슈퍼-서브타입 (확장된 ER모델. Extended E-R)
슈퍼-서브타입 도출
슈퍼, 서브타입 엔터티 식별자의 도메인은 반드시 같아야한다.
슈퍼-서브타입 도출되는 과정 1
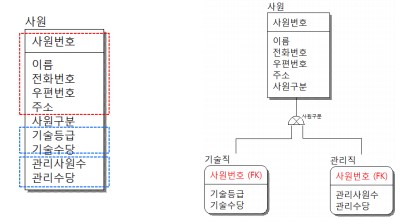
공통된 데이터만 사원 엔터티에 남기고(슈퍼타입)
기술직, 관리직만의 specialize된 속성들은 별도의 엔터티로 구성(서브타입)
슈퍼-서브타입 도출되는 과정 2
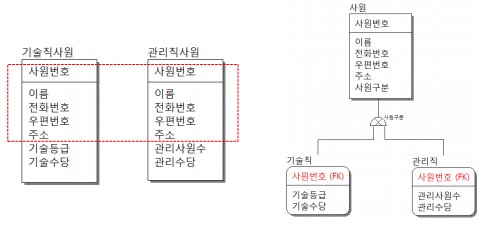
각 엔터티의 공통된 데이터는 별도의 사원 엔터티로 구성하고(슈퍼타입)
기술직, 관리직만의 specialize된 속성들만 각 엔터티에 남김(서브타입)
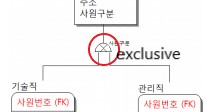
두 서브타입간에 교집합이 없을 경우 배타적exclusive 서브 카테고리 라고 하며, 위 그림과 같이 표기한다.
(기술직일 경우 관리직이 아니다 / 관리직일 경우 기술직이 아니다)
이 때 서브타입 표기 옆에 '사원구분'과 같은 구분자 속성을 지정해줘야 하며,
이러한 속성을 설계 속성이라고 한다.
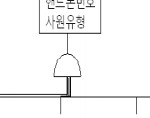
두 서브타입 간에 교집합이 있을 경우 포괄적inclusive 서브 카테고리라고 하며, 위 그림과 같이 표기한다.
(사원은 기술직 이면서 관리직일 수 있다)
슈퍼타입/서브타입 관계의 변환
하나의 테이블로 통합(Rollup)
: 슈퍼타입에 서브타입의 모든 컬럼을 통합하여 하나의 테이블로 생성.
- 전체 테이블을 같이 Access처리하는 것이 대부분인 경우
- 서브타입의 속성 개수가 적은 경우(1~2개)
- 서브타입과 관계를 맺은 엔티티가 별로 없는 경우
- 업무적으로 변화가능성이 작아 추가적인 서브타입이나 속성 추가의 가능성이 적은 경우
- 장점
: 조인할 일이 없으므로 SQL문장 구성이 단순, 수행속도가 빨라지는 경우가 많다.
: 서브타입을 구분하지 않고 데이터를 조회할 경우 처리가 용이하다. - 단점
: 특정 서브타입의 NOT NULL 제한 불가(NULL값이 많아질 수 있다)
여러 개의 테이블로 분리(Rolldown)
: 슈퍼타입을 각각의 서브타입에 추가하여 서브타입별로 테이블 생성.
- 데이터 처리 서브타입을 구분하여 사용함에 따라 공통적인 속성들만 별도로 Access할 필요가 없는 경우
- 슈퍼타입의 속성개수가 많지 않은 경우
- 슈퍼타입과 관계를 맺은 엔티티가 거의 없는 경우
- 장점
: 정보를 각 서브타입 별로 조작할 경우, 조인하지 않아도 되며 Full Scan 발생시 유리
: 관계에 의해 발생하는 복잡한 참조 무결성 규칙을 적용할 수 있다. - 단점
: 처리속도 감소할 수 있다. - UID 유지 관리가 어렵다.
각각의 테이블로 분리(Identity)
: 슈퍼타입과 서브타입 각각을 테이블로 생성.
(일부 서브타입은 슈퍼타입에 통합되는 경우도 존재)
- 슈퍼타입과 서브타입을 각각 적절히 Access하는 경우
- 슈퍼타입에 속한 공통속성들만 Access하는 빈도가 높은 경우
- 슈퍼타입과 서브타입 각각 별도 관계를 맺은 엔티티들이 존재하는 경우
- 업무적으로 변화가능성이 높아 유연성을 확보할 필요가 있는 경우
- 장점
: 각각의 테이블로 처리할 경우, 수행 속도가 빠르다.
: 슈퍼 타입에 속한 정보만 조회하는 경우, 문장 작성이 용이하다.
: 컬럼의 중복이 적으므로, 상대적으로 작은 공간을 차지한다.
: 관계에 의해 발생하는 복잡한 참조 무결성 규칙을 적용할 수 있다.

내가 보려고 쓰는 블로그