[해석] Supervised and Unsupervised Representation Learning for Reinforcement Learning
난 뭘 아는 걸까
원문 Supervised and Unsupervised Representation Learning for Reinforcement Learning Author: András Béres
그냥 원문 그대로 읽어도 되긴 하지만, 아무래도 영어면 한 번 볼 때 못읽고 지나치는 부분이 있다.
수식이 복잡하거나 어려운 글도 아니니 필요한 부분만 해석해서 두고두고 보려고 기록한다!
혹시 누군가 읽으신다면,, 이 글 의역 엄청 많이 했습니당. 그러다보니 오역이 생겼을 수도 있으니 감안하고 보세용!!
Introduction
최근 자율 주행차들은 학계와 관중 모두에서 큰 관심을 받고 있다. 딥러닝이 방대한 양의 센서 데이터 처리를 위한 도구를 제공해줄 수 있긴 하지만, 강화학습은 복잡한 상호작용 환경에서의 올바른 행동을 취할 수 있는 능력이 될 것이다. 이런 도구를 쓰는 것은 자율주행 task를 해결할 수 있는 방법이 되지만, 몇 몇 문제들이 실생활에서의 활용을 어렵게 한다.
현실 세계에서의 방대한 양의 경험을 모으는 AI 에이전트는 너무 비싸고, 가끔은 심지어 위험하기까지 하기 때문에, 우리는 에이전트를 시뮬레이터에서 학습시키고, 현실세계로 바꾼다. 난 연구 중에 Duckietown self-driving platform을 사용했는데, lane-following 에이전트를 시뮬레이션으로 강화 학습시킨 후, 현실 세계에로 바꾸었다.
Duckietown
Duckietown은 오픈소스 자율주행 플랫폼이고, 여러개의 메인 파트로 구성되어 있다. 그 중 하나인 Duckiebots은 작은 사이즈의 자율 주행이 가능한 차(autonomy capable vehicles) 이다. 라즈베리파이로 제어할 수 있고, 하나의 카메라를 갖추고 있다. (중략)
Representation Learning
강화학습의 성능과 스피드를 높일 수 있는 테크닉은 바로 Representation Learning(표현학습)이다. 표현학습이란, pretraining 또는 secondary task의 도움으로, 우리는 feature extractor이나 encoder를 학습시킬 수 있다 ㅡ 그것은 입력 이미지를 저차원의 유의미한 표현으로 압축한다. 이들은 일반적으로 input을 다운샘플링 하는 neural networks로 구현된다. 이러한 표현을 강화학습에서 사용하면, 우리는 task를 더 쉽게 만들 수 있고, 학습을 더 쉽게 이루어지게 하기 위해 observation space를 저차원으로 만들어준다.(아,, 저차원으로 만들면 학습이 더 쉽지,,! 연관지어서 생각을 못했당,,)
나는 표현학습에서 두 가지 방법을 실험했다. 하나는 Supervised representation learning이었는데, 우리는 전문가의 지식을 사용해서, 인코더에게 배워야 할 표현이 무엇인지 정확하게 말해줬다. 또 다른 하나는 Unsupervised representation learning이었다. 여기선 pretraining task에 맞기만 한다면 어떤 표현이든 자유롭게 배우도록 했다.
Supervised Representation Learning
Supervised Representation Learning에서는, 내가 따라야 할 표현을 골랐다: 우리는 입력 이미지 프레임 각각을 세개의 물리적인 양(차량으로부터 트랙 중간의 signed distance와 차량과 트랙의 signed angle, 그리고 차량 앞과 트랙의 곡률)을 같는 튜플로 인코딩한다. 나는 이 물리량을 각 프레임마다 예측하기 위해 regression을 사용한 나의 feature extractor을 pretrained 시켰고, 강화학습 agent의 입력으로써 세 개의 프레임마다 representation을 사용했다.
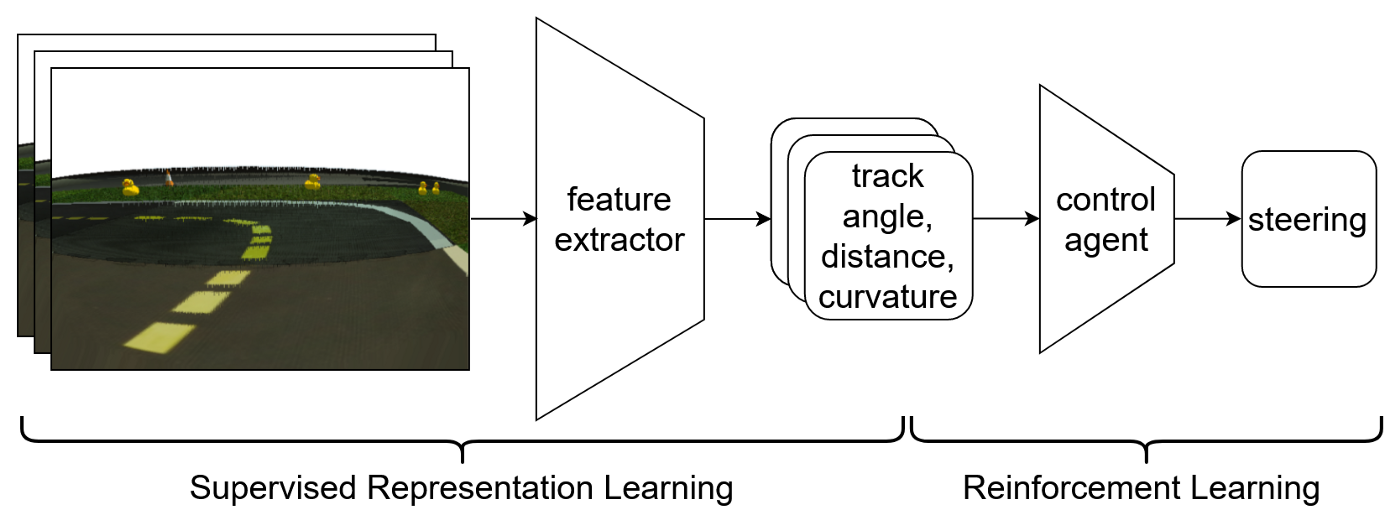
나는 200.000 이미지를 포함한 오프라인 데이터셋과 그것에 상응하는 ground truth 물리량을 생성하여 pretraining에 사용했다. 그 후, 나는 인코더를 동결시키고 observation wrapper로 사용했다. 이런 representations는 end-to-end 강화 학습과 비교하여 더 높은 최종 성능을 내는 결과를 보였다.
Unsupervised Representation Learning
몇 몇 상황에서 우리는, 어떤 representation이 특정 문제를 최적으로 풀 수 있는지를 모를 때가 있기도 하고, 데이터를 라벨링 하는 게 너무 어렵거나 비쌀 때가 있다. 이런 경우, 우리는 표현학습에서 unsupervised learning을 사용할 수 있다.
특히 강화학습에서 가장 유명한 방법은, Variational Autoencoder(VAE) 를 사용하는 방법이다. VAE는 입력 이미지를 latent representation으로 압축한다. 간단히 말하면, VAE는 입력을 latent distribution을 바꾸고, 샘플을 사용해서 이 distribution을 재구성하려 하는 작업을 수행한다. 스무스하고 조밀한 latent space를 강화하는 학습을 진행하는 동안, distribution은 regularization을 한다. 이 과정은 reinforcement learning에서 실용적이다.
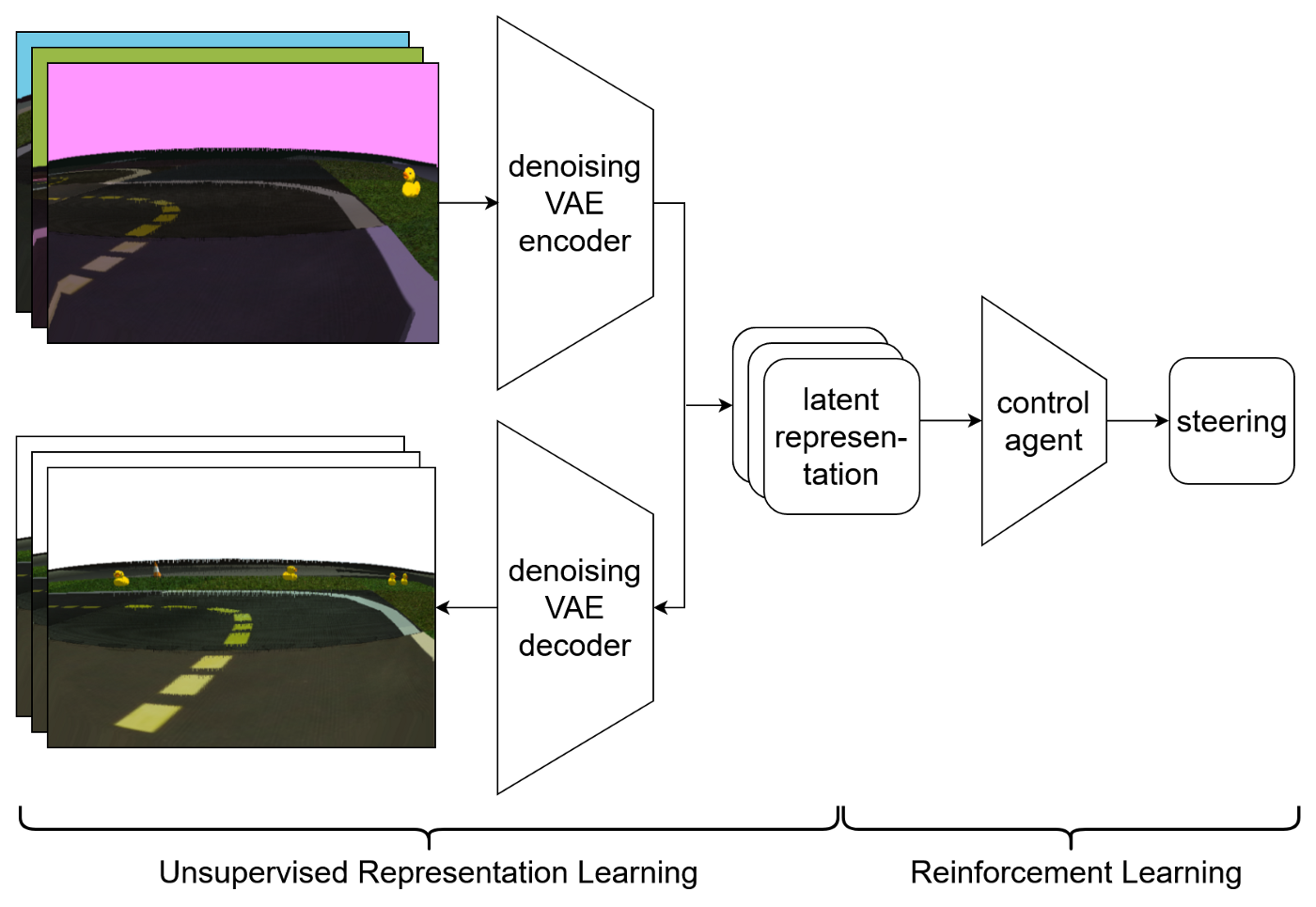
내가 사용한 방법은 VAE를 Visual Domain Randomization과 효율적으로 결합하는 방식이다. 내 아이디어는, non-randomized version을 randomized input image를 기반으로 재구성하는 것이다. 이것은 pretraining task를 더 어렵게 만들고, 모델이 시시각각 변하는 물체의 비쥬얼에서 레이턴트 용량을 낭비하지 않는다는 것을 보장한다. 이 방법은 VAE와 Denoising Autoencoders의 결합으로써 보여진다.
Result
Unsupervised representation learning 기술로, 나는 the Student Research Conference of Budapest University of Technology and Economics에서 1st prize in the Neural Networks section을 수상했다.
Supervised로도 상탔다.. ㅊㅋㅊㅋ!!
