
웹페이지 주소
https://flexngrid.com/
오픈소스 프로젝트인 flexngrid 페이지에서 담당한 영역에 대해 기록해보려 한다.
제주코딩베이스캠프 이호준 대표님이 모집한 프로젝트로, flex와 grid에 대한 내용과 실제로 실습이 가능한 오픈소스 페이지이다. 교육적으로 사용할 수 있는 페이지에 관심이 있었고 재밌을 것 같아 프로젝트에 참여하게 되었다.
이전부터 검색 기능을 해보고 싶었는데 마침 자리가 비어있어서 검색을 담당했다.
검색 모달
검색한 내역 배열에 저장하기
먼저 모달에서 검색한 내역을 저장해주기 위해서 빈 배열을 생성하고, 검색할때마다 input에 들어간 텍스트를 배열에 저장해줬다.
최근 검색어가 위에 올라와야 하므로, 배열 뒤에 저장하는 push가 아닌 앞 순서로 저장하는 unshift로 배열에 저장해주었다.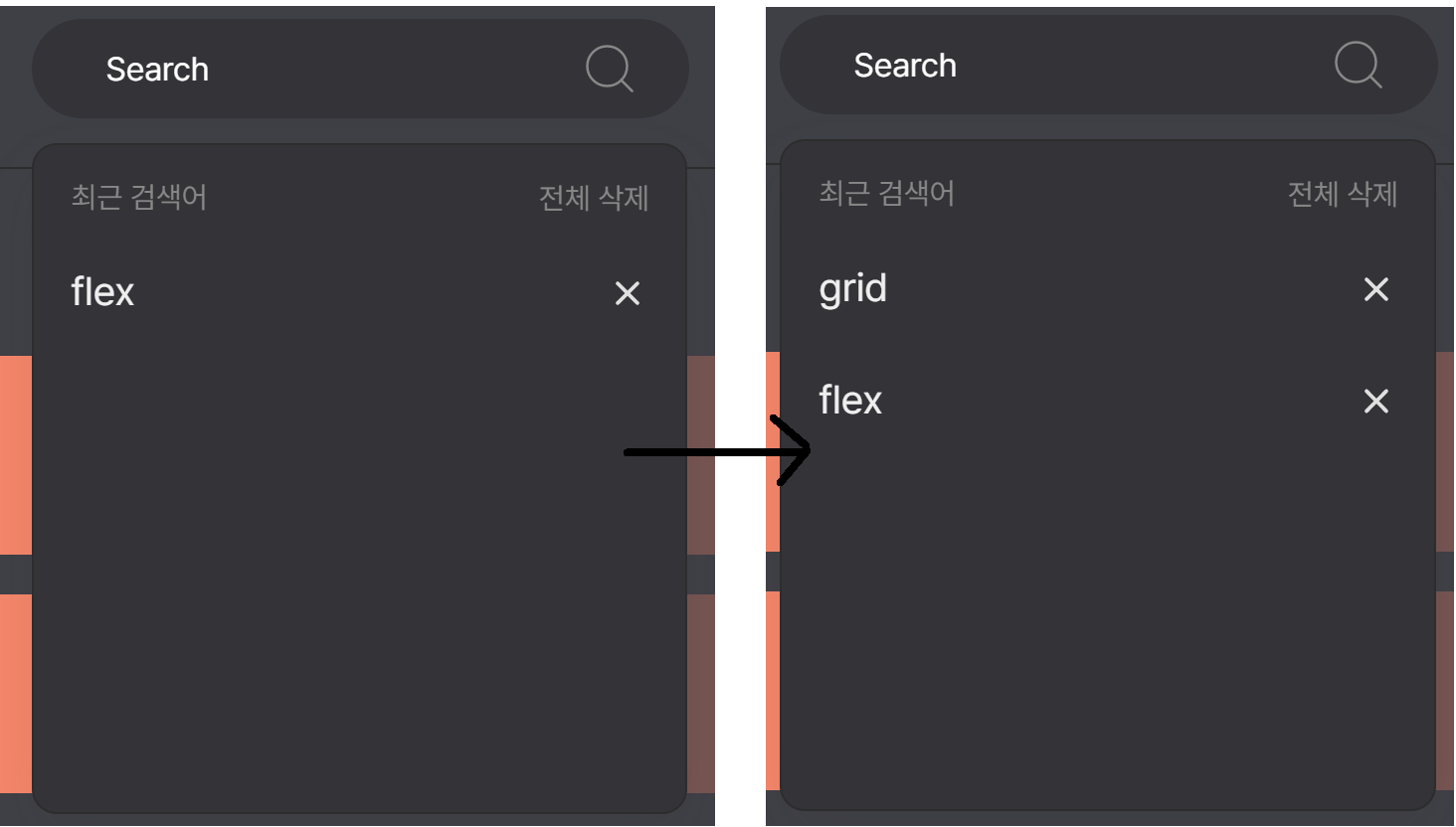
생각한 것과 다르게 신경쓸 것이 꽤 있었는데, 검색 내용 없이 그냥 검색을 했을 경우와 같은 내용을 검색한 경우에도 배열에 추가되어서 조건문으로 비어있거나 이미 있는 내용이 아닐때만 배열에 추가하도록 했다.
if (!searchHistory.includes(searchInputs.value) && searchInputs.value) { if (searchHistory.length > 4) { searchHistory.pop(); searchHistory.unshift(searchInputs.value); } else { searchHistory.unshift(searchInputs.value); }
includes는 배열이 특정 요소를 포함하는지 판별한다. 그리고 검색어는 5개까지만 저장되기 때문에 5가 넘어갈때 pop으로 뒤에 있는 배열요소를 제거했다.
발생한 문제
이미 검색한 내용으로 다시 검색한 경우에는 배열에 추가되지 않아서 최근 검색어로 올라오지 않고 같은 자리에 있는 문제가 있었다.
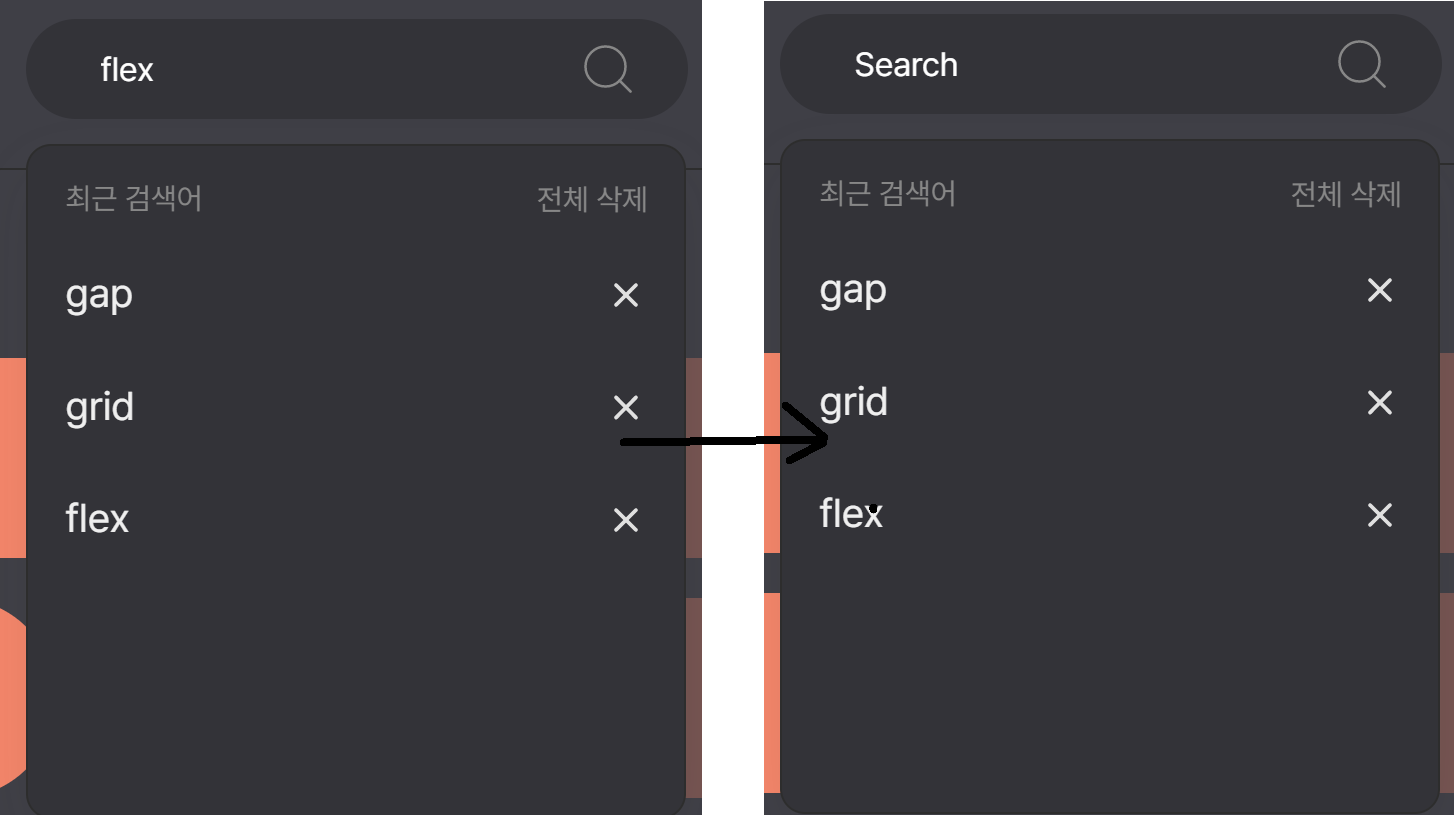
검색어가 동일한 경우에는 filter를 사용해서 검색어를 빼고 저장한 뒤 다시
unshift로 저장해줘서 중복된 검색어라면 제일 앞으로 가도록 바꿔서 문제를 해결했다.
let searchHistory=[]; /*if (!searchHistory.includes(searchInputs.value) && searchInputs.value) { if (searchHistory.length > 4) { searchHistory.pop(); searchHistory.unshift(searchInputs.value); } else { searchHistory.unshift(searchInputs.value); } }*/ else if (searchHistory.includes(searchInputs.value)) { searchHistory = searchHistory.filter((text) => { return text !== searchInputs.value; }); searchHistory.unshift(searchInputs.value); }
localstorage로 데이터 저장
내가 검색한 내역은 다른 페이지에서도 보여야하고, 페이지를 종료했다 다시 들어왔을 때도 저장이 되어 있어야 해서 localstorage를 활용해서 배열리스트를 받아오게 작업했다.
localStorage.setItem('searchHistoryData', JSON.stringify(searchHistory));
localStorage는 무조건 string 형태로 데이터를 저장하기 때문에 JSON.stringify로 배열 형태로 저장했다. 받아올때는JSON.parse로 받아오면 된다.
const searchData = localStorage.getItem('searchHistoryData'); if (searchData !== null) { searchHistory = JSON.parse(searchData); }
검색 배열이 달라질때마다 localStorage에 저장해주었다.
검색 리스트 삭제
X버튼을 눌렀을 때 해당 검색 리스트가 삭제되는 기능을 만들기 위해 previousSibling과 filter를 이용했다.
마크업 상 X버튼 위에 텍스트가 저장되기 때문에 요소의 바로 이전 형제를 찾는 previousSibling을 사용해 텍스트를 저장한 뒤 filter로 배열을 다시 반환시킨다.
if (e.target.classList.value == 'btn-del') { e.preventDefault(); const inText = e.target.previousSibling.innerText; searchHistory = searchHistory.filter((text) => { return text !== inText; }); localStorage.setItem('searchHistoryData', JSON.stringify(searchHistory)); }
전체 삭제는 배열을 빈 배열로 바꿔주기만 하면 된다.
리스트 동적 생성
모달이 켜질때 배열의 정보로 리스트를 생성해주기 위해 함수를 작성했다. 마크업은 따로 담당자가 있어서 담당자가 만든 마크업대로 생성해주었다. forEach로 배열을 순회해서 순서대로 동적으로 생성해준다. createElement, setAttribute, appendChild, createTextNode을 이용했다. 이전에도 js 프로젝트에서 해당 기능들로 생성했었기 때문에 쉽게 만들 수 있었다.
발생한 문제
모달이 열릴 때 마다 동적생성이 이뤄지기 때문에 계속해서 리스트가 추가되는 문제가 있었다. 생성하기 전에 한번 비워주는 과정이 필요했다.
const removeChildAll = (ele) => { while (ele.hasChildNodes()) { ele.removeChild(ele.firstChild); } };
생성하는 함수에 해당 코드로 자식 요소를 비워주게 해서 같은 리스트가 계속 쌓이는 문제를 해결했다.
완성된 모습
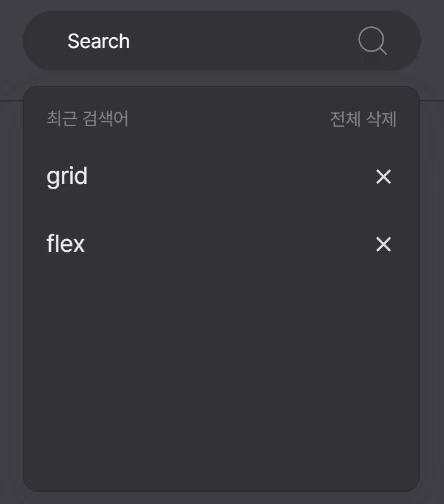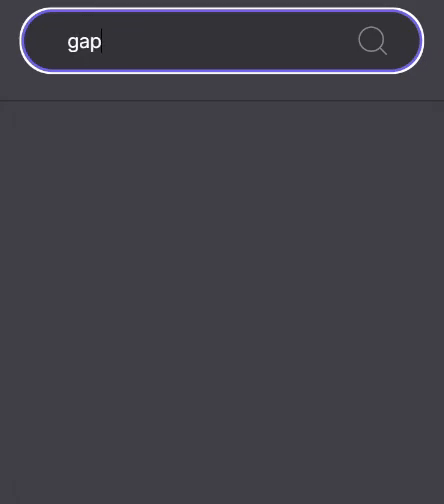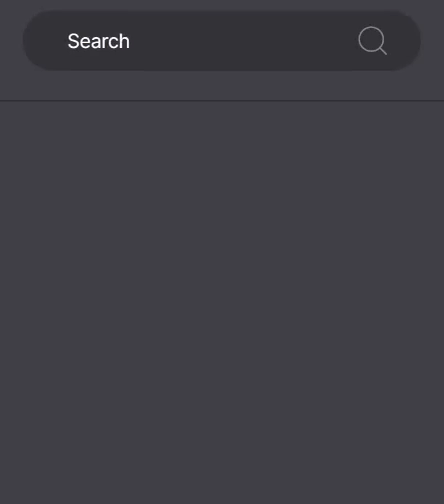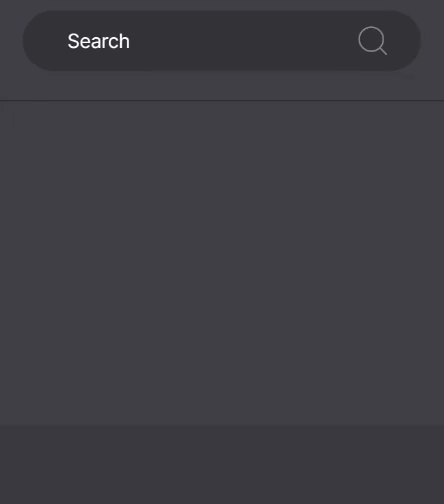
검색 페이지로 이동하기
검색 버튼을 누르거나 검색한 리스트를 누르면 location.href을 통해 검색페이지로 이동 시킨다. 처음에는 localStorage로 검색어를 저장해서 사용했는데 같이 기능을 담당한 동료가 엔터입력으로 검색이 가능하게 바꾸고, url에 표시된 검색어를 사용할 수 있게 코드를 개선시켜 주었다.
form태그를 이용해 get방식으로 엔터 입력 시 URL에 파라미터의 형태로 전송해준뒤, 검색 페이지에서 URLSearchParams를 이용해 검색어를 가져온다.
//검색 페이지
const URLSearch = new URLSearchParams(location.search);
const searchQuery = URLSearch.get("q");이때만 해도 페이지 이동 = localStorage사용에 매몰되어 있어서 별다른 생각을 하지 않고 작업했는데 좋은 의견을 주어 더 편리하게 검색을 이용할 수 있었다!🙇♂️
검색 모달 관련한 기능은 아주 어려운 부분 없이 금방 끝낼 수 있었다.
검색 페이지
검색페이지에서는 검색어에 관련된 리스트를 보여주고, 클릭 시 해당 내용의 페이지로 이동하는 페이지이다.
피그마 디자인
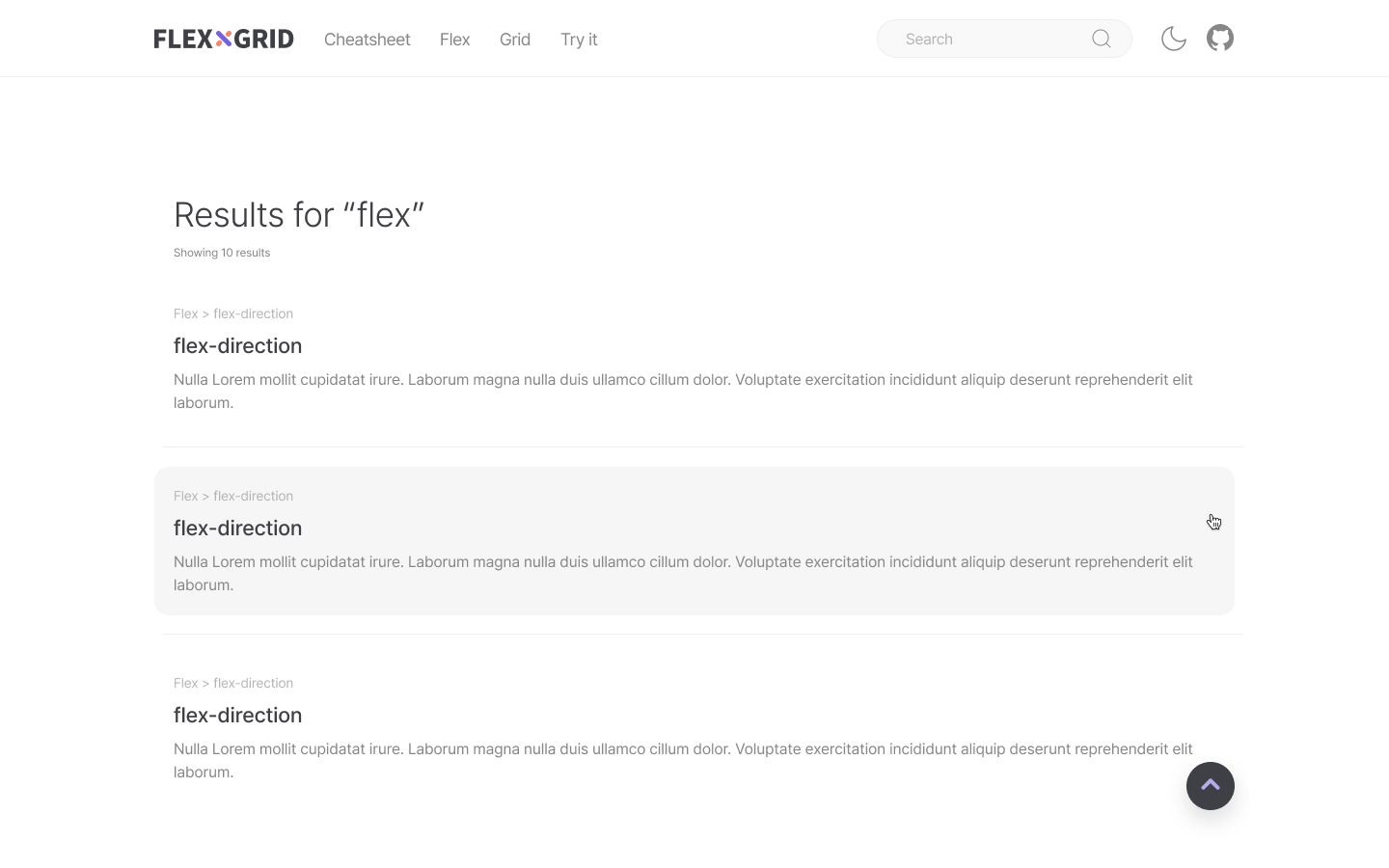
검색리스트 동적 생성
검색어까지 검색페이지에 넘겨주었으니 이제 남은 것은 검색어를 가지고 해당하는 리스트를 생성하는 일만 남았다.
어떻게 해야할지 고민이 많이 됐다. 설명 페이지의 내용을 가져오는 것은 둘째치고, 내용으로 검색을 하게 되면 중복되는 경우가 분명 생길텐데 어떻게 해야할지 감이 잘 잡히지 않았다.
내용페이지의 마크다운을 fetch로 받아와서 string 형태의 데이터를 정제해서 사용할 수는 있었는데 제목은 #으로 잡혀있어서 filter를 통해 데이터를 정제할 수 있었지만 설명부분은 따로 가져오기가 난감했다. 게다가 제목이 아닌 내용에 #이 포함되어 있는 경우에도 filter에 걸려 같이 넘어와 사용하기 힘들었다.
마크다운을 fetch로 받아온 string
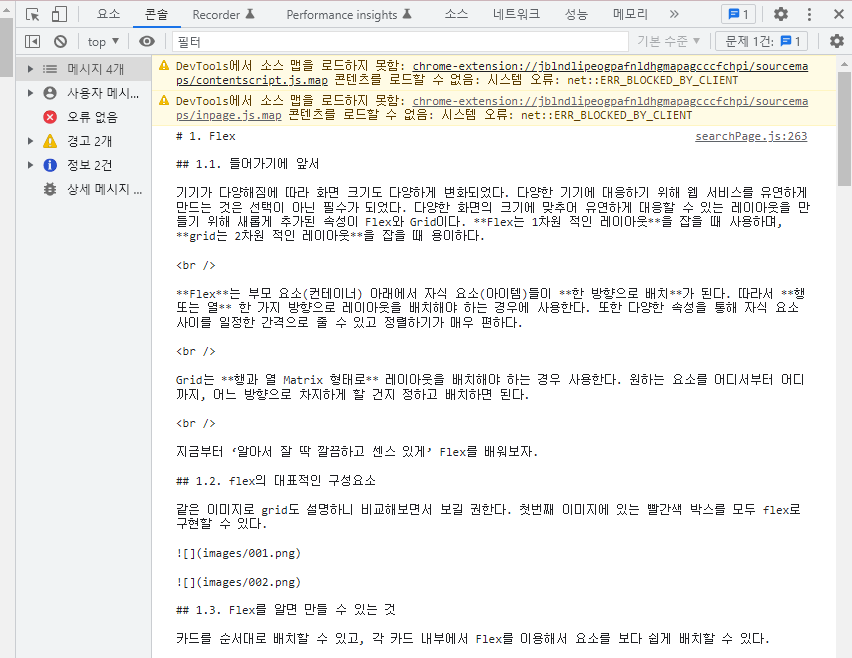
그러던 중 에디터를 맡은 동료가 설명페이지를 마크다운으로 파싱해서 다시 마크업으로 전환하는 기능을 만들었고 제목에는 <h2> ~ <h4>, 문장에는 <p>가 붙은 string 데이터를 얻을 수 있게 되었다.
단계별로 개발해보자!
기간이 충분하지 않으므로 일단 할 수 있는 것부터 개발을 진행하기 시작했다. 내용을 제외하고 제목 기준으로만 리스트를 생성하도록 처음 목표를 설정했다. 최종 목표는 내용기준으로도 리스트를 만드는 것이다.
1단계 : 제목으로만 찾기
빈 배열에 flex와 grid내용을 각각 filter를 통해 제목을 가져오고, map으로 내용을 모두 소문자로 바꾼다. 그렇게 나온 배열 중에 검색어에 포함된 내용을 push해준다.
const contents = []; . //fetch로 마크다운 파싱하는 코드 . . contents.push( flexhtml.filter( (v) => v.includes(`h2`) || v.includes(`h3`) || v.includes(`h4`)).map((v) => v.toLocaleLowerCase()) .filter((v) => v.includes(searchQuery.toLowerCase())),, gridhtml.filter( (v) => v.includes(`h2`) || v.includes(`h3`) || v.includes(`h4`)).map((v) => v.toLocaleLowerCase()) .filter((v) => v.includes(searchQuery.toLowerCase())), );
contents 배열을 forEach로 순회해서 flex와 grid에서 받아온 제목을 리스트 생성 함수에 넣어줬다.
contents.forEach((v, i) => { v.forEach((value) => { . . //리스트를 생성하는 코드 . . });
id값이 제목으로 정해져있기 때문에 받아온 value의 태그를 정규식으로 삭제 후 리스트에서 a 태그 href에 value를 넣어서 해당 위치로 이동하게 해줬다.
value = value.replace(/<\/?[^>]+(>|$)/g, "");
const searchListItemLink = document.createElement("a");
searchListItemLink.setAttribute(
"href",
`${i == 0 ? `/flex/#${value}` : `/grid/#${value}`}`
);
value = value.replace(/[0-9.]/g, "");

발생한 문제
정규식에서 숫자와 .을 제거했는데 제목의 뒤쪽에 있는 숫자들도 삭제되서 해당 부분을 수정했다.
 수정 후
수정 후
2단계 : 제목에서 상위 항목을 포함하기
이제 제목으로 리스트를 생성했으니까 그 제목의 상위 항목을 찾게 개선시켜보기로 한다.
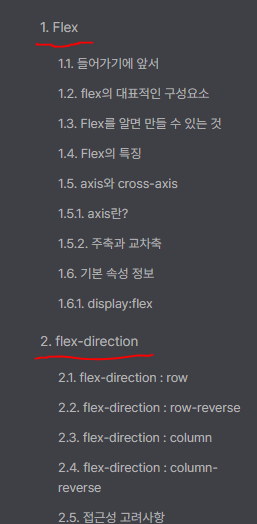
설명 페이지의 구조는 큰 제목h2와 그 아래에 있는 항목 h3, h4으로 이뤄져 있다.
gridhtml.filter((v) => v.includes(`h2`) || v.includes(`h3`) || v.includes(`h4`)).map((v) => v.toLocaleLowerCase())
일단 받아오는 방식을 제목 모두를 가져오게 바꾸고, 아이템을 생성할 때 검색어를 포함하는지 확인하게 변경했다.
그리고 value가 h3나 h4라면 while문으로 h2가 나올때까지 index를 줄여서 상위 제목을 찾는다
. . contents.forEach((v, i) => { v.forEach((value, j) => { if (value.includes(searchQuery.toLowerCase())) { if (value.includes("h3") || value.includes("h4")) { while (!contents[i][j].includes("h2")) { j--; if (j < 0) { break; } } highTag = contents[i][j]; } else if (value.includes("h2")) { highTag = value; } . . . . const searchRoute = document.createElement("span"); searchRoute.setAttribute("class", "route-search"); searchRoute.appendChild( document.createTextNode( i == 0 ? `flex > ${highTag}` : `grid > ${highTag}` ) ); const searchTitle = document.createElement("strong"); searchTitle.setAttribute("class", "tit-search"); searchTitle.appendChild(document.createTextNode(value)); . . . . }
변수에 해당 내용을 넣어서 사용한다. 처음부터 h2였다면 value자체를 상위 제목으로 사용했다.

1단계에서는 하나의 value값으로 현재 제목과 상위 제목을 전부 사용했기 때문에 같은 제목인 경우 내용이 달라도 어디 내용인지 알 수 없었지만 이제 상위 제목으로 어떤 내용에서 온 리스트인지 알게 되었다.
3단계 : 내용으로 찾기
이제 최종 목표인 내용으로도 검색해서 리스트를 생성하는 일만 남았다. filter로 가져올 때 p태그를 포함해서 가져오도록 한다.
gridhtml.filter( (v) => v.includes(`h2`) || v.includes(`h3`) || v.includes(`h4`) || v.includes(`<p>`) )

h2를 찾을때와 마찬가지로 <p>도 찾아준다. 먼저 제목이 나오니까 그에 해당하는 내용은 제목보다 아래 index에 있다. index를 증가시켜서 <p>를 찾아 사용했다.
. . . if (value.includes("h3") || value.includes("h4")) { currentTitle = value; while (!contents[i][j].includes("<p>")) { j++; if (contents[i][j].includes("<p>")) { currentDesc = contents[i][j]; } } . . . .
그런데 이렇게 내용을 가져오면 문제가 있다. 1.1. 들어가기에 앞서의 내용은 p태그 4개로 이뤄진 문장인데 이 경우 첫 번째 문장만 사용하게 된다. 또 p를 기준으로 찾는 경우에도 해당 내용의 제목을 찾을 때 중복이나 올바른 동작을 하지 않을 가능성이 크다.
그래서 아이템을 생성하기 전에, 배열 데이터를 다시 정제했다. p태그가 나오게 되면 그 index를 저장하고 그 p태그를 빈 배열에 더해준다. 그리고 splice로 그 태그를 삭제한다. 그 뒤에 다시 확인해서 p태그가 아닐때 까지 while문을 사용했다.
while문을 빠져나오게 되면 처음에 저장한 index에 splice로 추가해준다.
contents.forEach((check, i) => { for (let j = 0; j < contents[i].length - 1; j++) { if (check[j].includes("<p>")) { firstDesc = j; while (contents[i][j].includes("<p>")) { desc += contents[i][j]; contents[i].splice(j, 1); if (j < contents[i].length - 1) { } else { break; } if (contents[i][j].includes("<p>")) { continue; } else { break; } } contents[i].splice(firstDesc, 0, desc); desc = []; } } });
이를 통해 제목 밑에 있는 설명 내용이 하나의 p태그에 담기게 된다.
 이렇게 되있던 p 태그들이 2번에 모두 합쳐짐
이렇게 되있던 p 태그들이 2번에 모두 합쳐짐

h2를 찾은 경우
상위 제목과 현재 제목을 value로 넣어준다. while문으로p태그를 찾아서 있는 경우에 변수에 넣어서 사용하고,h3,h4가 나오는 경우에는(큰 제목 밑에 내용이 없는 경우) 빈칸으로 두었다.. . . else if (value.includes("h2")) { highTag = value; currentTitle = value; while (!contents[i][j].includes("<p>")) { j++; if (contents[i][j].includes("<p>")) { currentDesc = contents[i][j]; } else if ( contents[i][j].includes("h3") || contents[i][j].includes("h4") ) { currentDesc = ""; break; } } }
h3,h4를 찾은 경우
현재 제목을 value로 넣어주고, 역시 while문으로p태그를 찾아서 변수에 넣어주고, 그 뒤에h2를 찾아 상위 제목도 찾아 사용한다.if (value.includes("h3") || value.includes("h4")) { currentTitle = value; while (!contents[i][j].includes("<p>")) { j++; if (contents[i][j].includes("<p>")) { currentDesc = contents[i][j]; } } while (!contents[i][j].includes("h2")) { j--; if (contents[i][j].includes("h2")) { highTag = contents[i][j]; break; } if (j < 0) { break; } } }
p를 찾은 경우
내용 변수에 value를 넣어주고, while문으로h2 ~ h4를 찾아서 현재 제목을 설정하고,h2를 찾아서 상위 제목에 넣어준다.. . . else if (value.includes("<p>")) { currentDesc = value; while (!contents[i][j].includes("h2")) { j--; if ( contents[i][j].includes("h2") || contents[i][j].includes("h3") || contents[i][j].includes("h4") ) { currentTitle = contents[i][j]; if (contents[i][j].includes("h2")) { highTag = contents[i][j]; break; } while (!contents[i][j].includes("h2")) { j--; if (contents[i][j].includes("h2")) { highTag = contents[i][j]; break; } } break; } if (j < 0) { break; } } } . . .
발생한 문제들
- 검색어가 제목과 내용 둘다 포함된 경우 중복되서 리스트가 생성되는 문제가 있었다.
어차피 링크 이동은 제목 기준으로만 이동하기 때문에 prev변수를 만들어서 이전에 이미 이 제목으로 된 리스트가 있지 않은 경우에만 생성해서 중복을 방지했다.
. . . if (prev != currentTitle) { //리스트 생성 부분 prev = currentTitle; const searchListItem = document.createElement("li"); . . .
- 정규식에 문제가 있어서 제목이 또 이상하게 걸러지는 문제가 있었다. 공백과 .을 기준으로 다시 정규식을 변경했다.
제목 규칙이
1.1. 제목이런식으로 숫자뒤에 마침표가 찍히고 공백이 한칸 있다. 그걸 기준으로 정규식을 변경했다.currentTitle = currentTitle.replace(/[^s]+[.]/gi, "");
- 내용을 모두 소문자로 변경해서 검색했었는데, 제목에 대문자가 포함된 경우가 있었다. 이 경우 id값이 달라서 링크 이동이 제대로 되지 않았기 때문에 같이 공부하는 동료의 의견을 받아 대소문자 상관없이 검색되도록 정규식을 사용했다.
if (value.includes(value.match(new RegExp(searchQuery, "i"))))정규식 i플래그를 사용하면 대소문자를 구분하지 않고 비교해준다.
tolowercase로 소문자로 바꿨던 내용을 없애고 정규식을 통해 확인해 주니 굳이 변환할 필요도 없고 대소문자 관련한 다양한 문제가 해결되었다.


결과는..
내용으로도 검색되는게 이렇게 신날 줄이야!
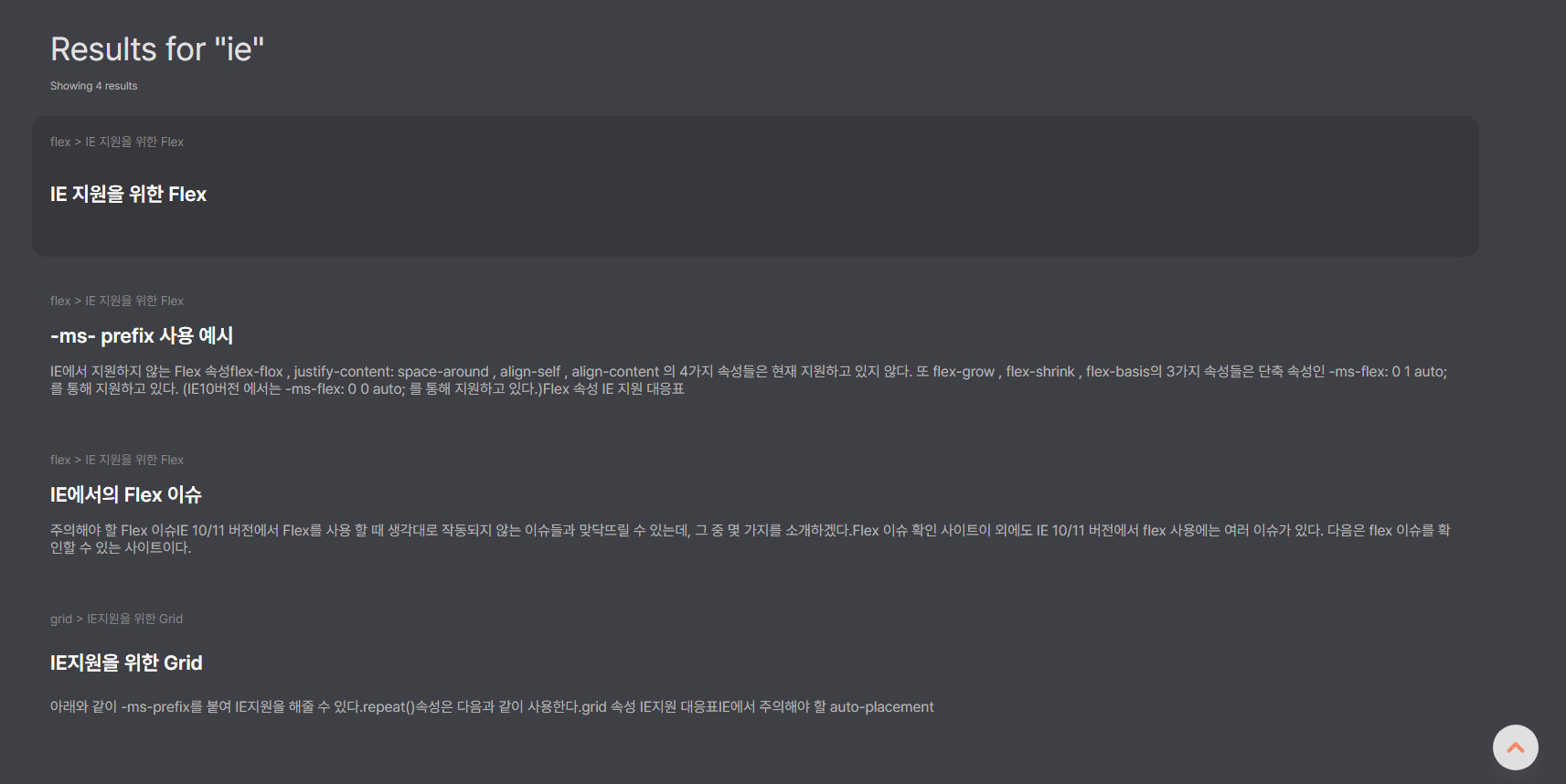
그 외 작업
다크모드 유지하기
다크모드로 css 스타일이 바뀐 후 설정을 유지하기 위해 localStorage를 사용했다. 다크모드를 누를 때 마다 boolean 변수를 사용하여 true false로 localStorage에 저장해서 사용했다.
const handleDarkMode = () => {
.
.
.
isDark = !isDark;
localStorage.setItem("darkmode", isDark);
}getItem으로 true인지 false인지 확인 해서 다크모드를 실행할지 아닐지를 정해줬다. string으로 저장되서 그냥 문자열로 확인해주었다.
if (currentMode == "true") {
isDark=true;
//다크모드 실행
} esle {
isDark=false;
//다크모드 취소
}사이드 메뉴 자동 스크롤
설명 페이지의 사이드 메뉴의 스크롤이 페이지 스크롤에 반응하지 않는 점이 아쉬워서, 담당자분께 허락을 받고 사이드 메뉴도 스크롤 되도록 변경했다.
수정 전
수정 후
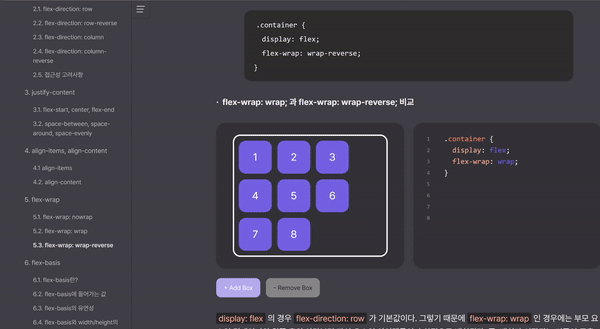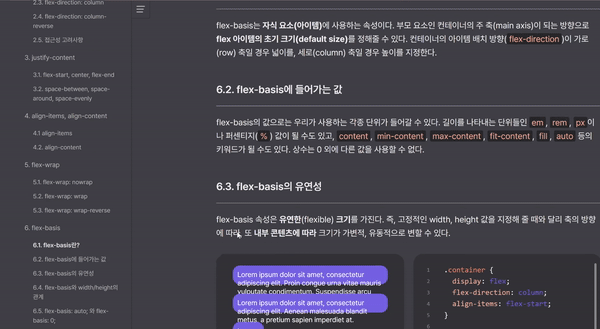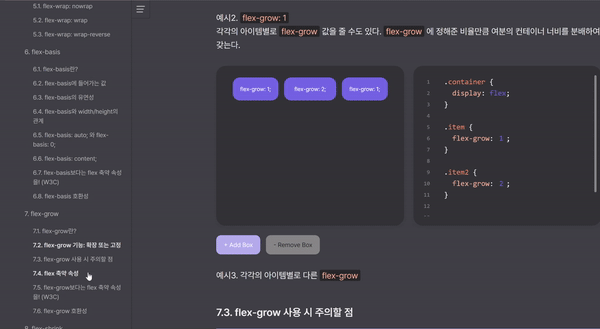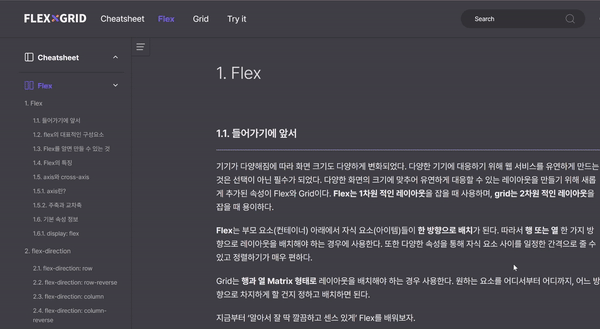
이미 사이드메뉴에 스크롤스파이가 적용되어 있어서 bold처리된 메뉴의 offsetTop을 이용해 scrollTo로 사이드 메뉴의 스크롤을 동작시켰다. 자연스러운 위치 이동을 위해서 사이드 메뉴의 height값의 절반만큼 빼줬다.
.
.
//스크롤스파이 적용...
drawerMenu.scrollTo(
0, drawerTit[i].offsetTop - drawerMenu.clientHeight / 2);아쉬운 점
기능 구현에 중점을 둬서 깔끔한 느낌의 코드가 아니라서 아쉬웠다. 스파게티 그 자체인 느낌이었고 알고리즘에 익숙하다면 더 깔끔하게 만들 수 있지 않을까? 여러모로 아쉽다.
개선할 부분
내용으로 검색된 아이템에 검색한 텍스트가 표시되면 좋을 것 같다.
느낀점
작은 목표부터 차근차근 밟아 나가며 이번 기능을 완성했는데 단계별로 완성할 때마다 성취감이 있었다. 아쉬운 부분이많지만 어떻게든 구현했다는게 중요하다고 생각해서, 일단은 작은 만족을 느꼈다.
