이 글은 부스트캠프 AI Tech 3기 강의를 듣고 정리한 글입니다.
PyTorch Basics
Numpy를 기반으로 만들어졌기 때문에 Numpy와 유사한 면이 많다.
다른점은 자동미분(AutoGrade)의 표현이 다르다.
이것을 포함한 다양한 수식에 관해서 알아보자
PyTorch Operations
numpy + AutoGrad
- numpy와 흡사한 것이 많기 때문에 numpy만 잘 쓸수 있어도 어느정도 활용이 가능하다
- 사실 파이썬에서 벡터를 다루는 프레임워크(TF, scipy 등)들도 numpy기반이다
Tensor
- 다차원 Arrays를 표현하는 PyTorch 클래스
- 사실상 numpy의 ndarray와 동일
- TF의 Tensor와도 동일
Numpy to Tensor
- Numpy와 같은 ndim과 shape을 가진다.
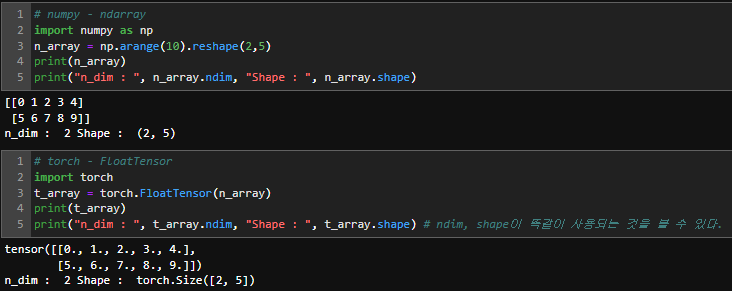
# numpy - ndarray
import numpy as np
n_array = np.arange(10).reshape(2,5)
print(n_array)
print("n_dim : ", n_array.ndim, "Shape : ", n_array.shape)
>>> [[0 1 2 3 4]
[5 6 7 8 9]]
n_dim : 2 Shape : (2, 5)```# torch - FloatTensor
import torch
t_array = torch.FloatTensor(n_array)
print(t_array)
print("n_dim : ", t_array.ndim, "Shape : ", t_array.shape) # ndim, shape이 똑같이 사용되는 것을 볼 수 있다.
>>> tensor([[0., 1., 2., 3., 4.],
[5., 6., 7., 8., 9.]])
n_dim : 2 Shape : torch.Size([2, 5])Array to Tensor
- Tensor 생성은 list나 ndarray를 사용가능
- 하지만 이런 방법으로 쓸일은 거의 없을 것이다.
- 모델안에 있는 여러 객체(weight)를 사용하기 때문에
# data to Tensor
data = [[3, 5],[10, 5]]
x_data = torch.tensor(data)
x_data
>>> tensor([[ 3, 5],
[10, 5]])```
# ndarray to Tensor
nd_array_ex = np.array(data)
tensor_array = torch.from_numpy(nd_array_ex)
tensor_array
>>> tensor([[ 3, 5],
[10, 5]], dtype=torch.int32)Tensor data Type
- 기본적으로 tensor가 가지는 datatype은 numpy와 동일
- 따라서 numpy에서 사용할 수 있는 건 tensor에도 사용가능하다.
- 차이점은 GPU의 사용가능하다는 점이 다르다.
numpy like operations
# Tensor 생성
data = [[3, 5, 20],[10, 5, 50], [1, 5, 10]]
x_data = torch.Tensor(data)
# slicing
print(x_data[1:]) # 1번째 행부터
print(x_data[:2, 1:]) # 2번째 행까지 & 1번째 열부터
print(x_data.flatten()) # 1차원으로 평탄화
>>> tensor([[10., 5., 50.],
[ 1., 5., 10.]])
tensor([[ 5., 20.],
[ 5., 50.]])
tensor([ 3., 5., 20., 10., 5., 50., 1., 5., 10.])
# ones_like
torch.ones_like(x_data)
>>> tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])# numpy형태로 변환
x_data.numpy()
>>> array([[ 3., 5., 20.],
[10., 5., 50.],
[ 1., 5., 10.]], dtype=float32)# pytorch의 tensor는 GPU에 올려서 사용가능
print(x_data.device) # x_data가 어디에 위치해 있는지 출력해준다.
# x_data를 GPU에 올려보고 올라갔는지 확인
if torch.cuda.is_available():
x_data_cuda = x_data.to('cuda')
print(x_data_cuda.device)
>>> cpu
device(type = 'cuda', index = 0)```Tensor handling
- view : reshape 대신 view를 쓴다.
- squeeze : 차원의 개수가 1인 차원을 삭제(압축)
- unsqueeze : 차원의 개수가 1인 차원을 추가
view
# 랜덤 2x3x2 Tensor 생성
tensor_ex = torch.rand(size=(2, 3, 2))
tensor_ex
>>> tensor([[[0.8276, 0.6040],
[0.1700, 0.4908],
[0.9781, 0.8323]],
[[0.6678, 0.3572],
[0.5641, 0.9679],
[0.8226, 0.0076]]])# view == reshape (기능적으로)
print(tensor_ex.view([-1, 6]))
print(tensor_ex.reshape([-1, 6]))
>>> tensor([[0.8276, 0.6040, 0.1700, 0.4908, 0.9781, 0.8323],
[0.6678, 0.3572, 0.5641, 0.9679, 0.8226, 0.0076]])
tensor([[0.8276, 0.6040, 0.1700, 0.4908, 0.9781, 0.8323],
[0.6678, 0.3572, 0.5641, 0.9679, 0.8226, 0.0076]])# view를 쓰면 주소값을 복사하기 때문에 a값이 바뀐 것이 b에도 영향을 준다
a = torch.zeros(3, 2) # 3x2 영행렬 생성
b = a.view(2, 3) # 2x3으로 reshape
a.fill_(1) # 1로 다 채우자
print('a',a)
print('b',b)
>>> a tensor([[1., 1.],
[1., 1.],
[1., 1.]])
b tensor([[1., 1., 1.],
[1., 1., 1.]])# reshape을 쓰면 copy를 해서 쓰기 때문에 바뀐 a값이 b에 영향을 주지 않는다.
a = torch.zeros(3, 2) # 3x2 영행렬 생성
b = a.t().reshape(6) #
a.fill_(1)
print('a',a)
print('b',b)
>>> a tensor([[1., 1.],
[1., 1.],
[1., 1.]])
b tensor([0., 0., 0., 0., 0., 0.])squeeze unsqueeze
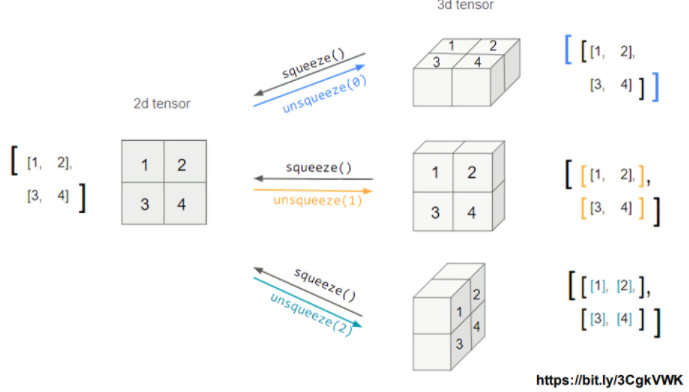
# squeeze() : 차원을 하나 줄여준다(압축) / 값이 존재하는 경우 압축x
tensor_ex = torch.rand(size=(2, 1, 2))
print(tensor_ex)
tensor_ex.squeeze()
>>> tensor([[[0.4955, 0.3750]],
[[0.9969, 0.5505]]])
tensor([[0.4955, 0.3750],
[0.9969, 0.5505]])# unsqueeze(n) : n번째 차원을 하나 들려준다.
tensor_ex = torch.rand(size=(2, 2))
print(tensor_ex)
print(tensor_ex.shape, end = '\n\n')
print(tensor_ex.unsqueeze(0))
print(tensor_ex.unsqueeze(0).shape, end = '\n\n') # 0번쨰 차원
print(tensor_ex.unsqueeze(1))
print(tensor_ex.unsqueeze(1).shape, end = '\n\n') # 1번쨰 차원
print(tensor_ex.unsqueeze(2))
print(tensor_ex.unsqueeze(2).shape) # 2번째 차원
>>> tensor([[0.0103, 0.5597],
[0.7411, 0.9000]])
torch.Size([2, 2])
tensor([[[0.0103, 0.5597],
[0.7411, 0.9000]]])
torch.Size([1, 2, 2])
tensor([[[0.0103, 0.5597]],
[[0.7411, 0.9000]]])
torch.Size([2, 1, 2])
tensor([[[0.0103],
[0.5597]],
[[0.7411],
[0.9000]]])
torch.Size([2, 2, 1])other operations
- 그외 대부분의 연산은 numpy와 동일
- numpy와 다른점
- numpy에서 행렬곱 : dot(내적)가능 (보통 '@' 연산자 사용)
- torch에서 행렬곱 : mm 연산자 사용(matmul) / dot은 내적용도로
n1 = np.arange(10).reshape(2,5)
n2 = np.arange(10).reshape(5,2)
t1 = torch.FloatTensor(n1)
t2 = torch.FloatTensor(n2)
print(t1)
print(t2)
>>> tensor([[0., 1., 2., 3., 4.],
[5., 6., 7., 8., 9.]])
tensor([[0., 1.],
[2., 3.],
[4., 5.],
[6., 7.],
[8., 9.]])# 텐서간 덧셈
t1 + t1
>>> tensor([[ 0., 2., 4., 6., 8.],
[10., 12., 14., 16., 18.]])# 텐서 + scalar
t1 + 10
>>> tensor([[10., 11., 12., 13., 14.],
[15., 16., 17., 18., 19.]])# shape이 맞지 않으면 +연산 x
t1 + t2
>>> RuntimeError: The size of tensor a (5) must match the size of tensor b (2) at non-singleton dimension 1# 벡터간 내적은 dot
t1 = torch.FloatTensor([1,2,3])
t2 = torch.FloatTensor([4,5,6])
t1.dot(t2)
>>> tensor(32.)# 행렬 곱셈 연산은 mm 사용 (=matmul)
# 내적을 구할 땐 dot
n1 = np.arange(10).reshape(2,5)
t1 = torch.FloatTensor(n1)
n2 = np.arange(10).reshape(5,2)
t2 = torch.FloatTensor(n2)
print(t1.mm(t2))
print(t1.matmul(t2))
>>> tensor([[ 60., 70.],
[160., 195.]])
tensor([[ 60., 70.],
[160., 195.]])# mm은 broadcasting 지원 x -> 명확하게 사이즈 맞춰줘야함
a = torch.rand(5,2, 3)
b = torch.rand(5)
a.mm(b)
>>> IndexError: Dimension out of range (expected to be in range of [-1, 0], but got 1)# matmul은 broadcasting 지원
a = torch.rand(5,2, 3) # (배치, 2x3)
b = torch.rand(3)
a.matmul(b)
"""
다음 연산을 다한 것과 같다.
a[0].mm(torch.unsqueeze(b,1))
a[1].mm(torch.unsqueeze(b,1))
a[2].mm(torch.unsqueeze(b,1))
a[3].mm(torch.unsqueeze(b,1))
a[4].mm(torch.unsqueeze(b,1))
"""
>>> tensor([[0.9021, 0.9448],
[0.4124, 1.0953],
[0.2896, 1.1156],
[0.6550, 0.8200],
[0.2880, 0.5235]])# mm 연산 후 squeeze()해준 것과 안해준 것의 차이
print(a[0].mm(torch.unsqueeze(b,1)).shape) # 2x1 행렬이 된다.
print(a[0].mm(torch.unsqueeze(b,1)))
print(a[0].mm(torch.unsqueeze(b,1)).squeeze().shape) # 벡터로 다시 변환해줌(사이즈 유지를 위해)
print(a[0].mm(torch.unsqueeze(b,1)).squeeze())
>>> torch.Size([2, 1])
tensor([[0.9021],
[0.9448]])
torch.Size([2])
tensor([0.9021, 0.9448])Tensor operations for ML/DL formula
- nn.functional 모듈을 통해 다양한 수식 변환을 지원
import torch
import torch.nn.functional as F
tensor = torch.FloatTensor([0.5, 0.7, 0.1])
h_tensor = F.softmax(tensor, dim=0) # softmax
h_tensor
>>> tensor([0.3458, 0.4224, 0.2318])y = torch.randint(5, (10,5))
print(y)
y_label = y.argmax(dim=1) # argmax 값
y_label
>>> tensor([[3, 4, 1, 4, 0],
[1, 2, 1, 3, 3],
[3, 1, 1, 4, 0],
[4, 1, 4, 2, 3],
[4, 3, 4, 4, 1],
[1, 1, 3, 0, 4],
[2, 2, 4, 2, 3],
[0, 3, 0, 4, 1],
[1, 2, 0, 3, 2],
[2, 1, 1, 2, 0]])
tensor([3, 4, 3, 2, 3, 4, 2, 3, 3, 3])# one - hot
torch.nn.functional.one_hot(y_label)
>>> tensor([[0, 0, 0, 0, 1],
[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 0, 1],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1],
[0, 0, 0, 0, 1],
[1, 0, 0, 0, 0]])# cartesian_prod == itertools.product
import itertools
a = [1, 2, 3]
b = [4, 5]
print(list(itertools.product(a, b)))
tensor_a = torch.tensor(a)
tensor_b = torch.tensor(b)
torch.cartesian_prod(tensor_a, tensor_b)
>>> [(1, 4), (1, 5), (2, 4), (2, 5), (3, 4), (3, 5)]
tensor([[1, 4],
[1, 5],
[2, 4],
[2, 5],
[3, 4],
[3, 5]])AutoGrad
- Pytorch의 핵심은 자동 미분의 지원 -> backward 함수 이용
이 수식을 미분 해보자
w = torch.tensor(2.0, requires_grad=True) # 미분 대상을 requires_grade = True로 설정
y = w**2
z = 10*y + 25
external_grad = torch.tensor(1.)
z.backward(gradient=external_grad)
w.grad
>>> tensor(40.)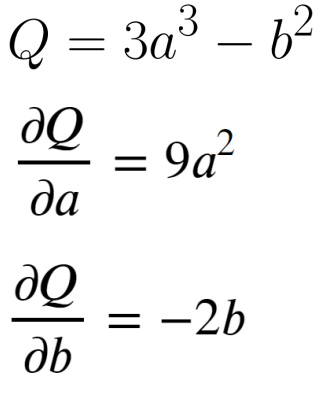
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1.,0.]) # shape 맞추는 용도, 편미분 결과값 제어
Q.backward(gradient=external_grad)
print(a.grad)
print(b.grad)
>>> tensor([36., 0.])
tensor([-12., -0.])
옹오옹오오오옹ㅇㅇ