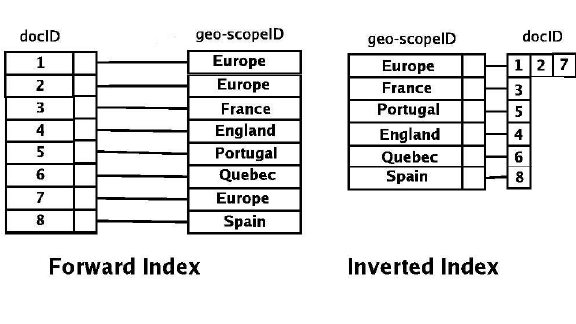
Index (색인): 키-밸류
Index는 큰 데이터베이스에서 데이터를 저장하고 탐색하는 과정이 보다 빠르고 효율적이도록 만들어진 것이다. 보통 테이블의 형태를 띠고 딕셔너리를 생각하면 쉽다. (키-원본 데이터의 주소) 데이터베이스의 일부 (또는 테이블의 일부)에만 색인 처리를 하기 때문에 자주 사용하는 데이터에 색인 처리를 해두면 시간을 절약할 수 있다. (색인 테이블부터 탐색 - 없으면 필요한 테이블이나 데이터베이스를 탐색)
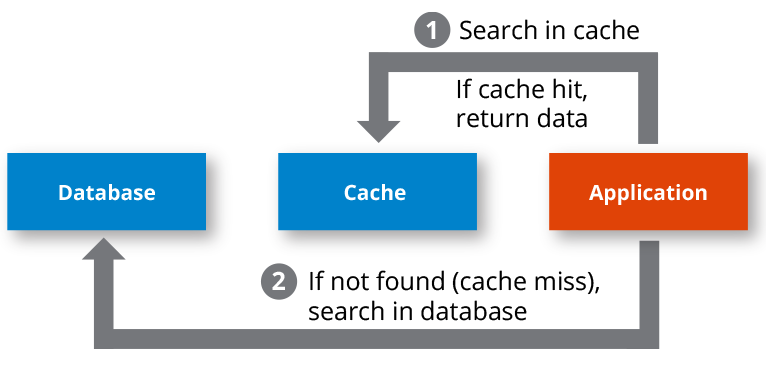
운영체제에서 자주 쓰는 걸 cache에 저장해 두고 cache miss가 나면 memory를 탐색하는 거랑 비슷한 것 같다
출처> https://hazelcast.com/foundations/caching/cache-miss/
캐시 미스가 나면 DB로 가는데 DB에서도 빨리 찾으려고 인덱스를 붙여놓고 인덱스를 안 걸어놨으면 DB를 탐색하고...
바쁘다 바빠 컴퓨터 세상
Inverted Index (역색인): 밸류-키
색인을 반대로 적용한 것으로 찾고자 하는 내용이 어디에 있는지를 기록해 둔다. 찾고자 하는 내용을 역색인 테이블에서 찾으면 원본 테이블에 어디 있는지 바로 알 수 있다. 엄청나군
특정 내용을 색인 방식으로 찾으려고 하면 아래와 같은 과정을 거쳐야 할 것임
- 색인 테이블 탐색
- 원하는 걸 찾을 때까지 색인 테이블의 모든 record에 대해서 들고 있는 주소에 가서 원하는 내용인지 확인해 보기
- if 색인 테이블 hit: 아싸 찾았다
- if miss: 원본 테이블 박박 뒤지기
근데 역색인 테이블은 원하는 내용을 갖고 있기 때문에, 테이블에 reference하지 않아도 된다. 색인 테이블은 hit 하더라도 탐색하는 과정에서 일단 유한 번 원본 테이블에 reference해야 한다. 역색인 테이블은 역색인 테이블에만 reference하면 된다는 것임 허거덩
수정: id에만 index를 걸어놓으면 이게 맞는데 (주소밖에 모르니까 직접 가서 확인해 봐야 함) 확인하려는 데이터도 같이 index를 걸어놓으면 굳이 원본 테이블 reference 할 필요 없다고 한다. 그치만 그만큼 테이블 크기가 커지겠죠
역색인 테이블은 심지어 데이터가 늘어나도 탐색해야 할 row가 늘어나는 게 아니라 밸류-키에서 키 배열 길이가 길어지는 것뿐이기 때문에 데이터가 추가돼도 탐색 속도에 큰 차이가 없다고 한다.
Elasticsearch는 역색인 방식을 쓰기 때문에 많은 데이터를 가지고 있어도 검색을 매우 빠르게 할 수 있다고 한다.
ES 쓸 때 ES의 강점은 쉽게 시각화를 할 수 있는 것 (심지어 실시간으로 시각화된 정보가 바뀌도록 그래프를 만들어둘 수 있음)이라고 생각했는데, 이것을 뒷받침하는 것은 아주 빠른 데이터 갱신과 검색이었겠다는 생각이 든다.
https://esbook.kimjmin.net/06-text-analysis/6.1-indexing-data
