 집중해서 본다는 의미에서 Attention 기법이다.
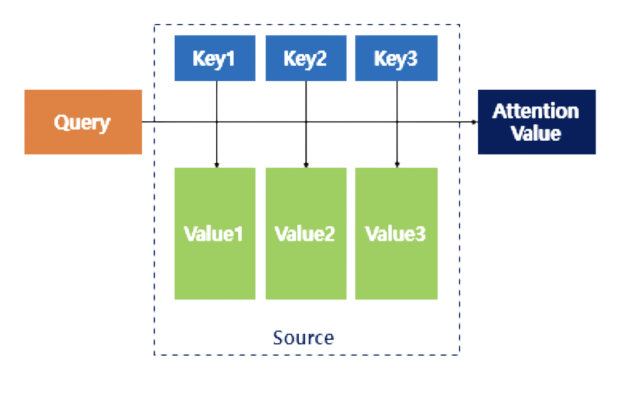
이때 어텐션을 함수로 표현하면 다음과 같다.
시점의 decoder cell 에서의 은닉 상태
모든 시점에서의 encoder cell 의 은닉 상태들
모든 시점에서의 encoder cell 의 은닉 상태들
Dot-Product Attention
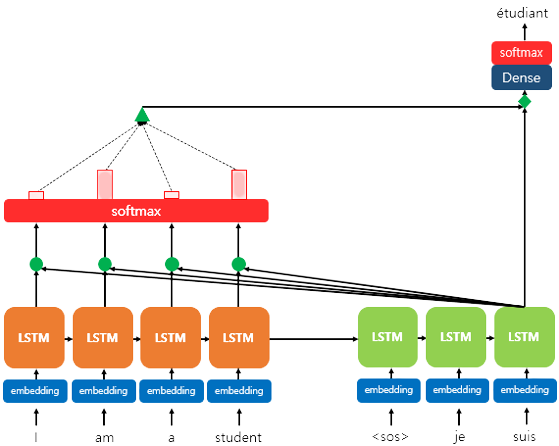
위 그림은 3번째 Decoder LSTM에서 어텐션을 사용하는 과정을 나타낸다. Decoder의 je와 suis까지는 결과가 도출되었으며, 이후의 값을 예측하기 위해 Encoder의 각각의 hidden state의 softmax를 구하여, 각 입력의 단어가 어느정도 도움이 도움이 되는지 수치화 하여 Decoder쪽으로 전달된다.
1) Attention Score 도출
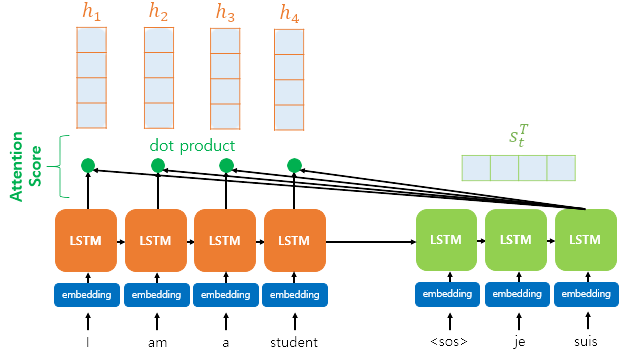
인코더의 각 time step에 대한 hidden state(은닉 상태)를 이라 하고, decoder의 각 time step에 대한 hidden state(은닉 상태)를 라 하자.
Attention score이란, decoder의 t시점에 값을 예측하기 위해, encoder의 모든 hidden state중에 현재 decoder의 hidden state값과 유사한지를 판단하는 스코어이다.
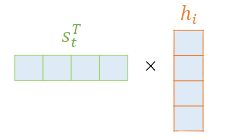
Dot-Product Attention에서는 각각의 스코어 값을 구하기 위해 각 은닉의 상태와 내적 연산을 수행한다. 내적연산을 수행하기 위해 decoder의 hidden state값을 와 같이 transpose하여 연산을 수행한다.
Attention Score을 정의하면 다음과 같다.
을 구하는 과정을 각 hidden state을 구하는 covariance로 이해해도 좋을 것 같다!
이를바탕으로 의 모든 encoder와의 attention score의 값의 모음을 라고 정의하면 다음과 같다.
2)Get Attention Distribution using SoftMax function
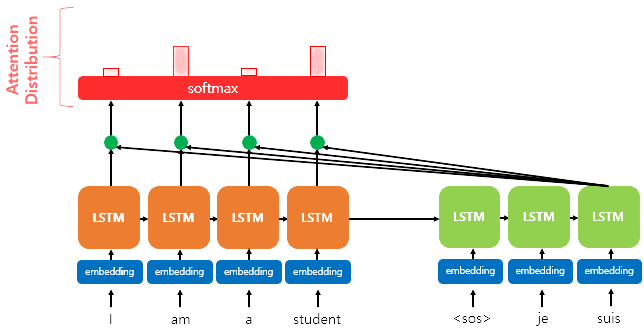
이제 구한 각각의 Attention Score을 바탕으로 SoftMax function을 이용하여 각 encoder의 hidden state에 대한 확률분포를 얻어낸다. 이를 Attention Distribution이라 한다.
그림에서는 예시로 인 경우이다.
Attention Distribution을 라고 표현하면,
3) Attention Distribution 와 hidden state를 가중합하여 Attention Value구하기
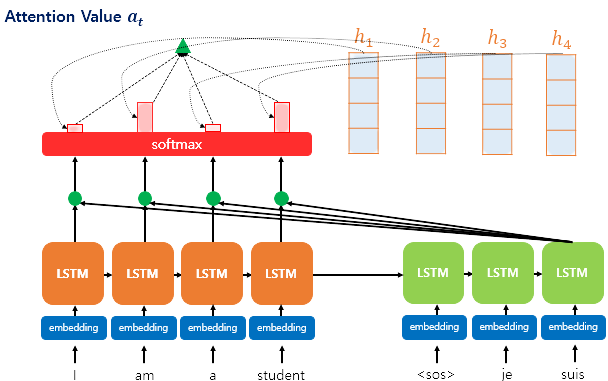
Attention 의 각각의 Attention Distribution(가중치)와 hidden state(은닉층)의 값을 곱한 것들을 전부 더한다. Weighted Sum(가중합)을 이용하여 Attention Value를 구한다.
이는 Encoder의 정보를 포함하고 있다고 하여 context vector라고도 불린다.
seq2seq에서 LSTM의 final state에 해당하는 Context Vector와는 다른 의미이므로 주의할 것!
수식은 다음과 같다.
Encoder의 hidden state의 정보를 비율만큼 반영한 종합정보를 도출한다.
4) Attention Value와 Decoder의 hidden state를 concat한다.
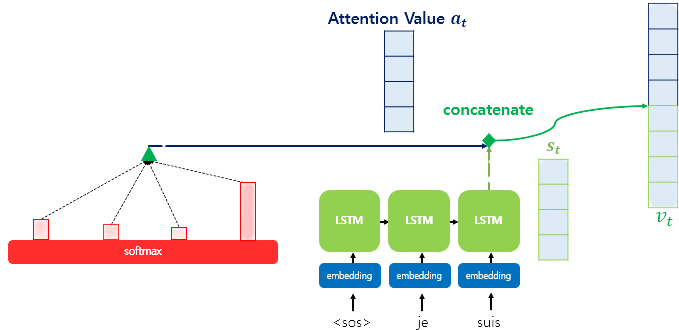
최종적으로 구한 Attention Value인 와 Decoder의 시점의 hidden state인 와 concat하여 하나의 vector로 만든다.
그림의 예시를 보면 와 을 concat하여 형태의 벡터가 구해진 것을 확인할 수 있다. 이러한 를 바탕으로 를 예측하는데 사용하여, 보다 정확하게 예측할 수 있도록 한다.
5) 출력층의 Input이 되는 를 계산한다.
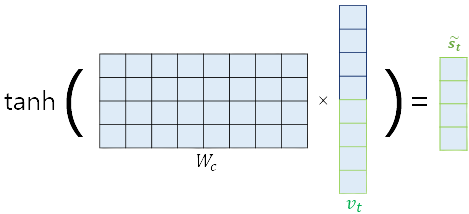
출력층 로 보내기 전에 한번더 은닉층의 학습을 진행한다. 이때 의 경우 학습이 가능한 parameter이며, 이다.
해당과정을 수행해야 하는 이유는 을 계산하기 위해서는 와 값이 필요하기 때문이다.
6)를 출력층의 입력으로 사용하여 예측한다.
