
정규표현식이란..
정규 표현식(正規表現式, 영어: regular expression, 간단히 regexp[1] 또는 regex, rational expression)[2][3] 또는 정규식(正規式)은 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다. 정규 표현식은 많은 텍스트 편집기와 프로그래밍 언어에서 문자열의 검색과 치환을 위해 지원하고 있다.
from 위키피디아
그렇습니다. 문자열의 검색과 치환이 필요할 때 사용하는 것이 정규표현식 입니다.
역시 개발자들은 사람들의 불편함을 가만두지 않습니다.
들어가기 앞서, raw string
raw string을 사용하면 escape문이 동작되지 않고 작성된대로 출력됩니다. 사용 방법은 출력할 문자열앞에 r을 붙여줍니다.
a= 'ab\n'
b = r'ab\n'
print(a)
print(b)
ab
ab\n한 줄 띄우라는 \n 이지만 raw string 앞에서는 동작하지 않습니다.
정규표현식을 사용한 코드를 먼저 보겠습니다.
paragraph = "wow, it's useful"
print(re.search(r'it',paragraph))
print(re.search(r'mincheol',paragraph))
<re.Match object; span=(5, 7), match='it'>
None첫번째 프린트 함수는 paragraph 문자열에서 'it' 이 들어간 첫 위치를 찾으라는 코드 입니다.
두번째 프린트 함수는 문자열에서 'mincheol' 은 찾지 못했으니 None 을 반환하는게 당연합니다.
그럼 다음 코드도 보겠습니다.
paragraph = "wow, it's useful1"
print(re.search(r'u.e',paragraph))
<re.Match object; span=(10, 13), match='use'>'u.e' 라는 문자열을 찾으라는 코드일까요 ? 아닙니다. 여기서 '.' 은 모든 문자를 가르킵니다. 그렇기에 여기선 'use'를 찾았고 그 위치를 알려줬습니다.
이런 '.' 등을 패턴이라고 합니다.
그러면 자주 사용되는 패턴들에 대해서 알아보겠습니다.
정규표현식 패턴 표현들
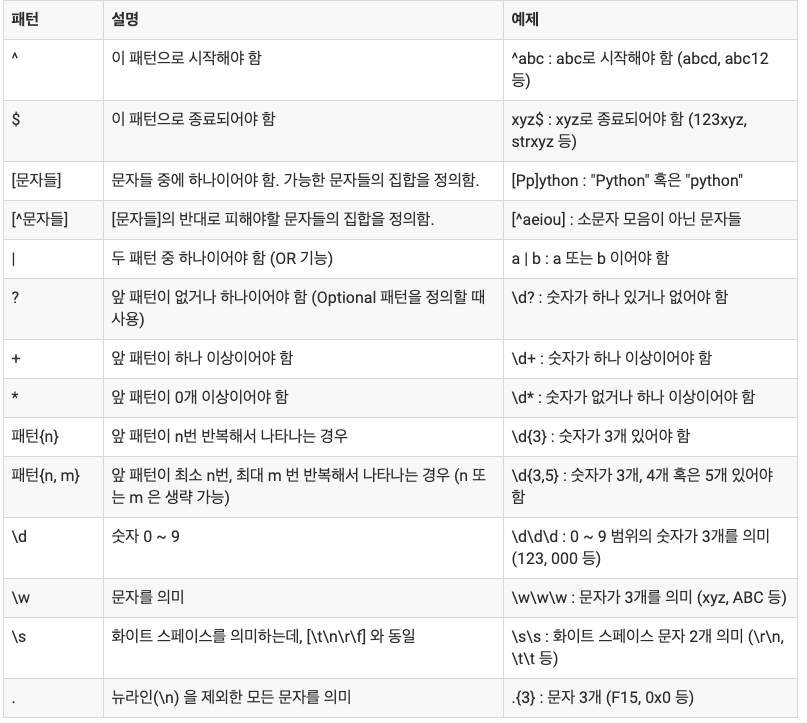
표 출처 - http://pythonstudy.xyz/python/article/401-정규-표현식-Regex (예제로 배우는 파이썬 프로그래밍)
또한 [0-9], [a-zA-Z] 은 무척 자주 사용하는 정규 표현식입니다.
특히 [] 안에서 ^는 반대를 뜻한다는것을 의미합니다.
[^0-9] 는 숫자를 제외한다는 뜻이고
[^abc] 는 a,b,c 를 제외한 문자를 뜻합니다.
이제파이썬에서 정규표현식을 써보겠습니다.
먼저, 파이썬에서 정규표현식을 쓰기 위해서는 내장 모듈 re 를 import 해줍니다.
import rere 모듈은 다양한 메서드가 존재합니다.
search
문자열 전체를 검색해, 첫번째로 패턴을 찾으면 match 객체를 반환합니다.
당연히 패턴을 찾지 못하면 None을 반환합니다.
paragraph = "wow, it's useful"
print(re.search(r'it',paragraph))
print(re.search(r't', paragraph))
print(re.search(r'mincheol',paragraph))
<re.Match object; span=(5, 7), match='it'>
<re.Match object; span=(6, 7), match='t'>
Noneparagraph = "wow, it's useful1"
print(re.search(r'u.e',paragraph))
<re.Match object; span=(10, 13), match='use'>
findall
search가 최초로 매칭되는 패턴만 반환한다면,findall은 매칭되는 전체의 패턴을 반환합니다.
매칭되는 모든 패턴을 리스트 형태로 반환합니다.
paragraph = "it's .. wow, it's useful1"
print(re.findall(r'it', paragraph))
['it', 'it']sub
주어진 문자열에서 일치하는 모든 패턴을 치환합니다. 그 결과를 문자열로 다시 반환합니다.
count가 0인 경우는 전체에서 일치되는 패턴을 모두 찾고, 1이상이면 해당 숫자만큼 치환 됩니다. count =0 인 경우엔 생략해도 됩니다.
paragraph = "it's .. wow, it's useful1"
print(re.sub(r'it','IT',paragraph))
print(re.sub(r'it','IT',paragraph,count=1))
IT's .. wow, IT's useful1
IT's .. wow, it's useful1문자열에 여러 기호들이 섞여 있습니다. re.sub 을 사용해 문자가 아니면 값을 지워보겠습니다.
paragraph = "~][m{{i@!#!@nc#h#@$@eo^^l**"
print(re.sub(r'[^\w]','', paragraph))
mincheolmatch
match()는 제가 생각하기엔 독특합니다. 왜냐하면 찾으려하는 패턴이 문자열의 첫 부분에 일치하는지만 확인해주기 때문입니다.
paragraph = "it's .. wow, it's useful1"
print(re.match(r'it', paragraph))
print(re.match(r'wow', paragraph))
<re.Match object; span=(0, 2), match='it'>
None정규표현식에 대해 간단히 알아봤습니다.
여담이지만, 정규표현식을 많은 개발자들이 '규식이' 라고 부른다고 하네요.
저 또한 이제 익숙한 느낌이 듭니다.
좀 더 편해지만 저도 '규식이' ..
음 .. '규식이 형' 이라고 불러보겠습니다.
개발자들이 꺼려하는 까칠한 규식이 형 - 컬리 기술 블로그

