
검색어 자동완성
프로젝트 요구사항에서 주식 검색에 대한 자동완성 기능을 만들어야 했다.
프로젝트에서 Redis를 사용하기도 했고, 자동완성 기능 구현시 Redis의 Zset을 많이 이용한다 해서 redis 이용해 구현 해봤다.
먼저 다음과 같은 고민을 했다.
-
Redis Zset은 score가 같을 때는 사전에 기반하여 정렬됨. (동일하게 설정)
-
zset의 ZRANGEBYLEX 메소드를 이용한다. (
Redis의ZRANGEBYLEX는 정확한 문자열 순서(완성형 글자 기준)로 검색을 수행)=> '삼ㅅ' 같은 문자에 대해서는 검색하지 않는다는 말이다.
-
그러면 요청이 '삼ㅅ'처럼 들어왔을때는 ZRANGEBYLEX의 결과가 없으니 자동완성 응답이 없는건가? ⇒ 이전의 결과를 캐싱해놓고 응답이 없을 땐 그것을 사용하면 되지 않을까?
그럼 캐싱 기준을 어떤식으로 정해야하는거지? (까지가 내생각이었다)
궁금해서 네이버 자동완성 기능을 조사해 본 결과..
일단 네이버는 브라우저 캐시에 요청을 보내고 받은 응답들을 저장해놓고 다시 그것이 들어오면 요청을 보내지않고 캐시에서 꺼내 사용하는것 같다.
캐싱을 브라우저 자체에 일정시간 해놓고 그것을 사용하며, 서버에 요청 자체를 보내지 않아서 서버와 DB모두에게 부담을 주지 않는것이다.

실제로 브라우저 자체에 ㅅ, 사, 삼, 삼ㅅ, 삼서, 삼성 모든 결과를 브라우저에 캐싱해놓고 사용하고 있었다.
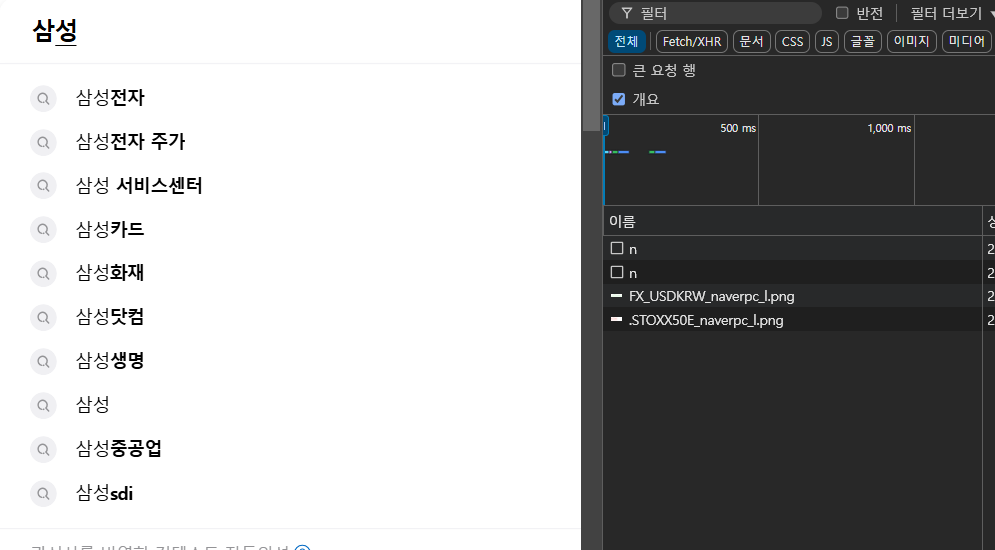
'삼성'을 검색했을때 응답이 오지않았고, 캐싱된 결과를 그대로 사용한다는 것을 알게되었다.
하나더,,
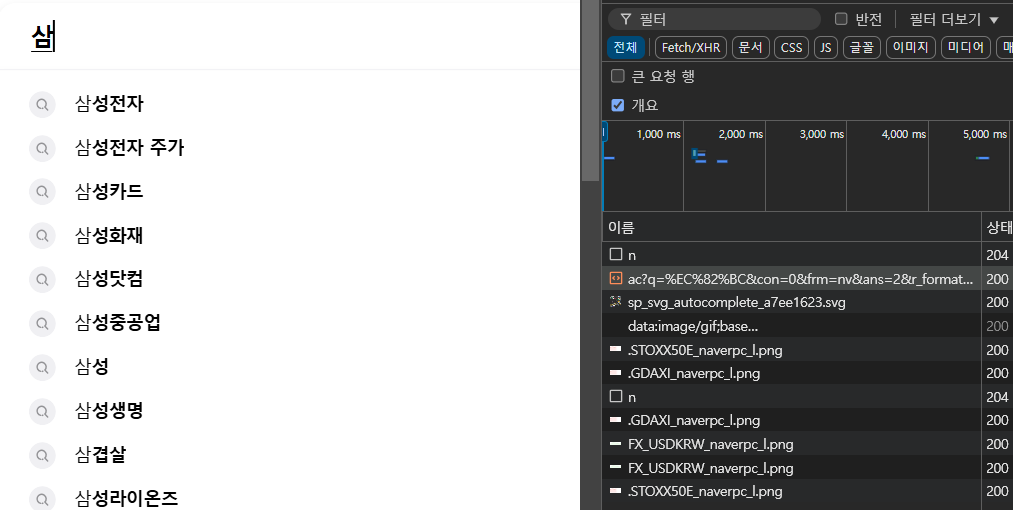
또, 검색어를 빠르게 입력하면, ㅅ, ㅏ, ㅁ 3개의 요청을 보내지 않고, “삼”으로 요청을 하나만 보내는 것을 알게됨. ⇒ 검색어 입력시간을 설정해서 프론트엔드 측에서 최적화한다는 것을 알게되었다.
이런 결과를 보고 난 뒤,
어짜피 ZRANGEBYLEX 이용하고 결과가 없을때는 이전 결과를 캐싱한 것을 보여준다고 하면,, 프론트에서만 처리하면 되는거 아닌가? 라는 의문점이 들며 구현을 시작했다.
실제로 강사님께 여쭤보니 자동완성은 프론트엔드에서 처리하는 것이 일반적이라고 말씀하셨다 ! (기특)
개발과정
redis zset 자료형으로 모든 주식 종목들의 score를 0으로 저장한 후,
ZRANGEBYLEX 메소드를 이용하려 했으나...


..왜 안되나 했네 (한 10번 수정함)deprecated된 메소드이고 ZRANGE로 사용해야 한다고 한다.
public List<String> searchStocks(String stockName) {
String STOCK_ZSET_KEY = "stocks:autoComplete";
if (stockName == null || stockName.isEmpty()) {
return Collections.emptyList();
}
ZSetOperations<String, String> zSetOperations = template.opsForZSet();
Set<String> allStocks = zSetOperations.rangeByScore(STOCK_ZSET_KEY, Double.NEGATIVE_INFINITY, Double.POSITIVE_INFINITY);
if (allStocks == null || allStocks.isEmpty()) {
return Collections.emptyList();
}
return allStocks.stream()
.filter(stock -> stock.startsWith(stockName))
.sorted()
.limit(20)
.collect(Collectors.toList());
}
난 rangeByScore로 배열에 불러온 다음, filter를 이용해 입력된 값을 시작 하는 값을 매핑하여 출력하는 것으로 구현했다.
물론 이때도 '삼ㅅ'와 같은 완성되지 않은 문자에 대해서 검색되지는 않았지만, 우리 서비스에서 그리 메이저 한 기능이 아니었을 뿐더러 시간도 없었기에 타협하기로 했다! ㅜ
** 프론트에 최적화하는 소스코드는 시간이 되면 리팩토링 해보겠음! **
근데 갑자기 생각이든게 네이버 같은 대규모 검색엔진에서는 ElasticSearch 같은거 쓰지않을까? ..
