H2 데이터베이스 설치
- 지금까지는 아주 간단하게 memory로 DB를 관리 -> 서버를 껐다 켜면 사라짐
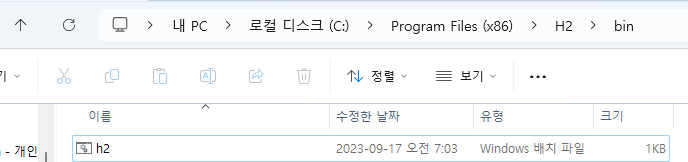
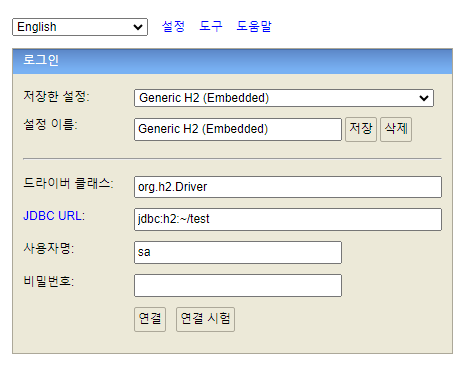
- H2 설치하고 이것을 (왼쪽) 실행하면 콘솔 (오른쪽)이 나온다.
 |  |
|---|
windows: DB 파일은 C://user/${username}에 생긴다.
쿼리들...
drop table if exists member CASCADE;
create table member
(
id bigint generated by default as identity,
name varchar(255),
primary key(id)
);
insert into member(name) values ('spring');bigint: JAVA의 long
generated by default as identity: 이 field를 NULL로 넣으면 DBMS가 적당히 알아서 값을 채워준다. (id를 생략해도 db가 알아서 잘 넣어주는 중)
순수 JDBC
JDBC(Java Database Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API이다. 위키
고대에 선배들은 이렇게 했구나~ 하면 됩니다
필요할 때 찾아와서 보세요
h2database 요게 클라이언트
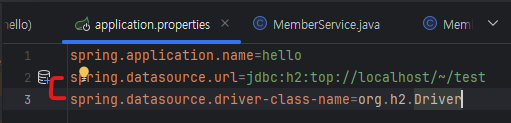
이렇게 하면 스프링이 그냥 DB랑 연결하는 필요한 작업을 다 해줘요
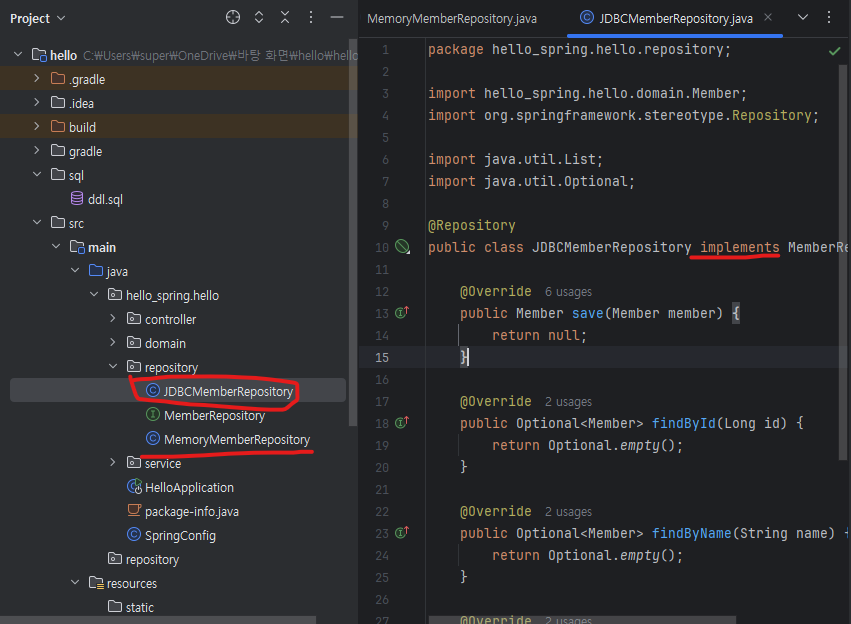
이제 메모리가 아니라 DB repository를 쓸 거니까 구현체를 새로 만들어 준다
- Save 함수
| 의사코드 | 실제구현 |
|---|---|
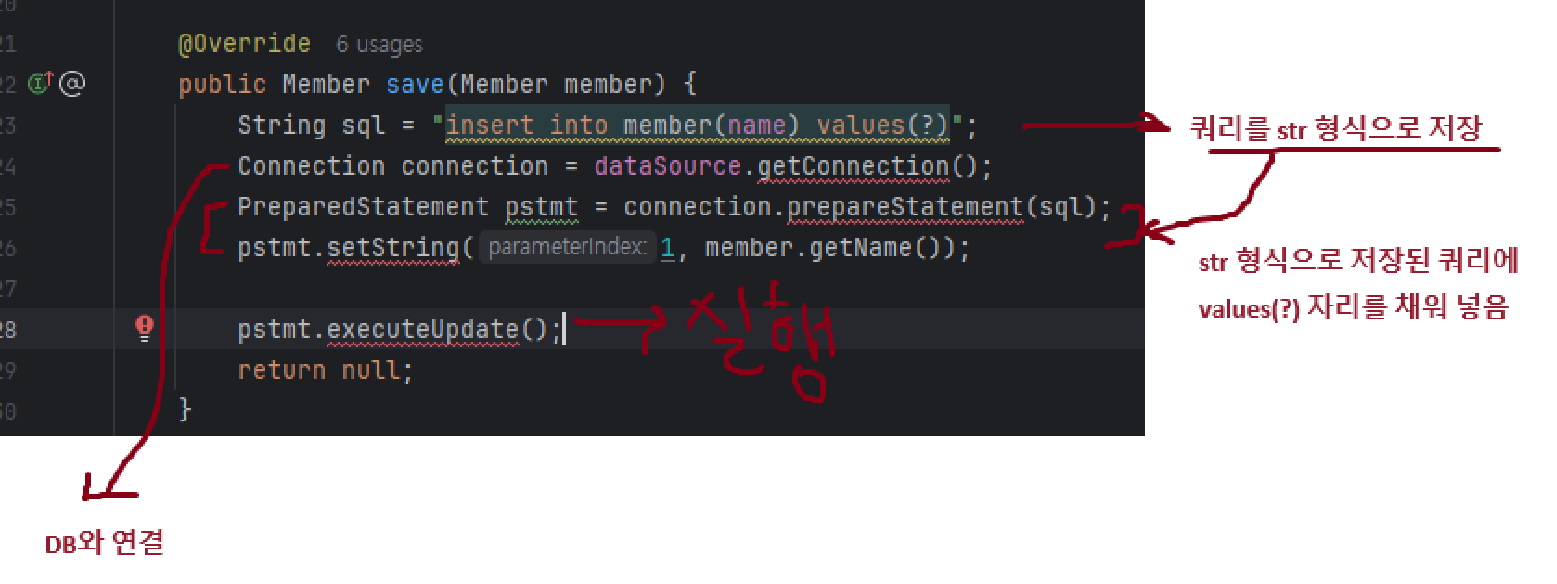 | 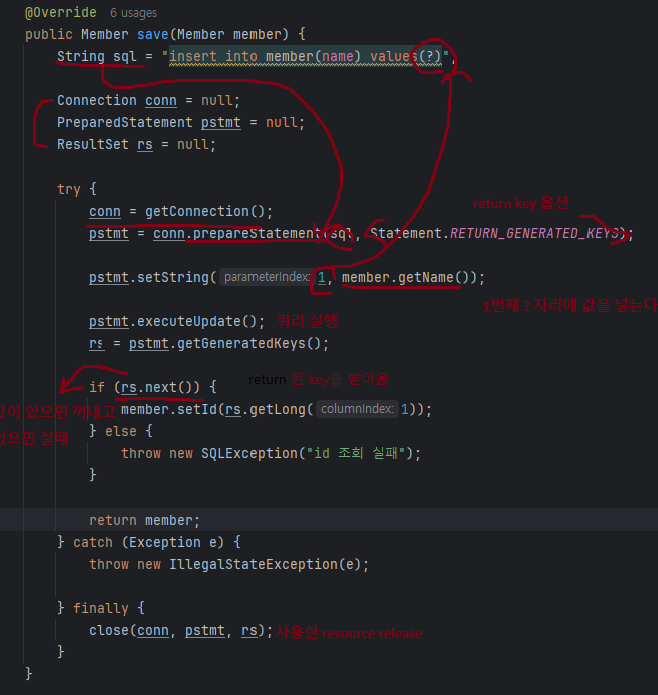 |
- Config 설정
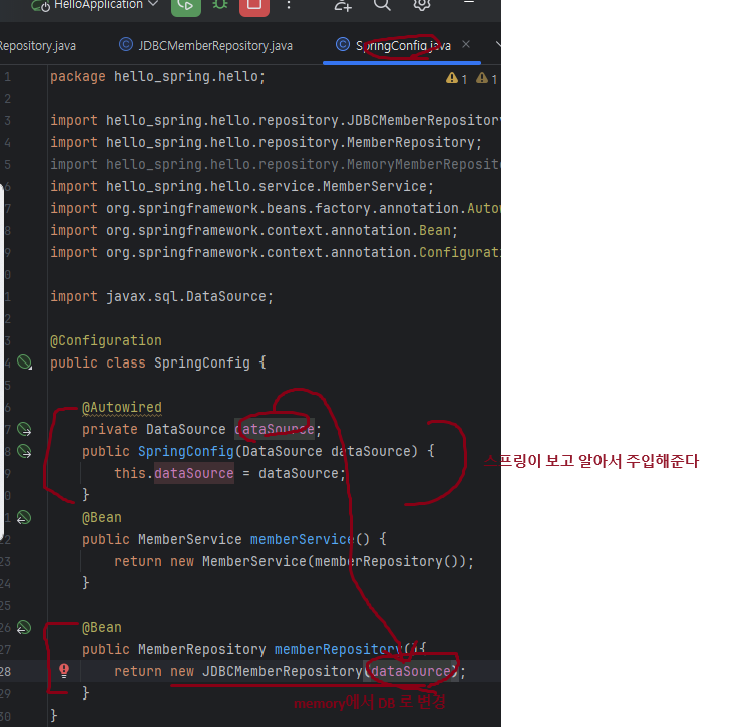
스프링을 왜 쓰는가?
- DI가 interface의 구현체 바꿔끼우기 등을 아주 쉽게 해준다.
- DI 덕분에 구현체를 바꾸려고 할 때 기존 코드를 조금도 손대지 않아도 된다. (Config만 손보면 됨)
- 개방-폐쇄 원칙 (OCP, Open-Closed Principle)
- 확장에는 열려있고 수정, 변경에는 닫혀있다.
스프링 통합 테스트
- @SpringBootTest 스프링 컨테이너와 테스트를 함께 실행한다.
- @SpringBootTest는 그냥 자바가 아니라 스프링을 띄우고 테스트하는 것이라서 시간이 좀 더 걸린다. (매번 스프링을 띄우고 테스트가 끝나면 스프링을 내린다.)
스프링 부트의 기막힌 기능
- DB의 transaction
- transaction은 commit하기 전까지는 DB에 반영되지 않는다.
- transaction을 실행하고 commit하기 전에 롤백하면 DB에는 아무런 영향을 주지 않는다.
- @Transactional이라는 annotation을 테스트 케이스 앞에 붙이면, 테스트가 끝나고 나면 테스트 중에 일어난 transaction을 commit하기 전에 싹 롤백해준다.
- 이렇게 하면 DB에 데이터가 남지 않으므로 다음 테스트에 영향을 주지 않는다. (앞에서 AfterEach 하면서 delete해왔던 것과 마찬가지)
- @Transactional은 test case (@...Test)앞에 있을 때만 동작하고 이외에는 동작하지 않는다.
스프링을 띄우는 통합 테스트와 단순 자바 코드를 테스트하는 단위 테스트
- 순수한 단위 테스트가 훨씬 좋은 테스트일 확률이 높다.
- 컨테이너까지 올리고... 해야 한다면 오래 걸린다.
- 단위 테스트는 한 번에 테스트 해야 하는 것만 잘 쪼개서 만들어야 한다.
- 단위 테스트를 만드는 연습을 해야 합니다!
스프링 JdbcTemplate
- Jdbc API에서 본 반복 코드를 대부분 제거해 준다.
- SQL 쿼리는 직접 작성해야 한다.
- 실무에서 많이 씁니다

- 생성자가 딱 하나일 때는 @AutoWired를 생략해도 된다 (하나일 때만!)
| JDBC | JDBC Template |
|---|---|
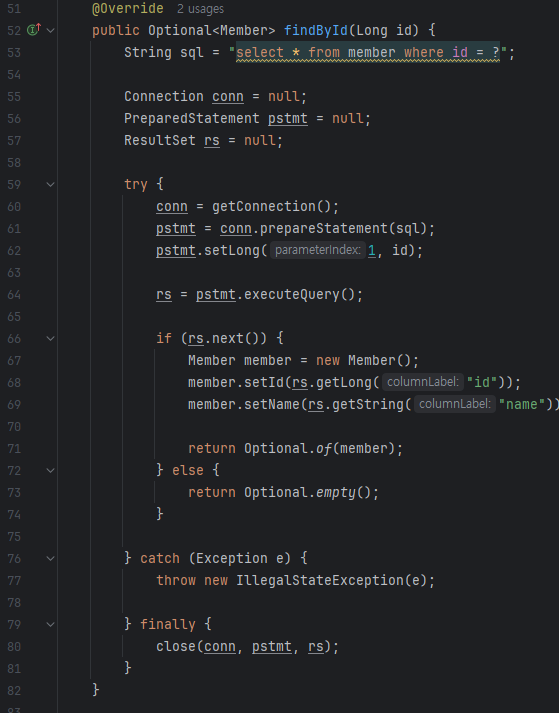 |  |
템플릿을 쓰면 코드가 어마어마하게 짧고 간단해진다.
JPA (Java Persistence API)
- 객체를 바로 DB에 쿼리 없이 저장할 수 있음 (JPA가 알아서 쿼리 날림)
- SQL과 데이터 중심의 설계에서 객체 중심의 설계로 전환할 수 있다 (개발자가 쿼리를 신경 안 써도 되니까) => 개발 생산성을 크게 높일 수 있다.
초기 세팅: gradle로 라이브러리 다운 받고...
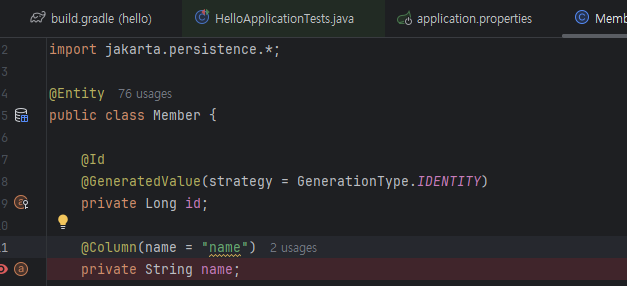
JPA: ORM (Object, Relational, Mapping)
Object와 relational DB의 table을 Mapping한다. 매핑 어떻게 하느냐 -> annotation으로 합니다
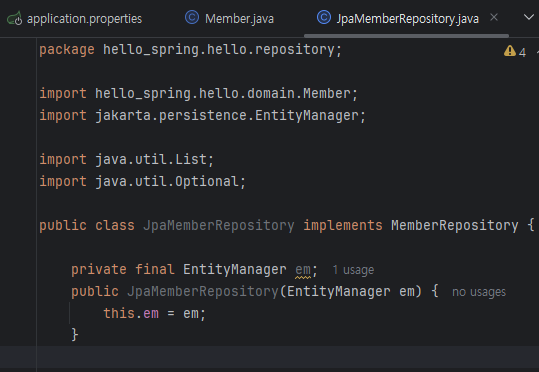

- JPA를 쓰려면 EntityManager라는 것을 주입받아야 한다.
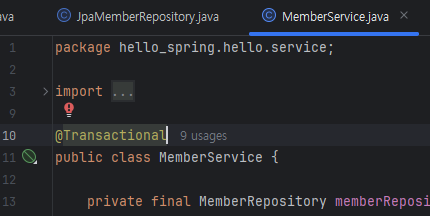
jpql: Java Persistence Query Language
객체를 가지고 쿼리를 막 날릴 수 있다. Select 객체 from table 같은 것 됨
jpa를 쓸 때 주의해야 할 점
- 항상 transaction이 있어야 한다. 모든 데이터 변경이 transaction 안에서 실행되어야 한다.
그래서 이번에는 MemberService 앞에 @Transactional을 붙임
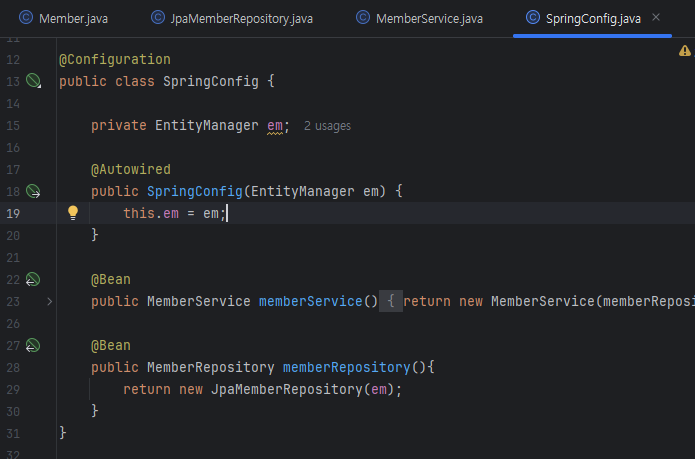
SpringConfig에서 EntityManager를 만들고 주입받을 수 있도록 수정해준다.
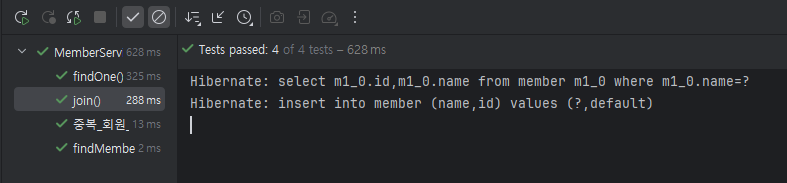
test를 돌려 보면 내가 쿼리를 작성하지 않았지만 hibernate라는 멋지고 똑똑한 친구가 쿼리를 써서 보내둔 것이 보인다.
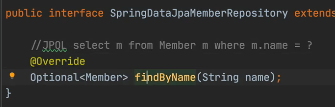
스프링 데이터 JPA
- 이것은 어마어마한 녀석이라고 한다
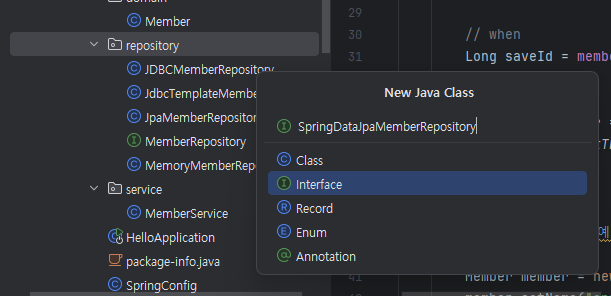
-
interface로 만든다.
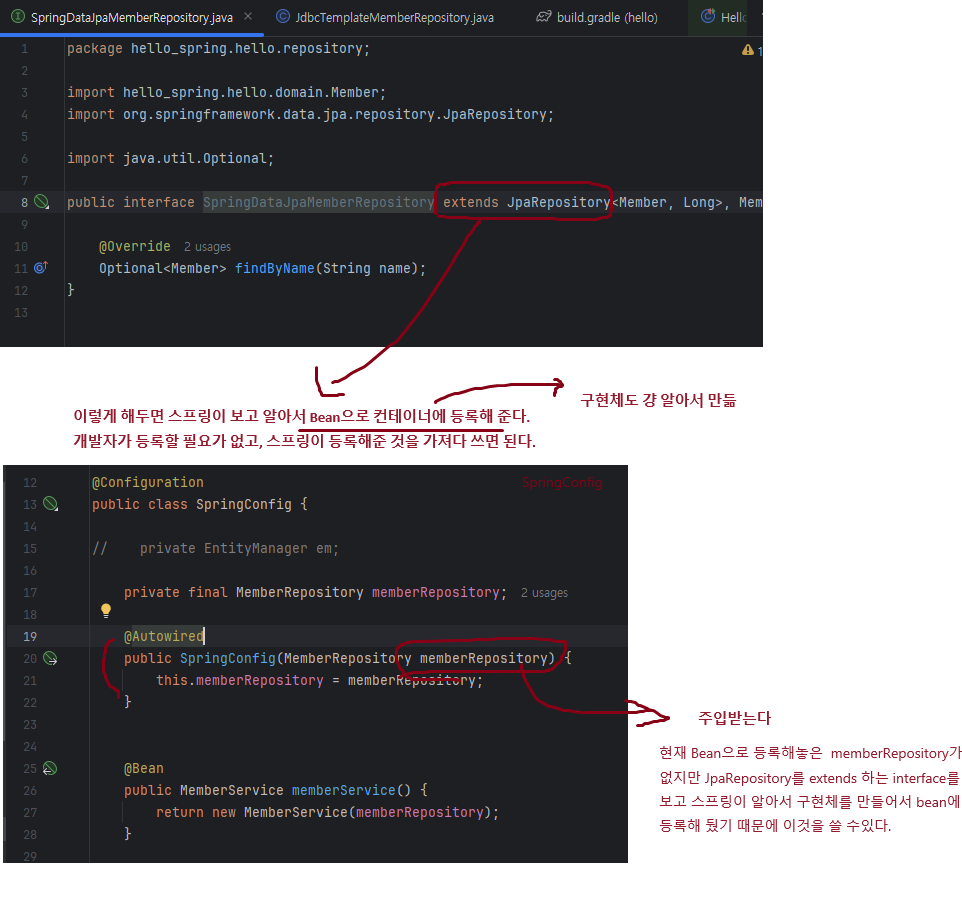
-
JpaRepository는 기본 쿼리CRUD (delete, findBy..., save 등) 들은 거의 다 제공한다.
-
이 세상에 존재하는 모든 객체를 하나의 메소드로 처리할 순 없으니까... 이름 짓는 규칙을 만들어 줘야 한다.
-
findByName 처럼 규칙을 알려 주면 JpaRepository가 다른 메소드들도 이름을 뚝딱뚝딱 만들어준다.